
Todas las IA tributarias que probé clasificaron mal la misma deducción, porque internet lo hizo
Tenía dos monitores abiertos. A la izquierda, la ley: la Sección 63(b)(7) del Internal Revenue Code, la disposición que el Omnibus Budget Reconciliation Act utilizó para crear una nueva deducción por los intereses de préstamos para vehículos de pasajeros elegibles. A la derecha, el propio sitio web de H&R Block, que describía esa misma deducción como un "incentivo por encima de la línea".
Esas dos pantallas no pueden tener razón a la vez. La Sección 63(b)(7) reduce la renta imponible: es una deducción por debajo de la línea. No afecta a la renta bruta ajustada. "Por encima de la línea" significa lo contrario. Una de las mayores marcas de preparación de impuestos de Estados Unidos tenía invertida la dirección de una deducción en su sitio público, y a fecha de abril de 2026 aún la tenía así.
Eso sería una nota al pie, de no ser por lo que ocurrió cuando empecé a preguntarle a la IA sobre ello. Planteé la cuestión a varios de los principales grandes modelos de lenguaje: las mismas herramientas de IA para el cumplimiento tributario que las firmas están integrando ahora en la preparación de declaraciones. Todos y cada uno de ellos me dijeron, con gramática impecable y una cita plausible, que la deducción era por encima de la línea. Todos habían leído el mismo internet. Y el internet estaba equivocado.
Cuando todas las IA te dan la misma respuesta equivocada, no es un fallo puntual. Son los datos de entrenamiento votando, y la verdad perdiendo.
Ese fue el momento en que la empresa que estaba construyendo cobró nitidez. La industria corría por lograr que la IA preparara las declaraciones de impuestos más rápido. Casi nadie estaba construyendo lo que la atrapa cuando la IA se equivoca con confianza y de forma sistemática. Esa brecha es la que la capa de verificación de IA para el cumplimiento tributario de Veriprajna existe para llenar.
El error que se propaga en cascada
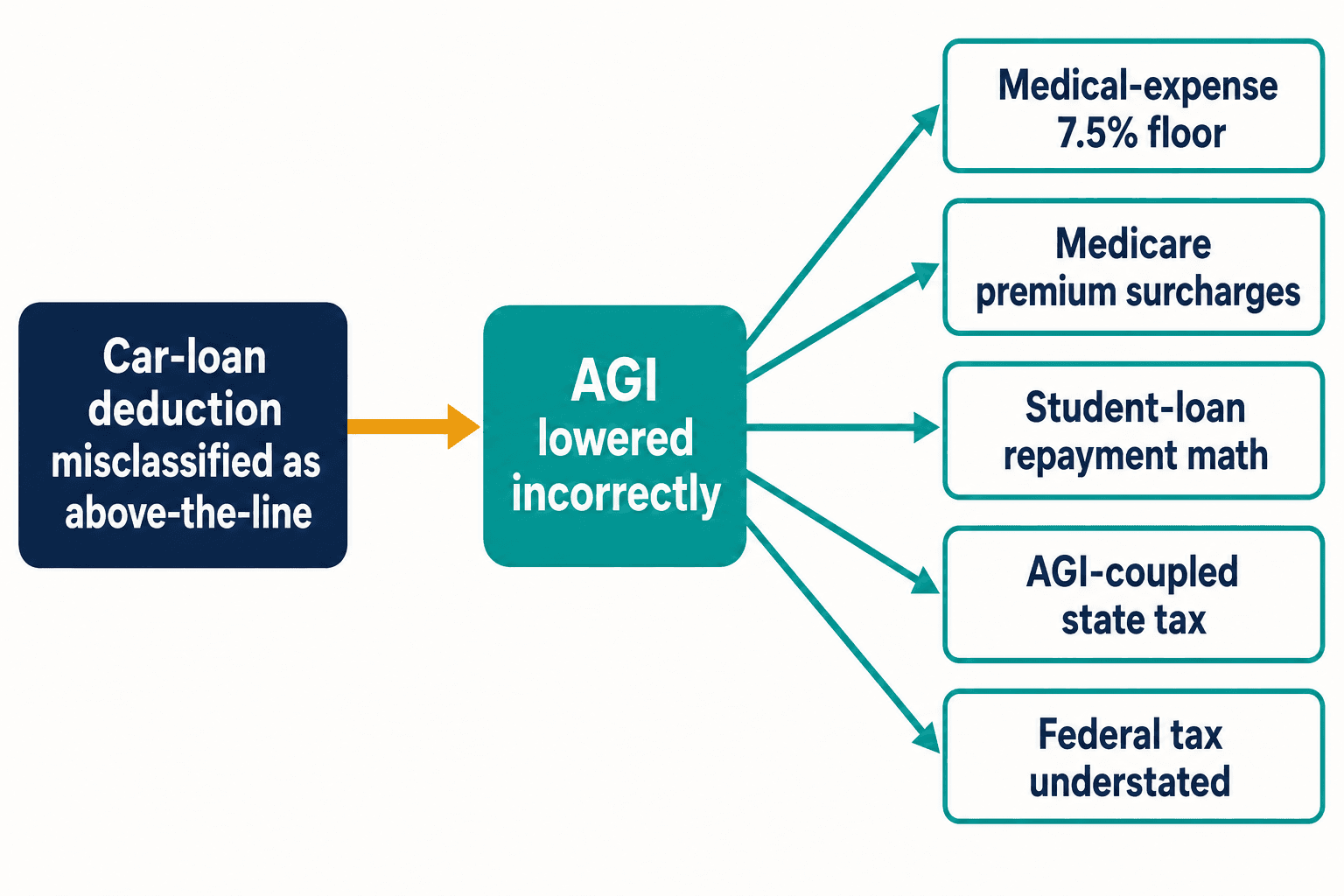
Aquí está el motivo por el que una sola deducción invertida me quitaba el sueño. Una clasificación errónea como la del préstamo para el coche no queda contenida. Trata esa deducción como por encima de la línea y reduces la renta bruta ajustada que nunca debió moverse. La AGI es un elemento de carga en el código tributario. Alimenta el umbral del 7,5 % para la deducción de gastos médicos. Alimenta los recargos de primas de Medicare vinculados a los ingresos. Alimenta el cálculo del reembolso basado en los ingresos de los préstamos estudiantiles. En los estados cuyo impuesto está acoplado a la AGI federal, también subestima silenciosamente el impuesto estatal.
