
כל בינה מלאכותית למס שבדקתי טעתה באותו ניכוי — מפני שהאינטרנט טעה
היו לי שני מסכים פתוחים. משמאל, החוק: סעיף 63(b)(7) של קוד ההכנסה הפנימי (Internal Revenue Code), ההוראה שחוק Omnibus Budget Reconciliation Act השתמש בה כדי ליצור ניכוי חדש עבור ריבית על הלוואות לרכבי נוסעים כשירים. מימין, האתר של H&R Block עצמו, שמתאר את אותו הניכוי כ"תמריץ מעל הקו".
שני המסכים האלה לא יכולים שניהם להיות צודקים. סעיף 63(b)(7) מפחית את ההכנסה החייבת במס — זהו ניכוי מתחת לקו. הוא אינו נוגע בהכנסה ברוטו מותאמת. "מעל הקו" משמעו ההפך. אחד ממותגי הכנת המס הגדולים באמריקה טעה בכיוון של ניכוי באתר הציבורי שלו, ונכון לאפריל 2026 הוא עדיין טועה.
זו הייתה נותרת הערת שוליים, לולא מה שקרה כשהתחלתי לשאול בינה מלאכותית על כך. הצגתי את השאלה לכמה מודלי שפה גדולים מובילים — אותם כלי בינה מלאכותית לציות מס שחברות מחברות כעת לתהליך הכנת הדוחות. כל אחד מהם אמר לי, בדקדוק נקי ובציטוט סביר, שהניכוי הוא מעל הקו. כולם קראו את אותו האינטרנט. והאינטרנט טעה.
כשכל בינה מלאכותית נותנת לך את אותה תשובה שגויה, זו לא תקלה. אלה נתוני האימון שמצביעים, והאמת שמפסידה.
זה היה הרגע שבו החברה שבניתי התחדדה בעיניי. התעשייה רצה להפוך את הבינה המלאכותית למכינה של דוחות מס מהר יותר. כמעט אף אחד לא בנה את הדבר שתופס אותה כאשר הבינה המלאכותית טועה בביטחון ובאופן שיטתי. הפער הזה הוא מה ששכבת אימות הבינה המלאכותית לציות מס של Veriprajna נועדה למלא.
השגיאה שמשתלשלת
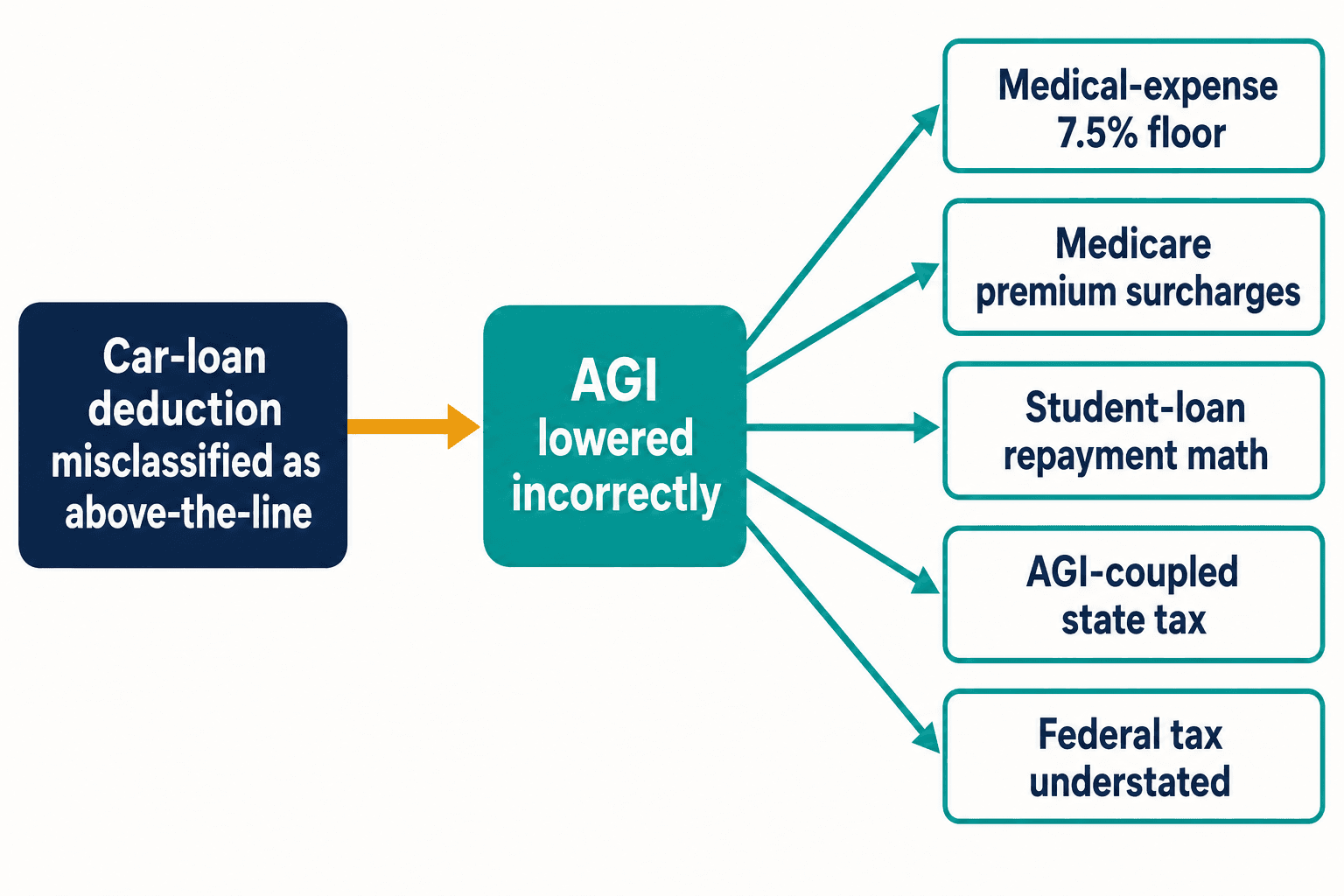
