
Elke tax AI die ik testte had dezelfde aftrek verkeerd — omdat het internet dat ook had
Ik had twee monitoren open staan. Links de wettekst: Internal Revenue Code Section 63(b)(7), de bepaling die de Omnibus Budget Reconciliation Act gebruikte om een nieuwe aftrek te creëren voor rente op leningen voor gekwalificeerde personenvoertuigen. Rechts de eigen website van H&R Block, die diezelfde aftrek beschreef als een "above-the-line incentive."
Die twee schermen kunnen niet allebei kloppen. Section 63(b)(7) verlaagt het belastbaar inkomen — het is een below-the-line aftrek. Het raakt het adjusted gross income niet. "Above-the-line" betekent het tegenovergestelde. Een van de grootste merken voor belastingaangifte in Amerika had de richting van een aftrek verkeerd om op zijn openbare site staan, en per april 2026 was dat nog steeds zo.
Dat zou een voetnoot zijn, ware het niet wat er gebeurde toen ik AI erover begon te vragen. Ik legde de vraag voor aan verschillende toonaangevende grote taalmodellen — dezelfde tax compliance AI-tools die bedrijven nu inbouwen in het opstellen van aangiften. Ieder van hen vertelde me, met vlekkeloze grammatica en een plausibele bronvermelding, dat de aftrek above-the-line was. Ze hadden allemaal hetzelfde internet gelezen. En het internet had het mis.
Wanneer elke AI je hetzelfde foute antwoord geeft, is het geen storing. Het zijn de trainingsdata die stemmen, en de waarheid die verliest.
Dat was het moment waarop het bedrijf dat ik aan het opbouwen was scherp in beeld kwam. De sector racete om AI belastingaangiften sneller te laten opstellen. Vrijwel niemand bouwde datgene wat het opvangt wanneer de AI zelfverzekerd en systematisch fout zit. Die kloof is wat Veriprajna's tax compliance AI-verificatielaag bestaat om op te vullen.
De fout die zich voortplant
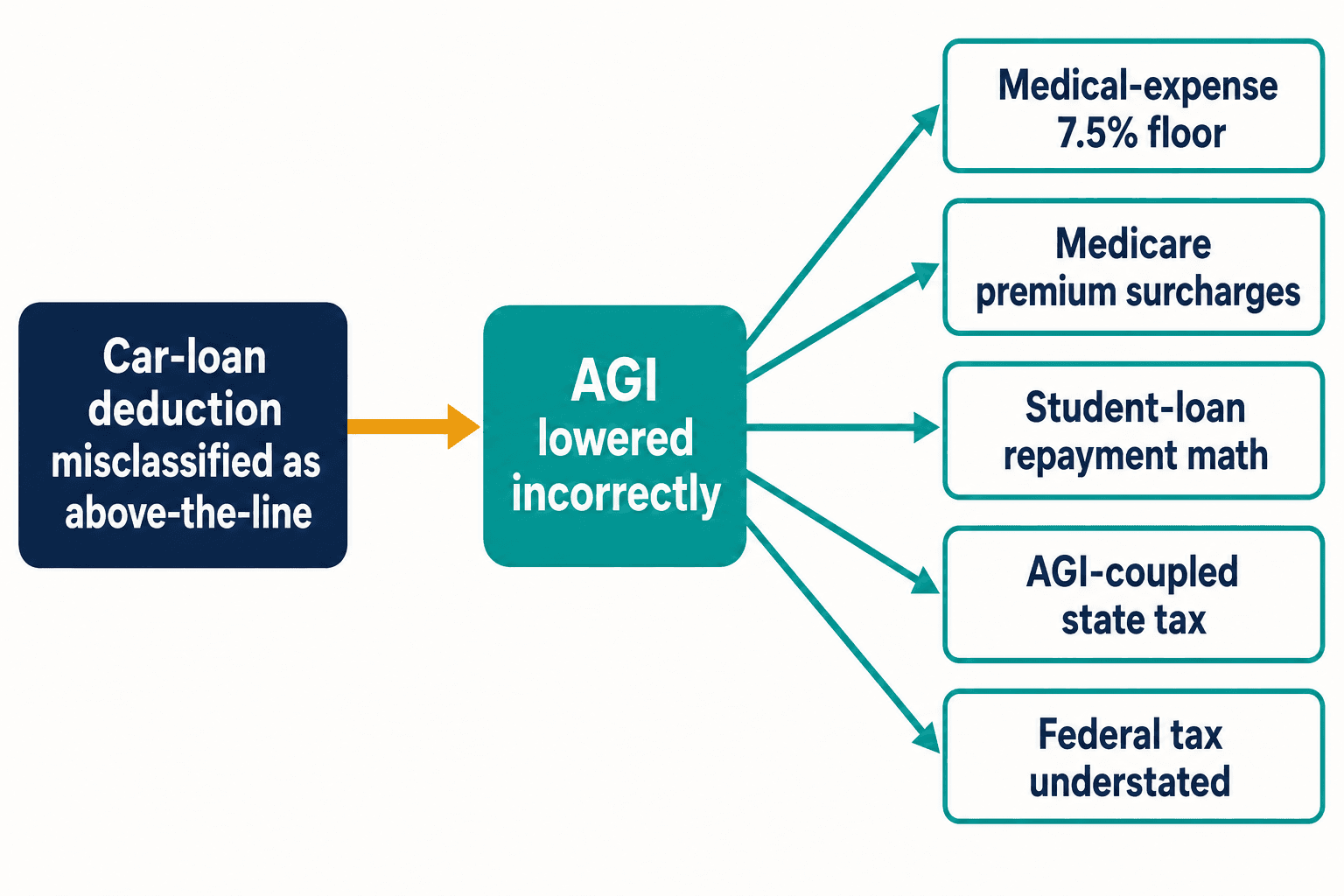
