
내가 테스트한 모든 세무 AI가 똑같은 공제를 틀렸다 — 인터넷이 틀렸기 때문에
모니터 두 대를 켜 두고 있었다. 왼쪽에는 법령이 있었다. 내국세법 제63조(b)(7)항으로, 종합예산조정법(Omnibus Budget Reconciliation Act)이 적격 승용차 대출 이자에 대한 새로운 공제를 신설하는 데 사용한 조항이다. 오른쪽에는 H&R Block 자체 웹사이트가 있었는데, 바로 그 동일한 공제를 'above-the-line 인센티브'라고 설명하고 있었다.
그 두 화면이 동시에 옳을 수는 없다. 제63조(b)(7)항은 과세소득을 줄인다 — 즉 below-the-line 공제다. 이 조항은 조정총소득(AGI)에는 손대지 않는다. 'above-the-line'은 그 반대를 뜻한다. 미국 최대 세무 신고 대행 브랜드 중 하나가 자사 공개 사이트에서 공제의 방향을 거꾸로 표기해 두었고, 2026년 4월 현재까지도 여전히 그랬다.
그 정도라면 각주에 그칠 일이었지만, 내가 이에 대해 AI에 묻기 시작하면서 벌어진 일은 달랐다. 나는 여러 선도적인 대규모 언어 모델에 그 질문을 던졌다 — 기업들이 지금 신고서 작성에 연결해 넣고 있는 바로 그 세무 컴플라이언스 AI 도구들이다. 그들 하나하나가 깔끔한 문법과 그럴듯한 인용을 곁들여, 그 공제가 above-the-line이라고 내게 말했다. 그들은 모두 같은 인터넷을 읽었다. 그리고 그 인터넷이 틀렸다.
모든 AI가 당신에게 똑같이 틀린 답을 줄 때, 그것은 결함이 아니다. 그것은 학습 데이터가 투표를 하고, 진실이 지는 것이다.
내가 세우고 있던 회사가 선명하게 초점을 맞춘 순간이었다. 업계는 AI가 세금 신고서를 더 빠르게 작성하도록 만드는 데 앞다투고 있었다. AI가 자신 있게, 체계적으로 틀렸을 때 그것을 잡아내는 것을 만드는 사람은 거의 없었다. 바로 그 공백을 Veriprajna의 세무 컴플라이언스 AI 검증 레이어가 메우기 위해 존재한다.
연쇄적으로 번지는 오류
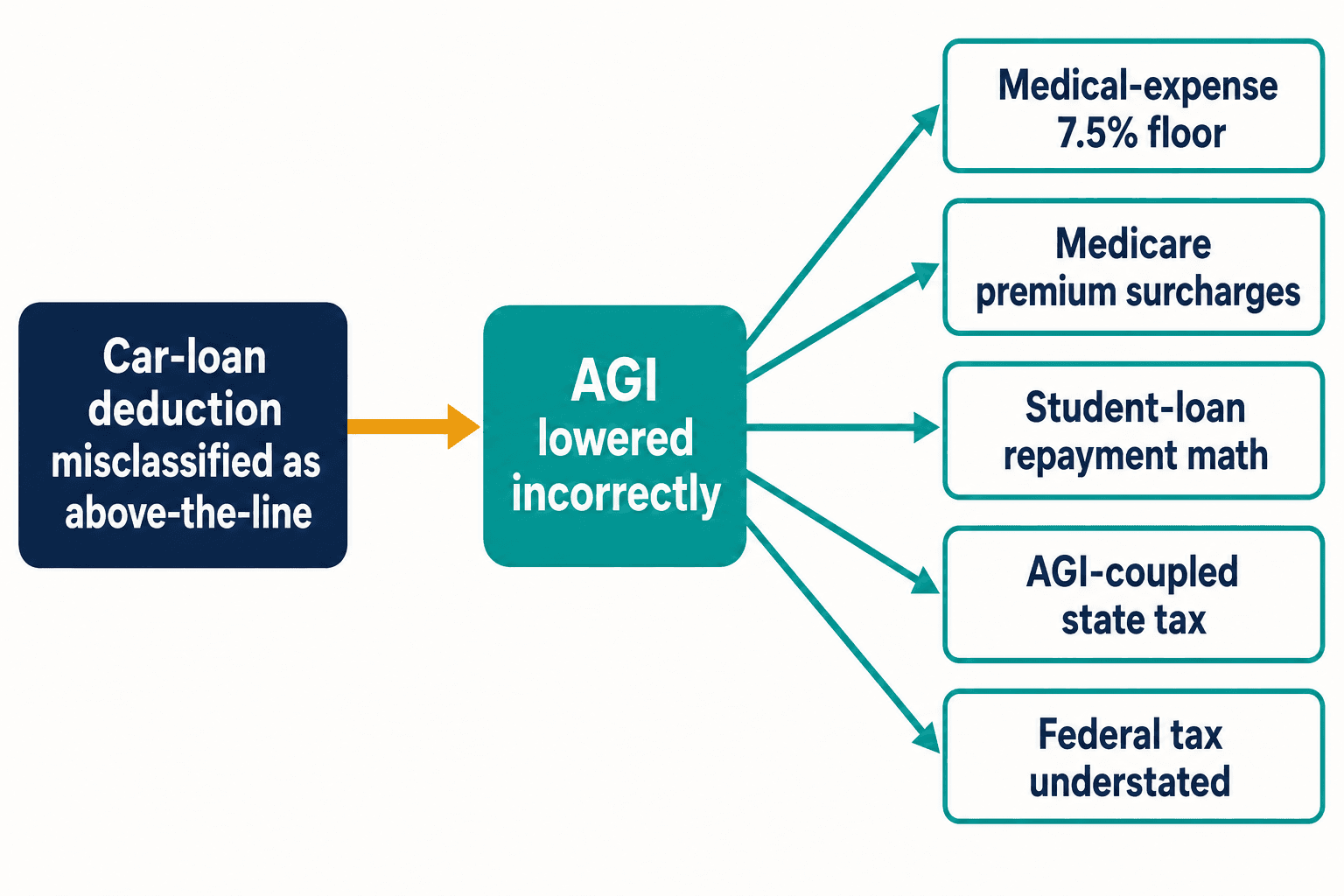