הנה למה ניכוי הפוך יחיד הדיר שינה מעיניי. סיווג שגוי כמו זה של הלוואת הרכב לא נשאר תחום. תתייחס לאותו ניכוי כאל מעל הקו ותפחית הכנסה ברוטו מותאמת שלעולם לא הייתה אמורה לזוז. הכנסה ברוטו מותאמת (AGI) נושאת משקל בקוד המס. היא מזינה את רצפת ניכוי ההוצאות הרפואיות של 7.5%. היא מזינה את תוספות הפרמיה של Medicare התלויות בהכנסה. היא מזינה את חישוב ההחזר מבוסס-ההכנסה של הלוואות סטודנטים. במדינות שבהן המס צמוד ל-AGI הפדרלי, היא גם מפחיתה בשקט את מס המדינה.
אסימון שגוי אחד, חמישה חישובים שגויים במורד הזרם — וזה מהוראה יחידה. לקוד ההכנסה הפנימי יש אלפים כאלה. הקונגרס ביצע בו בממוצע 420 שינויים בשנה בין 2000 ל-2020, לפי שירות הסנגור לנישום (Taxpayer Advocate Service). כל שינוי טרי הוא הזדמנות טרייה לבלוגוספרה להגיע לשם לפני שההנחיות הרשמיות מתייצבות, ולדור הבא של המודלים ללמוד את הגרסה השגויה מתוך חזרה גרידא.
ומי שמשלם אינו האלגוריתם. כאשר דוח שגוי, קנס דיוק בשיעור 20% לפי מדריך ה-IRS נוחת על האדם ששמו על שורת החתימה, החתום תחת עונש של עדות שקר. למודל שניסח אותו אין PTIN ואין אחריות. חזרתי שוב ושוב לאותה אסימטריה. עמדנו למסור את הניסוח למכונות ולהשאיר את החשיפה אצל בני האדם.
למה הפסקתי להאמין שאחזור יציל אותנו
האינסטינקט הראשון שלי היה אותו אחד שיש לכולם: להזין למודל את החוק עצמו. אחזור מוגבר-יצירה — RAG, שבו המערכת מחפשת את החוק האמיתי ומוסרת אותו למודל לפני שהוא עונה — היה אמור להיות הפתרון. Blue J, שגייסה סבב D בסך 122M$, בנתה בדיוק את זה: RAG מעל GPT-4.1, עם שותפות IBFD המשתרעת על יותר מ-220 תחומי שיפוט. הנדסה רצינית של אנשים רציניים.
