
我测试的每一款税务AI都把同一项扣除弄错了——因为互联网本身就是错的
我打开了两块显示器。左边是法条:《国内税收法典》第63(b)(7)条,《综合预算调节法案》正是依据这一条款为符合条件的乘用车贷款利息新设了一项扣除。右边是H&R Block自己的网站,把这同一项扣除描述为一种“线上激励”(above-the-line incentive)。
这两块屏幕不可能都对。第63(b)(7)条减少的是应税所得——它是一项线下扣除,根本不触及调整后总收入。“线上”的含义正好相反。美国最大的报税品牌之一在其公开网站上把一项扣除的方向弄反了,而且截至2026年4月依然如此。
这本来只算个脚注,可当我开始就此询问AI时,事情就不一样了。我把这个问题抛给了几款领先的大型语言模型——正是那些企业如今正接入报税流程的税务合规AI工具。它们无一例外地告诉我,语法工整、还附上看似可信的引用,说这项扣除是线上扣除。它们读的是同一个互联网。而互联网是错的。
当每一个AI都给你同样的错误答案时,那不是故障。那是训练数据在投票,而真相输掉了。
就是在那一刻,我正在创建的这家公司变得清晰起来。整个行业都在争相让AI更快地拟制税务申报表。几乎没有人在打造那样一样东西——当AI自信而系统性地出错时,能把它抓出来的东西。这个空白正是VeriPrajna的税务合规AI验证层存在的意义。
层层放大的错误
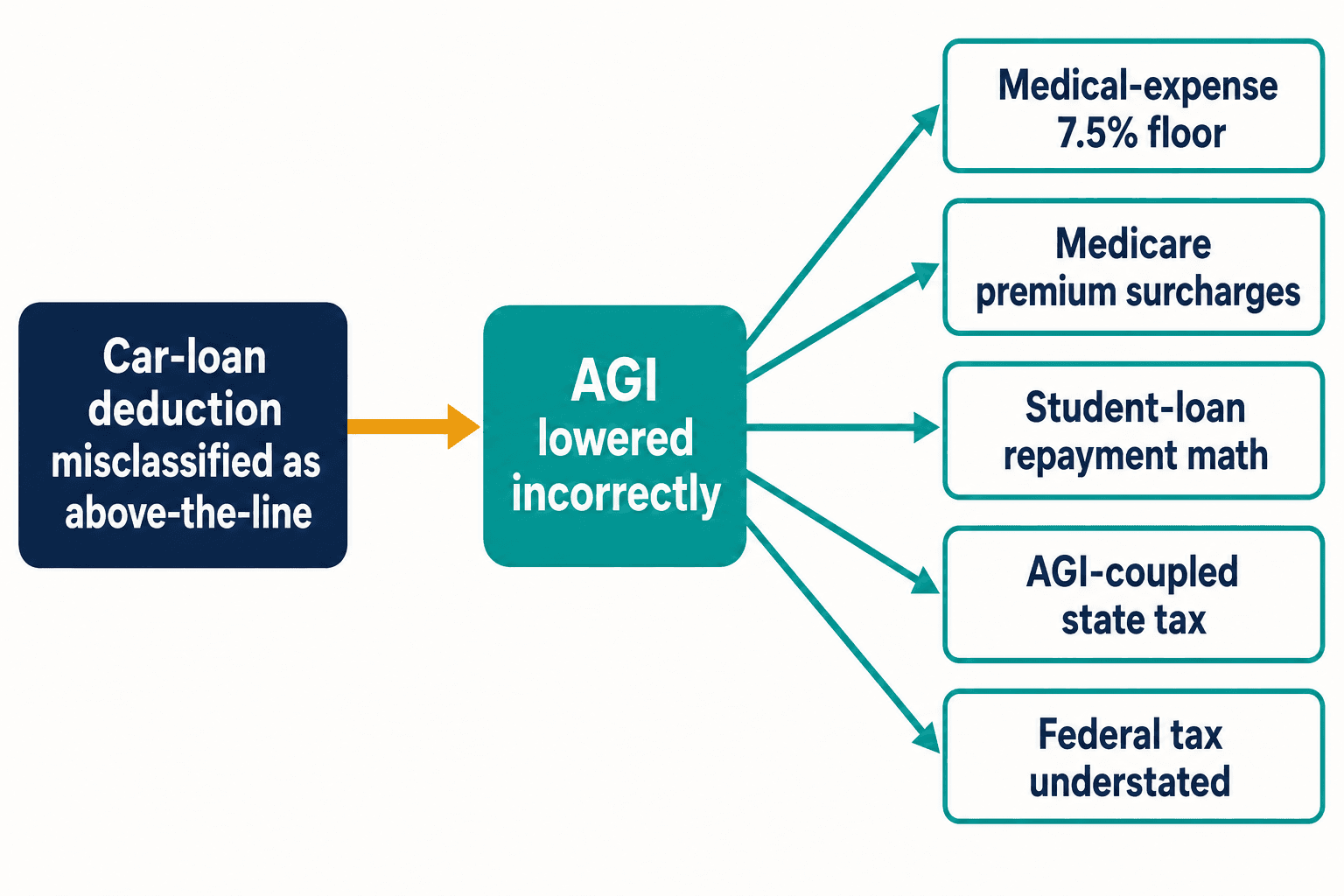
这就是为什么一项方向弄反的扣除让我彻夜难眠。像车贷这样的错误归类不会止步于自身。把这项扣除当作线上扣除,你就压低了本不该变动的调整后总收入。调整后总收入(AGI)在税法中是承重结构:它决定7.5%的医疗费用扣除门槛;它决定医疗保险按收入分级的保费附加费;它决定学生贷款按收入调整还款的算法。在那些税收与联邦AGI挂钩的州,它还悄悄少算了州税。
一个错误的词元,五处下游计算错误——而这仅仅出自一项条款。《国内税收法典》有成千上万条。据纳税人权益保护局的数据,2000年至2020年间,国会平均每年对它做出420处修改。每一次新的改动,都是博客圈抢在官方指引尘埃落定之前抢先发声的新机会,也是下一代模型仅凭一遍遍重复就学到错误版本的新机会。
而付出代价的不是算法。当一份申报表出错时,依据国税局手册的20%准确性相关罚款,落在了签名栏上写着名字、并在伪证处罚下签字的那个人身上。起草它的模型既没有PTIN,也不承担任何责任。我一次次回到这种不对等上。我们正要把起草交给机器,却把风险敞口留给了人。
