
Testei várias IAs tributárias e todas erraram a mesma dedução — porque a internet errou
Eu estava com dois monitores abertos. À esquerda, a lei: a Seção 63(b)(7) do Internal Revenue Code, o dispositivo que o Omnibus Budget Reconciliation Act usou para criar uma nova dedução de juros sobre empréstimos qualificados para veículos de passageiros. À direita, o próprio site da H&R Block, descrevendo essa mesma dedução como um "incentivo above-the-line".
Essas duas telas não podem estar ambas certas. A Seção 63(b)(7) reduz a renda tributável — é uma dedução below-the-line. Ela não afeta a renda bruta ajustada. "Above-the-line" significa o oposto. Uma das maiores marcas de preparação tributária dos Estados Unidos tinha a direção de uma dedução invertida em seu site público e, em abril de 2026, ainda tinha.
Isso seria uma nota de rodapé, se não fosse pelo que aconteceu quando comecei a perguntar à IA sobre o assunto. Coloquei a questão diante de vários grandes modelos de linguagem de ponta — as mesmas ferramentas de IA de conformidade tributária que as empresas agora estão integrando à preparação de declarações. Cada um deles me disse, com gramática impecável e uma citação plausível, que a dedução era above-the-line. Todos tinham lido a mesma internet. E a internet estava errada.
Quando toda IA lhe dá a mesma resposta errada, não é uma falha. São os dados de treinamento votando, e a verdade perdendo.
Foi nesse momento que a empresa que eu estava construindo ganhou nitidez. O setor corria para fazer a IA preparar declarações de imposto mais rápido. Quase ninguém estava construindo a coisa que detecta quando a IA está confiante e sistematicamente errada. Essa lacuna é o que a camada de verificação de IA de conformidade tributária da Veriprajna existe para preencher.
O Erro Que se Propaga em Cascata
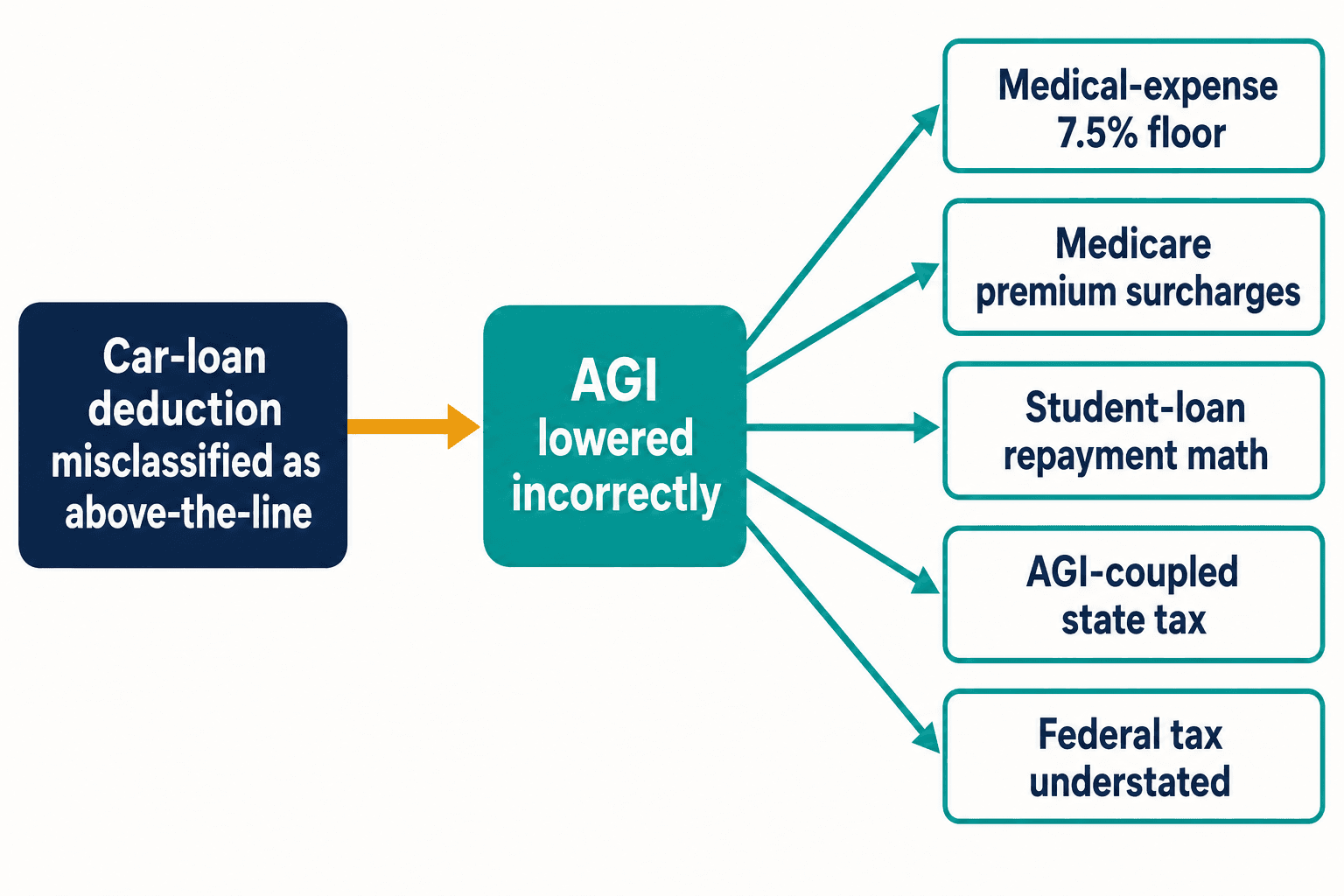
Eis por que uma única dedução invertida me tirava o sono. Uma classificação errada como a do empréstimo de carro não fica contida. Trate essa dedução como above-the-line e você reduz a renda bruta ajustada que nunca deveria ter se movido. A AGI é estrutural no código tributário. Ela alimenta o piso de 7,5% da dedução de despesas médicas. Ela alimenta as sobretaxas de prêmio do Medicare relacionadas à renda. Ela alimenta o cálculo de pagamento baseado na renda dos empréstimos estudantis. Nos estados cujo imposto está acoplado à AGI federal, ela também subestima silenciosamente o imposto estadual.
