
Jede Steuer-KI, die ich getestet habe, ordnete denselben Abzug falsch ein — weil das Internet es tat
Ich hatte zwei Monitore geöffnet. Links das Gesetz: Internal Revenue Code Section 63(b)(7), die Bestimmung, mit der der Omnibus Budget Reconciliation Act einen neuen Abzug für Zinsen auf qualifizierte Pkw-Darlehen geschaffen hat. Rechts die Website von H&R Block, die genau diesen Abzug als "above-the-line-Anreiz" beschreibt.
Diese beiden Bildschirme können nicht beide recht haben. Section 63(b)(7) senkt das zu versteuernde Einkommen — es ist ein below-the-line-Abzug. Er berührt das bereinigte Bruttoeinkommen (adjusted gross income) nicht. "Above-the-line" bedeutet das Gegenteil. Eine der größten Steuererklärungsmarken Amerikas hatte die Richtung eines Abzugs auf ihrer öffentlichen Website falsch herum dargestellt, und im April 2026 war das immer noch so.
Das wäre eine Randnotiz geblieben, wäre da nicht das gewesen, was passierte, als ich anfing, KI danach zu fragen. Ich stellte die Frage mehreren führenden großen Sprachmodellen — genau denselben KI-Werkzeugen für Steuer-Compliance, die Kanzleien jetzt in die Erstellung von Steuererklärungen einbinden. Jedes einzelne sagte mir, in sauberer Grammatik und mit einer plausiblen Quellenangabe, dass der Abzug above-the-line sei. Sie hatten alle dasselbe Internet gelesen. Und das Internet lag falsch.
Wenn jede KI dieselbe falsche Antwort gibt, ist das keine Panne. Es sind die Trainingsdaten, die abstimmen — und die Wahrheit, die verliert.
Das war der Moment, in dem das Unternehmen, das ich aufbaute, Kontur annahm. Die Branche wetteiferte darum, KI Steuererklärungen schneller erstellen zu lassen. Fast niemand baute das, was sie abfängt, wenn die KI selbstbewusst und systematisch falsch liegt. Genau diese Lücke soll VeriPrajnas Verifikationsschicht für Steuer-Compliance-KI füllen.
Der Fehler, der sich fortpflanzt
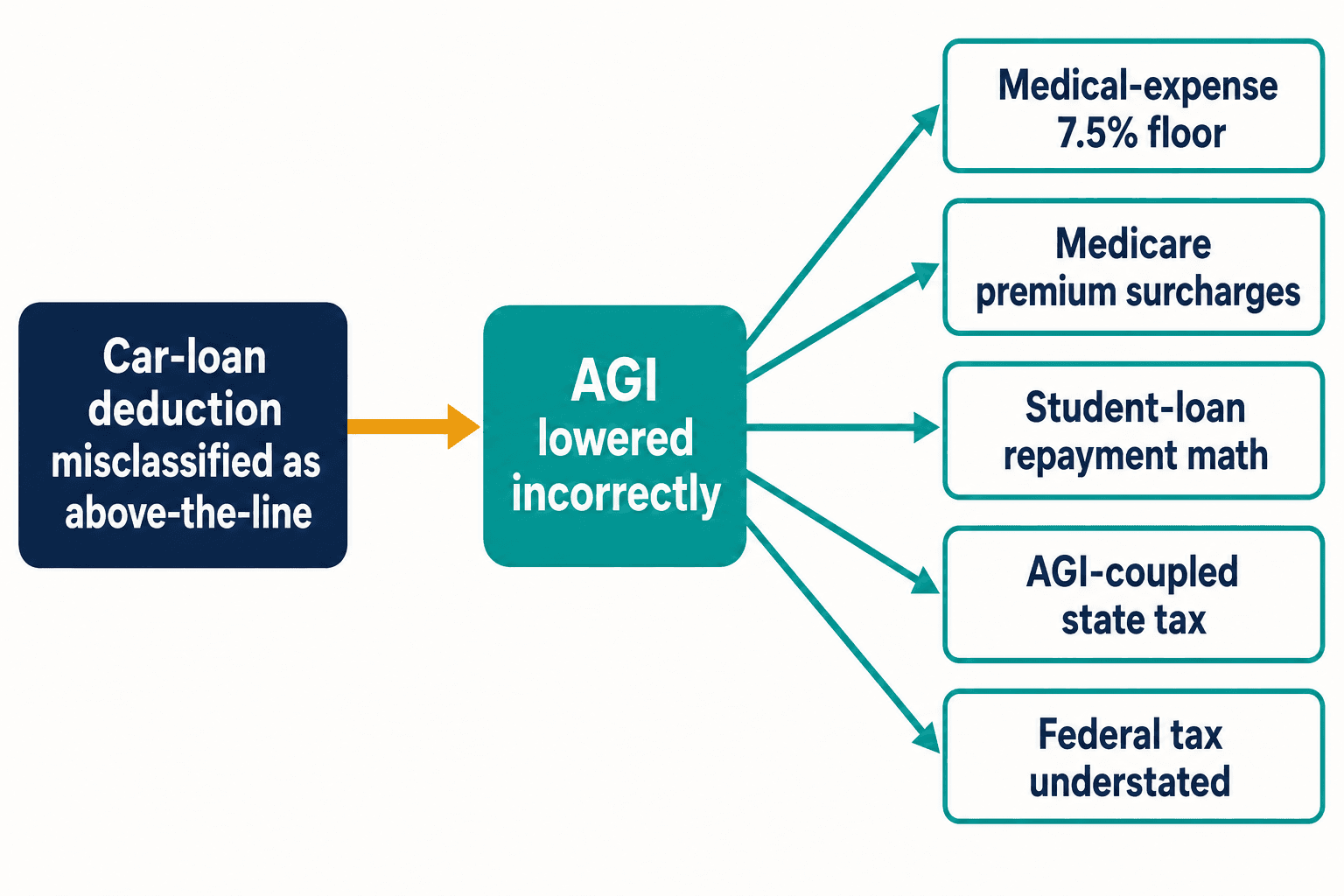