אז בנינו אב-טיפוס אחזור משלנו. וראיתי אותו שולף את הטקסט הנכון של סעיף 63(b)(7) — ואז מסכם אותו בכל זאת בצורה שגויה.
זו הייתה ההדגמה ששברה את ההנחה שלי. האחזור עבד. הפרשנות לא. שפת התיקונים בקוד המס נקראת כמו "סעיף 163(h) מתוקן על ידי הוספת…" — צריך לשחזר את המצב הנוכחי של החוק מתוך שברים, ומודל שהמשקלים הפנימיים שלו ספגו מיליוני פוסטים של בלוגים על "מעל הקו" פועל כקורא מוטה. הוא רואה את החוק הנכון ועדיין שומע את הקונצנזוס השגוי. מסירת המסמך הנכון למנוע הסתברותי אינה גורמת לו להסיק מסקנות; היא רק נותנת לתשובה שגויה-בביטחון ציטוט שנראה טוב יותר.
אחזור מספק למודל את הטקסט הנכון. הוא אינו עושה דבר לגבי כך שהמודל כבר גיבש את דעתו.
התחלנו לקרוא לזה שגיאת קונצנזוס — כאשר כל בינה מלאכותית מתכנסת לאותה תשובה שגויה משום שהרשומה הציבורית שממנה למדה שגויה בעצמה. זו אינה הזיה במובן הרגיל. הזיה היא אקראית. זו שיטתית, ניתנת לשחזור, ומשותפת לכל מודל שאומן על הרשת הפתוחה. ההבחנה הזו שינתה את האופן שבו חשבתי על כל הבעיה.
"פשוט עטוף את GPT ושחרר אותו"
היה פרק זמן שבו באמת תהיתי אם אני מסבך את זה יתר על המידה. יועץ שאני מכבד אמר לי, פחות או יותר, להפסיק לפלסף — לעטוף מודל טוב, להוסיף אחזור, לשחרר, ולתת לשוק להחליט. לא מעט חברות ממומנות היטב עשו בדיוק את זה.
הוויכוח שהיה לנו הסתכם במספר אחד שמצוטט ללא הרף: Blue J מדווחת על שיעור אי-הסכמה נמוך מ-1 ל-700. זה נשמע כמו נתון דיוק. זה לא. הוא מודד באיזו תדירות משתמשים חולקים על הכלי — ומומחה שאינו יודע מראש את התשובה הנכונה אינו יכול לחלוק על תשובה שגויה. המדד שותק בדיוק במקום שבו שוכנת הסכנה: התשובה השגויה, הבטוחה והסבירה שלאיש בצד השני אין את הידע כדי לערער עליה.
שיעור אי-הסכמה מודד את ביטחון המשתמשים, לא את נכונות המודל. בעמדה בעלת קנס גבוה, אלה אינם אותו דבר — והפער ביניהם הוא המקום שבו שוכן הקנס.
איבדתי שינה על השאלה אם "כנראה צודק" הוא מוצר. בשאלה של עיצוב, הוא כן. בעמדת מס שבה קנס הדיוק הוא 20% מחסר-התשלום וקנס ההונאה הוא 75%, "כנראה צודק" הוא חבות שהפכת לאוטומטית והרחבת. זה היה הטיעון שסיים את תוכנית עטיפת-GPT. הסתברותי הוא הכלי הלא נכון לשאלה דטרמיניסטית, לא משנה עד כמה ההסתברויות משתפרות.
מה בעצם קונה לך אימות דטרמיניסטי?
הספקים שמבינים זאת הכי טוב אינם הצ'אטבוטים — הם מנועי המס העקיף. Vertex מתחזקת מעל 300 מיליון שיעורי מס. Avalara, שקיבלה השקעה של 500M$ מ-BlackRock בסוף 2025, ו-Sovos מריצות הגשה ביותר מ-12,000 תחומי שיפוט. עבור התרחישים שהם מכסים, הם דטרמיניסטיים ב-100% עם מסלולי ביקורת מלאים. שאל אותם את אותה שאלת שיעור אלף פעמים ותקבל את אותה התשובה אלף פעמים, ותוכל להראות למבקר בדיוק למה.