Dit is waarom één omgekeerde aftrek me wakker hield. Een verkeerde classificatie zoals die van de autolening blijft niet beperkt. Behandel die aftrek als above-the-line en je verlaagt het adjusted gross income dat nooit had mogen bewegen. AGI is dragend in het belastingstelsel. Het voedt de aftrekdrempel voor medische kosten van 7,5%. Het voedt Medicare's inkomensgerelateerde premietoeslagen. Het voedt de op inkomen gebaseerde terugbetalingsberekening van studieleningen. In staten waarvan de belasting gekoppeld is aan het federale AGI onderschat het ook stilzwijgend de staatsbelasting.
Één verkeerde token, vijf stroomafwaartse rekenfouten — en dat is nog maar van één enkele bepaling. De Internal Revenue Code heeft er duizenden. Het Congres bracht er tussen 2000 en 2020 gemiddeld 420 wijzigingen per jaar in aan, aldus de Taxpayer Advocate Service. Elke nieuwe wijziging is een nieuwe kans voor de blogosfeer om er te zijn voordat de officiële richtlijnen zijn uitgekristalliseerd, en voor de volgende generatie modellen om de verkeerde versie te leren door pure herhaling.
En degene die betaalt is niet het algoritme. Wanneer een aangifte fout is, komt de nauwkeurigheidsboete van 20% volgens het IRS-handboek terecht bij de mens wiens naam op de handtekeningregel staat, ondertekend op straffe van meineed. Het model dat de aangifte opstelde heeft geen PTIN en geen aansprakelijkheid. Ik bleef terugkomen op die asymmetrie. We stonden op het punt het opstellen aan machines over te laten en het risico bij mensen te laten liggen.
Waarom ik geloof opgaf dat retrieval ons zou redden
Mijn eerste ingeving was dezelfde die iedereen heeft: geef het model de daadwerkelijke wet. Retrieval-augmented generation — RAG, waarbij het systeem de echte wettekst opzoekt en aan het model overhandigt voordat het antwoordt — zou de oplossing zijn. Blue J, dat een Series D van $122M ophaalde, bouwde precies dit: RAG bovenop GPT-4.1, met een IBFD-partnerschap dat 220+ rechtsgebieden omspant. Serieus ingenieurswerk door serieuze mensen.
