
Ogni AI fiscale che ho testato ha sbagliato la stessa detrazione — perché lo aveva fatto internet
Avevo due monitor aperti. A sinistra, la norma: la Sezione 63(b)(7) dell'Internal Revenue Code, la disposizione che l'Omnibus Budget Reconciliation Act ha usato per creare una nuova detrazione sugli interessi dei prestiti per veicoli passeggeri idonei. A destra, il sito di H&R Block, che descriveva quella stessa detrazione come un "incentivo above-the-line".
Quelle due schermate non possono avere ragione entrambe. La Sezione 63(b)(7) riduce il reddito imponibile — è una detrazione below-the-line. Non tocca il reddito lordo rettificato. "Above-the-line" significa l'opposto. Uno dei più grandi marchi di preparazione fiscale d'America aveva sbagliato la direzione di una detrazione sul proprio sito pubblico, e ad aprile 2026 era ancora così.
Sarebbe una nota a piè di pagina, se non fosse per ciò che è successo quando ho iniziato a interrogare l'AI a riguardo. Ho posto la domanda a diversi importanti large language model — gli stessi strumenti di AI per la compliance fiscale che gli studi stanno ora integrando nella preparazione delle dichiarazioni. Ognuno di essi mi ha detto, con grammatica impeccabile e una citazione plausibile, che la detrazione era above-the-line. Avevano tutti letto lo stesso internet. E internet aveva torto.
Quando ogni AI ti dà la stessa risposta sbagliata, non è un difetto tecnico. Sono i dati di addestramento che votano, ed è la verità che perde.
È stato in quel momento che l'azienda che stavo costruendo ha preso forma. Il settore correva per far preparare all'AI le dichiarazioni fiscali più velocemente. Quasi nessuno stava costruendo ciò che la coglie in fallo quando l'AI è sistematicamente e con sicurezza in errore. Quella lacuna è ciò che il livello di verifica dell'AI per la compliance fiscale di Veriprajna esiste per colmare.
L'errore che si propaga a cascata
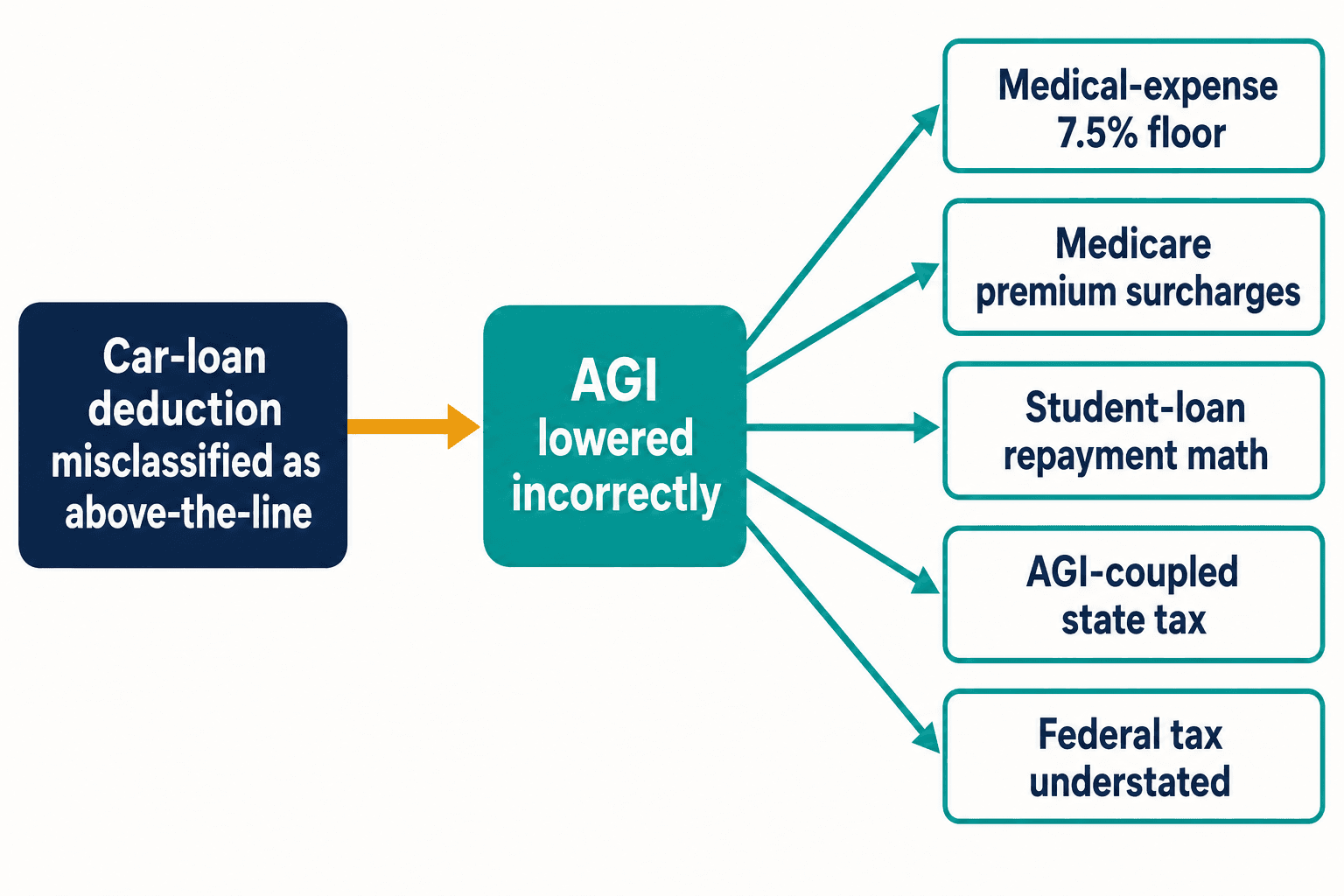
