
Toutes les IA fiscales que j'ai testées se sont trompées sur la même déduction — parce que l'internet aussi
J'avais deux écrans ouverts. À gauche, la loi : l'article 63(b)(7) de l'Internal Revenue Code, la disposition que l'Omnibus Budget Reconciliation Act a utilisée pour créer une nouvelle déduction sur les intérêts des prêts pour véhicules de tourisme admissibles. À droite, le site web de H&R Block lui-même, décrivant cette même déduction comme un « incitatif au-dessus de la ligne ».
Ces deux écrans ne peuvent pas avoir raison tous les deux. L'article 63(b)(7) réduit le revenu imposable — c'est une déduction en dessous de la ligne. Elle ne touche pas le revenu brut ajusté. « Au-dessus de la ligne » signifie l'inverse. L'une des plus grandes marques de préparation de déclarations fiscales aux États-Unis avait inversé le sens d'une déduction sur son site public, et en avril 2026 c'était toujours le cas.
Cela n'aurait été qu'une note de bas de page, si ce n'est ce qui s'est passé quand j'ai commencé à interroger l'IA à ce sujet. J'ai posé la question à plusieurs grands modèles de langage de premier plan — les mêmes outils d'IA de conformité fiscale que les cabinets intègrent désormais à la préparation des déclarations. Chacun d'entre eux m'a affirmé, avec une grammaire impeccable et une citation plausible, que la déduction était au-dessus de la ligne. Ils avaient tous lu le même internet. Et l'internet avait tort.
Quand chaque IA vous donne la même mauvaise réponse, ce n'est pas un bug. C'est la donnée d'entraînement qui vote, et la vérité qui perd.
C'est à ce moment-là que l'entreprise que je construisais a pris forme. Le secteur se démenait pour que l'IA prépare les déclarations fiscales plus vite. Presque personne ne construisait ce qui rattrape l'IA lorsqu'elle a tort avec assurance, de façon systématique. C'est cette lacune que la couche de vérification par IA de conformité fiscale de Veriprajna existe pour combler.