단 하나의 거꾸로 된 공제가 나를 잠 못 들게 한 이유는 이렇다. 자동차 대출 건과 같은 오분류는 그 자리에 머물지 않는다. 그 공제를 above-the-line으로 처리하면, 결코 움직여서는 안 될 조정총소득(AGI)을 낮추게 된다. AGI는 세법에서 하중을 떠받치는 요소다. 이것은 7.5%의 의료비 공제 기준선을 좌우한다. 메디케어의 소득연동 보험료 할증을 좌우한다. 학자금 대출의 소득기반 상환 계산을 좌우한다. 주(州) 세금이 연방 AGI에 연동된 주에서는, 조용히 주 세금까지 과소 신고하게 만든다.
틀린 토큰 하나가 다섯 개의 다운스트림 오산을 낳는다 — 그것도 단 하나의 조항에서 말이다. 내국세법에는 그런 조항이 수천 개 있다. 납세자 권익 보호관실(Taxpayer Advocate Service)에 따르면, 2000년부터 2020년 사이에 의회는 연평균 420건씩 세법을 개정했다. 새로운 개정 하나하나가, 공식 지침이 정착되기 전에 블로고스피어가 먼저 도달할 새로운 기회이자, 다음 세대 모델들이 순전한 반복만으로 틀린 버전을 학습할 새로운 기회다.
그리고 대가를 치르는 것은 알고리즘이 아니다. 신고서가 틀리면, IRS 매뉴얼상 20%의 정확성 관련 가산세가, 위증 시 처벌을 감수한다는 서명란에 이름을 올린 사람에게 떨어진다. 그것을 초안한 모델은 PTIN도 없고 책임도 없다. 나는 그 비대칭성으로 계속 되돌아왔다. 우리는 초안 작성은 기계에 맡기고 위험 노출은 사람에게 남겨두려던 참이었다.
검색(retrieval)이 우리를 구해줄 거라는 믿음을 내가 버린 이유
나의 첫 직감은 누구나 갖는 그것과 같았다: 모델에 실제 법을 먹이자. 검색 증강 생성(retrieval-augmented generation) — RAG, 즉 시스템이 실제 법령을 찾아서 답하기 전에 모델에 건네주는 방식 — 이 그 해결책이 될 것으로 여겨졌다. 1억 2,200만 달러 규모의 시리즈 D를 유치한 Blue J가 바로 이것을 구축했다: GPT-4.1 위에 얹은 RAG에, 220개 이상의 관할권을 아우르는 IBFD 파트너십을 더한 것이다. 진지한 사람들의 진지한 엔지니어링이다.
