
私がテストした税務AIは、どれも同じ控除を間違えた――インターネットが間違っていたからだ
モニターを2台開いていた。左側には法令、すなわち内国歳入法典第63条(b)(7)項――包括予算調整法(Omnibus Budget Reconciliation Act)が適格旅客車両ローンの利子に対する新たな控除を創設するために用いた条項だ。右側にはH&R Block自身のウェブサイトがあり、その同じ控除を「上乗せ型(above-the-line)のインセンティブ」と説明していた。
この2つの画面が両方とも正しいということはあり得ない。第63条(b)(7)項は課税所得を減らす――これは控除後(below-the-line)の控除だ。調整後総所得(AGI)には一切影響しない。「上乗せ型(above-the-line)」はその逆を意味する。米国最大級の税務申告ブランドの一つが、自社の公開サイトで控除の方向を逆に記載しており、2026年4月時点でもなおそのままだった。
それだけなら脚注で済む話だ――だが、私がAIにこれについて尋ね始めたときに起きたことは違った。私はいくつかの主要な大規模言語モデルにこの問いを投げかけた――まさに各社がいま申告書作成に組み込みつつある、あの税務コンプライアンスAIツールと同じものだ。そのどれもが、整った文法ともっともらしい引用を添えて、その控除は上乗せ型(above-the-line)だと答えた。それらはすべて同じインターネットを読んでいた。そしてそのインターネットが間違っていたのだ。
どのAIもあなたに同じ誤答を返すとき、それは不具合ではない。訓練データが投票し、真実が負けているのだ。
それが、私が立ち上げようとしていた会社の輪郭がはっきり見えた瞬間だった。業界は競って、AIに税務申告書を作成させるのを速くしようとしていた。だが、AIが自信満々に、しかも体系的に間違っているときにそれを捕まえるものを構築している者は、ほとんど誰もいなかった。その空白こそ、Veriprajnaの税務コンプライアンスAI検証レイヤーが埋めるために存在する。
連鎖する誤り
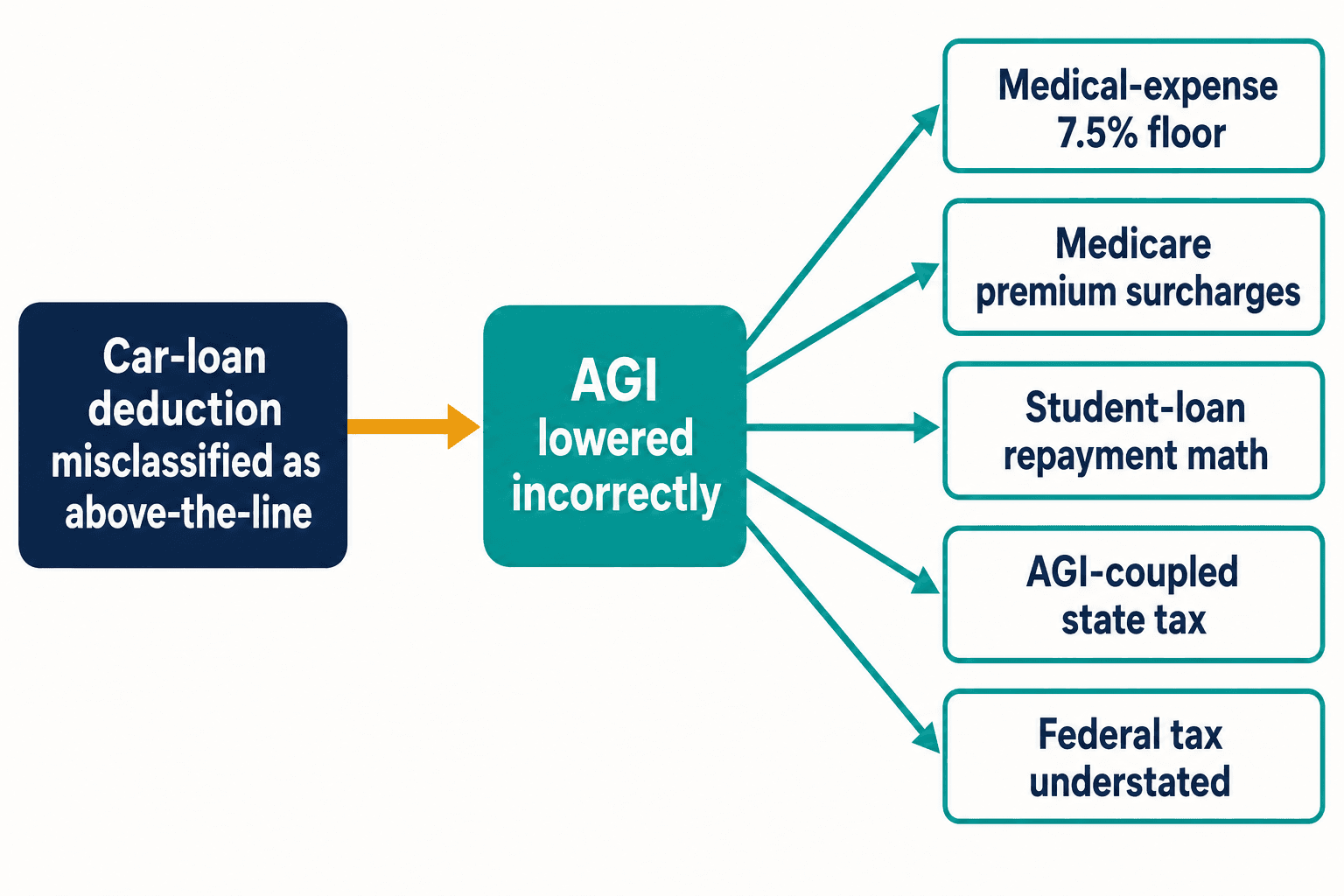
一つの逆向きの控除がなぜ私を眠らせなかったのか、その理由はこうだ。あの車両ローンのような誤分類は、一箇所にとどまらない。その控除を上乗せ型(above-the-line)として扱えば、本来動かすべきでない調整後総所得(AGI)を引き下げてしまう。AGIは税法典において荷重を担う。それは医療費控除の7.5%の下限(フロア)に影響する。メディケアの所得連動保険料上乗せに影響する。学生ローンの所得連動返済計算に影響する。州税が連邦AGIに連動している州では、州税までひそかに過少申告してしまう。
誤ったトークン一つで、下流の計算誤りが五つ――そしてこれはたった一つの条項からだ。内国歳入法典には数千の条項がある。納税者権利擁護局(Taxpayer Advocate Service)によれば、2000年から2020年の間に議会は年平均420回の改正を行った。新しい改正が一つ加わるたびに、公式ガイダンスが定まる前にブログ圏が先回りする新たな機会が生まれ、次世代のモデルが単なる反復によって誤った版を学習する新たな機会が生まれる。