L'erreur qui se propage en cascade
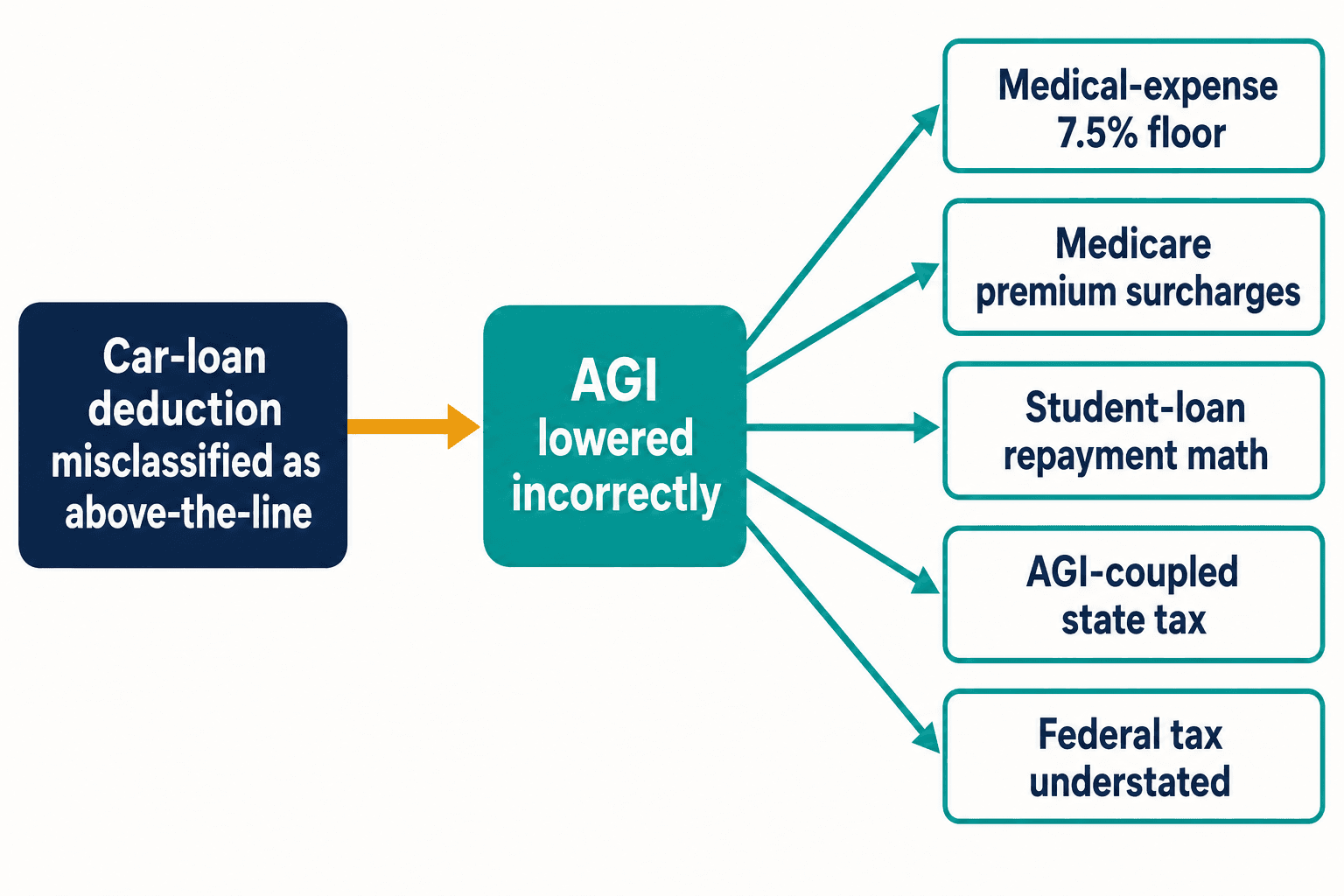
Voici pourquoi une seule déduction inversée m'a tenu éveillé. Une erreur de classification comme celle du prêt automobile ne reste pas isolée. Traitez cette déduction comme étant au-dessus de la ligne et vous abaissez un revenu brut ajusté qui n'aurait jamais dû changer. L'AGI est porteur dans le code fiscal. Il alimente le seuil de 7,5 % de la déduction pour frais médicaux. Il alimente les surtaxes de primes liées au revenu de Medicare. Il alimente le calcul du remboursement en fonction du revenu des prêts étudiants. Dans les États dont l'impôt est arrimé à l'AGI fédéral, il sous-estime aussi discrètement l'impôt d'État.
Un jeton erroné, cinq erreurs de calcul en aval — et cela ne vient que d'une seule disposition. L'Internal Revenue Code en compte des milliers. Le Congrès y a apporté en moyenne 420 modifications par an entre 2000 et 2020, selon le Taxpayer Advocate Service. Chaque nouvelle modification est une nouvelle occasion pour la blogosphère d'arriver avant que les directives officielles ne se stabilisent, et pour la prochaine génération de modèles d'apprendre la mauvaise version à force de pure répétition.
Et celui qui paie, ce n'est pas l'algorithme. Quand une déclaration est erronée, la pénalité de 20 % liée à l'exactitude prévue par le manuel de l'IRS retombe sur l'humain dont le nom figure sur la ligne de signature, signée sous peine de parjure. Le modèle qui l'a rédigée n'a ni PTIN ni responsabilité. Je revenais sans cesse à cette asymétrie. Nous nous apprêtions à confier la rédaction aux machines en laissant l'exposition aux personnes.
