
كل أداة ذكاء اصطناعي ضريبية جرّبتها أخطأت في الخصم نفسه — لأن الإنترنت أخطأ
كان لديّ شاشتان مفتوحتان. على اليسار، النص التشريعي: القسم 63(b)(7) من قانون الإيرادات الداخلي (Internal Revenue Code)، وهو الحكم الذي استخدمه قانون التوفيق الشامل للموازنة (Omnibus Budget Reconciliation Act) لإنشاء خصم جديد على الفائدة على قروض سيارات الركاب المؤهلة. وعلى اليمين، موقع H&R Block نفسه، يصف الخصم ذاته بأنه "حافز فوق الخط".
لا يمكن أن تكون الشاشتان صحيحتين معًا. فالقسم 63(b)(7) يخفّض الدخل الخاضع للضريبة — إنه خصم تحت الخط. وهو لا يمسّ إجمالي الدخل المعدّل. أما "فوق الخط" فيعني العكس. إحدى أكبر علامات إعداد الضرائب في أمريكا كانت قد عكست اتجاه أحد الخصومات على موقعها العام، وحتى أبريل 2026 لا يزال الأمر كذلك.
قد يكون ذلك مجرد هامش، لولا ما حدث حين بدأت أسأل الذكاء الاصطناعي عنه. طرحت السؤال على عدة نماذج لغوية كبيرة رائدة — أدوات الذكاء الاصطناعي ذاتها للامتثال الضريبي التي تربطها الشركات الآن بإعداد الإقرارات. أخبرني كل واحد منها، بقواعد نحوية سليمة واستشهاد معقول، بأن الخصم فوق الخط. لقد قرأت جميعها الإنترنت نفسه. وكان الإنترنت مخطئًا.
حين يعطيك كل ذكاء اصطناعي الإجابة الخاطئة نفسها، فهذا ليس خللًا عابرًا. إنه تصويت بيانات التدريب، والحقيقة هي الخاسرة.