אבל המנועים האלה אינם יכולים לקרוא משפט. הם אינם יכולים להסיק מסקנות לגבי מבחן עובדות-ונסיבות, והוספת כלל חדש פירושה שאדם מקודד אותו ידנית. אז השדה מתפצל בבירור: המנועים האמינים אינם יכולים להבין שפה, והמערכות שמבינות שפה אינן אמינות.
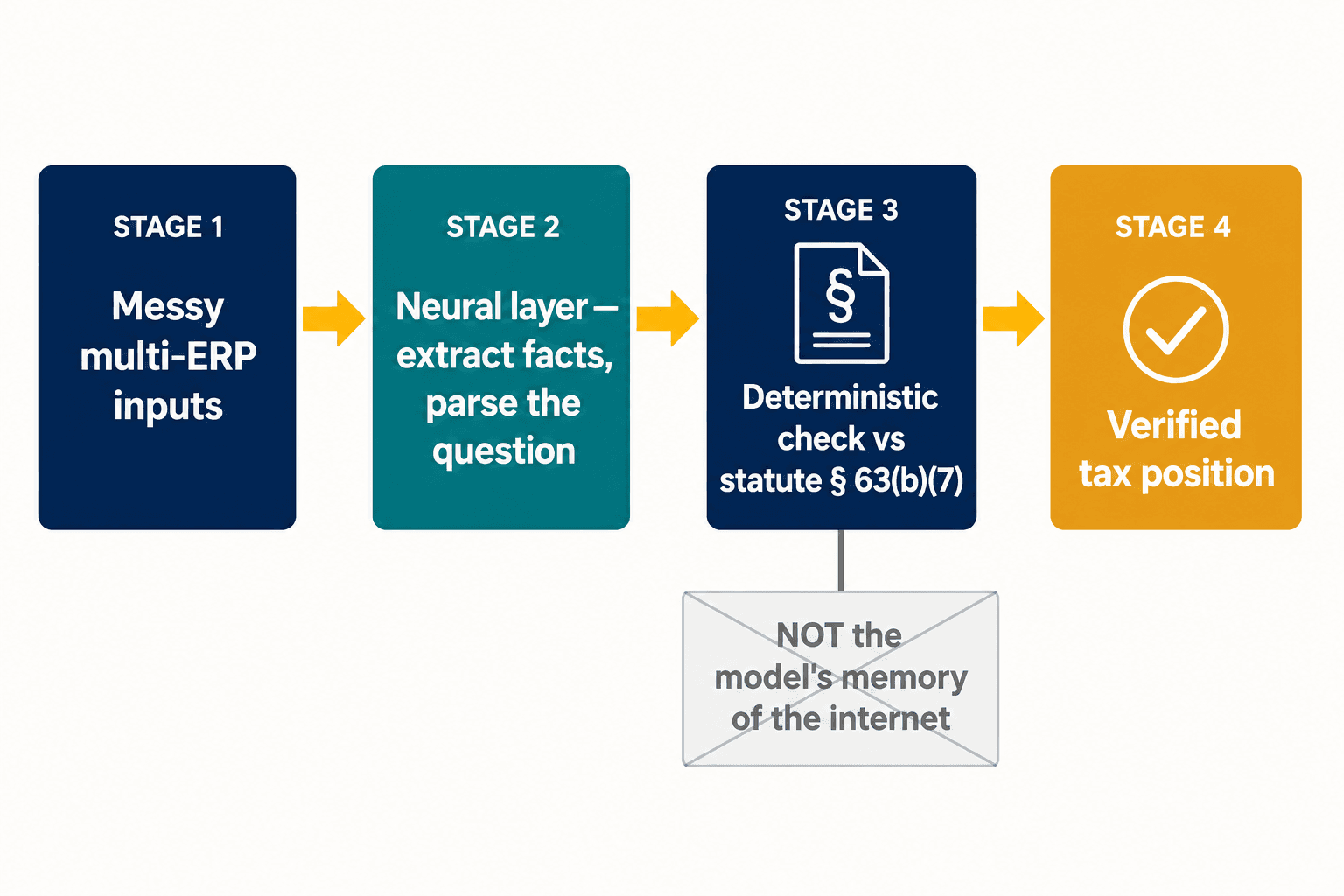
הפיצול הזה הוא כל בעיית העיצוב, וכאן ביססנו את הארכיטקטורה שלנו. אנחנו לא מנסים להפוך מודל אחד ליצירתי וּודאי כאחד. אנחנו נותנים לשכבה נוירונית לעשות את מה שמודלים נוירוניים טובים בו — לקרוא קלטים מבולגנים, לחלץ עובדות מובנות מדוח, לנתח מה מומחה באמת שואל. ואז, עבור ההוראות שבהן הנכונות אינה נתונה למשא ומתן, התשובה נבדקת מול ייצוג דטרמיניסטי של החוק עצמו, ולא מול זיכרון המודל של מה שהאינטרנט אמר עליו. ניכוי הלוואת הרכב שוכן מתחת לקו משום שסעיף 63(b)(7) אומר זאת, נקודה — לא משום שהמודל שקל את הראיות והראיות במקרה היו שגויות.