그래서 우리도 우리 나름의 검색 프로토타입을 만들었다. 그리고 나는 그것이 제63조(b)(7)항의 정확한 텍스트를 불러오는 것을 지켜보았다 — 그러고는 그것을 어쨌든 틀리게 요약하는 것을.
그것이 내 가정을 무너뜨린 데모였다. 검색은 작동했다. 해석은 그러지 못했다. 세법의 개정 조문 언어는 다음과 같이 읽힌다 "제163조(h)항은 …을 삽입함으로써 개정된다" — 당신은 조각들로부터 현행 법의 상태를 재구성해야 하고, 수백만 개의 'above-the-line' 블로그 게시물을 내부 가중치로 흡수한 모델은 편향된 독자처럼 행동한다. 그것은 올바른 법령을 보고도 여전히 틀린 통념을 듣는다. 확률 엔진에 올바른 문서를 건네준다고 해서 그것이 추론하게 되는 것은 아니다. 그저 자신 있게 틀린 답에 더 그럴듯해 보이는 인용을 붙여줄 뿐이다.
검색은 모델에 올바른 텍스트를 가져다준다. 하지만 모델이 이미 마음을 정해버렸다는 사실에 대해서는 아무것도 하지 못한다.
우리는 이것을 컨센서스 오류(Consensus Error)라고 부르기 시작했다 — 모든 AI가, 학습한 공개 기록 자체가 틀렸기 때문에 똑같이 틀린 답으로 수렴할 때를 말한다. 그것은 통상적 의미의 환각(hallucination)이 아니다. 환각은 무작위적이다. 이것은 체계적이고, 반복 가능하며, 오픈 웹으로 학습한 모든 모델이 공유한다. 그 구분이 이 문제 전체를 바라보는 내 사고방식을 바꿔놓았다.
"그냥 GPT를 감싸서 출시하라"
정말로 내가 이걸 지나치게 복잡하게 만들고 있는 건 아닌지 궁금해했던 시기가 있었다. 내가 존경하는 한 조언자는 대략 이렇게 말했다 — 철학 놀음은 그만두고, 좋은 모델을 감싸고, 검색을 붙이고, 출시해서, 시장이 결정하게 하라고. 자금이 넉넉한 수많은 회사가 바로 그렇게 하고 있었다.
우리가 벌인 논쟁은 끊임없이 인용되는 하나의 숫자로 귀결되었다: Blue J는 700분의 1 미만의 이견률(disagree rate)을 보고한다. 정확도 수치처럼 들린다. 그렇지 않다. 그것은 얼마나 자주 사용자가 그 도구에 이의를 제기하는지를 측정한다 — 그리고 이미 정답을 알지 못하는 실무자는 틀린 답에 이의를 제기할 수 없다. 그 지표는 정확히 위험이 도사리는 곳에서 침묵한다: 반대편의 누구도 반박할 지식이 없는, 자신 있고 그럴듯하며 틀린 답 말이다.
이견률은 사용자의 자신감을 측정하는 것이지, 모델의 정확성을 측정하는 것이 아니다. 가산세가 큰 세무 입장에서 이 둘은 같은 것이 아니다 — 그리고 그 둘 사이의 간극이 바로 가산세가 도사리는 곳이다.
나는 '아마도 맞을 것'이 제품이 될 수 있는지를 두고 잠을 설쳤다. 서식(formatting) 문제라면 제품이 된다. 하지만 정확성 가산세가 과소납부액의 20%이고 사기 가산세가 75%인 세무 입장에서라면, '아마도 맞음'은 당신이 자동화하고 규모까지 키워버린 책임이다. 그것이 GPT 감싸기 계획을 끝낸 논거였다. 확률론적 도구는 결정론적 질문에 잘못된 도구다, 확률이 아무리 좋아진들 말이다.
결정론적 검증은 실제로 당신에게 무엇을 사주는가?
이것을 가장 잘 이해하는 벤더는 챗봇이 아니라 간접세 엔진들이다. Vertex는 3억 개가 넘는 세율을 유지한다. 2025년 말 BlackRock으로부터 5억 달러 투자를 받은 Avalara와 Sovos는 12,000곳이 넘는 관할권에 걸쳐 신고를 처리한다. 그들이 다루는 시나리오에서는 완전한 감사 추적과 함께 100% 결정론적이다. 그들에게 같은 세율 질문을 천 번 물어보면 천 번 같은 답을 얻고, 그 이유를 감사관에게 정확히 보여줄 수 있다.