Ecco perché una singola detrazione invertita mi ha tolto il sonno. Una classificazione errata come quella del prestito auto non resta circoscritta. Tratta quella detrazione come above-the-line e abbassi il reddito lordo rettificato che non avrebbe mai dovuto muoversi. L'AGI è portante nel codice fiscale. Alimenta la soglia del 7,5% per la detrazione delle spese mediche. Alimenta le maggiorazioni dei premi Medicare legate al reddito. Alimenta il calcolo del rimborso basato sul reddito dei prestiti studenteschi. Negli stati la cui imposta è agganciata all'AGI federale, sottostima silenziosamente anche l'imposta statale.
Un token sbagliato, cinque errori di calcolo a valle — e questo da una singola disposizione. L'Internal Revenue Code ne ha migliaia. Il Congresso vi ha apportato in media 420 modifiche l'anno tra il 2000 e il 2020, secondo il Taxpayer Advocate Service. Ogni nuova modifica è una nuova occasione perché la blogosfera arrivi prima che la guida ufficiale si assesti, e perché la prossima generazione di modelli apprenda la versione sbagliata per pura ripetizione.
E chi paga non è l'algoritmo. Quando una dichiarazione è sbagliata, la sanzione del 20% relativa all'accuratezza prevista dal manuale dell'IRS ricade sull'essere umano il cui nome è sulla riga della firma, apposta sotto pena di falsa dichiarazione. Il modello che l'ha redatta non ha PTIN né responsabilità. Continuavo a tornare su quell'asimmetria. Stavamo per affidare la stesura alle macchine e lasciare l'esposizione alle persone.
Perché ho smesso di credere che il retrieval ci avrebbe salvato
Il mio primo istinto è stato lo stesso di chiunque: dare in pasto al modello la legge vera. La retrieval-augmented generation — RAG, in cui il sistema consulta la norma reale e la fornisce al modello prima che risponda — avrebbe dovuto essere la soluzione. Blue J, che ha raccolto un Series D da 122 milioni di dollari, ha costruito esattamente questo: RAG sopra GPT-4.1, con una partnership IBFD che copre oltre 220 giurisdizioni. Ingegneria seria di persone serie.
