
我測試的每一個稅務AI都把同一項扣除額弄錯了——因為整個網際網路都錯了
我開了兩台螢幕。左邊是法條:《國內稅收法典》第63(b)(7)條——《綜合預算調節法》藉以創設一項新扣除額的條款,適用於合格載客車輛貸款的利息。右邊是H&R Block自家的網站,把同一項扣除額描述為一種「線上(above-the-line)優惠」。
這兩個畫面不可能都對。第63(b)(7)條降低的是應稅所得——它是一項線下(below-the-line)扣除額,不會觸及調整後總所得。「線上(above-the-line)」的意思恰恰相反。全美規模最大的報稅品牌之一,在其公開網站上把一項扣除額的方向弄反了,而截至2026年4月,這個錯誤依然存在。
這本來只會是個註腳,若不是我開始就此事詢問AI後所發生的一切。我把這個問題丟給了幾個領先的大型語言模型——正是各家公司如今紛紛接入報稅流程的那些稅務合規AI工具。它們每一個都以無懈可擊的文法和貌似可信的引用告訴我,這項扣除額是線上(above-the-line)扣除。它們讀的都是同一個網際網路。而這個網際網路是錯的。
當每一個AI都給你同一個錯誤答案時,那不是故障。那是訓練資料在投票,而真相落敗了。
就是在那一刻,我正在打造的這家公司變得清晰起來。整個產業都在競相讓AI更快地編製稅務申報表。幾乎沒有人在打造那個能在AI自信而系統性地出錯時把它抓出來的東西。這個缺口,正是Veriprajna稅務合規AI驗證層存在的目的。
會連鎖擴散的錯誤
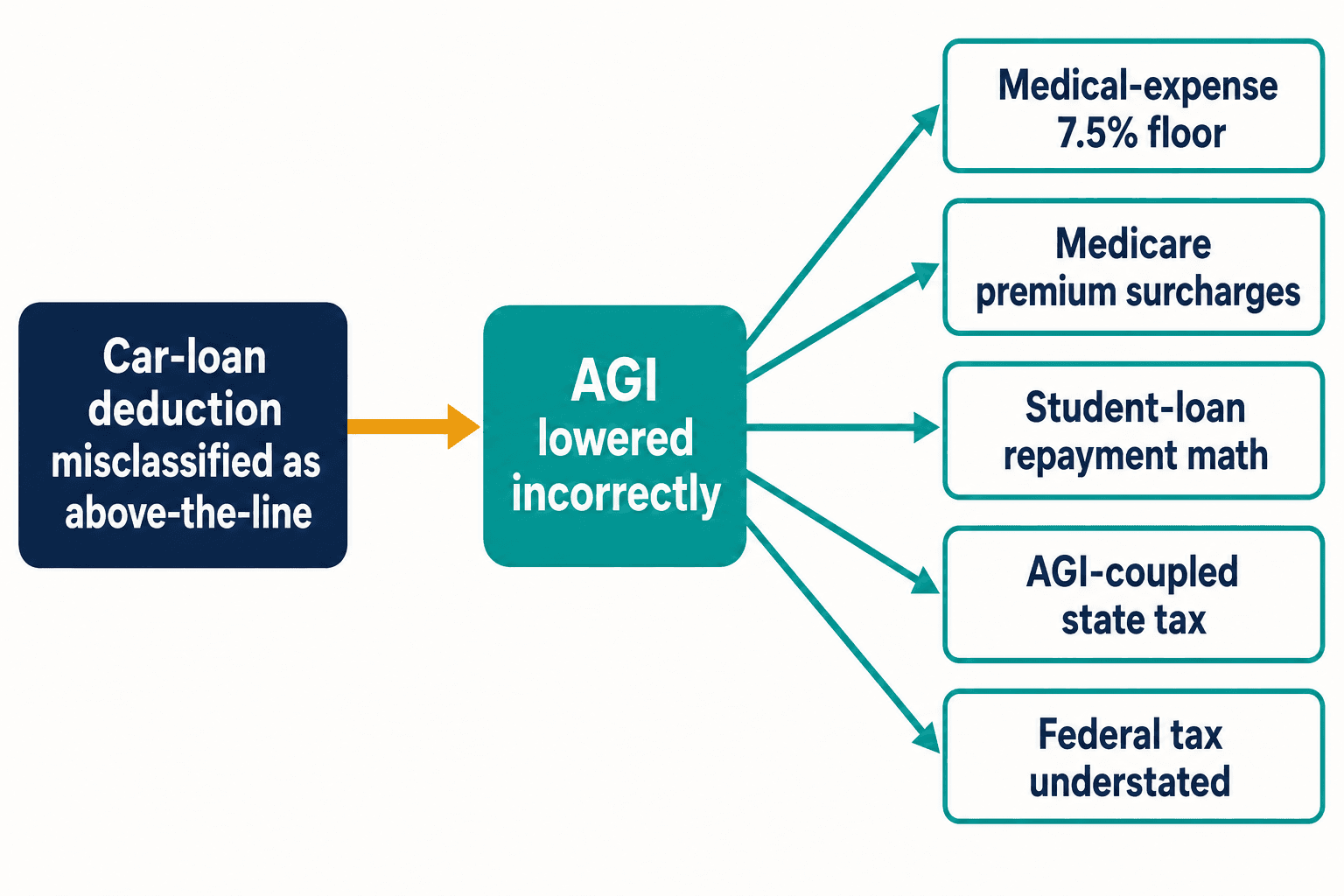
以下就是為什麼一項方向弄反的扣除額讓我夜不能寐。像這種車貸扣除額的錯誤分類不會被侷限住。把這項扣除額當作線上(above-the-line)扣除,你就降低了本不該變動的調整後總所得。AGI在稅法中具有承重作用。它牽動7.5%的醫療費用扣除門檻。它牽動聯邦醫療保險與所得掛鉤的保費附加費。它牽動學生貸款依所得而定的還款計算。在稅制與聯邦AGI連動的州,它還悄悄低報了州稅。