Um token errado, cinco cálculos errados a jusante — e isso a partir de um único dispositivo. O Internal Revenue Code tem milhares. O Congresso fez uma média de 420 alterações por ano nele entre 2000 e 2020, segundo o Taxpayer Advocate Service. Cada nova alteração é uma nova oportunidade para a blogosfera chegar antes que a orientação oficial se consolide, e para a próxima geração de modelos aprender a versão errada por pura repetição.
E quem paga não é o algoritmo. Quando uma declaração está errada, a multa de 20% relacionada à precisão prevista no manual da IRS recai sobre o ser humano cujo nome está na linha de assinatura, assinada sob pena de perjúrio. O modelo que a redigiu não tem PTIN e nenhuma responsabilidade. Eu voltava sempre a essa assimetria. Estávamos prestes a entregar a redação às máquinas e deixar a exposição com as pessoas.
Por Que Deixei de Acreditar Que a Recuperação Nos Salvaria
Meu primeiro instinto foi o mesmo que todo mundo tem: alimentar o modelo com a lei de verdade. A geração aumentada por recuperação — RAG, em que o sistema busca a lei real e a entrega ao modelo antes de ele responder — deveria ser a solução. A Blue J, que levantou uma Série D de US$ 122 milhões, construiu exatamente isso: RAG sobre o GPT-4.1, com uma parceria com a IBFD abrangendo mais de 220 jurisdições. Engenharia séria feita por gente séria.
Então construímos um protótipo de recuperação próprio. E eu o vi buscar o texto correto da Seção 63(b)(7) — e depois resumi-lo errado mesmo assim.
Foi a demonstração que quebrou minha suposição. A recuperação funcionou. A interpretação, não. A linguagem de emenda no código tributário se lê como "A Seção 163(h) é emendada com a inserção de…" — você precisa reconstruir o estado atual da lei a partir de fragmentos, e um modelo cujos pesos internos absorveram milhões de posts de blog dizendo "above-the-line" atua como um leitor enviesado. Ele vê a lei certa e ainda assim ouve o consenso errado. Entregar a um mecanismo de probabilidade o documento correto não o faz raciocinar; apenas dá a uma resposta confiantemente errada uma citação de aparência melhor.
A recuperação leva ao modelo o texto certo. Ela não faz nada quanto ao fato de o modelo já ter tomado sua decisão.
Começamos a chamar isso de Erro de Consenso — quando toda IA converge para a mesma resposta errada porque o registro público de que ela aprendeu está, ele próprio, errado. Não é alucinação no sentido usual. Uma alucinação é aleatória. Isso é sistemático, repetível e compartilhado por todos os modelos treinados na web aberta. Essa distinção mudou como pensei sobre todo o problema.