Così abbiamo costruito un nostro prototipo di retrieval. E l'ho visto recuperare il testo corretto della Sezione 63(b)(7) — e poi riassumerlo comunque in modo sbagliato.
È stata quella la demo che ha demolito la mia assunzione. Il retrieval funzionava. L'interpretazione no. Il linguaggio degli emendamenti nel codice fiscale suona come "La Sezione 163(h) è modificata inserendo…" — devi ricostruire lo stato attuale della legge a partire da frammenti, e un modello i cui pesi interni hanno assorbito milioni di post di blog che dicono "above-the-line" agisce da lettore prevenuto. Vede la norma giusta e sente comunque il consenso sbagliato. Consegnare a un motore probabilistico il documento corretto non lo fa ragionare; dà solo a una risposta sbagliata con sicurezza una citazione dall'aspetto migliore.
Il retrieval procura al modello il testo giusto. Non fa nulla riguardo al fatto che il modello si sia già fatto un'idea.
Abbiamo iniziato a chiamarlo Errore di consenso — quando ogni AI converge sulla stessa risposta sbagliata perché il registro pubblico da cui ha imparato è esso stesso sbagliato. Non è allucinazione nel senso consueto. Un'allucinazione è casuale. Questo è sistematico, ripetibile e condiviso da ogni modello addestrato sul web aperto. Quella distinzione ha cambiato il modo in cui ho pensato all'intero problema.
"Basta impacchettare GPT e spedirlo"
C'è stato un periodo in cui mi sono davvero chiesto se non stessi complicando le cose. Un consulente che stimo mi disse, più o meno, di smetterla di filosofeggiare — impacchetta un buon modello, aggiungi il retrieval, spediscilo, lascia decidere al mercato. Parecchie aziende ben finanziate stavano facendo esattamente questo.
La discussione che avemmo si ridusse a un numero che viene citato di continuo: Blue J riporta un tasso di disaccordo inferiore a 1 su 700. Sembra una cifra sull'accuratezza. Non lo è. Misura quanto spesso gli utenti non sono d'accordo con lo strumento — e un professionista che non conosce già la risposta corretta non può dissentire da una sbagliata. La metrica tace proprio dove vive il pericolo: la risposta sicura, plausibile e sbagliata che nessuno dall'altra parte ha le conoscenze per contestare.
Un tasso di disaccordo misura la fiducia degli utenti, non la correttezza del modello. Su una posizione ad alta sanzione, non sono la stessa cosa — e il divario tra le due è dove vive la sanzione.
Ho perso il sonno chiedendomi se "probabilmente giusto" fosse un prodotto. Su una questione di formattazione, lo è. Su una posizione fiscale in cui la sanzione per accuratezza è il 20% del pagamento insufficiente e la sanzione per frode è il 75%, "probabilmente giusto" è una responsabilità che hai automatizzato e scalato. È stato quell'argomento a mettere fine al piano impacchetta-GPT. Il probabilistico è lo strumento sbagliato per una domanda deterministica, per quanto buone diventino le probabilità.
Cosa ti garantisce davvero la verifica deterministica?
I fornitori che lo capiscono meglio non sono i chatbot — sono i motori di imposta indiretta. Vertex mantiene oltre 300 milioni di aliquote fiscali. Avalara, che ha ricevuto un investimento da 500 milioni di dollari da BlackRock alla fine del 2025, e Sovos gestiscono le dichiarazioni in più di 12.000 giurisdizioni. Per gli scenari che coprono, sono deterministici al 100% con piste di controllo complete. Poni loro la stessa domanda su un'aliquota mille volte e ottieni la stessa risposta mille volte, e puoi mostrare a un revisore esattamente il perché.