하지만 그 엔진들은 문장을 읽지 못한다. 사실관계 및 정황(facts-and-circumstances) 판단에 대해 추론하지 못하며, 새로운 규칙을 추가한다는 것은 사람이 손으로 그것을 코드화한다는 뜻이다. 그래서 이 분야는 깔끔하게 갈라진다: 신뢰할 수 있는 엔진은 언어를 이해하지 못하고, 언어를 이해하는 시스템은 신뢰할 수 없다.
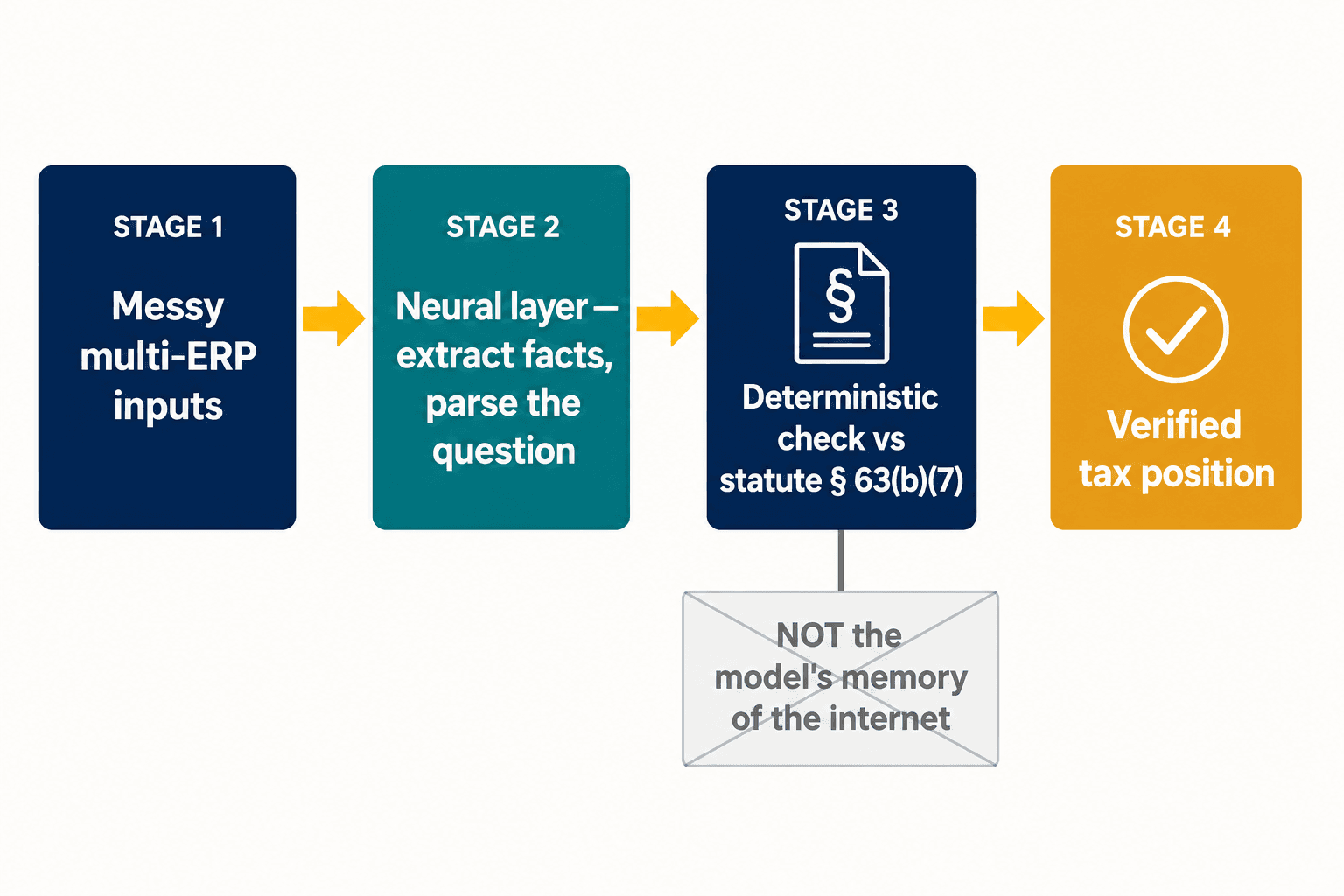
그 분열이 설계 문제의 전부이며, 바로 그곳에서 우리는 우리 아키텍처를 안착시켰다. 우리는 하나의 모델을 창의적이면서 동시에 확실하게 만들려 하지 않는다. 우리는 신경망 레이어가 신경망 모델이 잘하는 일을 하게 둔다 — 지저분한 입력을 읽고, 신고서에서 구조화된 사실을 추출하고, 실무자가 실제로 무엇을 묻고 있는지 파싱하는 일 말이다. 그런 다음, 정확성이 타협 불가능한 조항에 대해서는, 그 답을 모델이 인터넷에서 본 내용에 대한 기억이 아니라 법령 그 자체의 결정론적 표현에 대조해 검사한다. 자동차 대출 공제는 제63조(b)(7)항이 그렇게 말하기 때문에 below-the-line에 속한다, 그것으로 끝이다 — 모델이 증거를 저울질했는데 마침 그 증거가 틀렸기 때문이 아니라.