Dus bouwden we een eigen retrieval-prototype. En ik zag hoe het de juiste tekst van Section 63(b)(7) ophaalde — en die vervolgens toch verkeerd samenvatte.
Dat was de demo die mijn aanname deed sneuvelen. De retrieval werkte. De interpretatie niet. Wijzigingstaal in het belastingstelsel leest als "Section 163(h) is amended by inserting…" — je moet de huidige stand van de wet uit fragmenten reconstrueren, en een model waarvan de interne gewichten miljoenen "above-the-line" blogposts hebben opgezogen fungeert als een bevooroordeelde lezer. Het ziet de juiste wettekst en hoort toch de verkeerde consensus. Een kansengine het juiste document overhandigen zorgt er niet voor dat het redeneert; het geeft een zelfverzekerd fout antwoord alleen maar een mooier ogende bronvermelding.
Retrieval bezorgt het model de juiste tekst. Het doet niets aan het feit dat het model zijn oordeel al heeft gevormd.
We begonnen dit Consensusfout te noemen — wanneer elke AI convergeert naar hetzelfde foute antwoord omdat de openbare bron waarvan het leerde zelf fout is. Het is geen hallucinatie in de gebruikelijke zin. Een hallucinatie is willekeurig. Dit is systematisch, herhaalbaar en gedeeld door elk model dat op het open web is getraind. Dat onderscheid veranderde hoe ik over het hele probleem dacht.
"Wrap gewoon GPT en breng het uit"
Er was een periode waarin ik me oprecht afvroeg of ik het te ingewikkeld maakte. Een adviseur die ik respecteer zei me, min of meer, om te stoppen met filosoferen — wrap een goed model, voeg retrieval toe, breng het uit, en laat de markt beslissen. Talloze goed gefinancierde bedrijven deden precies dat.
Het meningsverschil dat we hadden kwam neer op één getal dat voortdurend wordt geciteerd: Blue J rapporteert een disagree rate van minder dan 1 op 700. Het klinkt als een nauwkeurigheidscijfer. Dat is het niet. Het meet hoe vaak gebruikers het oneens zijn met de tool — en een professional die het juiste antwoord nog niet kent, kan het niet oneens zijn met een fout antwoord. De maatstaf zwijgt precies daar waar het gevaar zit: het zelfverzekerde, plausibele, foute antwoord dat niemand aan de andere kant de kennis heeft om aan te vechten.
Een disagreement rate meet het vertrouwen van de gebruikers, niet de correctheid van het model. Bij een positie met een hoge boete zijn dat niet hetzelfde — en de kloof daartussen is waar de boete zit.
Ik lag wakker over de vraag of "waarschijnlijk juist" een product was. Bij een kwestie van opmaak is dat zo. Bij een fiscale positie waar de nauwkeurigheidsboete 20% van de te weinig betaalde belasting is en de fraudeboete 75%, is "waarschijnlijk juist" een aansprakelijkheid die je hebt geautomatiseerd en opgeschaald. Dat was het argument dat een einde maakte aan het wrap-GPT-plan. Probabilistisch is het verkeerde gereedschap voor een deterministische vraag, hoe goed de kansen ook worden.
Wat levert deterministische verificatie je nu eigenlijk op?
De leveranciers die dit het best begrijpen zijn niet de chatbots — het zijn de engines voor indirecte belastingen. Vertex onderhoudt meer dan 300 miljoen belastingtarieven. Avalara, dat eind 2025 een investering van $500M van BlackRock kreeg, en Sovos verzorgen aangiften in meer dan 12.000 rechtsgebieden. Voor de scenario's die zij dekken zijn ze 100% deterministisch met volledige audit trails. Stel hun duizend keer dezelfde tariefvraag en je krijgt duizend keer hetzelfde antwoord, en je kunt een auditor precies laten zien waarom.