تلك كانت اللحظة التي اتّضحت فيها الشركة التي كنت أبنيها. كان القطاع يتسابق لجعل الذكاء الاصطناعي يُعِدّ الإقرارات الضريبية بشكل أسرع. لم يكن أحد تقريبًا يبني الشيء الذي يمسك الخطأ حين يكون الذكاء الاصطناعي مخطئًا بثقة ومنهجية. تلك الفجوة هي ما وُجدت طبقة التحقق من الذكاء الاصطناعي للامتثال الضريبي من Veriprajna لأجل سدّه.
الخطأ الذي يتسلسل
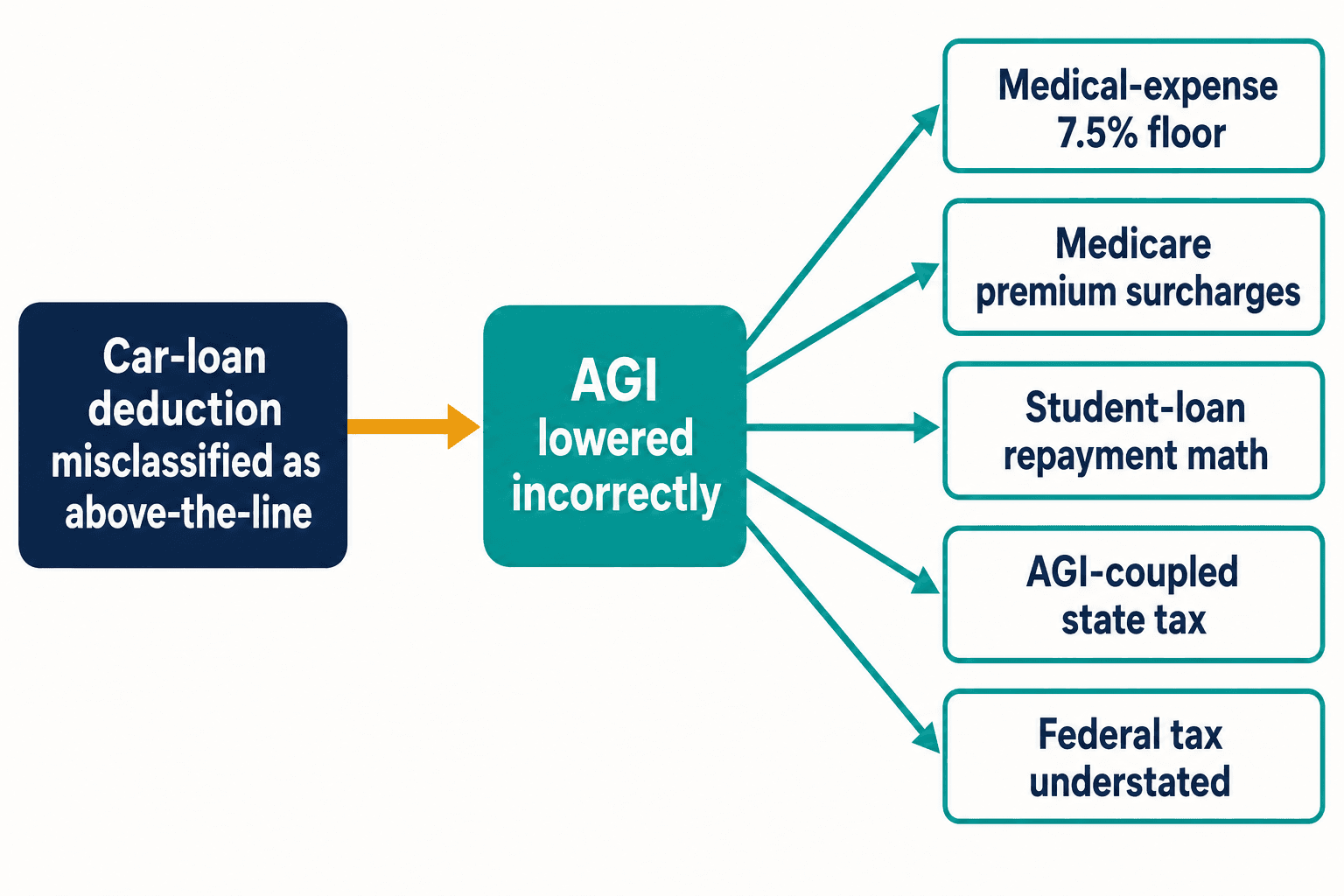
إليك سبب حرماني النوم من خصم واحد معكوس. سوء التصنيف كالذي حدث مع قرض السيارة لا يبقى محصورًا. عامِل ذلك الخصم على أنه فوق الخط فتخفّض إجمالي الدخل المعدّل الذي ما كان ينبغي أن يتحرك أصلًا. إجمالي الدخل المعدّل (AGI) عنصر حامل في قانون الضرائب. فهو يغذّي عتبة خصم النفقات الطبية البالغة 7.5%. ويغذّي رسوم Medicare الإضافية على الأقساط المرتبطة بالدخل. ويغذّي حساب السداد المرتبط بالدخل على قروض الطلاب. وفي الولايات التي تُربط ضريبتها بإجمالي الدخل المعدّل الفيدرالي، يقلّل ضمنًا من ضريبة الولاية أيضًا.
رمز واحد خاطئ، وخمسة أخطاء حسابية لاحقة — وهذا من حكم واحد فقط. قانون الإيرادات الداخلي يضم آلاف الأحكام. أجرى الكونغرس عليه ما متوسطه 420 تغييرًا سنويًا بين عامي 2000 و2020، وفقًا لخدمة المدافع عن دافعي الضرائب (Taxpayer Advocate Service). كل تغيير جديد فرصة جديدة كي تسبقه المدوّنات قبل أن تستقر الإرشادات الرسمية، وكي يتعلّم الجيل التالي من النماذج النسخة الخاطئة بمجرد التكرار.