一個錯誤的token,五項下游計算錯誤——而這還只是出自單一條款。《國內稅收法典》有數以千計的條款。根據納稅人權益維護處(Taxpayer Advocate Service)的資料,國會在2000年至2020年間平均每年對它做出420項修改。每一次新的修改,都是部落格圈搶在官方指引塵埃落定之前先行發聲的新機會,也是下一代模型純粹因為重複而學到錯誤版本的新機會。
而付出代價的並不是演算法。當一份申報表出錯時,依IRS手冊而課予的20%與正確性相關的罰款,會落在簽名欄上署名、並在偽證處罰下簽署的那個人身上。起草它的模型既沒有PTIN,也不負任何責任。我不斷回想到這種不對稱。我們正要把起草工作交給機器,卻把風險曝露留給人。
我為何不再相信檢索能拯救我們
我最初的直覺跟每個人一樣:把真正的法律餵給模型。檢索增強生成(retrieval-augmented generation,即RAG——系統在回答前先查出真實法條並交給模型)本應是解方。籌得1.22億美元D輪融資的Blue J建的正是這個:在GPT-4.1之上做RAG,並與IBFD合作,橫跨220多個司法管轄區。是嚴肅之人所做的嚴肅工程。
於是我們也建了自己的檢索原型。我看著它調出第63(b)(7)條的正確條文——然後照樣把它總結錯了。
那場示範打破了我的假設。檢索起作用了,詮釋卻沒有。稅法中的修正條文讀起來像「第163(h)條經由插入……而修訂」——你必須從片段中重建法律的現行狀態,而一個內部權重已吸收了數百萬則「線上(above-the-line)」部落格文章的模型,會表現得像一個帶有偏見的讀者。它看到了正確的法條,卻仍然聽到了錯誤的共識。把正確的文件交給一台機率引擎,並不能使它推理;它只是給一個自信的錯誤答案,配上一則更好看的引用。
檢索能讓模型拿到正確的文本。它對模型早已打定主意這件事卻無能為力。