Hier ist der Grund, warum mir ein einziger falsch herum eingeordneter Abzug den Schlaf raubte. Eine Fehlklassifikation wie die beim Pkw-Darlehen bleibt nicht isoliert. Behandelt man diesen Abzug als above-the-line, senkt man das bereinigte Bruttoeinkommen (AGI), das sich niemals hätte bewegen dürfen. Das AGI ist tragend im Steuerrecht. Es speist die Grenze von 7,5 % für den Abzug medizinischer Ausgaben. Es speist die einkommensabhängigen Prämienzuschläge von Medicare. Es speist die einkommensorientierte Rückzahlungsberechnung bei Studienkrediten. In Staaten, deren Steuer an das föderale AGI gekoppelt ist, wird auch die Landessteuer stillschweigend zu niedrig ausgewiesen.
Ein falsches Token, fünf nachgelagerte Fehlberechnungen — und das aus einer einzigen Bestimmung. Der Internal Revenue Code hat Tausende davon. Der Kongress nahm zwischen 2000 und 2020 durchschnittlich 420 Änderungen pro Jahr daran vor, so der Taxpayer Advocate Service. Jede neue Änderung ist eine neue Gelegenheit für die Blogosphäre, schneller da zu sein als die offiziellen Leitlinien, und für die nächste Modellgeneration, die falsche Version durch schiere Wiederholung zu lernen.
Und wer die Rechnung zahlt, ist nicht der Algorithmus. Wenn eine Steuererklärung falsch ist, trifft die 20-prozentige genauigkeitsbezogene Strafe nach dem IRS-Handbuch den Menschen, dessen Name in der Unterschriftszeile steht, unterschrieben unter Strafandrohung wegen Meineids. Das Modell, das sie entworfen hat, hat keine PTIN und keine Haftung. Ich kam immer wieder auf diese Asymmetrie zurück. Wir waren im Begriff, das Entwerfen den Maschinen zu übergeben und das Risiko bei den Menschen zu belassen.
Warum ich aufhörte zu glauben, dass Retrieval uns retten würde
Mein erster Impuls war derselbe, den jeder hat: dem Modell das tatsächliche Gesetz vorlegen. Retrieval-augmented generation — RAG, bei dem das System das echte Gesetz nachschlägt und es dem Modell übergibt, bevor es antwortet — sollte die Lösung sein. Blue J, das eine Series D über 122 Mio. USD einwarb, baute genau das: RAG auf Basis von GPT-4.1, mit einer IBFD-Partnerschaft über mehr als 220 Rechtsordnungen. Ernsthafte Ingenieurskunst von ernsthaften Leuten.