والشخص الذي يدفع الثمن ليس الخوارزمية. حين يكون الإقرار خاطئًا، تقع غرامة الدقة البالغة 20% بموجب دليل مصلحة الضرائب (IRS) على عاتق الإنسان الذي يحمل اسمه سطر التوقيع، الموقَّع تحت طائلة عقوبة الحنث باليمين. أما النموذج الذي صاغه فلا يملك رقم PTIN ولا أي مسؤولية. ظللت أعود إلى هذا التفاوت. كنا على وشك تسليم الصياغة للآلات وترك التبعة على البشر.
لماذا كففت عن الاعتقاد بأن الاسترجاع سينقذنا
كان حدسي الأول هو ذاته الذي يخطر للجميع: أطعِم النموذج القانون الفعلي. كان يُفترض أن يكون الحل هو التوليد المعزَّز بالاسترجاع — RAG، حيث يبحث النظام عن النص التشريعي الحقيقي ويسلّمه للنموذج قبل أن يجيب. بنت Blue J، التي جمعت جولة تمويل من الفئة D بقيمة 122 مليون دولار، هذا بالضبط: RAG فوق GPT-4.1، مع شراكة مع IBFD تغطي أكثر من 220 ولاية قضائية. هندسة جادّة من أناس جادّين.
لذا بنينا نموذجًا أوليًا للاسترجاع خاصًا بنا. وشاهدته يستدعي النص الصحيح للقسم 63(b)(7) — ثم يلخّصه بشكل خاطئ رغم ذلك.
ذلك هو العرض التوضيحي الذي حطّم افتراضي. الاسترجاع نجح. أما التفسير فلا. تُقرأ لغة التعديل في قانون الضرائب هكذا: "يُعدَّل القسم 163(h) بإدراج…" — عليك أن تعيد بناء الحالة الراهنة للقانون من شظايا، ونموذج امتصّت أوزانه الداخلية ملايين المنشورات المدوّنة التي تقول "فوق الخط" يتصرّف كقارئ متحيّز. يرى النص التشريعي الصحيح ومع ذلك يسمع الإجماع الخاطئ. تسليم محرّك احتمالات المستند الصحيح لا يجعله يستدل؛ إنما يمنح الإجابة الخاطئة بثقة استشهادًا أفضل مظهرًا.
الاسترجاع يجلب للنموذج النص الصحيح. لكنه لا يفعل شيئًا حيال كون النموذج قد حسم رأيه سلفًا.
بدأنا نسمّي هذا خطأ الإجماع — حين يتقارب كل ذكاء اصطناعي نحو الإجابة الخاطئة نفسها لأن السجل العام الذي تعلّم منه خاطئ في ذاته. إنه ليس هلوسة بالمعنى المعتاد. الهلوسة عشوائية. أما هذا فمنهجي، وقابل للتكرار، ومشترك عبر كل نموذج مُدرَّب على الويب المفتوح. ذلك التمييز غيّر طريقة تفكيري في المشكلة برمّتها.
"فقط غلّف GPT وأطلقه"
كانت هناك فترة تساءلت فيها بصدق إن كنت أُعقّد الأمر أكثر من اللازم. أخبرني مستشار أحترمه، بما معناه، أن أتوقف عن الفلسفة — غلّف نموذجًا جيدًا، وأضف الاسترجاع، وأطلقه، ودع السوق يقرّر. كان هناك كثير من الشركات جيدة التمويل تفعل ذلك بالضبط.
الجدال الذي دار بيننا انتهى إلى رقم واحد يُقتبس باستمرار: تُبلّغ Blue J عن معدل اختلاف أقل من 1 من كل 700. يبدو كأنه رقم دقة. لكنه ليس كذلك. إنه يقيس كم مرة يختلف المستخدمون مع الأداة — والممارس الذي لا يعرف الإجابة الصحيحة أصلًا لا يمكنه الاختلاف مع إجابة خاطئة. المقياس صامت تمامًا حيث يكمن الخطر: الإجابة الواثقة، المعقولة، الخاطئة التي لا يملك أحد على الطرف الآخر المعرفة الكافية لتحدّيها.