"É Só Encapsular o GPT e Lançar"
Houve um período em que eu genuinamente me perguntei se estava complicando demais. Um consultor que respeito me disse, mais ou menos, para parar de filosofar — encapsular um bom modelo, adicionar recuperação, lançar, deixar o mercado decidir. Muitas empresas bem financiadas estavam fazendo exatamente isso.
A discussão que tivemos se resumiu a um número que é citado o tempo todo: a Blue J relata uma taxa de discordância inferior a 1 em 700. Soa como um número de precisão. Não é. Ele mede com que frequência usuários discordam da ferramenta — e um profissional que ainda não conhece a resposta correta não pode discordar de uma errada. A métrica é silenciosa exatamente onde mora o perigo: a resposta confiante, plausível e errada que ninguém do outro lado tem conhecimento para contestar.
Uma taxa de discordância mede a confiança dos usuários, não a correção do modelo. Em uma posição de alta multa, essas não são a mesma coisa — e a distância entre elas é onde mora a multa.
Perdi o sono pensando se "provavelmente certo" era um produto. Numa questão de formatação, é. Numa posição tributária em que a multa por precisão é de 20% do valor recolhido a menor e a multa por fraude é de 75%, "provavelmente certo" é uma responsabilidade que você automatizou e escalou. Foi esse o argumento que encerrou o plano de encapsular o GPT. O probabilístico é a ferramenta errada para uma questão determinística, por melhores que fiquem as probabilidades.
O Que a Verificação Determinística Realmente Lhe Traz?
Os fornecedores que entendem isso melhor não são os chatbots — são os motores de impostos indiretos. A Vertex mantém mais de 300 milhões de alíquotas tributárias. A Avalara, que recebeu um investimento de US$ 500 milhões da BlackRock no fim de 2025, e a Sovos processam declarações em mais de 12.000 jurisdições. Para os cenários que cobrem, elas são 100% determinísticas com trilhas de auditoria completas. Faça a mesma pergunta sobre uma alíquota mil vezes e você obtém a mesma resposta mil vezes, e pode mostrar a um auditor exatamente o porquê.
Mas esses motores não conseguem ler uma frase. Eles não conseguem raciocinar sobre um teste de fatos e circunstâncias, e adicionar uma nova regra significa um humano codificando-a à mão. Então o campo se divide nitidamente: os motores que são confiáveis não conseguem entender linguagem, e os sistemas que entendem linguagem não são confiáveis.