我們開始把這稱為共識錯誤(Consensus Error)——當每一個AI都收斂到同一個錯誤答案,因為它們所學習的公開紀錄本身就是錯的。這在通常意義上並不是幻覺。幻覺是隨機的。這是系統性的、可重現的,並且為每一個在開放網路上訓練的模型所共有。這個區別改變了我對整個問題的思考方式。
「把GPT包裝一下就出貨」
有一段時間,我真的懷疑自己是不是把它想得太複雜了。一位我敬重的顧問差不多是這麼跟我說的:別再空談哲學了——包裝一個好模型,加上檢索,把它出貨,讓市場來決定。許多資金充裕的公司正是這麼做的。
我們爭論的焦點歸結到一個被不斷引用的數字:Blue J報稱其異議率低於七百分之一。它聽起來像是一個準確度指標。它不是。它衡量的是使用者多常與工具意見相左——而一個本來就不知道正確答案的從業者,無法對一個錯誤答案表示異議。這個指標恰恰在危險所在之處噤聲不語:那個自信、貌似可信、卻錯誤的答案,對面沒有人具備足以質疑它的知識。
異議率衡量的是使用者的信心,而非模型的正確性。在一個高罰款的立場上,這兩者並不是同一回事——而兩者之間的落差,正是罰款棲身之處。
我曾為了「大概對」算不算是一種產品而失眠。在格式問題上,它算。在一個正確性罰款為少繳稅額20%、詐欺罰款為75%的稅務立場上,「大概對」是一種你已經自動化並規模化了的法律責任。就是這個論點終結了「包裝GPT」的計畫。機率式工具是回答確定性問題的錯誤工具,無論那些機率變得多好都一樣。
確定性驗證究竟能為你帶來什麼?
最懂這一點的供應商並不是那些聊天機器人——而是那些間接稅引擎。Vertex維護著超過3億筆稅率。Avalara在2025年底接受了貝萊德(BlackRock)5億美元的投資,它與Sovos在超過12,000個司法管轄區執行申報。對於它們所涵蓋的情境,它們是100%確定性的,並具備完整的稽核軌跡。同一個稅率問題問它們一千次,你會得到一千次相同的答案,而且你能向稽核員精確說明為什麼。
但那些引擎讀不懂一個句子。它們無法對事實與情境測試進行推理,而新增一條規則意味著要由人手工編寫。於是這個領域清楚地一分為二:可靠的引擎讀不懂語言,而讀得懂語言的系統又不可靠。