Ma quei motori non sanno leggere una frase. Non sanno ragionare su un test di fatti e circostanze, e aggiungere una nuova regola significa che un essere umano deve codificarla a mano. Così il campo si divide nettamente: i motori che sono affidabili non sanno comprendere il linguaggio, e i sistemi che comprendono il linguaggio non sono affidabili.
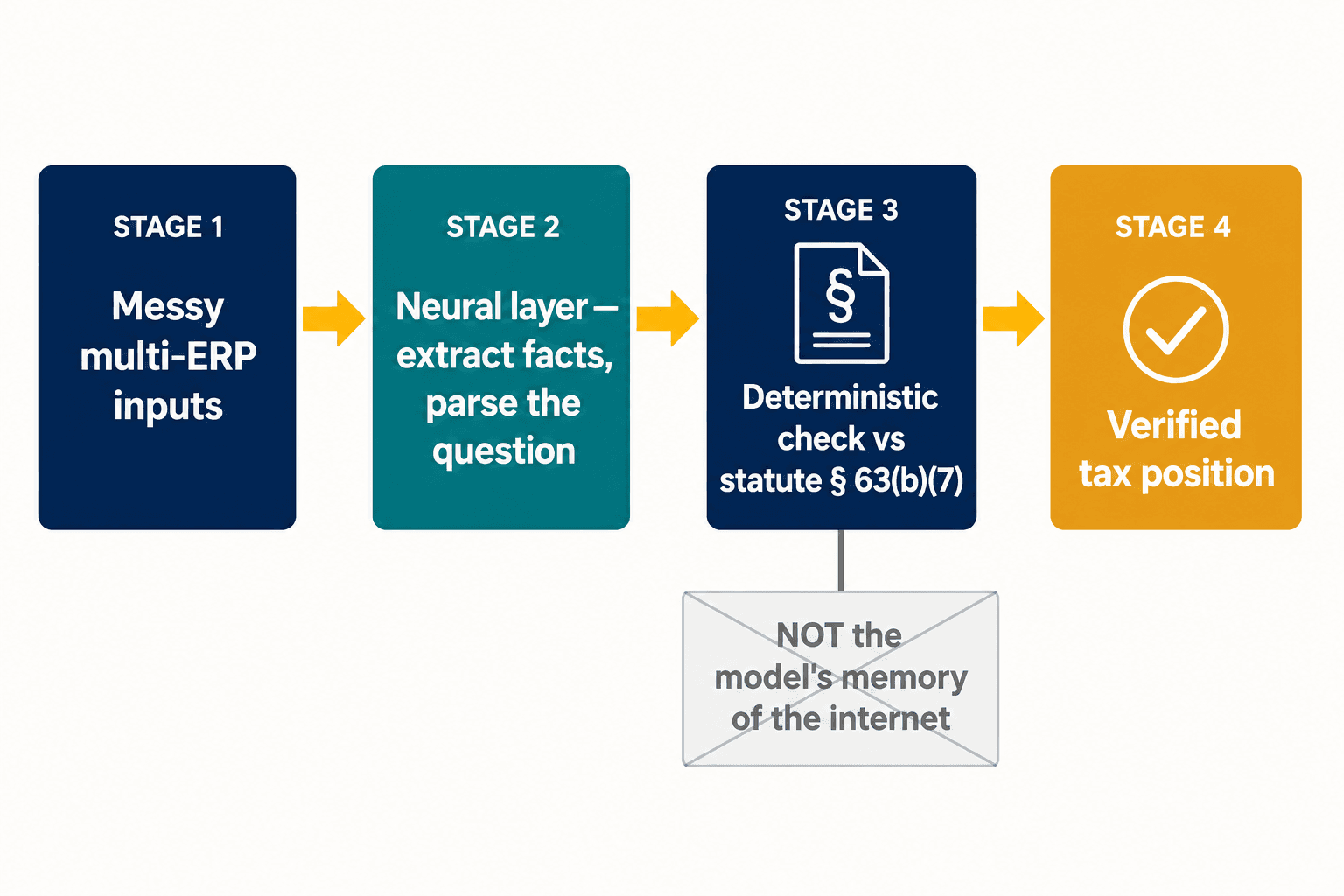
Quella divisione è l'intero problema di progettazione, ed è lì che abbiamo collocato la nostra architettura. Non cerchiamo di rendere un solo modello sia creativo sia certo. Lasciamo che un livello neurale faccia ciò in cui i modelli neurali sono bravi — leggere input disordinati, estrarre fatti strutturati da una dichiarazione, interpretare ciò che un professionista sta effettivamente chiedendo. Poi, per le disposizioni in cui la correttezza è irrinunciabile, la risposta viene controllata rispetto a una rappresentazione deterministica della norma stessa, non rispetto alla memoria del modello di ciò che internet diceva a riguardo. La detrazione del prestito auto vive below-the-line perché la Sezione 63(b)(7) lo dice, punto — non perché il modello abbia pesato le prove e le prove si siano rivelate sbagliate.