Un token equivocado, cinco cálculos erróneos aguas abajo, y eso a partir de una sola disposición. El Internal Revenue Code tiene miles. El Congreso le hizo un promedio de 420 cambios al año entre 2000 y 2020, según el Taxpayer Advocate Service. Cada cambio nuevo es una oportunidad nueva para que la blogosfera llegue antes de que la orientación oficial se asiente, y para que la siguiente generación de modelos aprenda la versión equivocada por pura repetición.
Y quien paga no es el algoritmo. Cuando una declaración está mal, la sanción por precisión del 20 % conforme al manual del IRS recae sobre la persona cuyo nombre figura en la línea de la firma, firmada bajo pena de perjurio. El modelo que la redactó no tiene PTIN ni responsabilidad alguna. No dejaba de volver a esa asimetría. Estábamos a punto de entregar la redacción a las máquinas y dejar la exposición al riesgo en manos de las personas.
Por qué dejé de creer que la recuperación nos salvaría
Mi primer instinto fue el mismo que tiene todo el mundo: darle al modelo la ley de verdad. La generación aumentada por recuperación (RAG, donde el sistema busca la ley real y se la entrega al modelo antes de que responda) se suponía que era la solución. Blue J, que recaudó una Serie D de 122 millones de dólares, construyó exactamente esto: RAG sobre GPT-4.1, con una asociación con IBFD que abarca más de 220 jurisdicciones. Ingeniería seria, hecha por gente seria.
Así que construimos un prototipo de recuperación propio. Y lo vi recuperar el texto correcto de la Sección 63(b)(7), y luego resumirlo mal de todos modos.
Esa fue la demostración que rompió mi suposición. La recuperación funcionaba. La interpretación no. El lenguaje de las enmiendas en el código tributario se lee como "La Sección 163(h) se modifica insertando…": tienes que reconstruir el estado actual de la ley a partir de fragmentos, y un modelo cuyos pesos internos han absorbido millones de publicaciones de blog sobre "por encima de la línea" actúa como un lector sesgado. Ve la ley correcta y aun así oye el consenso equivocado. Entregarle a un motor de probabilidades el documento correcto no lo hace razonar; solo le da a una respuesta equivocada con confianza una cita de mejor aspecto.
La recuperación le consigue al modelo el texto correcto. No hace nada respecto a que el modelo ya se haya formado una opinión.
Empezamos a llamar a esto Error de Consenso: cuando toda la IA converge en la misma respuesta equivocada porque el registro público del que aprendió es en sí mismo erróneo. No es alucinación en el sentido habitual. Una alucinación es aleatoria. Esto es sistemático, repetible y compartido por todos los modelos entrenados en la web abierta. Esa distinción cambió mi forma de pensar sobre todo el problema.