העניין אינו להחליף את Thomson Reuters או את Wolters Kluwer. CCH Axcess Expert AI מוטמע ב-10,000 משרדים; ONESOURCE טוענת להפחתה של 65% בזמן הדיווח השגרתי. הכלים האלה טובים בהכנה, וההכנה היא כיום בעיה שנפתרה במידה רבה. שכבת האימות יושבת מעל מה שאתה כבר מריץ, ניטרלית לספק, ותופסת את השגיאות השיטתיות לפני שהן מגיעות ל-IRS. Thomson Reuters מאמתת את Thomson Reuters. Wolters Kluwer מאמתת את Wolters Kluwer. אף אחד לא אימת על פני כל זה, מול אמת קרקעית, עבור העמדות שבאמת נושאות קנסות.
עבור תאגידים רב-לאומיים גדולים הבעיה מחריפה עוד לפני שהבינה המלאכותית פותחת את הפה. כ-78% מהחברות מריצות בין ארבע לשבע מערכות ERP שונות, ו-EY מצאה שמחצית ממנהיגי המס מציינים את היעדר תוכנית נתונים וטכנולוגיה בת-קיימא כמחסום הגדול ביותר שלהם. הוסף על כך את Pillar Two — משטר מס המינימום הגלובלי הדורש נתונים ברמת הישות ודיווח בין-חברתי אמין, שרק כ-15% מהארגונים באזורים מסוימים מדווחים שהם מוכנים לו במלואם — והחוליה החלשה ביותר אינה כלל ההיסק של המודל; היא השאלה אם העובדות המובנות שמזינות אותו נכונות מלכתחילה. זה החצי השני של העבודה: שכבת החילוץ הנוירונית שהופכת קלטים מבולגנים מרב-מערכות למשהו שבינה מלאכותית או מנוע דטרמיניסטי יכולים לסמוך עליו.
למה בינה מלאכותית למס היא לפתע שאלת חיסיון, לא שאלת אבטחה?
במשך זמן מה חשבתי על דרישת המערכת הסגורה כעל העדפת אבטחה — נחמד שיש, היגיינה ארגונית. ואז בפברואר 2026 בית המשפט של SDNY נתן את פסיקת Heppner, וזה חדל להיות אופציונלי.
הגרסה הקצרה: הדבקת עובדות של לקוח לתוך כלי בינה מלאכותית ציבורי עלולה לוותר על חיסיון עורך דין-לקוח לגבי אותן תקשורות. עבור מחלקת מס, זה ממסגר מחדש את הכול. הבחירה בין צ'אטבוט ציבורי לבין מערכת סגורה, מבוקרת-ארגון, כבר אינה עניין של היגיינת נתונים — אלא של השאלה אם הניתוח החסוי שלך נשאר חסוי. ה-IRS חיזק את הכיוון באותה עונה: מדיניות ממשל הבינה המלאכותית שלו, IRM 10.24.1, מסווגת כעת פלטים של בינה מלאכותית יוצרת המשמשים כבסיס העיקרי להחלטה בעלת אפקט משפטי או מהותי כ"בעלי השפעה גבוהה", ודורשת פיקוח מוגבר. הרגולטורים אומרים לך, בשפתם שלהם, שעמדת מס של בינה מלאכותית שאינה מאומתת היא סיכון בעל השפעה גבוהה.
לאחר Heppner, הארכיטקטורה שאתה בוחר לבינה מלאכותית למס היא החלטת חיסיון עוד לפני שהיא החלטה הנדסית.