そして、その代償を払うのはアルゴリズムではない。申告書が間違っていた場合、IRSマニュアルに基づく20%の正確性関連ペナルティは、署名欄に名前が載っている人間――偽証罪の罰則のもとで署名した人間――に降りかかる。それを起草したモデルにはPTINもなければ責任もない。私はこの非対称性に何度も立ち返った。私たちはまさに起草を機械に委ね、そのリスクは人間に残そうとしていたのだ。
検索(リトリーバル)が私たちを救ってくれると信じるのをやめた理由
私の最初の直感は、誰もが抱くのと同じものだった――モデルに実際の法律を与えればいい。検索拡張生成(RAG)――システムが本物の法令を調べ、答える前にそれをモデルに渡す仕組み――がその解決策になるはずだった。1億2,200万ドルのシリーズDを調達したBlue Jは、まさにこれを構築した。GPT-4.1の上にRAGを載せ、220以上の法域にまたがるIBFDとの提携を持つ。真剣な人々による真剣なエンジニアリングだ。
そこで私たちも独自の検索プロトタイプを構築した。そして私は、それが第63条(b)(7)項の正しい条文を引き出し――それでもなお、その要約を間違えるのを見た。
それが私の前提を打ち砕いたデモだった。検索は機能した。解釈は機能しなかった。税法典の改正文言は「第163条(h)項は、……を挿入することにより改正される」のように読める――断片から現行の法律の状態を再構成しなければならず、内部の重みに何百万もの「上乗せ型(above-the-line)」というブログ投稿を吸収したモデルは、偏った読み手として振る舞う。正しい法令を目にしながら、それでも誤った合意(コンセンサス)を聞き取ってしまう。確率エンジンに正しい文書を渡しても、それが推論するようにはならない。ただ、自信満々の誤答に、より見栄えのよい引用を与えるだけだ。
検索はモデルに正しい条文を届ける。だが、モデルがすでに心を決めてしまっていることについては、何もしない。
私たちはこれをコンセンサス・エラー(合意誤り)と呼び始めた――すべてのAIが同じ誤答に収束するのは、それらが学習した公的記録そのものが間違っているからだ。これは通常の意味でのハルシネーション(幻覚)ではない。ハルシネーションはランダムだ。これは体系的で、再現可能で、オープンウェブで訓練されたあらゆるモデルに共有されている。この区別が、私が問題全体をどう考えるかを変えた。
「GPTをラップして出荷すればいい」
私は本当に、自分が問題を複雑にしすぎているのではないかと悩んだ時期があった。私が尊敬するあるアドバイザーは、要するに、哲学するのはやめろと言った――良いモデルをラップし、検索を加え、出荷し、市場に判断させろ、と。潤沢な資金を持つ多くの企業が、まさにそれをやっていた。
私たちが交わした議論は、絶えず引用される一つの数字に行き着いた。Blue Jは異議率(disagree rate)が700分の1未満だと報告している。それは正確性の指標のように聞こえる。だが違う。それが測っているのは、ユーザーがそのツールにどれだけ異議を唱えるか――であって、正しい答えをそもそも知らない実務家は、誤った答えに異議を唱えることができない。この指標は、まさに危険が潜む場所――自信満々で、もっともらしく、そして誤っており、相手側にそれに異議を唱えるだけの知識を持つ者が誰もいない答え――について沈黙している。