Il punto non è sostituire Thomson Reuters o Wolters Kluwer. CCH Axcess Expert AI è integrato in 10.000 studi; ONESOURCE afferma una riduzione del 65% dei tempi di rendicontazione ordinaria. Quegli strumenti sono bravi nella preparazione, e la preparazione è ormai un problema in gran parte risolto. Il livello di verifica si colloca al di sopra di qualunque cosa tu già utilizzi, indipendente dal fornitore, e coglie gli errori sistematici prima che raggiungano l'IRS. Thomson Reuters verifica Thomson Reuters. Wolters Kluwer verifica Wolters Kluwer. Nessuno verificava attraverso tutto quanto, rispetto alla verità di fatto, per le posizioni che comportano davvero delle sanzioni.
Per le grandi multinazionali il problema si aggrava prima ancora che l'AI apra bocca. Circa il 78% delle aziende utilizza da quattro a sette diversi sistemi ERP, ed EY ha rilevato che metà dei responsabili fiscali cita la mancanza di un piano sostenibile in materia di dati e tecnologia come il proprio ostacolo maggiore in assoluto. Aggiungici il Pillar Two — il regime di imposta minima globale che richiede dati a livello di entità e una rendicontazione infragruppo affidabile, per cui solo circa il 15% delle organizzazioni in alcune regioni dichiara di essere pienamente pronto — e l'anello più debole non è affatto il ragionamento del modello; è se i fatti strutturati che lo alimentano siano corretti in partenza. Questa è l'altra metà del lavoro: il livello di estrazione neurale che trasforma input disordinati provenienti da più sistemi in qualcosa di cui un'AI o un motore deterministico può fidarsi.
Perché l'AI fiscale è diventata all'improvviso una questione di segreto professionale, non di sicurezza?
Per un po' ho pensato al requisito del sistema chiuso come a una preferenza di sicurezza — piacevole da avere, igiene aziendale. Poi, a febbraio 2026, la SDNY ha emesso la sentenza Heppner, e ha smesso di essere facoltativo.
In breve: incollare i fatti di un cliente in uno strumento di AI pubblico può far decadere il segreto professionale tra avvocato e cliente su quelle comunicazioni. Per un ufficio fiscale, questo ridefinisce tutto. La scelta tra un chatbot pubblico e un sistema chiuso e controllato dall'azienda non riguarda più l'igiene dei dati — riguarda se la tua analisi riservata resti riservata. L'IRS ha rafforzato la direzione nella stessa stagione: la sua politica di governance dell'AI, l'IRM 10.24.1, ora classifica gli output di AI generativa che fungono da base principale per una decisione con effetto legale o materiale come "ad alto impatto", richiedendo una supervisione rafforzata. I regolatori ti stanno dicendo, nel loro linguaggio, che una posizione fiscale generata dall'AI e non verificata è un rischio ad alto impatto.