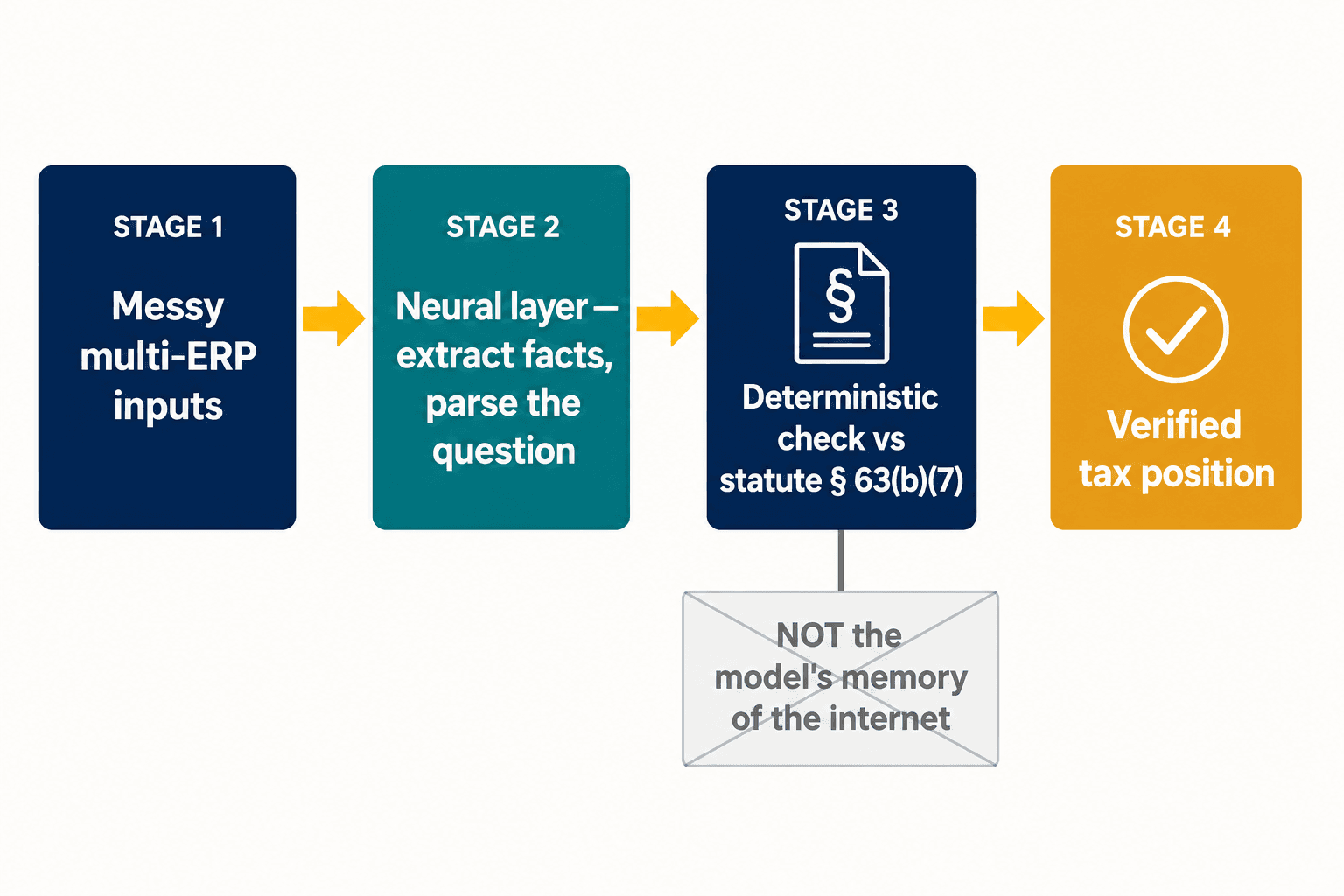
那道分裂就是整個設計難題所在,也是我們的架構落腳之處。我們不試圖讓單一模型同時具備創造力與確定性。我們讓神經層去做神經模型擅長的事——讀取雜亂的輸入、從一份申報表中提取結構化的事實、解析從業者實際在問的是什麼。然後,對於那些正確性不容妥協的條款,答案會針對法條本身的一種確定性表述來檢查,而不是針對模型對於網際網路怎麼說它的記憶。車貸扣除額之所以位於線下,是因為第63(b)(7)條這麼說,句號——而不是因為模型權衡了證據,而證據恰好是錯的。
重點不在於取代湯森路透(Thomson Reuters)或威科集團(Wolters Kluwer)。CCH Axcess Expert AI已嵌入10,000家事務所;ONESOURCE聲稱把例行報表作業時間縮短了65%。那些工具在編製方面很出色,而編製如今在很大程度上已是一個解決了的問題。這個驗證層位於之上——凌駕於你已在運行的任何工具之上,不偏向任何供應商,並在系統性錯誤送達IRS之前將它們攔截下來。湯森路透驗證湯森路透。威科集團驗證威科集團。沒有人在跨越這一切、針對真實基準、為那些真正會招致罰款的立場進行驗證。
對大型跨國企業而言,問題在AI開口之前就已層層疊加。約有78%的公司運行著四到七套不同的ERP系統,而安永(EY)發現,半數稅務主管把缺乏可持續的資料與科技規劃列為他們最大的單一障礙。再疊上支柱二(Pillar Two)——這個全球最低稅制要求實體層級的資料與可靠的公司間報告,而在某些地區僅約15%的組織自稱已完全準備就緒——那麼最薄弱的一環根本不是模型的推理;而是餵給它的結構化事實一開始是否就正確。這就是工作的另一半:那個把雜亂的多系統輸入轉化為AI或確定性引擎皆可信賴之物的神經提取層。
為什麼稅務AI突然變成了一個特權問題,而非安全問題?