"Simplemente envuelve GPT y lánzalo"
Hubo una temporada en la que genuinamente me pregunté si lo estaba complicando en exceso. Un asesor al que respeto me dijo, más o menos, que dejara de filosofar: envuelve un buen modelo, añade recuperación, lánzalo y deja que el mercado decida. Multitud de empresas bien financiadas estaban haciendo precisamente eso.
La discusión que tuvimos se redujo a una cifra que se cita constantemente: Blue J reporta una tasa de desacuerdo inferior a 1 de cada 700. Suena como una cifra de precisión. No lo es. Mide con qué frecuencia los usuarios no están de acuerdo con la herramienta, y un profesional que no conoce ya la respuesta correcta no puede estar en desacuerdo con una equivocada. La métrica calla justo donde vive el peligro: la respuesta segura, plausible y equivocada que nadie del otro lado tiene el conocimiento para rebatir.
Una tasa de desacuerdo mide la confianza de los usuarios, no la corrección del modelo. En una posición de alta sanción, esas no son la misma cosa, y la brecha entre ambas es donde vive la sanción.
Perdí el sueño por si "probablemente correcto" era un producto. En una cuestión de formato, lo es. En una posición tributaria donde la sanción por precisión es el 20 % del pago insuficiente y la sanción por fraude es el 75 %, "probablemente correcto" es una responsabilidad que has automatizado y escalado. Ese fue el argumento que puso fin al plan de envolver GPT. Lo probabilístico es la herramienta equivocada para una pregunta determinista, por buenas que lleguen a ser las probabilidades.
¿Qué te aporta realmente la verificación determinista?
Los proveedores que mejor entienden esto no son los chatbots, son los motores de impuestos indirectos. Vertex mantiene más de 300 millones de tasas impositivas. Avalara, que recibió una inversión de 500 millones de dólares de BlackRock a finales de 2025, y Sovos gestionan la presentación de declaraciones en más de 12.000 jurisdicciones. Para los escenarios que cubren, son 100 % deterministas, con rastros de auditoría completos. Hazles la misma pregunta sobre una tasa mil veces y obtienes la misma respuesta mil veces, y puedes mostrarle a un auditor exactamente por qué.
Pero esos motores no saben leer una frase. No pueden razonar sobre una prueba de hechos y circunstancias, y añadir una nueva regla significa que un humano la codifique a mano. Así que el campo se divide con nitidez: los motores que son fiables no pueden entender el lenguaje, y los sistemas que entienden el lenguaje no son fiables.