معدل الاختلاف يقيس ثقة المستخدمين، لا صحة النموذج. وفي موقف عالي الغرامة، ليس هذان الأمران واحدًا — والفجوة بينهما هي حيث تكمن الغرامة.
فقدت النوم بشأن ما إذا كان "صحيح على الأرجح" منتجًا. في مسألة تنسيق، هو كذلك. أما في موقف ضريبي تبلغ فيه غرامة الدقة 20% من النقص في السداد وغرامة الاحتيال 75%، فإن "صحيح على الأرجح" مسؤولية أتمتّها ووسّعت نطاقها. تلك كانت الحجة التي أنهت خطة تغليف GPT. الاحتمالي أداة خاطئة لسؤال حتمي، مهما بلغت جودة الاحتمالات.
ماذا يمنحك التحقق الحتمي فعلًا؟
البائعون الذين يتقنون هذا أكثر من غيرهم ليسوا روبوتات الدردشة — بل محرّكات الضرائب غير المباشرة. تحتفظ Vertex بأكثر من 300 مليون معدل ضريبي. وتُجري Avalara، التي حصلت على استثمار بقيمة 500 مليون دولار من BlackRock في أواخر 2025، وSovos عمليات التقديم عبر أكثر من 12,000 ولاية قضائية. بالنسبة للسيناريوهات التي تغطّيها، فهي حتمية بنسبة 100% مع مسارات تدقيق كاملة. اسألها سؤال المعدل نفسه ألف مرة فتحصل على الإجابة نفسها ألف مرة، ويمكنك أن تُظهر للمدقّق بالضبط لماذا.
لكن تلك المحرّكات لا تستطيع قراءة جملة. لا تستطيع الاستدلال بشأن اختبار الوقائع والظروف، وإضافة قاعدة جديدة تعني أن يرمّزها إنسان يدويًا. لذا ينقسم المجال بوضوح: المحرّكات الموثوقة لا تستطيع فهم اللغة، والأنظمة التي تفهم اللغة ليست موثوقة.