Pourquoi j'ai cessé de croire que la récupération de documents nous sauverait
Mon premier réflexe a été le même que celui de tout le monde : donner au modèle la loi réelle. La génération augmentée par récupération — le RAG, où le système va chercher la vraie loi et la fournit au modèle avant qu'il ne réponde — était censée être la solution. Blue J, qui a levé une série D de 122 M$, a construit exactement cela : du RAG par-dessus GPT-4.1, avec un partenariat IBFD couvrant plus de 220 juridictions. De l'ingénierie sérieuse, par des gens sérieux.
Nous avons donc construit notre propre prototype de récupération. Et je l'ai regardé extraire le texte correct de l'article 63(b)(7) — puis le résumer quand même de travers.
C'est la démonstration qui a brisé mon hypothèse. La récupération fonctionnait. L'interprétation, non. Le langage des amendements dans le code fiscal ressemble à « L'article 163(h) est modifié par l'insertion de… » — vous devez reconstruire l'état actuel de la loi à partir de fragments, et un modèle dont les poids internes ont absorbé des millions d'articles de blog « au-dessus de la ligne » se comporte en lecteur biaisé. Il voit la bonne loi et entend pourtant le mauvais consensus. Confier à un moteur probabiliste le bon document ne le fait pas raisonner ; cela ne fait que donner à une réponse confiante mais erronée une citation plus présentable.
La récupération procure au modèle le bon texte. Elle ne change rien au fait que le modèle a déjà fait son choix.
Nous avons commencé à appeler cela une erreur de consensus — quand chaque IA converge vers la même mauvaise réponse parce que le corpus public dont elle a appris est lui-même erroné. Ce n'est pas de l'hallucination au sens habituel. Une hallucination est aléatoire. Ceci est systématique, reproductible et partagé par tous les modèles entraînés sur le web ouvert. Cette distinction a changé ma façon de voir tout le problème.
« Il suffit d'emballer GPT et de le livrer »
Il y a eu une période où je me suis sincèrement demandé si je ne compliquais pas les choses. Un conseiller que je respecte m'a dit, en substance, d'arrêter de philosopher — d'emballer un bon modèle, d'ajouter de la récupération, de le livrer et de laisser le marché décider. Bon nombre d'entreprises bien financées faisaient précisément cela.
Le débat que nous avons eu s'est ramené à un chiffre sans cesse cité : Blue J rapporte un taux de désaccord inférieur à 1 sur 700. Cela ressemble à un indicateur d'exactitude. Ça n'en est pas un. Il mesure la fréquence à laquelle les utilisateurs sont en désaccord avec l'outil — et un praticien qui ne connaît pas déjà la bonne réponse ne peut pas être en désaccord avec une mauvaise. L'indicateur reste silencieux précisément là où réside le danger : la réponse confiante, plausible et fausse que personne, de l'autre côté, n'a les connaissances pour contester.
Un taux de désaccord mesure la confiance des utilisateurs, pas l'exactitude du modèle. Sur une position à forte pénalité, ce ne sont pas la même chose — et l'écart entre les deux, c'est là que vit la pénalité.
J'ai perdu le sommeil à me demander si « probablement juste » était un produit. Sur une question de mise en forme, ça l'est. Sur une position fiscale où la pénalité pour inexactitude est de 20 % du montant sous-payé et la pénalité pour fraude de 75 %, « probablement juste » est une responsabilité que vous avez automatisée et mise à l'échelle. C'est l'argument qui a mis fin au plan d'emballer GPT. Le probabiliste est le mauvais outil pour une question déterministe, aussi bonnes que deviennent les probabilités.
Qu'apporte réellement la vérification déterministe ?
Les fournisseurs qui l'ont le mieux compris ne sont pas les chatbots — ce sont les moteurs de fiscalité indirecte. Vertex maintient plus de 300 millions de taux d'imposition. Avalara, qui a reçu un investissement de 500 M$ de BlackRock fin 2025, et Sovos gèrent les déclarations dans plus de 12 000 juridictions. Pour les scénarios qu'ils couvrent, ils sont 100 % déterministes avec des pistes d'audit complètes. Posez-leur mille fois la même question de taux et vous obtenez mille fois la même réponse, et vous pouvez montrer à un auditeur exactement pourquoi.