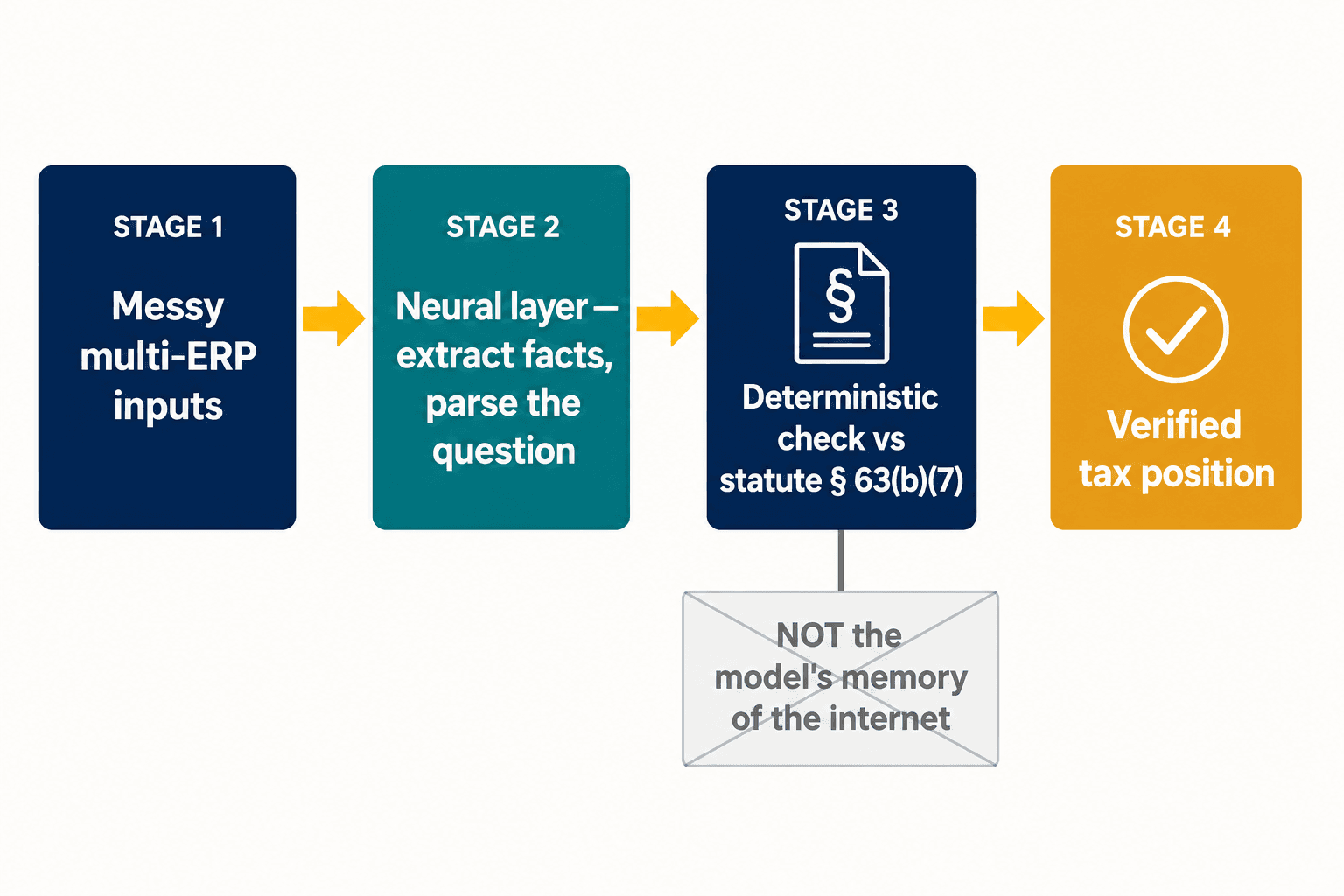
Essa divisão é todo o problema de design, e é onde ancoramos nossa arquitetura. Não tentamos fazer um único modelo ser ao mesmo tempo criativo e certeiro. Deixamos uma camada neural fazer aquilo em que os modelos neurais são bons — ler entradas bagunçadas, extrair fatos estruturados de uma declaração, interpretar o que um profissional está de fato perguntando. Depois, para os dispositivos em que a correção é inegociável, a resposta é verificada contra uma representação determinística da própria lei, não contra a memória do modelo sobre o que a internet disse a respeito dela. A dedução do empréstimo de carro fica below-the-line porque a Seção 63(b)(7) diz que sim, ponto final — não porque o modelo pesou as evidências e as evidências por acaso estavam erradas.
A ideia não é substituir a Thomson Reuters ou a Wolters Kluwer. O CCH Axcess Expert AI está incorporado em 10.000 empresas; o ONESOURCE afirma uma redução de 65% no tempo de relatórios de rotina. Essas ferramentas são boas em preparação, e preparação é hoje um problema em grande parte resolvido. A camada de verificação fica por cima do que você já usa, neutra quanto ao fornecedor, e detecta os erros sistemáticos antes que eles cheguem à IRS. A Thomson Reuters verifica a Thomson Reuters. A Wolters Kluwer verifica a Wolters Kluwer. Ninguém estava verificando tudo isso, contra a verdade fundamental, para as posições que de fato carregam multas.
Para grandes multinacionais o problema se agrava antes mesmo de a IA abrir a boca. Cerca de 78% das empresas rodam de quatro a sete sistemas ERP diferentes, e a EY constatou que metade dos líderes tributários aponta a falta de um plano sustentável de dados e tecnologia como sua maior barreira isolada. Some a isso o Pillar Two — o regime global de imposto mínimo que exige dados no nível de entidade e relatórios intercompanhias confiáveis, para o qual apenas cerca de 15% das organizações em algumas regiões relatam estar plenamente preparadas — e o elo mais fraco não é o raciocínio do modelo, de forma alguma; é se os fatos estruturados que o alimentam estão corretos, em primeiro lugar. Essa é a outra metade do trabalho: a camada neural de extração que transforma entradas bagunçadas de múltiplos sistemas em algo em que uma IA ou um motor determinístico possa confiar.
Por Que a IA Tributária de Repente é uma Questão de Sigilo, e Não de Segurança?