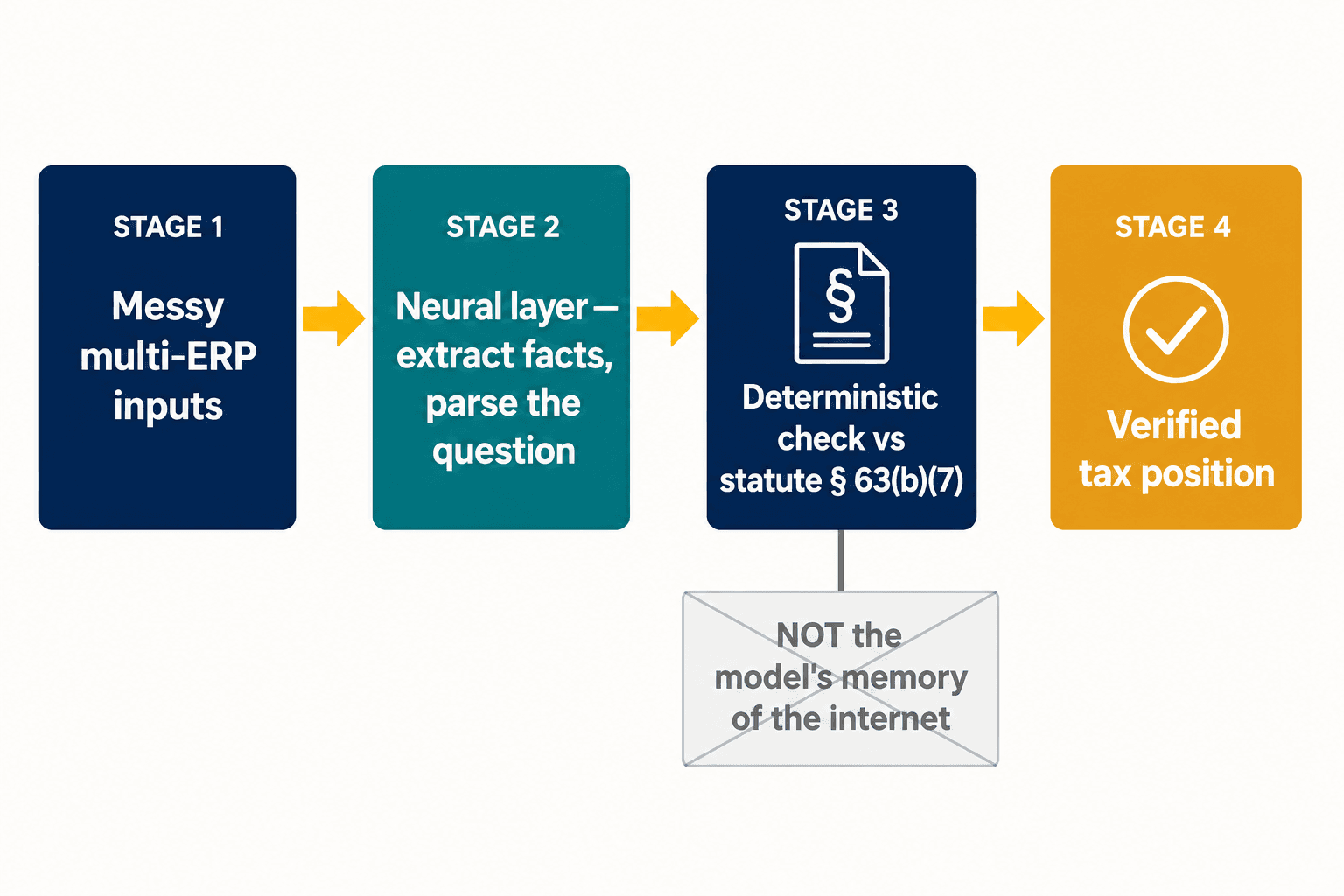
ذلك الانقسام هو مشكلة التصميم بأكملها، وهو حيث استقرّت معماريتنا. نحن لا نحاول جعل نموذج واحد مبدعًا ومتيقّنًا في آنٍ واحد. ندع طبقة عصبية تفعل ما تُجيده النماذج العصبية — قراءة المدخلات الفوضوية، واستخراج حقائق منظَّمة من الإقرار، وتحليل ما يسأل عنه الممارس فعلًا. ثم، بالنسبة للأحكام التي تكون فيها الصحة غير قابلة للتفاوض، يُفحَص الجواب مقابل تمثيل حتمي للنص التشريعي نفسه، لا مقابل ذاكرة النموذج عمّا قاله الإنترنت عنه. خصم قرض السيارة يقع تحت الخط لأن القسم 63(b)(7) يقول ذلك، وانتهى الأمر — لا لأن النموذج وزن الأدلة وصادف أن الأدلة كانت خاطئة.
الهدف ليس استبدال Thomson Reuters أو Wolters Kluwer. فأداة CCH Axcess Expert AI مدمجة عبر 10,000 شركة؛ وتزعم ONESOURCE خفضًا بنسبة 65% في وقت إعداد التقارير الروتينية. تلك الأدوات جيدة في الإعداد، والإعداد مشكلة محلولة إلى حد كبير الآن. تجلس طبقة التحقق فوق كل ما تشغّله بالفعل، محايدةً تجاه البائع، وتمسك الأخطاء المنهجية قبل أن تصل إلى مصلحة الضرائب. Thomson Reuters تتحقق من Thomson Reuters. وWolters Kluwer تتحقق من Wolters Kluwer. لم يكن أحد يتحقق عبر كل ذلك، مقابل الحقيقة المرجعية، للمواقف التي تحمل الغرامات فعلًا.