Also bauten wir einen eigenen Retrieval-Prototyp. Und ich sah zu, wie er den korrekten Text von Section 63(b)(7) heraufholte — und ihn dann trotzdem falsch zusammenfasste.
Das war die Demo, die meine Annahme zerbrach. Das Retrieval funktionierte. Die Interpretation nicht. Änderungssprache im Steuerrecht liest sich wie "Section 163(h) wird durch Einfügen von … geändert" — man muss den aktuellen Stand des Gesetzes aus Fragmenten rekonstruieren, und ein Modell, dessen interne Gewichte Millionen von "above-the-line"-Blogbeiträgen aufgesogen haben, agiert als voreingenommener Leser. Es sieht das richtige Gesetz und hört dennoch den falschen Konsens. Einer Wahrscheinlichkeitsmaschine das korrekte Dokument in die Hand zu geben, bringt sie nicht zum Denken; es verpasst einer selbstbewusst falschen Antwort nur eine besser aussehende Quellenangabe.
Retrieval verschafft dem Modell den richtigen Text. Es ändert nichts daran, dass das Modell sich bereits entschieden hat.
Wir begannen, dies Konsensfehler zu nennen — wenn jede KI auf dieselbe falsche Antwort konvergiert, weil die öffentliche Datenlage, aus der sie gelernt hat, selbst falsch ist. Es ist keine Halluzination im üblichen Sinne. Eine Halluzination ist zufällig. Dies ist systematisch, wiederholbar und über jedes im offenen Web trainierte Modell hinweg geteilt. Diese Unterscheidung veränderte, wie ich über das gesamte Problem dachte.
"Pack einfach GPT ein und liefere es aus"
Es gab eine Phase, in der ich mich ernsthaft fragte, ob ich es zu kompliziert machte. Ein Berater, den ich schätze, sagte mir mehr oder weniger, ich solle aufhören zu philosophieren — ein gutes Modell einpacken, Retrieval hinzufügen, ausliefern, den Markt entscheiden lassen. Etliche gut finanzierte Unternehmen taten genau das.
Der Streit, den wir hatten, lief auf eine Zahl hinaus, die ständig zitiert wird: Blue J berichtet von einer Widerspruchsrate unter 1 zu 700. Es klingt nach einer Genauigkeitskennzahl. Ist es aber nicht. Sie misst, wie oft Nutzer dem Werkzeug widersprechen — und ein Praktiker, der die richtige Antwort nicht ohnehin schon kennt, kann einer falschen nicht widersprechen. Die Kennzahl schweigt genau dort, wo die Gefahr wohnt: bei der selbstbewussten, plausiblen, falschen Antwort, der niemand auf der anderen Seite mit dem nötigen Wissen widersprechen kann.
Eine Widerspruchsrate misst das Vertrauen der Nutzer, nicht die Korrektheit des Modells. Bei einer Position mit hohem Strafrisiko sind das nicht dasselbe — und in der Lücke dazwischen wohnt die Strafe.
Ich verlor den Schlaf über der Frage, ob "wahrscheinlich richtig" ein Produkt ist. Bei einer Frage der Formatierung ist es das. Bei einer Steuerposition, bei der die Genauigkeitsstrafe 20 % der Unterzahlung und die Betrugsstrafe 75 % beträgt, ist "wahrscheinlich richtig" eine Haftung, die man automatisiert und skaliert hat. Das war das Argument, das den Plan, GPT einfach einzupacken, beendete. Probabilistisch ist das falsche Werkzeug für eine deterministische Frage, egal wie gut die Wahrscheinlichkeiten werden.
Was bringt deterministische Verifikation eigentlich wirklich?
Die Anbieter, die das am besten verstehen, sind nicht die Chatbots — es sind die Engines für indirekte Steuern. Vertex pflegt über 300 Millionen Steuersätze. Avalara, das Ende 2025 eine Investition von 500 Mio. USD von BlackRock erhielt, und Sovos wickeln die Meldungen über mehr als 12.000 Rechtsordnungen hinweg ab. Für die von ihnen abgedeckten Szenarien sind sie zu 100 % deterministisch mit vollständigen Prüfpfaden. Stellt man ihnen tausendmal dieselbe Satzfrage, bekommt man tausendmal dieselbe Antwort, und man kann einem Prüfer genau zeigen, warum.