Por um tempo, pensei na exigência de sistema fechado como uma preferência de segurança — bom de ter, higiene corporativa. Então, em fevereiro de 2026, a SDNY proferiu a decisão Heppner, e isso deixou de ser opcional.
A versão curta: colar os fatos de um cliente em uma ferramenta de IA pública pode renunciar ao sigilo advogado-cliente sobre essas comunicações. Para um departamento tributário, isso reformula tudo. A escolha entre um chatbot público e um sistema fechado, controlado pela empresa, não é mais sobre higiene de dados — é sobre se sua análise sigilosa permanece sigilosa. A IRS reforçou essa direção na mesma temporada: sua política de governança de IA, a IRM 10.24.1, agora classifica como "de alto impacto" as saídas de IA generativa que servem de base principal para uma decisão com efeito jurídico ou material, exigindo supervisão reforçada. Os reguladores estão dizendo a você, em sua própria linguagem, que uma posição tributária de IA não verificada é um risco de alto impacto.
No pós-Heppner, a arquitetura que você escolhe para a IA tributária é uma decisão de sigilo antes de ser uma decisão de engenharia.
Isso não é um dano hipotético. A Accountancy Age relatou em março de 2026 que metade dos contadores do Reino Unido tinha conhecimento de empresas sofrendo perdas financeiras diretas em razão de aconselhamento incorreto de IA. Pesquisadores registraram cerca de 800 casos de erros de citação por IA em 25 países. Enquanto isso, a IRS está elevando sua taxa de auditoria de grandes corporações de 8,8% para 22,6%. Mais posições redigidas por IA, mais auditorias e uma multa que recai sobre quem assina — essa é a rota de colisão.
As Objeções Que Mais Ouço
As pessoas me perguntam se modelos melhores não vão simplesmente resolver isso por conta própria. Não vão, e não porque os modelos não estejam melhorando. O Erro de Consenso é uma propriedade dos dados, não do tamanho do modelo. Um modelo maior treinado na mesma internet errada aprende a resposta errada com mais fluência, não menos. Você não consegue superar em escala um problema que escala junto com você.
A outra coisa que ouço: uma camada determinística não é apenas um conjunto de regras rígidas e frágeis, codificadas à mão, que não conseguem acompanhar 420 alterações no código por ano? Seria, se tentássemos codificar o código inteiro. Não tentamos. A camada de verificação foca nos dispositivos de alta multa e alta cascata — o punhado em que estar confiantemente errado custa dinheiro de verdade — e deixa os noventa por cento de rotina para as ferramentas de preparação que já os tratam bem. Você não precisa de certeza sobre tudo. Você precisa de certeza sobre as coisas que mordem.
E de vez em quando alguém pergunta por que um departamento tributário deveria construir isso em vez de esperar por uma das Big Four. A EY tem como meta 80% de automação da conformidade tributária estrangeira; a KPMG lançou um Tax AI Accelerator em fevereiro de 2026. Mas essas ferramentas são feitas para os próprios trabalhos da firma, vendidas dentro de projetos de seis e sete dígitos, e verificam o trabalho da firma — não o seu. A camada de verificação que você de fato controla é a que protege a assinatura que você de fato assina.
O Que Eu Diria ao Meu Eu do Passado
A conformidade tributária custa às empresas dos EUA mais de US$ 126 bilhões por ano, e o setor tem razão em jogar IA contra esse número. A preparação deveria ser automatizada. O erro é supor que, uma vez que a IA consiga redigir a declaração, o trabalho está feito — quando, na verdade, o gargalo apenas se deslocou a jusante, para a verificação, onde é mais difícil de enxergar e mais caro de errar.
Comecei isto pensando que a parte difícil era ensinar direito tributário a uma máquina. A parte difícil acabou sendo o oposto: saber em quais perguntas uma máquina jamais deveria ter permissão para adivinhar, e construir a camada que se recusa a deixá-la fazer isso. No dia em que toda ferramenta tributária rodar com IA, a única pergunta real que resta é quem verifica a IA — e "a mesma IA, perguntada com mais educação" não é uma resposta. Se você quer ver como construímos essa verificação, é aqui.
A internet estava errada sobre uma dedução de empréstimo de carro, e toda máquina que aprendeu com ela herdou o erro sem piscar. Em algum lugar do código há milhares mais desses, esperando. O trabalho não é tornar a IA mais inteligente. É garantir que, quando o mundo inteiro estiver confiantemente errado, sua posição tributária não esteja.