有一陣子,我把封閉系統這項要求當作一種安全偏好——有了很好,是企業衛生的一環。然後在2026年2月,紐約南區聯邦地區法院(SDNY)作出了Heppner裁決,它便不再是可有可無的了。
簡而言之:把客戶的事實貼進一個公開的AI工具,可能會使那些通訊喪失律師與委託人之間的保密特權。對一個稅務部門來說,這重新界定了一切。在公開聊天機器人與封閉的、由企業掌控的系統之間做選擇,已不再關乎資料衛生——它關乎你享有特權的分析是否仍然享有特權。IRS在同一季強化了這個方向:其AI治理政策IRM 10.24.1,如今把作為具法律或重大效果之決定主要依據的生成式AI輸出歸類為「高影響」,要求加強監督。監理機關正以他們自己的語言告訴你:一個未經驗證的AI稅務立場是一項高影響風險。
在Heppner之後,你為稅務AI所選擇的架構,在成為一個工程決策之前,先是一個特權決策。
這並非假想中的危害。《會計時代》(Accountancy Age)在2026年3月報導,半數英國會計師知曉有企業因錯誤的AI建議而蒙受直接的財務損失。研究人員已在25個國家記錄了約800起AI引用錯誤案例。與此同時,IRS正把其大型企業稽核率從8.8%提高至22.6%。更多由AI起草的立場、更多的稽核,再加上一項會落在簽署者身上的罰款——這就是那條相撞的航線。
我最常聽到的反對意見
人們問我,更好的模型會不會自己就把這問題解決了。不會,而且原因不在於模型沒有進步。共識錯誤是資料的一種屬性,而非模型大小的屬性。一個在同一個錯誤網際網路上訓練的更大模型,只會把錯誤答案學得更流暢,而不是更少。你無法用規模去勝過一個會隨著你一起擴張的問題。
我聽到的另一件事:一個確定性層難道不就是些脆弱的硬編碼規則,跟不上一年420項的法典修改嗎?如果我們試圖把整部法典都編進去,那的確會如此。我們並不這麼做。這個驗證層鎖定的是高罰款、高連鎖效應的條款——那少數幾個一旦自信地弄錯就會付出真金白銀的條款——並把例行的那九成留給那些已經處理得很好的編製工具。你不需要對每一件事都確定。你需要的是對那些會咬人的事有確定性。
還時不時有人問,為什麼一個稅務部門該自己來建這個,而不是等四大會計師事務所(Big Four)之一。安永(EY)的目標是把海外稅務合規自動化80%;安侯建業(KPMG)在2026年2月推出了一個稅務AI加速器(Tax AI Accelerator)。但那些工具是為事務所自己的委任案而建、在六位數與七位數的專案內出售的,而且它們驗證的是事務所的工作——不是你的。你真正能掌控的驗證層,才是那個保護你真正簽下的那個簽名的驗證層。
我想對過去的自己說的話
稅務合規每年讓美國企業付出超過1,260億美元,而這個產業把AI砸向這個數字是對的。編製理當被自動化。錯誤在於假設:一旦AI能起草申報表,工作就完成了——而事實上瓶頸只是往下游移動了,移到了驗證,那裡更難被看見,一旦弄錯也更昂貴。
我起初以為困難的部分是教一台機器懂稅法。結果困難的部分恰恰相反:知道有哪些問題是一台機器絕不該被允許去猜測的,並打造那個拒絕讓它去猜的層。當每一個稅務工具都跑在AI上的那一天,唯一真正剩下的問題就是誰來檢查這個AI——而「同一個AI,只是更禮貌地問一遍」並不是一個答案。如果你想看看我們是怎麼打造那道檢查的,就在這裡。
網際網路對一項車貸扣除額弄錯了,而每一台從中學習的機器都眼睛也不眨地繼承了這個錯誤。在法典的某處,還有數以千計那樣的錯誤,正等待著。這項工作不是要讓AI更聰明。而是要確保,當全世界都自信地錯了的時候,你的稅務立場不會錯。