Maar die engines kunnen geen zin lezen. Ze kunnen niet redeneren over een facts-and-circumstances-toets, en een nieuwe regel toevoegen betekent dat een mens die met de hand moet coderen. Zo splitst het veld zich netjes: de engines die betrouwbaar zijn kunnen geen taal begrijpen, en de systemen die taal begrijpen zijn niet betrouwbaar.
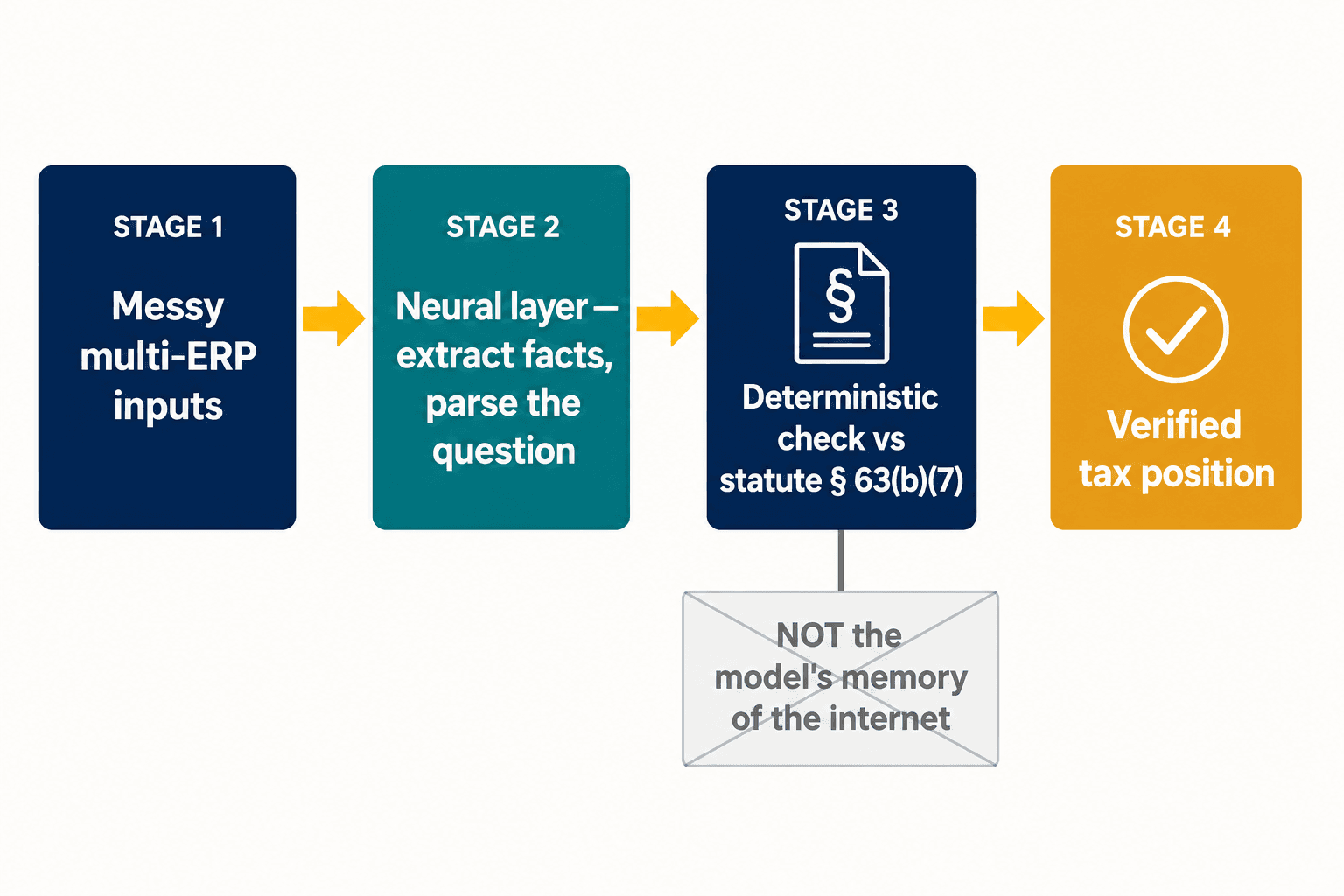
Die splitsing is het hele ontwerpprobleem, en het is waar we onze architectuur op lieten neerkomen. We proberen niet om één model tegelijk creatief én zeker te maken. We laten een neurale laag doen waar neurale modellen goed in zijn — rommelige invoer lezen, gestructureerde feiten uit een aangifte extraheren, ontleden wat een professional werkelijk vraagt. Vervolgens wordt, voor de bepalingen waar correctheid niet onderhandelbaar is, het antwoord gecontroleerd tegen een deterministische weergave van de wettekst zelf, niet tegen het geheugen van het model van wat het internet erover zei. De autolening-aftrek staat below the line omdat Section 63(b)(7) dat zegt, punt uit — niet omdat het model het bewijs afwoog en het bewijs toevallig fout was.
Het doel is niet om Thomson Reuters of Wolters Kluwer te vervangen. CCH Axcess Expert AI is ingebed bij 10.000 kantoren; ONESOURCE claimt een reductie van 65% in de tijd voor routinerapportage. Die tools zijn goed in het opstellen, en het opstellen is nu grotendeels een opgelost probleem. De verificatielaag zit bovenop wat je al draait, leveranciersneutraal, en vangt de systematische fouten op voordat ze de IRS bereiken. Thomson Reuters verifieert Thomson Reuters. Wolters Kluwer verifieert Wolters Kluwer. Niemand verifieerde over het geheel heen, tegen de grondwaarheid, voor de posities die daadwerkelijk boetes met zich meebrengen.