Doch diese Engines können keinen Satz lesen. Sie können nicht über einen Test nach Tatsachen und Umständen (facts-and-circumstances) urteilen, und eine neue Regel hinzuzufügen bedeutet, dass ein Mensch sie von Hand kodiert. So teilt sich das Feld sauber auf: Die Engines, die zuverlässig sind, können Sprache nicht verstehen, und die Systeme, die Sprache verstehen, sind nicht zuverlässig.
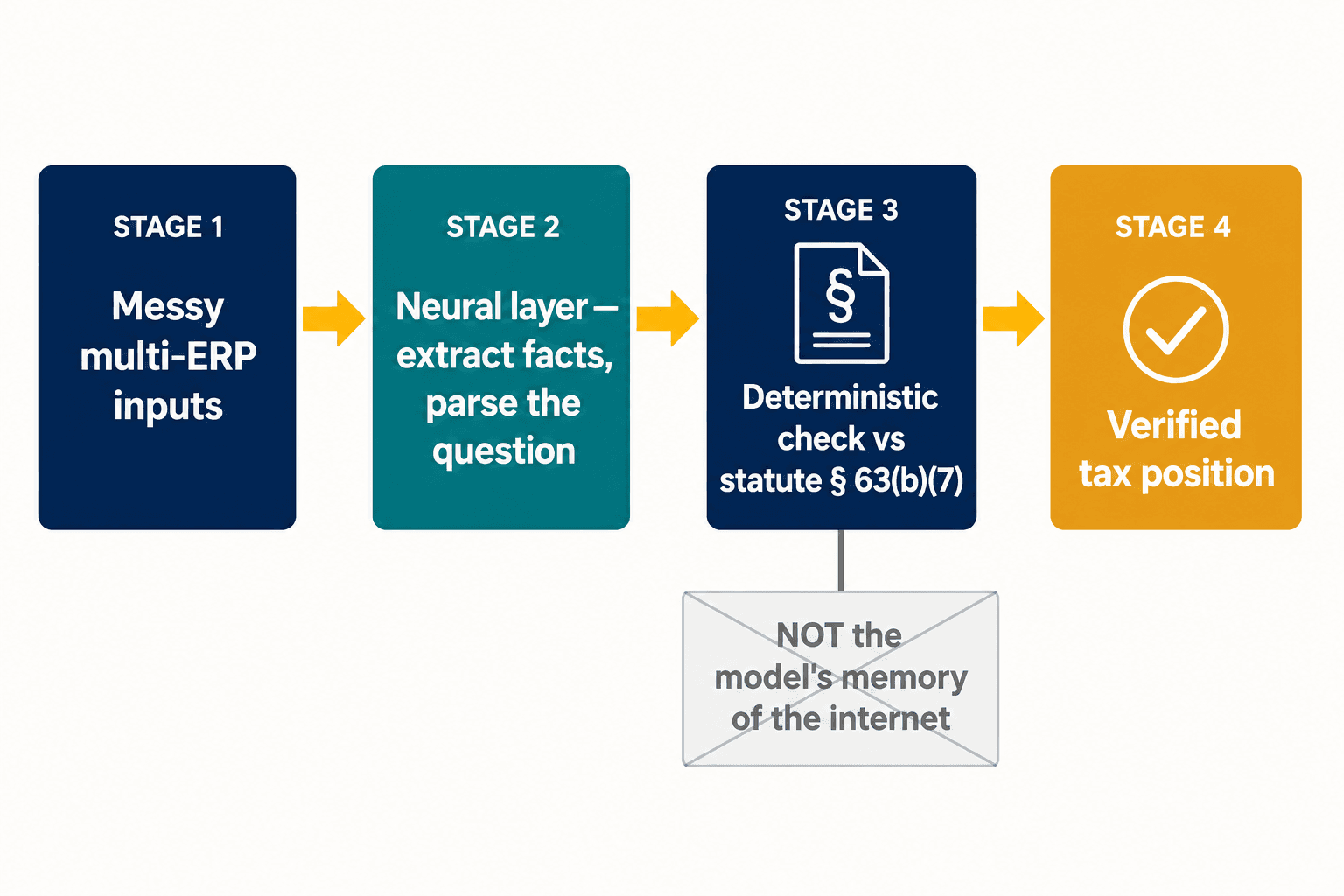
Diese Spaltung ist das gesamte Designproblem, und genau dort haben wir unsere Architektur verankert. Wir versuchen nicht, ein einziges Modell zugleich kreativ und sicher zu machen. Wir lassen eine neuronale Schicht das tun, worin neuronale Modelle gut sind — unordentliche Eingaben lesen, strukturierte Fakten aus einer Steuererklärung extrahieren, herausparsen, was ein Praktiker tatsächlich fragt. Dann wird für die Bestimmungen, bei denen Korrektheit nicht verhandelbar ist, die Antwort gegen eine deterministische Repräsentation des Gesetzes selbst geprüft, nicht gegen die Erinnerung des Modells daran, was das Internet darüber gesagt hat. Der Pkw-Darlehen-Abzug liegt below-the-line, weil Section 63(b)(7) das so sagt, Punkt — nicht, weil das Modell die Beweise abgewogen hat und die Beweise zufällig falsch waren.