Mais ces moteurs ne savent pas lire une phrase. Ils ne peuvent pas raisonner sur un critère de faits et circonstances, et ajouter une nouvelle règle suppose qu'un humain la code à la main. Le domaine se scinde donc nettement : les moteurs qui sont fiables ne comprennent pas le langage, et les systèmes qui comprennent le langage ne sont pas fiables.
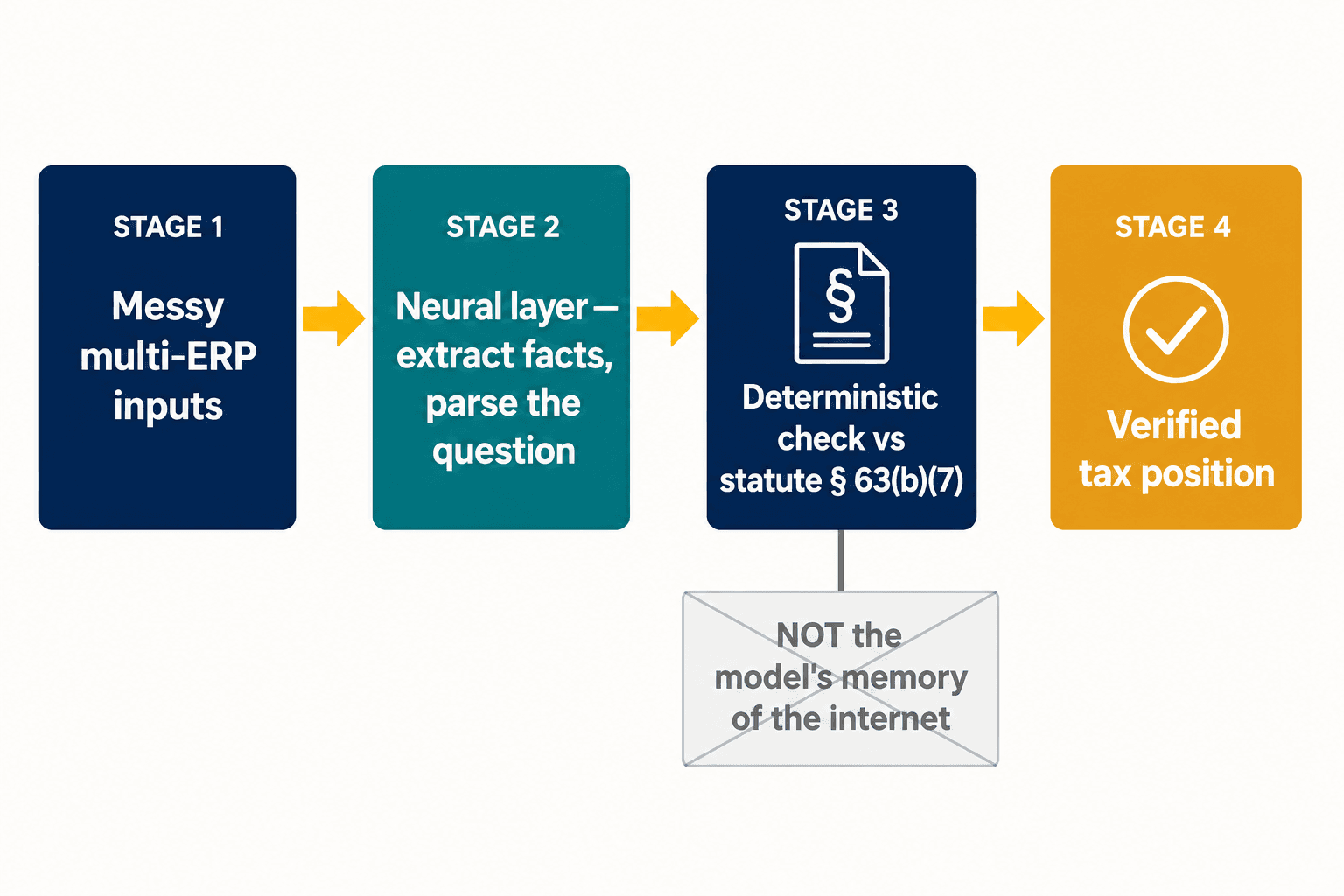
Cette scission est tout le problème de conception, et c'est là que nous avons ancré notre architecture. Nous n'essayons pas de rendre un seul modèle à la fois créatif et certain. Nous laissons une couche neuronale faire ce que les modèles neuronaux font bien — lire des entrées désordonnées, extraire des faits structurés d'une déclaration, analyser ce que demande réellement un praticien. Ensuite, pour les dispositions où l'exactitude n'est pas négociable, la réponse est confrontée à une représentation déterministe de la loi elle-même, et non à la mémoire qu'a le modèle de ce qu'internet en a dit. La déduction du prêt automobile se situe en dessous de la ligne parce que l'article 63(b)(7) le dit, point final — et non parce que le modèle a pesé les preuves et que les preuves se trouvaient être fausses.
L'objectif n'est pas de remplacer Thomson Reuters ou Wolters Kluwer. CCH Axcess Expert AI est intégré dans 10 000 cabinets ; ONESOURCE revendique une réduction de 65 % du temps de reporting de routine. Ces outils sont bons en préparation, et la préparation est aujourd'hui un problème largement résolu. La couche de vérification se place au-dessus de tout ce que vous utilisez déjà, indépendamment du fournisseur, et détecte les erreurs systématiques avant qu'elles n'atteignent l'IRS. Thomson Reuters vérifie Thomson Reuters. Wolters Kluwer vérifie Wolters Kluwer. Personne ne vérifiait l'ensemble, par rapport à la vérité de terrain, pour les positions qui entraînent réellement des pénalités.