Voor grote multinationals stapelt het probleem zich op nog voordat de AI zijn mond opendoet. Ongeveer 78% van de bedrijven draait vier tot zeven verschillende ERP-systemen, en EY constateerde dat de helft van de belastingleiders het ontbreken van een duurzaam data- en technologieplan noemt als hun grootste enkele belemmering. Voeg daar Pillar Two aan toe — het wereldwijde minimumbelastingregime dat gegevens op entiteitsniveau en betrouwbare intercompany-rapportage vereist, waar in sommige regio's slechts ongeveer 15% van de organisaties zegt volledig klaar voor te zijn — en de zwakste schakel is helemaal niet het redeneren van het model; het is of de gestructureerde feiten die het voeden om te beginnen wel juist zijn. Dat is de andere helft van het werk: de neurale extractielaag die rommelige invoer uit meerdere systemen omzet in iets waar een AI of een deterministische engine op kan vertrouwen.
Waarom is tax AI ineens een privilegevraag en geen beveiligingsvraag?
Een tijdlang beschouwde ik de eis van een gesloten systeem als een beveiligingsvoorkeur — mooi meegenomen, enterprise-hygiëne. Toen deed in februari 2026 de SDNY uitspraak in de Heppner-zaak, en werd het niet langer optioneel.
De korte versie: het plakken van de gegevens van een cliënt in een openbare AI-tool kan het advocaat-cliëntprivilege over die communicatie doen vervallen. Voor een belastingafdeling herformuleert dat alles. De keuze tussen een openbare chatbot en een gesloten, enterprise-gecontroleerd systeem gaat niet langer over datahygiëne — het gaat erover of je bevoorrechte analyse bevoorrecht blijft. De IRS versterkte dezelfde periode de richting: haar AI-governancebeleid, IRM 10.24.1, classificeert nu generatieve-AI-uitvoer die als voornaamste basis dient voor een beslissing met juridische of materiële gevolgen als "high-impact," en eist versterkt toezicht. De toezichthouders vertellen je, in hun eigen taal, dat een ongeverifieerde AI-belastingpositie een high-impact-risico is.