بالنسبة للشركات متعددة الجنسيات الكبيرة، تتضاعف المشكلة قبل أن يفتح الذكاء الاصطناعي فمه أصلًا. فنحو 78% من الشركات تشغّل ما بين أربعة إلى سبعة أنظمة ERP مختلفة، ووجدت EY أن نصف قادة الضرائب يذكرون غياب خطة مستدامة للبيانات والتكنولوجيا كأكبر عائق منفرد لديهم. أضِف إلى ذلك الركيزة الثانية (Pillar Two) — نظام الحد الأدنى العالمي للضريبة الذي يتطلب بيانات على مستوى الكيان وإبلاغًا موثوقًا بين الشركات، والذي لا يُبلّغ سوى نحو 15% من المؤسسات في بعض المناطق عن جاهزيته له بالكامل — عندها لا تكون الحلقة الأضعف استدلال النموذج على الإطلاق؛ بل ما إذا كانت الحقائق المنظَّمة التي تغذّيه صحيحة من الأساس. ذلك هو النصف الآخر من العمل: طبقة الاستخراج العصبية التي تحوّل المدخلات الفوضوية متعددة الأنظمة إلى شيء يمكن أن يثق به إما ذكاء اصطناعي أو محرّك حتمي.
لماذا أصبح الذكاء الاصطناعي الضريبي فجأة مسألة امتياز، لا مسألة أمن؟
لفترة، اعتبرت شرط النظام المغلق تفضيلًا أمنيًا — أمرًا لطيف الوجود، من قبيل النظافة المؤسسية. ثم في فبراير 2026 أصدرت محكمة المنطقة الجنوبية لنيويورك (SDNY) حكم Heppner، ولم يعد الأمر اختياريًا.
الخلاصة المختصرة: لصق وقائع عميل في أداة ذكاء اصطناعي عامة قد يُسقط امتياز السرية بين المحامي وموكّله على تلك المراسلات. وبالنسبة لقسم ضرائب، فإن ذلك يعيد صياغة كل شيء. لم يعد الاختيار بين روبوت دردشة عام ونظام مغلق تتحكم فيه المؤسسة يتعلق بنظافة البيانات — بل بما إذا كان تحليلك المشمول بالامتياز يظل مشمولًا بالامتياز. وقد عزّزت مصلحة الضرائب هذا الاتجاه في الموسم نفسه: فسياسة حوكمة الذكاء الاصطناعي لديها، IRM 10.24.1، تصنّف الآن مخرجات الذكاء الاصطناعي التوليدي التي تُشكّل الأساس الرئيسي لقرار ذي أثر قانوني أو مادي على أنها "عالية التأثير"، وتتطلب رقابة معزَّزة. المنظّمون يخبرونك، بلغتهم الخاصة، بأن موقفًا ضريبيًا بذكاء اصطناعي غير مُتحقَّق منه هو خطر عالي التأثير.
بعد قضية Heppner، فإن المعمارية التي تختارها للذكاء الاصطناعي الضريبي هي قرار امتياز قبل أن تكون قرارًا هندسيًا.
هذا ليس ضررًا افتراضيًا. أفادت Accountancy Age في مارس 2026 بأن نصف المحاسبين في المملكة المتحدة كانوا على علم بشركات تكبّدت خسائر مالية مباشرة من مشورة ذكاء اصطناعي خاطئة. وقد سجّل باحثون نحو 800 حالة خطأ استشهاد بالذكاء الاصطناعي عبر 25 دولة. وفي الوقت نفسه ترفع مصلحة الضرائب معدل تدقيقها للشركات الكبيرة من 8.8% نحو 22.6%. مزيد من المواقف المصاغة بالذكاء الاصطناعي، ومزيد من عمليات التدقيق، وغرامة تقع على الموقِّع — ذلك هو مسار التصادم.