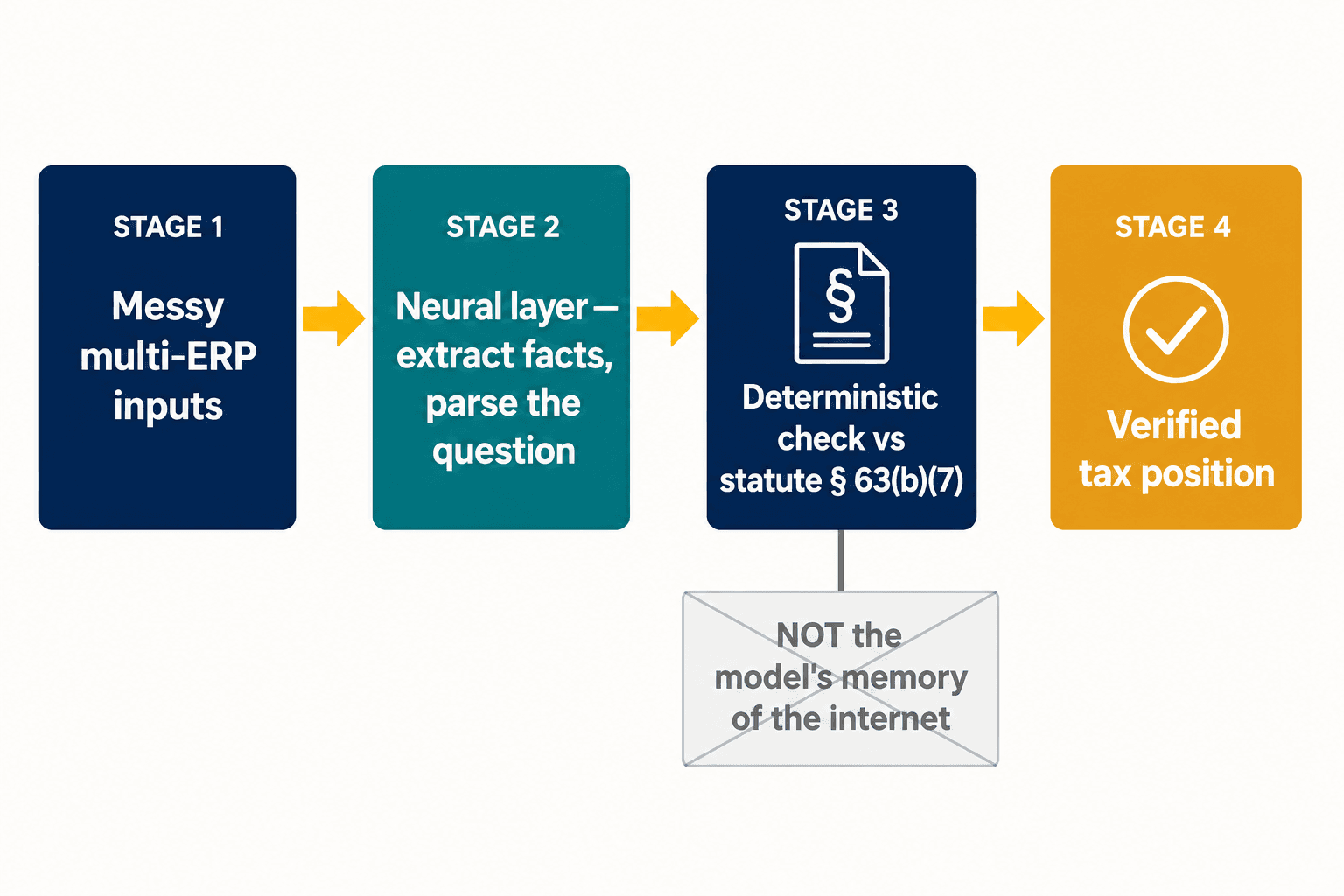
Esa división es todo el problema de diseño, y es donde aterrizó nuestra arquitectura. No intentamos que un solo modelo sea a la vez creativo y certero. Dejamos que una capa neuronal haga lo que los modelos neuronales hacen bien: leer entradas desordenadas, extraer hechos estructurados de una declaración, analizar qué está preguntando realmente un profesional. Luego, para las disposiciones donde la corrección es innegociable, la respuesta se comprueba contra una representación determinista de la ley misma, no contra la memoria del modelo sobre lo que dijo internet al respecto. La deducción del préstamo para el coche vive por debajo de la línea porque la Sección 63(b)(7) así lo dice, punto final, no porque el modelo sopesara las pruebas y las pruebas resultaran estar equivocadas.
El objetivo no es reemplazar a Thomson Reuters ni a Wolters Kluwer. CCH Axcess Expert AI está integrado en 10.000 firmas; ONESOURCE afirma una reducción del 65 % en el tiempo de generación de informes rutinarios. Esas herramientas son buenas en la preparación, y la preparación es en gran medida un problema ya resuelto ahora. La capa de verificación se sitúa por encima de lo que ya uses, es neutral respecto al proveedor y atrapa los errores sistemáticos antes de que lleguen al IRS. Thomson Reuters verifica a Thomson Reuters. Wolters Kluwer verifica a Wolters Kluwer. Nadie estaba verificando en el conjunto de todo ello, contra la verdad de base, para las posiciones que realmente acarrean sanciones.
Para las grandes multinacionales, el problema se agrava antes de que la IA siquiera abra la boca. Aproximadamente el 78 % de las empresas operan con entre cuatro y siete sistemas ERP distintos, y EY halló que la mitad de los líderes tributarios citan la falta de un plan sostenible de datos y tecnología como su mayor barrera individual. Súmale el Pilar Dos (el régimen de impuesto mínimo global que exige datos a nivel de entidad e informes intercompañía fiables, para el que solo alrededor del 15 % de las organizaciones en algunas regiones dicen estar plenamente preparadas) y el eslabón más débil no es en absoluto el razonamiento del modelo; es si los hechos estructurados que lo alimentan son correctos en primer lugar. Esa es la otra mitad del trabajo: la capa de extracción neuronal que convierte entradas desordenadas de múltiples sistemas en algo en lo que una IA o un motor determinista pueden confiar.
¿Por qué la IA tributaria se ha convertido de repente en una cuestión de secreto profesional, no de seguridad?