为什么我不再相信检索能拯救我们
我最初的本能和所有人一样:把真正的法律喂给模型。检索增强生成——RAG,即系统在回答前查出真实法条并交给模型——本该是解决之道。融资1.22亿美元D轮的Blue J,构建的正是这一套:在GPT-4.1之上做RAG,并与IBFD达成覆盖220多个司法管辖区的合作。这是严肃的人做的严肃工程。
于是我们自己也搭了一个检索原型。我眼看着它调出了第63(b)(7)条的正确文本——然后还是把它总结错了。
正是那次演示打破了我的假设。检索成功了,解读却没有。税法中的修订用语读起来像“第163(h)条经插入……予以修订”——你必须从零碎片段中重建法律的当前状态,而一个内部权重已吸收了数百万篇“线上扣除”博文的模型,会像一个带偏见的读者。它看到了正确的法条,却仍然听到了错误的共识。把正确的文件递给一台概率引擎,并不会让它去推理;它只是给一个自信的错误答案配上了一份更好看的引用。
检索让模型拿到了正确的文本。它对模型早已打定的主意却无能为力。
我们开始把这称为共识错误——当每一个AI都收敛到同一个错误答案上,只因它们所学的公共记录本身就是错的。这不是通常意义上的幻觉。幻觉是随机的。而这是系统性的、可重复的,并且在每一个基于开放网络训练的模型之间共享。这个区别改变了我看待整个问题的方式。
“只要包一层GPT发布出去就行”
有那么一段时间,我真的怀疑自己是不是把事情想复杂了。一位我敬重的顾问差不多是这么跟我说的:别再空想哲学了——包一个好模型,加上检索,发布出去,让市场来决定。许多资金充裕的公司做的正是这件事。
我们那场争论归结为一个被反复引用的数字:Blue J报告的分歧率低于七百分之一。它听起来像是一个准确率指标。它不是。它衡量的是用户对工具的不同意频率——而一个本就不知道正确答案的从业者,无法对一个错误答案表示不同意。这个指标恰恰在危险所在之处保持沉默:那个自信、可信、错误,而另一方没有知识去质疑的答案。
分歧率衡量的是用户的信心,而非模型的正确性。在一个高罚款风险的立场上,这两者并不是一回事——而两者之间的落差,正是罚款所在。
我为“大概是对的”是否算得上一款产品而失眠。在格式问题上,它算。但在一个准确性罚款为少缴税额20%、欺诈罚款为75%的税务立场上,“大概是对的”是一项被你自动化并规模化了的责任。正是这个论点终结了那套包GPT的计划。对于一个确定性的问题,概率化是错误的工具,无论概率变得多么好。
确定性验证究竟能给你带来什么?