Es geht nicht darum, Thomson Reuters oder Wolters Kluwer zu ersetzen. CCH Axcess Expert AI ist in 10.000 Kanzleien eingebettet; ONESOURCE beansprucht eine Reduzierung der Routine-Berichtszeit um 65 %. Diese Werkzeuge sind gut in der Erstellung, und die Erstellung ist inzwischen weitgehend ein gelöstes Problem. Die Verifikationsschicht sitzt über allem, was man bereits betreibt, herstellerneutral, und fängt die systematischen Fehler ab, bevor sie das IRS erreichen. Thomson Reuters verifiziert Thomson Reuters. Wolters Kluwer verifiziert Wolters Kluwer. Niemand verifizierte über all das hinweg, gegen die tatsächliche Wahrheit, für die Positionen, die wirklich Strafen nach sich ziehen.
Bei großen multinationalen Konzernen verschärft sich das Problem, noch bevor die KI überhaupt den Mund aufmacht. Rund 78 % der Unternehmen betreiben vier bis sieben verschiedene ERP-Systeme, und EY stellte fest, dass die Hälfte der Steuerverantwortlichen das Fehlen eines nachhaltigen Daten- und Technologieplans als ihr größtes Einzelhindernis nennt. Nimmt man Pillar Two hinzu — das globale Mindeststeuerregime, das Daten auf Entitätsebene und verlässliche konzerninterne Berichterstattung verlangt, worauf sich nur etwa 15 % der Organisationen in manchen Regionen als vollständig vorbereitet bezeichnen — dann ist das schwächste Glied gar nicht das Schlussfolgern des Modells; es ist die Frage, ob die strukturierten Fakten, die es speisen, überhaupt richtig sind. Das ist die andere Hälfte der Arbeit: die neuronale Extraktionsschicht, die unordentliche Eingaben aus mehreren Systemen in etwas verwandelt, dem entweder eine KI oder eine deterministische Engine vertrauen kann.
Warum ist Steuer-KI plötzlich eine Frage des Privilegs, nicht der Sicherheit?
Eine Zeit lang betrachtete ich die Anforderung eines geschlossenen Systems als Sicherheitspräferenz — nett zu haben, Unternehmenshygiene. Dann verkündete der SDNY im Februar 2026 das Heppner-Urteil, und es war nicht mehr optional.
Die Kurzfassung: Die Fakten eines Mandanten in ein öffentliches KI-Werkzeug einzufügen, kann das Anwaltsgeheimnis (attorney-client privilege) über diese Kommunikation aufheben. Für eine Steuerabteilung stellt das alles neu auf. Die Wahl zwischen einem öffentlichen Chatbot und einem geschlossenen, unternehmenskontrollierten System dreht sich nicht mehr um Datenhygiene — es geht darum, ob Ihre privilegierte Analyse privilegiert bleibt. Das IRS bekräftigte die Richtung in derselben Saison: Seine KI-Governance-Richtlinie, IRM 10.24.1, klassifiziert nun generative KI-Ausgaben, die als wesentliche Grundlage für eine Entscheidung mit rechtlicher oder materieller Wirkung dienen, als "high-impact" und verlangt verstärkte Aufsicht. Die Regulierungsbehörden sagen Ihnen in ihrer eigenen Sprache, dass eine nicht verifizierte KI-Steuerposition ein Risiko mit hoher Tragweite ist.
Nach Heppner ist die Architektur, die man für Steuer-KI wählt, eine Privilegentscheidung, bevor sie eine technische ist.