Durante un tiempo pensé en el requisito de un sistema cerrado como una preferencia de seguridad: algo deseable, higiene empresarial. Luego, en febrero de 2026, el SDNY dictó el fallo Heppner, y dejó de ser opcional.
La versión corta: pegar los datos de un cliente en una herramienta de IA pública puede renunciar al secreto profesional entre abogado y cliente sobre esas comunicaciones. Para un departamento tributario, eso lo replantea todo. La elección entre un chatbot público y un sistema cerrado y controlado por la empresa ya no trata de higiene de datos: trata de si tu análisis amparado por el secreto profesional sigue estando amparado. El IRS reforzó esa dirección la misma temporada: su política de gobernanza de IA, IRM 10.24.1, ahora clasifica los resultados de IA generativa que sirven como base principal de una decisión con efecto legal o material como "de alto impacto", exigiendo una supervisión reforzada. Los reguladores te están diciendo, en su propio lenguaje, que una posición tributaria de IA sin verificar es un riesgo de alto impacto.
Tras Heppner, la arquitectura que elijas para la IA tributaria es una decisión de secreto profesional antes de ser una decisión de ingeniería.
Este no es un daño hipotético. Accountancy Age informó en marzo de 2026 de que la mitad de los contadores del Reino Unido conocían empresas que habían sufrido pérdidas financieras directas a causa de asesoramiento incorrecto de la IA. Los investigadores han registrado aproximadamente 800 casos de errores de citación de IA en 25 países. Mientras tanto, el IRS está elevando su tasa de auditoría de grandes corporaciones del 8,8 % hacia el 22,6 %. Más posiciones redactadas por IA, más auditorías y una sanción que recae sobre quien firma: ese es el rumbo de colisión.
Las objeciones que más escucho
La gente me pregunta si los modelos mejores no resolverán esto por sí solos. No lo harán, y no porque los modelos no estén mejorando. El Error de Consenso es una propiedad de los datos, no del tamaño del modelo. Un modelo más grande entrenado con el mismo internet equivocado aprende la respuesta equivocada con más fluidez, no menos. No puedes superar por escala un problema que escala contigo.
La otra cosa que oigo: ¿no es una capa determinista simplemente reglas rígidas y codificadas a mano que no pueden seguir el ritmo de 420 cambios al código por año? Lo sería, si intentáramos codificar el código entero. No lo hacemos. La capa de verificación apunta a las disposiciones de alta sanción y alta cascada (el puñado en el que equivocarse con confianza cuesta dinero de verdad) y deja el noventa por ciento rutinario a las herramientas de preparación que ya lo manejan bien. No necesitas certeza sobre todo. Necesitas certeza sobre las cosas que muerden.
Y de vez en cuando alguien pregunta por qué un departamento tributario debería construir esto en lugar de esperar a una de las Big Four. EY apunta a un 80 % de automatización del cumplimiento tributario en el extranjero; KPMG lanzó un Tax AI Accelerator en febrero de 2026. Pero esas herramientas están construidas para los propios encargos de la firma, se venden dentro de proyectos de seis y siete cifras, y verifican el trabajo de la firma, no el tuyo. La capa de verificación que realmente controlas es la que protege la firma que realmente estampas.
Lo que le diría a mi yo anterior
El cumplimiento tributario les cuesta a las empresas estadounidenses más de 126.000 millones de dólares al año, y la industria hace bien en lanzarle IA a esa cifra. La preparación debería automatizarse. El error es asumir que, una vez que la IA puede redactar la declaración, el trabajo está hecho, cuando en realidad el cuello de botella simplemente se ha desplazado aguas abajo, a la verificación, donde es más difícil de ver y más caro de equivocarse.
Empecé esto pensando que la parte difícil era enseñarle a una máquina la ley tributaria. La parte difícil resultó ser lo contrario: saber qué preguntas nunca debería permitírsele a una máquina adivinar, y construir la capa que se niega a dejarla. El día en que toda herramienta tributaria funcione con IA, la única pregunta real que quedará es quién comprueba a la IA, y "la misma IA, preguntada con más cortesía" no es una respuesta. Si quieres ver cómo construimos esa comprobación, está aquí.
El internet se equivocó sobre una deducción por un préstamo para el coche, y toda máquina que aprendió de él heredó el error sin pestañear. En algún lugar del código hay miles más de esos, esperando. El trabajo no es hacer más inteligente a la IA. Es asegurarse de que, cuando el mundo entero se equivoca con confianza, tu posición tributaria no lo haga.