異議率が測っているのはユーザーの自信であって、モデルの正しさではない。ペナルティの高いポジションにおいて、この二つは同じものではない――そして、その両者の隔たりこそがペナルティの潜む場所だ。
「たぶん正しい」が製品になり得るのかどうか、私は眠れなかった。書式の問題であれば、それでいい。しかし、正確性ペナルティが過少納付額の20%、詐欺ペナルティが75%となる税務ポジションにおいては、「たぶん正しい」は、あなたが自動化しスケールさせてしまった責任(liability)だ。それが、GPTをラップする計画に終止符を打った議論だった。確率論的なものは、確定的な問いに対しては誤ったツールだ――確率がどれほど良くなろうとも。
確定的検証は、実際のところあなたに何をもたらすのか
これを最もよく理解しているベンダーは、チャットボットではない――間接税エンジンだ。Vertexは3億を超える税率を維持している。2025年後半にBlackRockから5億ドルの投資を受けたAvalara、そしてSovosは、12,000を超える法域にまたがる申告を運用している。彼らがカバーするシナリオについては、100%確定的で、完全な監査証跡を備えている。同じ税率の問いを千回尋ねれば、千回とも同じ答えが返り、その理由を監査人に正確に示すことができる。
しかし、それらのエンジンは文章を読むことができない。事実と状況(facts-and-circumstances)のテストについて推論することはできず、新しいルールを追加するには人間が手作業でそれをコード化する必要がある。こうして分野はきれいに二分される――信頼できるエンジンは言語を理解できず、言語を理解するシステムは信頼できない。
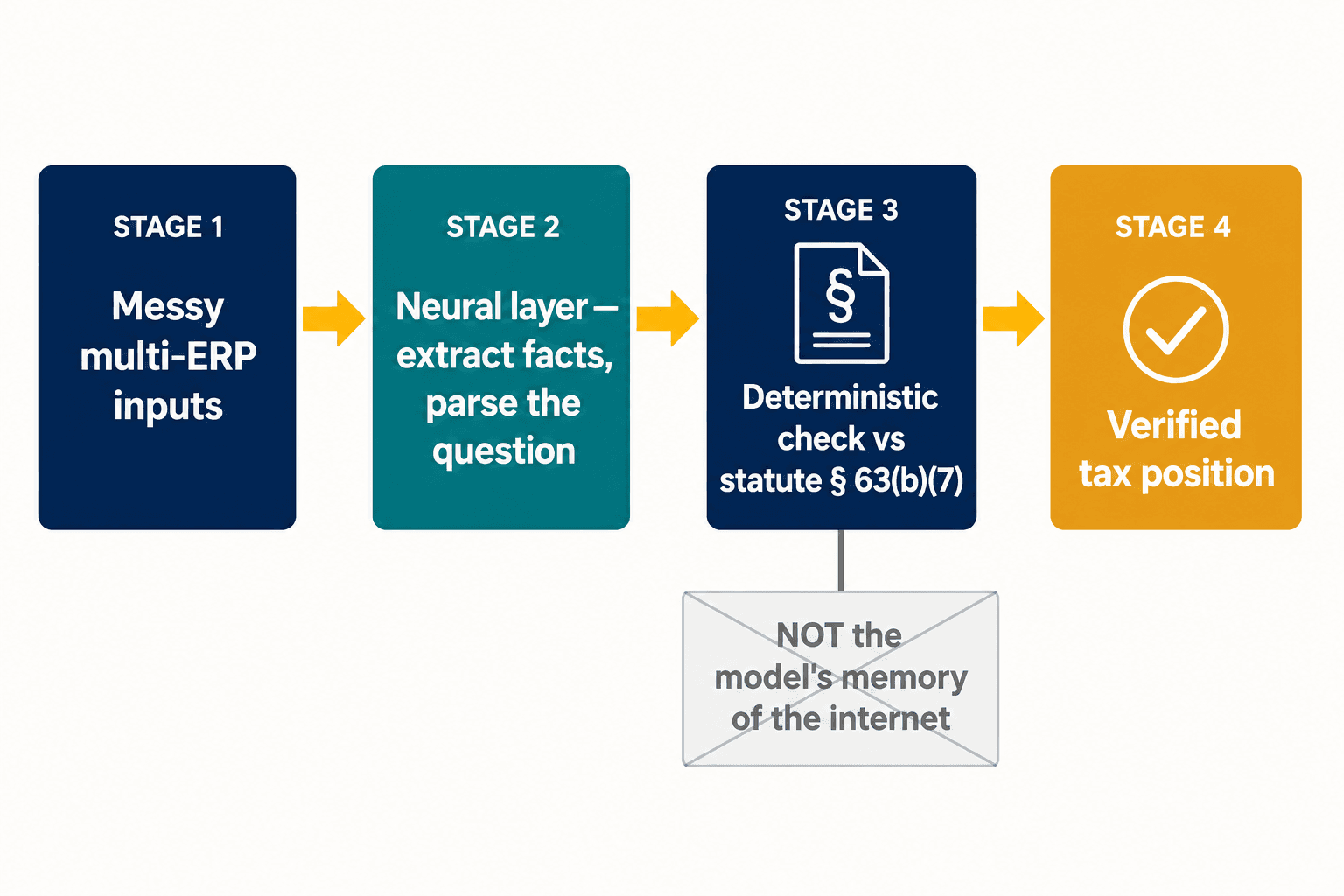
その分断こそが設計問題のすべてであり、そこに私たちのアーキテクチャは着地した。私たちは、一つのモデルを創造的かつ確実の両方にしようとはしない。ニューラル層には、ニューラルモデルが得意とすること――乱雑な入力を読み、申告書から構造化された事実を抽出し、実務家が実際に何を尋ねているのかを解析すること――をさせる。そして、正しさが交渉の余地なきものである条項については、その答えはモデルの記憶――インターネットがそれについて何と言っていたかの記憶――ではなく、法令そのものの確定的な表現に照らしてチェックされる。車両ローン控除が控除後(below-the-line)にあるのは、第63条(b)(7)項がそう言っているからだ、以上――モデルが証拠を検討し、その証拠がたまたま間違っていたから、ではない。