Dies ist kein hypothetischer Schaden. Accountancy Age berichtete im März 2026, dass die Hälfte der britischen Buchhalter von Unternehmen wusste, die durch falsche KI-Beratung direkte finanzielle Verluste erlitten. Forscher haben rund 800 Fälle von KI-Zitierfehlern in 25 Ländern dokumentiert. Zugleich erhöht das IRS seine Prüfquote bei großen Konzernen von 8,8 % in Richtung 22,6 %. Mehr KI-entworfene Positionen, mehr Prüfungen und eine Strafe, die den Unterzeichner trifft — das ist der Kollisionskurs.
Die Einwände, die ich am häufigsten höre
Man fragt mich, ob bessere Modelle das nicht einfach von selbst lösen werden. Werden sie nicht, und nicht, weil die Modelle sich nicht verbessern. Konsensfehler ist eine Eigenschaft der Daten, nicht der Modellgröße. Ein größeres Modell, das auf demselben falschen Internet trainiert wird, lernt die falsche Antwort flüssiger, nicht seltener. Man kann ein Problem, das mit einem mitwächst, nicht durch Skalierung überholen.
Das andere, was ich höre: Ist eine deterministische Schicht nicht einfach spröde, fest einkodierte Regeln, die mit 420 Gesetzesänderungen pro Jahr nicht Schritt halten können? Das wäre sie, wenn wir versuchten, den gesamten Code zu kodieren. Tun wir nicht. Die Verifikationsschicht zielt auf die Bestimmungen mit hohem Strafrisiko und hoher Kaskadenwirkung ab — die wenigen, bei denen selbstbewusst falsch zu liegen echtes Geld kostet — und überlässt die routinemäßigen neunzig Prozent den Erstellungswerkzeugen, die sie bereits gut bewältigen. Man braucht keine Gewissheit über alles. Man braucht Gewissheit über die Dinge, die einen beißen.
Und hin und wieder fragt jemand, warum eine Steuerabteilung dies selbst bauen sollte, statt auf einen der Big Four zu warten. EY strebt eine 80-prozentige Automatisierung der ausländischen Steuer-Compliance an; KPMG startete im Februar 2026 einen Tax AI Accelerator. Doch diese Werkzeuge sind für die eigenen Mandate der Firma gebaut, innerhalb von Projekten im sechs- und siebenstelligen Bereich verkauft, und sie verifizieren die Arbeit der Firma — nicht Ihre. Die Verifikationsschicht, die Sie tatsächlich kontrollieren, ist diejenige, die die Unterschrift schützt, die Sie tatsächlich leisten.
Was ich meinem früheren Ich sagen würde
Steuer-Compliance kostet US-Unternehmen mehr als 126 Milliarden USD pro Jahr, und die Branche tut recht daran, KI auf diese Zahl loszulassen. Die Erstellung sollte automatisiert werden. Der Fehler besteht darin anzunehmen, dass die Aufgabe erledigt ist, sobald die KI die Steuererklärung entwerfen kann — obwohl sich der Engpass in Wirklichkeit nur nachgelagert verschoben hat, hin zur Verifikation, wo er schwerer zu erkennen und teurer falsch zu machen ist.
Ich begann dies in dem Glauben, der schwierige Teil sei, einer Maschine das Steuerrecht beizubringen. Der schwierige Teil erwies sich als das Gegenteil: zu wissen, bei welchen Fragen eine Maschine niemals raten dürfen sollte, und die Schicht zu bauen, die sich weigert, sie das tun zu lassen. An dem Tag, an dem jedes Steuerwerkzeug auf KI läuft, bleibt nur eine wirkliche Frage übrig: Wer prüft die KI — und "dieselbe KI, nur höflicher gefragt" ist keine Antwort. Wenn Sie sehen möchten, wie wir diese Prüfung gebaut haben, hier entlang.
Das Internet lag bei einem Pkw-Darlehen-Abzug falsch, und jede Maschine, die daraus lernte, erbte den Fehler, ohne mit der Wimper zu zucken. Irgendwo im Steuerrecht warten Tausende weitere davon. Die Arbeit besteht nicht darin, KI klüger zu machen. Sie besteht darin, sicherzustellen, dass Ihre Steuerposition nicht falsch ist, wenn die ganze Welt selbstbewusst falsch liegt.