Pour les grandes multinationales, le problème s'aggrave avant même que l'IA n'ouvre la bouche. Environ 78 % des entreprises exploitent quatre à sept systèmes ERP différents, et EY a constaté que la moitié des responsables fiscaux citent l'absence d'un plan durable en matière de données et de technologie comme leur principal obstacle. Ajoutez le Pilier Deux — le régime d'imposition minimale mondiale qui exige des données au niveau des entités et un reporting intercompagnie fiable, auquel seulement 15 % environ des organisations dans certaines régions se disent pleinement prêtes — et le maillon faible n'est pas du tout le raisonnement du modèle ; c'est de savoir si les faits structurés qui l'alimentent sont justes au départ. C'est l'autre moitié du travail : la couche d'extraction neuronale qui transforme des entrées désordonnées provenant de plusieurs systèmes en quelque chose auquel une IA ou un moteur déterministe peut se fier.
Pourquoi l'IA fiscale devient-elle soudain une question de secret professionnel, et non de sécurité ?
Pendant un temps, je considérais l'exigence de système fermé comme une préférence de sécurité — un plus, de l'hygiène d'entreprise. Puis, en février 2026, le SDNY a rendu l'arrêt Heppner, et cela a cessé d'être facultatif.
En résumé : coller les faits d'un client dans un outil d'IA public peut faire renoncer au secret professionnel avocat-client sur ces communications. Pour un service fiscal, cela recadre tout. Le choix entre un chatbot public et un système fermé, contrôlé par l'entreprise, ne concerne plus l'hygiène des données — il s'agit de savoir si votre analyse protégée reste protégée. L'IRS a renforcé cette orientation la même saison : sa politique de gouvernance de l'IA, l'IRM 10.24.1, classe désormais les sorties d'IA générative servant de base principale à une décision ayant un effet juridique ou matériel comme « à fort impact », exigeant une surveillance renforcée. Les régulateurs vous disent, dans leur propre langage, qu'une position fiscale par IA non vérifiée est un risque à fort impact.