זהו אינו נזק היפותטי. Accountancy Age דיווח במרץ 2026 שמחצית מרואי החשבון בבריטניה היו מודעים לעסקים שספגו הפסדים כספיים ישירים מייעוץ בינה מלאכותית שגוי. חוקרים תיעדו כ-800 מקרים של שגיאות ציטוט בבינה מלאכותית ב-25 מדינות. בינתיים ה-IRS מעלה את שיעור ביקורת התאגידים הגדולים שלו מ-8.8% לכיוון 22.6%. יותר עמדות שנוסחו בבינה מלאכותית, יותר ביקורות, וקנס שנוחת על החותם — זהו מסלול ההתנגשות.
ההתנגדויות שאני שומע הכי הרבה
אנשים שואלים אותי אם מודלים טובים יותר פשוט יפתרו את זה בעצמם. הם לא, ולא משום שהמודלים אינם משתפרים. שגיאת קונצנזוס היא תכונה של הנתונים, לא של גודל המודל. מודל גדול יותר שאומן על אותו אינטרנט שגוי לומד את התשובה השגויה בשטף רב יותר, לא פחות. אי אפשר לגבור בקנה מידה על בעיה שגדלה יחד איתך.
הדבר האחר שאני שומע: האם שכבה דטרמיניסטית אינה סתם כללים נוקשים ומקודדים-קשיח שאינם יכולים לעמוד בקצב של 420 שינויי קוד בשנה? היא כן הייתה, אילו ניסינו לקודד את כל הקוד. אנחנו לא. שכבת האימות מכוונת להוראות בעלות הקנס הגבוה והמפל הגבוה — קומץ המקרים שבהם טעות בטוחה עולה כסף אמיתי — ומשאירה את התשעים האחוזים השגרתיים לכלי ההכנה שכבר מטפלים בהם היטב. אינך זקוק לוודאות לגבי הכול. אתה זקוק לוודאות לגבי הדברים שנושכים.
ומדי פעם מישהו שואל למה מחלקת מס צריכה לבנות את זה במקום לחכות לאחת מ-Big Four. EY מכוונת לאוטומציה של 80% מציות המס הזר; KPMG השיקה Tax AI Accelerator בפברואר 2026. אבל הכלים האלה בנויים עבור ההתקשרויות של המשרד עצמו, נמכרים בתוך פרויקטים בני שש ושבע ספרות, והם מאמתים את עבודת המשרד — לא את שלך. שכבת האימות שאתה באמת שולט בה היא זו שמגנה על החתימה שאתה באמת חותם.
מה הייתי אומר לעצמי המוקדם יותר
ציות מס עולה לעסקים בארה"ב יותר מ-126 מיליארד דולר בשנה, והתעשייה צודקת בכך שהיא זורקת בינה מלאכותית על המספר הזה. הכנה צריכה להיות אוטומטית. הטעות היא בהנחה שברגע שהבינה המלאכותית יכולה לנסח את הדוח, העבודה הסתיימה — כאשר למעשה צוואר הבקבוק פשוט זז במורד הזרם, לאימות, שם קשה יותר לראות אותו ויקר יותר לטעות בו.
התחלתי את זה מתוך מחשבה שהחלק הקשה הוא ללמד מכונה דיני מס. החלק הקשה התברר כהפך: לדעת אילו שאלות מכונה לעולם לא צריכה לקבל רשות לנחש, ולבנות את השכבה שמסרבת לתת לה. ביום שבו כל כלי מס פועל על בינה מלאכותית, השאלה האמיתית היחידה שנותרת היא מי בודק את הבינה המלאכותית — ו"אותה בינה מלאכותית, שנשאלת בנימוס רב יותר" אינה תשובה. אם ברצונך לראות כיצד בנינו את הבדיקה הזו, היא כאן.
האינטרנט טעה לגבי ניכוי הלוואת רכב, וכל מכונה שלמדה ממנו ירשה את השגיאה מבלי למצמץ. איפשהו בקוד נמצאים אלפים נוספים כאלה, ממתינים. העבודה אינה להפוך את הבינה המלאכותית לחכמה יותר. היא לוודא שכאשר כל העולם טועה בביטחון, עמדת המס שלך אינה טועה.