把这件事看得最透的厂商不是聊天机器人——而是间接税引擎。Vertex维护着超过3亿条税率。2025年末获得贝莱德5亿美元投资的Avalara,以及Sovos,在超过12,000个司法管辖区跨境办理申报。对于它们覆盖的场景,它们是100%确定性的,并具备完整的审计轨迹。同一个税率问题问它们一千次,你会得到一千次相同的答案,而且你能向审计员精确地说明为什么。
但那些引擎读不懂一个句子。它们无法对“事实与情境”的检验作出推理,而新增一条规则意味着要由人手工编码。于是这个领域清晰地一分为二:可靠的引擎读不懂语言,而读得懂语言的系统不可靠。
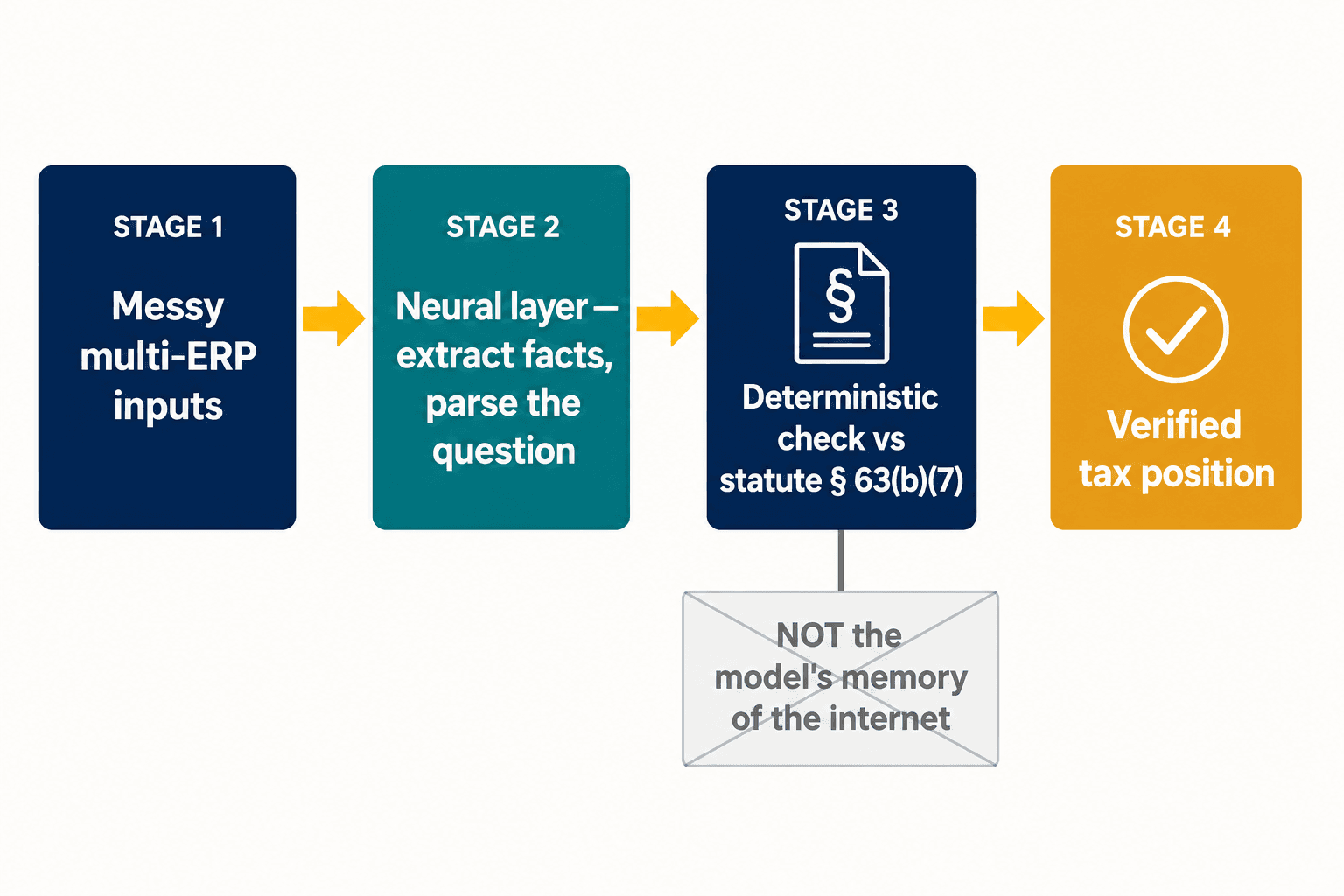
这道分裂就是整个设计难题所在,也正是我们落定架构的地方。我们不去试图让一个模型既有创造力又有确定性。我们让神经层去做神经模型擅长的事——读取杂乱的输入,从一份申报表中提取结构化事实,解析一位从业者真正在问什么。然后,对于那些正确性不容讨价还价的条款,答案将对照法条本身的确定性表示来核验,而不是对照模型对互联网怎么说的记忆。车贷扣除属于线下,是因为第63(b)(7)条这么规定,句号——而不是因为模型权衡了证据、而证据恰好是错的。
重点不是要取代汤森路透或威科集团。CCH Axcess Expert AI已嵌入10,000家事务所;ONESOURCE声称将常规报告时间缩短了65%。那些工具擅长的是拟制,而拟制如今在很大程度上已是一个被解决的问题。验证层坐落在之上——凌驾于你现有运行的任何系统之上,与厂商无关,在系统性错误抵达国税局之前将其抓出。汤森路透验证汤森路透。威科集团验证威科集团。没有人在横跨这一切、对照根本事实、为那些真正带来罚款的立场做验证。
对大型跨国企业来说,问题在AI张口之前就已层层叠加。大约78%的公司运行着四到七套不同的ERP系统,安永发现半数税务负责人把缺乏可持续的数据与技术规划列为他们最大的单一障碍。再叠加“支柱二”——这一全球最低税制度要求实体层级的数据和可靠的公司间报告,而在某些地区只有约15%的机构表示已为此做好充分准备——那么最薄弱的一环根本不在于模型的推理;而在于喂给它的结构化事实一开始是否正确。这正是工作的另一半:把杂乱的多系统输入转化为AI或确定性引擎都能信赖之物的神经提取层。
为什么税务AI突然成了一个特权问题,而不是安全问题?