Après l'arrêt Heppner, l'architecture que vous choisissez pour l'IA fiscale est une décision de secret professionnel avant d'être une décision d'ingénierie.
Ce n'est pas un préjudice hypothétique. Accountancy Age a rapporté en mars 2026 que la moitié des comptables britanniques avaient connaissance d'entreprises ayant subi des pertes financières directes à cause de conseils erronés d'une IA. Des chercheurs ont recensé environ 800 cas d'erreurs de citation par IA dans 25 pays. Pendant ce temps, l'IRS relève son taux d'audit des grandes entreprises de 8,8 % vers 22,6 %. Plus de positions rédigées par IA, plus d'audits, et une pénalité qui retombe sur le signataire — voilà la trajectoire de collision.
Les objections que j'entends le plus
Les gens me demandent si de meilleurs modèles ne vont pas simplement résoudre cela d'eux-mêmes. Ce ne sera pas le cas, et non parce que les modèles ne s'améliorent pas. L'erreur de consensus est une propriété des données, pas de la taille du modèle. Un modèle plus grand entraîné sur le même internet erroné apprend la mauvaise réponse plus couramment, pas moins. On ne peut pas échapper par l'échelle à un problème qui grandit avec vous.
L'autre chose que j'entends : une couche déterministe n'est-elle pas juste un ensemble de règles codées en dur, fragiles, incapables de suivre 420 modifications du code par an ? Ce serait le cas, si nous essayions de coder l'intégralité du code. Ce n'est pas ce que nous faisons. La couche de vérification cible les dispositions à forte pénalité et à fort effet de cascade — la poignée où se tromper avec assurance coûte de l'argent réel — et laisse les quatre-vingt-dix pour cent de routine aux outils de préparation qui les gèrent déjà bien. Vous n'avez pas besoin de certitude sur tout. Vous avez besoin de certitude sur les choses qui mordent.
Et de temps en temps, quelqu'un me demande pourquoi un service fiscal devrait construire cela plutôt que d'attendre l'un des Big Four. EY vise 80 % d'automatisation de la conformité fiscale étrangère ; KPMG a lancé un Tax AI Accelerator en février 2026. Mais ces outils sont conçus pour les propres missions du cabinet, vendus au sein de projets à six et sept chiffres, et ils vérifient le travail du cabinet — pas le vôtre. La couche de vérification que vous contrôlez réellement est celle qui protège la signature que vous apposez réellement.
Ce que je dirais à mon moi d'avant
La conformité fiscale coûte aux entreprises américaines plus de 126 milliards de dollars par an, et le secteur a raison de jeter l'IA sur ce chiffre. La préparation devrait être automatisée. L'erreur est de supposer qu'une fois que l'IA sait rédiger la déclaration, le travail est terminé — alors qu'en réalité le goulot d'étranglement s'est simplement déplacé en aval, vers la vérification, où il est plus difficile à voir et plus coûteux de se tromper.
J'ai commencé tout cela en pensant que le plus dur était d'enseigner le droit fiscal à une machine. Le plus dur s'est avéré être l'inverse : savoir quelles questions une machine ne devrait jamais être autorisée à deviner, et construire la couche qui l'en empêche. Le jour où chaque outil fiscal fonctionnera à l'IA, la seule vraie question qui restera sera de savoir qui contrôle l'IA — et « la même IA, interrogée plus poliment » n'est pas une réponse. Si vous voulez voir comment nous avons construit ce contrôle, c'est ici.
L'internet avait tort au sujet d'une déduction de prêt automobile, et chaque machine qui en a appris a hérité de l'erreur sans sourciller. Quelque part dans le code, il y en a des milliers d'autres, qui attendent. Le travail n'est pas de rendre l'IA plus intelligente. C'est de s'assurer que, lorsque le monde entier a tort avec assurance, votre position fiscale, elle, ne l'est pas.