요점은 Thomson Reuters나 Wolters Kluwer를 대체하는 것이 아니다. CCH Axcess Expert AI는 10,000개 회사에 내장되어 있고, ONESOURCE는 일상적 보고 시간을 65% 단축했다고 주장한다. 그런 도구들은 작성(preparation)에 능하며, 작성은 이제 대체로 해결된 문제다. 검증 레이어는 당신이 이미 운영하는 그 무엇이든 그 위에 얹혀, 벤더에 중립적으로, 시스템적 오류가 IRS에 도달하기 전에 잡아낸다. Thomson Reuters는 Thomson Reuters를 검증한다. Wolters Kluwer는 Wolters Kluwer를 검증한다. 그 누구도 그 모든 것을 아울러, 실제로 가산세를 수반하는 입장에 대해, 실측 진실(ground truth)에 대조해 검증하고 있지는 않았다.
대형 다국적 기업에는 AI가 입을 열기도 전에 문제가 복잡해진다. 대략 78%의 기업이 네 개에서 일곱 개의 서로 다른 ERP 시스템을 운영하며, EY는 세무 책임자의 절반이 지속 가능한 데이터·기술 계획의 부재를 자신들의 가장 큰 단일 장애물로 꼽는다는 것을 발견했다. 여기에 필러 투(Pillar Two) — 개체 단위 데이터와 신뢰할 수 있는 기업 간 보고를 요구하는 글로벌 최저한세 체제로, 일부 지역에서는 조직의 약 15%만이 완전히 준비되었다고 답한다 — 를 더해 보라. 그러면 가장 약한 고리는 모델의 추론이 전혀 아니다. 그것은 모델에 공급되는 구조화된 사실이 애초에 옳은가 하는 것이다. 그것이 이 작업의 나머지 절반이다: 지저분한 다중 시스템 입력을, AI든 결정론적 엔진이든 신뢰할 수 있는 무언가로 바꾸는 신경망 추출 레이어 말이다.
세무 AI가 갑자기 보안 문제가 아니라 특권(privilege) 문제가 된 이유는?
한동안 나는 폐쇄형 시스템 요건을 보안 선호 정도로 — 있으면 좋은 것, 엔터프라이즈 위생 수준으로 — 생각했다. 그러다 2026년 2월, SDNY가 Heppner 판결을 내렸고, 그것은 더 이상 선택 사항이 아니게 되었다.
요약하자면: 의뢰인의 사실관계를 공개 AI 도구에 붙여넣는 것은 그 커뮤니케이션에 대한 변호사-의뢰인 특권(attorney-client privilege)을 포기하게 만들 수 있다. 세무 부서에는 이것이 모든 것을 다시 규정한다. 공개 챗봇과 폐쇄형·기업 통제 시스템 사이의 선택은 더 이상 데이터 위생의 문제가 아니다 — 당신의 특권 보호 분석이 특권으로 유지되는가의 문제다. IRS는 같은 시기에 그 방향을 강화했다: AI 거버넌스 정책인 IRM 10.24.1은 이제 법적 또는 실질적 효력을 갖는 결정의 주된 근거로 기능하는 생성형 AI 산출물을 '고영향(high-impact)'으로 분류하며, 강화된 감독을 요구한다. 규제 당국은 그들 자신의 언어로, 검증되지 않은 AI 세무 입장이 고영향 위험임을 당신에게 말하고 있다.
Heppner 판결 이후, 세무 AI를 위해 당신이 선택하는 아키텍처는 엔지니어링 결정이기에 앞서 특권에 관한 결정이다.