有一阵子,我把封闭系统这项要求视为一种安全偏好——锦上添花,属于企业的良好卫生习惯。然后在2026年2月,纽约南区联邦地区法院(SDNY)作出了Heppner裁决,它便不再是可选项了。
简而言之:把客户的事实粘贴进一款公开的AI工具,可能会放弃对这些沟通所享有的律师-客户特权。对一个税务部门而言,这重新定义了一切。在公开聊天机器人与封闭的、企业自控的系统之间做选择,不再是数据卫生的问题——而是你享有特权的分析是否还能保持特权。国税局在同一季度强化了这个方向:其AI治理政策IRM 10.24.1,如今把作为具有法律或实质影响之决定主要依据的生成式AI输出归类为“高影响”,要求加强监督。监管者正在用他们自己的语言告诉你:一个未经验证的AI税务立场是一项高影响风险。
Heppner案之后,你为税务AI所选择的架构,在成为一个工程决定之前,先是一个特权决定。
这并非假想的危害。《会计时代》(Accountancy Age)在2026年3月报道,半数英国会计师知晓有企业因错误的AI建议而蒙受直接经济损失。研究人员已记录下横跨25个国家、约800起AI引用错误的案例。与此同时,国税局正把大型企业的审计率从8.8%提高到22.6%。更多由AI起草的立场,更多审计,以及一项落在签字人身上的罚款——这就是那条相撞的航线。
我最常听到的那些反对意见
人们问我,更好的模型是不是会自己就把这个问题解决掉。它们不会,而这并不是因为模型没有进步。共识错误是数据的属性,而非模型规模的属性。一个基于同一个错误互联网训练的更大模型,只会更流利地学到错误答案,而不是更不流利。你无法用规模跑赢一个和你一起扩张的问题。
我听到的另一件事:确定性层难道不就是些脆弱的硬编码规则,跟不上每年420处的法典变更吗?如果我们试图把整部法典都编码进去,它确实会是。但我们不那么做。验证层瞄准的是高罚款、高连锁反应的条款——那少数几个自信出错就要付出真金白银的地方——而把常规的九成留给那些本就处理得很好的拟制工具。你不需要对一切都确定。你需要对那些会咬人的东西确定。
还时不时有人问,为什么一个税务部门要自己搭这个,而不是等四大之一。安永的目标是把境外税务合规自动化80%;毕马威于2026年2月推出了税务AI加速器。但那些工具是为事务所自己的业务打造的,包在六位数和七位数的项目里出售,而且它们验证的是事务所的工作——不是你的。你真正掌控的验证层,才是那个保护你真正签下的那个签名的层。
我会对早先的自己说些什么
税务合规每年让美国企业花费超过1,260亿美元,而整个行业针对这个数字投入AI是对的。拟制理应被自动化。错误在于以为一旦AI能起草申报表,活儿就干完了——而事实上瓶颈只是往下游挪了,挪到了验证环节,那里更难被看见,一旦出错也更昂贵。
我起步时以为难的部分是教会一台机器税法。结果难的部分恰恰相反:知道哪些问题绝不该允许一台机器去猜,并搭建那个拒绝让它猜的层。当每一款税务工具都跑在AI上的那一天,唯一真正剩下的问题就是谁来检查这个AI——而“同一个AI,只是问得更客气一点”并不是一个答案。如果你想看看我们是怎么搭建那道检查的,就在这里。
互联网在一项车贷扣除上错了,而每一台从中学习的机器都眼睛不眨地继承了这个错误。在法典的某处,还有成千上万个这样的错误在等着。真正的工作不是让AI更聪明。而是确保当整个世界都自信地错着时,你的税务立场不会错。