أكثر الاعتراضات التي أسمعها
يسألني الناس عمّا إذا كانت النماذج الأفضل ستحل هذا وحدها. لن تفعل، وليس لأن النماذج لا تتحسّن. خطأ الإجماع خاصية من خصائص البيانات، لا حجم النموذج. النموذج الأكبر المُدرَّب على الإنترنت الخاطئ نفسه يتعلّم الإجابة الخاطئة بطلاقة أكبر، لا أقل. لا يمكنك التغلب بالتوسّع على مشكلة تتوسّع معك.
الأمر الآخر الذي أسمعه: أليست الطبقة الحتمية مجرد قواعد جامدة مرمَّزة يدويًا لا تستطيع مواكبة 420 تغييرًا في القانون سنويًا؟ ستكون كذلك، لو حاولنا ترميز القانون بأكمله. لكننا لا نفعل. تستهدف طبقة التحقق الأحكام عالية الغرامة وعالية التسلسل — الحفنة التي يكلّف فيها الخطأ الواثق مالًا حقيقيًا — وتترك التسعين بالمئة الروتينية لأدوات الإعداد التي تتعامل معها جيدًا بالفعل. لست بحاجة إلى اليقين بشأن كل شيء. أنت بحاجة إلى اليقين بشأن الأمور التي تعضّ.
ومن حين لآخر يسألني أحدهم لماذا ينبغي لقسم ضرائب أن يبني هذا بدلًا من انتظار إحدى شركات الأربعة الكبار (Big Four). تستهدف EY أتمتة 80% من الامتثال الضريبي الأجنبي؛ وأطلقت KPMG مُسرِّع الذكاء الاصطناعي الضريبي (Tax AI Accelerator) في فبراير 2026. لكن تلك الأدوات مبنية لارتباطات الشركة نفسها، وتُباع ضمن مشاريع من ست وسبع خانات، وهي تتحقق من عمل الشركة — لا عملك أنت. طبقة التحقق التي تتحكم فيها فعلًا هي التي تحمي التوقيع الذي توقّعه فعلًا.
ما كنت سأقوله لنفسي في وقت سابق
يكلّف الامتثال الضريبي الشركات الأمريكية أكثر من 126 مليار دولار سنويًا، والقطاع محقّ في توجيه الذكاء الاصطناعي نحو ذلك الرقم. ينبغي أتمتة الإعداد. الخطأ هو افتراض أنه بمجرد أن يتمكن الذكاء الاصطناعي من صياغة الإقرار يكون العمل قد انتهى — بينما في الواقع انتقل عنق الزجاجة للتوّ إلى مرحلة لاحقة، إلى التحقق، حيث يكون أصعب في الرؤية وأغلى ثمنًا عند الخطأ.
بدأت هذا وأنا أظن أن الجزء الصعب هو تعليم الآلة قانون الضرائب. تبيّن أن الجزء الصعب هو العكس: معرفة أي الأسئلة يجب ألا يُسمح للآلة أبدًا بأن تخمّن فيها، وبناء الطبقة التي ترفض السماح لها بذلك. يوم يعمل كل أداة ضريبية على الذكاء الاصطناعي، يبقى السؤال الحقيقي الوحيد هو مَن يفحص الذكاء الاصطناعي — و"الذكاء الاصطناعي نفسه، وقد سُئل بلطف أكبر" ليس جوابًا. إذا أردت أن ترى كيف بنينا ذلك الفحص، فهو هنا.
كان الإنترنت مخطئًا بشأن خصم قرض سيارة، وكل آلة تعلّمت منه ورثت الخطأ دون أن يرفّ لها جفن. في مكان ما داخل القانون توجد آلاف أخرى منها، تنتظر. العمل ليس جعل الذكاء الاصطناعي أذكى. بل ضمان أنه حين يكون العالم كله مخطئًا بثقة، لا يكون موقفك الضريبي كذلك.