Dopo Heppner, l'architettura che scegli per l'AI fiscale è una decisione sul segreto professionale prima di essere una decisione ingegneristica.
Non è un danno ipotetico. Accountancy Age ha riferito a marzo 2026 che metà dei commercialisti britannici era a conoscenza di aziende che avevano subìto perdite finanziarie dirette a causa di consulenze errate fornite dall'AI. I ricercatori hanno registrato circa 800 casi di errori di citazione dell'AI in 25 paesi. Nel frattempo l'IRS sta aumentando il proprio tasso di verifica delle grandi imprese dall'8,8% verso il 22,6%. Più posizioni redatte dall'AI, più verifiche, e una sanzione che ricade sul firmatario — questa è la rotta di collisione.
Le obiezioni che sento più spesso
Le persone mi chiedono se modelli migliori risolveranno tutto da soli. Non lo faranno, e non perché i modelli non stiano migliorando. L'errore di consenso è una proprietà dei dati, non della dimensione del modello. Un modello più grande addestrato sullo stesso internet sbagliato apprende la risposta sbagliata con più scioltezza, non meno. Non puoi superare con la scala un problema che scala insieme a te.
L'altra cosa che sento: un livello deterministico non è forse solo un insieme di regole rigide e cablate a mano, incapace di stare al passo con 420 modifiche al codice l'anno? Lo sarebbe, se cercassimo di codificare l'intero codice. Non lo facciamo. Il livello di verifica prende di mira le disposizioni ad alta sanzione e ad alta cascata — quella manciata in cui sbagliare con sicurezza costa denaro vero — e lascia il novanta per cento di routine agli strumenti di preparazione che già lo gestiscono bene. Non hai bisogno di certezza su tutto. Hai bisogno di certezza sulle cose che mordono.
E ogni tanto qualcuno chiede perché un ufficio fiscale dovrebbe costruire questo invece di aspettare una delle Big Four. EY punta all'80% di automazione della compliance fiscale estera; KPMG ha lanciato un Tax AI Accelerator a febbraio 2026. Ma quegli strumenti sono costruiti per gli incarichi dello studio stesso, venduti all'interno di progetti da sei e sette cifre, e verificano il lavoro dello studio — non il tuo. Il livello di verifica che controlli davvero è quello che protegge la firma che apponi davvero.
Cosa direi a me stesso di un tempo
La compliance fiscale costa alle imprese statunitensi più di 126 miliardi di dollari l'anno, e il settore fa bene a scagliare l'AI contro quel numero. La preparazione dovrebbe essere automatizzata. L'errore è presumere che, una volta che l'AI può redigere la dichiarazione, il lavoro sia finito — quando in realtà il collo di bottiglia si è appena spostato a valle, alla verifica, dove è più difficile da vedere e più costoso da sbagliare.
Ho iniziato pensando che la parte difficile fosse insegnare la legge fiscale a una macchina. La parte difficile si è rivelata l'opposto: sapere su quali domande a una macchina non dovrebbe mai essere permesso di tirare a indovinare, e costruire il livello che si rifiuta di lasciarglielo fare. Il giorno in cui ogni strumento fiscale funzionerà con l'AI, l'unica vera domanda che resterà è chi controlla l'AI — e "la stessa AI, interrogata più gentilmente" non è una risposta. Se vuoi vedere come abbiamo costruito quel controllo, è qui.
Internet aveva torto su una detrazione per un prestito auto, e ogni macchina che ha imparato da esso ha ereditato l'errore senza battere ciglio. Da qualche parte nel codice ce ne sono migliaia di altri, in attesa. Il lavoro non consiste nel rendere l'AI più intelligente. Consiste nell'assicurarsi che, quando il mondo intero sbaglia con sicurezza, la tua posizione fiscale non lo faccia.