이것은 가상의 피해가 아니다. Accountancy Age는 2026년 3월, 영국 회계사의 절반이 잘못된 AI 자문으로 직접적인 금전 손실을 입은 기업들을 알고 있다고 보도했다. 연구자들은 25개국에 걸쳐 약 800건의 AI 인용 오류 사례를 기록했다. 한편 IRS는 대기업 감사율을 8.8%에서 22.6%를 향해 높이고 있다. AI가 초안한 입장은 더 많아지고, 감사는 더 늘어나며, 가산세는 서명한 사람에게 떨어진다 — 그것이 충돌 궤도다.
내가 가장 자주 듣는 반론들
사람들은 더 나은 모델이 이 문제를 알아서 그냥 해결하지 않겠느냐고 내게 묻는다. 그러지 못할 것이며, 모델이 나아지지 않아서가 아니다. 컨센서스 오류(Consensus Error)는 데이터의 속성이지, 모델 크기의 속성이 아니다. 같은 틀린 인터넷으로 학습한 더 큰 모델은 틀린 답을 덜이 아니라 더 유창하게 학습한다. 당신과 함께 규모가 커지는 문제를 규모로 이겨낼 수는 없다.
내가 듣는 또 다른 것: 결정론적 레이어는 연간 420건의 세법 개정을 따라잡지 못하는 취약한 하드코딩 규칙에 불과하지 않은가? 우리가 세법 전체를 코드화하려 든다면 그럴 것이다. 우리는 그러지 않는다. 검증 레이어는 가산세가 크고 연쇄가 큰 조항 — 자신 있게 틀리는 것이 실제 돈으로 값을 치르게 하는 소수의 조항 — 을 겨냥하고, 일상적인 90%는 이미 그것을 잘 처리하는 작성 도구에 맡긴다. 당신은 모든 것에 대한 확실성이 필요하지는 않다. 당신은 물어뜯는 것들에 대한 확실성이 필요하다.
그리고 이따금 누군가는 왜 세무 부서가 빅 포(Big Four) 중 하나를 기다리지 않고 이것을 직접 구축해야 하는지 묻는다. EY는 해외 세무 컴플라이언스의 80% 자동화를 목표로 하고 있고, KPMG는 2026년 2월 Tax AI Accelerator를 출시했다. 하지만 그런 도구들은 해당 회사 자신의 업무를 위해 만들어지고, 6자리·7자리 금액의 프로젝트 안에서 팔리며, 그들은 그 회사의 작업을 검증한다 — 당신의 것이 아니라. 당신이 실제로 통제하는 검증 레이어야말로 당신이 실제로 서명하는 그 서명을 보호하는 것이다.
예전의 나에게 해주고 싶은 말
세무 컴플라이언스는 미국 기업에 연간 1,260억 달러 넘는 비용을 지운다, 그리고 업계가 그 숫자에 AI를 던지는 것은 옳다. 작성은 자동화되어야 한다. 실수는 일단 AI가 신고서를 초안할 수 있게 되면 일이 끝났다고 가정하는 것이다 — 실제로는 병목이 그저 하류로, 즉 보기가 더 어렵고 틀리면 더 큰 대가를 치르는 검증 단계로 옮겨갔을 뿐인데 말이다.
나는 어려운 부분이 기계에 세법을 가르치는 것이라고 생각하며 이 일을 시작했다. 어려운 부분은 정반대로 드러났다: 기계가 어떤 질문에 대해서는 절대 추측하도록 허용해서는 안 되는지 아는 것, 그리고 그것을 결코 허용하지 않는 레이어를 구축하는 것이었다. 모든 세무 도구가 AI로 돌아가는 날, 남는 유일한 진짜 질문은 누가 그 AI를 검사하는가이다 — 그리고 '똑같은 AI에게, 더 정중하게 물어보기'는 답이 아니다. 우리가 그 검증을 어떻게 구축했는지 보고 싶다면, 여기에서 볼 수 있다.
인터넷은 자동차 대출 공제에 대해 틀렸고, 그것으로부터 학습한 모든 기계는 눈 하나 깜짝하지 않고 그 오류를 물려받았다. 세법 어딘가에는 그런 것이 수천 개 더, 기다리고 있다. 이 일은 AI를 더 똑똑하게 만드는 것이 아니다. 온 세상이 자신 있게 틀렸을 때, 당신의 세무 입장만은 틀리지 않도록 하는 것이다.