要点は、Thomson ReutersやWolters Kluwerを置き換えることではない。CCH Axcess Expert AIは10,000のファームに組み込まれており、ONESOURCEは定型報告時間の65%削減を謳っている。それらのツールは作成(preparation)が得意であり、作成はいまやおおむね解決済みの問題だ。検証レイヤーは、あなたがすでに運用しているものが何であれ、その上に載り、ベンダー中立で、体系的な誤りがIRSに届く前にそれを捕まえる。Thomson ReutersはThomson Reutersを検証する。Wolters KluwerはWolters Kluwerを検証する。それらすべてを横断して、真実(ground truth)に照らし、実際にペナルティを伴うポジションについて検証していた者は、誰もいなかった。
大規模な多国籍企業にとって、問題はAIが口を開く前から複合化する。およそ78%の企業が4~7種類の異なるERPシステムを運用しており、EYの調査では、税務リーダーの半数が、持続可能なデータおよびテクノロジー計画の欠如を最大の障壁として挙げている。そこに第2の柱(Pillar Two)――エンティティ単位のデータと信頼できるグループ間報告を要求する世界的最低税制で、一部の地域では組織のわずか約15%しか完全に対応できていると報告していない――が重なると、最も弱い環はモデルの推論ではまったくない。それは、そこに供給される構造化された事実がそもそも正しいかどうかだ。それが、作業のもう半分だ――乱雑な複数システムの入力を、AIまたは確定的エンジンが信頼できる何かへと変える、ニューラル抽出レイヤーである。
なぜ税務AIは突然、セキュリティの問題ではなく特権(privilege)の問題になったのか
しばらくの間、私はクローズドシステムの要件をセキュリティ上の好み――あれば良い、エンタープライズの衛生管理――程度に考えていた。ところが2026年2月、SDNY(ニューヨーク南部地区連邦地裁)がHeppner判決を下し、それは任意のものではなくなった。
かいつまんで言えば、クライアントの事実を公開AIツールに貼り付けると、それらのやり取りに関する弁護士・依頼者間特権(attorney-client privilege)を放棄する可能性がある、ということだ。税務部門にとって、これはすべての枠組みを変える。公開チャットボットと、クローズドでエンタープライズが管理するシステムとの選択は、もはやデータの衛生管理の話ではない――あなたの特権的分析が特権を保ち続けられるかどうかの話だ。IRSは同じ時期にその方向性を補強した。そのAIガバナンス方針であるIRM 10.24.1は、法的または重大な影響を持つ決定の主要な根拠となる生成AIの出力を「高影響(high-impact)」と分類し、強化された監督を求めるようになった。規制当局は、彼ら自身の言葉で、検証されていないAIの税務ポジションは高影響のリスクだと告げているのだ。
Heppner判決以後、税務AIのために選ぶアーキテクチャは、エンジニアリングの決定である前に、特権(privilege)の決定である。
これは仮説上の損害ではない。Accountancy Ageは2026年3月、英国の会計士の半数が、誤ったAIの助言によって直接的な金銭的損失を被った企業の存在を認識していたと報じた。研究者たちは、25カ国にわたっておよそ800件のAI引用エラー事例を記録している。その一方で、IRSは大企業に対する監査率を8.8%から22.6%へと引き上げつつある。AIが起草するポジションの増加、監査の増加、そして署名者に降りかかるペナルティ――それが衝突コースだ。