Na Heppner is de architectuur die je kiest voor tax AI een privilegebeslissing voordat het een ingenieursbeslissing is.
Dit is geen hypothetische schade. Accountancy Age meldde in maart 2026 dat de helft van de Britse accountants op de hoogte was van bedrijven die directe financiële verliezen leden door onjuist AI-advies. Onderzoekers hebben ongeveer 800 gevallen van AI-bronvermeldingsfouten in 25 landen geregistreerd. Ondertussen verhoogt de IRS haar auditpercentage voor grote bedrijven van 8,8% richting 22,6%. Meer door AI opgestelde posities, meer audits, en een boete die bij de ondertekenaar terechtkomt — dat is de aanstormende botsing.
De bezwaren die ik het vaakst hoor
Mensen vragen me of betere modellen dit niet gewoon vanzelf zullen oplossen. Dat zullen ze niet, en niet omdat de modellen niet verbeteren. Consensusfout is een eigenschap van de data, niet van de omvang van het model. Een groter model dat op hetzelfde foute internet is getraind leert het foute antwoord vloeiender, niet minder. Je kunt een probleem dat met je meeschaalt niet overtreffen door op te schalen.
Het andere dat ik hoor: is een deterministische laag niet gewoon broze hardgecodeerde regels die geen 420 wetswijzigingen per jaar kunnen bijhouden? Dat zou zo zijn, als we probeerden de hele wet te coderen. Dat doen we niet. De verificatielaag richt zich op de bepalingen met hoge boetes en grote cascadewerking — de handvol waar zelfverzekerd fout zitten echt geld kost — en laat de routinematige negentig procent over aan de tools voor het opstellen die dat al goed afhandelen. Je hebt geen zekerheid nodig over alles. Je hebt zekerheid nodig over de dingen die bijten.
En zo nu en dan vraagt iemand waarom een belastingafdeling dit zou moeten bouwen in plaats van te wachten op een van de Big Four. EY streeft naar 80% automatisering van buitenlandse belastingcompliance; KPMG lanceerde in februari 2026 een Tax AI Accelerator. Maar die tools zijn gebouwd voor de eigen opdrachten van het kantoor, verkocht binnen projecten van zes en zeven cijfers, en ze verifiëren het werk van het kantoor — niet dat van jou. De verificatielaag die je daadwerkelijk beheert is degene die de handtekening beschermt die jij daadwerkelijk zet.
Wat ik mijn vroegere zelf zou vertellen
Belastingcompliance kost Amerikaanse bedrijven meer dan $126 miljard per jaar, en de sector doet er goed aan AI op dat getal los te laten. Het opstellen zou geautomatiseerd moeten worden. De fout is aan te nemen dat zodra de AI de aangifte kan opstellen, de klus geklaard is — terwijl in werkelijkheid het knelpunt gewoon stroomafwaarts is verschoven, naar de verificatie, waar het moeilijker te zien is en duurder om verkeerd te doen.
Ik begon hieraan met de gedachte dat het moeilijke deel het onderwijzen van belastingrecht aan een machine was. Het moeilijke deel bleek het tegenovergestelde te zijn: weten welke vragen een machine nooit mag raden, en de laag bouwen die weigert dat toe te staan. Op de dag dat elke belastingtool op AI draait, is de enige echte vraag die overblijft wie de AI controleert — en "dezelfde AI, beleefder gevraagd" is geen antwoord. Wil je zien hoe we die controle hebben gebouwd, het staat hier.
Het internet had het mis over een autolening-aftrek, en elke machine die ervan leerde erfde de fout zonder met de ogen te knipperen. Ergens in de wet liggen er nog duizenden van die fouten te wachten. Het werk is niet AI slimmer maken. Het is ervoor zorgen dat wanneer de hele wereld zelfverzekerd fout zit, jouw belastingpositie dat niet is.