私が最もよく耳にする反論
人々は私に、より優れたモデルが登場すればこれは自然に解決されるのではないかと尋ねる。そうはならない。しかも、それはモデルが改善していないからではない。コンセンサス・エラーはデータの性質であって、モデルの規模の性質ではない。同じ誤ったインターネットで訓練された、より大きなモデルは、誤った答えを、より流暢に――少なくではなく――学習する。あなたと共にスケールする問題を、スケールで打ち負かすことはできない。
もう一つよく耳にするのは、確定的レイヤーとは、年420回のコード改正についていけない、脆く固定コード化されたルールにすぎないのではないか、というものだ。もし私たちがコード全体を符号化しようとするなら、確かにそうなるだろう。だが私たちはそうしない。検証レイヤーは、ペナルティが高く、連鎖が大きい条項――自信満々に間違うことが現実の金銭を要する、あの一握りの条項――を標的とし、定型的な残り90パーセントは、すでにそれをうまく処理している作成ツールに委ねる。すべてについて確実性が必要なわけではない。噛みついてくるものについての確実性が必要なのだ。
そして時折、なぜ税務部門は四大会計事務所(Big Four)のいずれかを待つのではなく、自らこれを構築すべきなのか、と尋ねる人がいる。EYは海外税務コンプライアンスの80%自動化を目指しており、KPMGは2026年2月にTax AI Acceleratorを立ち上げた。だが、それらのツールはそのファーム自身の業務のために作られ、六桁・七桁のプロジェクトの内側で販売され、そしてそれらが検証するのはそのファームの仕事であって――あなたの仕事ではない。あなたが実際に管理できる検証レイヤーこそが、あなたが実際に署名する署名を守るものだ。
かつての自分に伝えたいこと
税務コンプライアンスは米国企業に年間1,260億ドル超のコストを負わせており、業界がその数字にAIをぶつけようとするのは正しい。作成は自動化されるべきだ。誤りは、いったんAIが申告書を起草できるようになれば仕事は終わりだ、と思い込むことにある――実際にはボトルネックは下流の検証へと移動しただけであり、そこはより見えにくく、間違えたときにより高くつく。
私はこれを始めたとき、難しいのは機械に税法を教えることだと思っていた。ところが難しいのはその逆だった。すなわち、どの問いを機械に決して推測させてはならないのかを知ること、そしてそれを許さないレイヤーを構築することだった。あらゆる税務ツールがAIで動く日、残る唯一の本当の問いは、誰がそのAIをチェックするのか、ということだ――そして「同じAIに、より丁寧に尋ねる」は答えにならない。私たちがそのチェックをどう構築したかを見たいなら、こちらへ。
インターネットは車両ローン控除について間違っており、そこから学習したあらゆる機械が、まばたき一つせずにその誤りを受け継いだ。コードのどこかには、そうしたものがさらに数千、待ち構えている。仕事はAIをより賢くすることではない。世界全体が自信満々に間違っているとき、あなたの税務ポジションだけはそうならないようにすること――それが仕事だ。