
A Facial Recognition Vendor Scored 99% — and Still Flagged Innocent Shoppers All Day
The vendor's algorithm was ranked in the top tier of the U.S. government's own benchmark. On a gallery of twelve million mugshots, the leading face-recognition systems now hit better than 99% accuracy. The number was real, the certificate was real, and I had used it to reassure a pilot customer that their loss-prevention deployment was sound.
Then we ran their actual store data, and the system flagged innocent shoppers all day long.
That gap — between a 99% benchmark score and a system that confronts the wrong grandmother in aisle six — is the whole subject of this essay. Facial recognition compliance is almost never an algorithm problem. It's a procurement problem, a data problem, and a governance problem wearing an algorithm's clothes. I learned that the expensive way, and it's why my team at Veriprajna ended up auditing biometric systems against the regulations, benchmarks, and operational standards that actually matter instead of just scoring vendors' accuracy.
The Scorecard I Built First Was the Wrong Tool

When I started, I thought the audit was obvious. Read the NIST Face Recognition Vendor Test — the National Institute of Standards and Technology runs the most respected independent benchmark in the field — pull the vendor's rank, score it, hand the customer a green check. I built exactly that: a tidy vendor accuracy scorecard.
The pilot was a retail chain with a watchlist of known organized-theft suspects. Their vendor was a genuine top performer on FRVT. By my scorecard, they passed cleanly. So when their stores kept generating alerts on people who clearly weren't on any list, I assumed it was a tuning issue and went looking for the bug in the threshold.
There was no bug. The math was working exactly as designed — I had just audited the wrong thing.
A benchmark tells you how an algorithm performs in the lab. It tells you almost nothing about how it will behave in your store.
Here's what I had missed. NIST's headline accuracy comes from closed-set matching: given a face, find its match in a known gallery. That's the phone-unlock problem — is this the owner, yes or no. But a retail watchlist is an open-set problem, and the two are not cousins. In a store with 8,000 daily visitors and a 200-person watchlist, 97.5% of every scan is against someone who isn't enrolled at all. A closed-set algorithm strains to find the best match for every face it sees. Point it at that volume and even a 0.1% false-positive rate throws roughly 8 wrong alerts per store per day. Across 500 locations, that's 4,000 innocent people flagged daily. I had certified a system on the wrong question entirely.
That was the failure that rebuilt the company's approach. We stopped scoring vendors and started auditing deployments.
The False Positives Were Hiding in the Photo Album
The second surprise was where the bad matches actually came from. I had assumed a wrong match meant a weak model. Then I sat down with a customer's enrollment gallery — the actual set of watchlist images the system compares faces against — and pulled up the thumbnail grid.
It was a mess. A handful of clean, controlled headshots. And then dozens of grainy CCTV stills, cell-phone snapshots, and booking photos that were a decade old. You cannot reliably match a live 2026 face against a low-resolution 2014 booking photo, and no algorithm rank in the world fixes that. The contamination was in the data, not the model.
This is the part nobody audits. Enterprises obsess over which vendor to buy and never inspect the gallery they're feeding it — the unpruned watchlists, the stale captures, the resolution mismatches that drive most real-world false positives. When we started treating enrollment-database hygiene as a first-class part of the audit, the false-alert rates in pilots dropped before we touched a single threshold.
And those false alerts are not evenly distributed. NIST's demographic testing found that within-group false-positive rates vary by up to 7,203 times across demographic groups — children, the elderly, and Asian and American Indian subjects all see elevated rates, partly because darker skin tones impose harder dynamic-range capture requirements that cheap cameras don't meet. This isn't theoretical. When the Federal Trade Commission examined Rite Aid's deployment, it found that stores in plurality-Black and Asian communities generated significantly more false alerts than stores in plurality-White communities. Employees, untrained in the system's limits, treated each alert as fact and confronted customers accordingly.
The question that should keep a retail risk officer up at night isn't "is our vendor accurate." It's "whose faces is our gallery worst at, and what do our employees do when the screen lights up."
What 108 Days in Jail Looks Like
If you want to know why I think the human-review step is the whole ballgame, read the Angela Lipps file.
Lipps is a 50-year-old grandmother. In July 2025, Fargo police used facial recognition to identify her as a suspect, and U.S. Marshals arrested her. She was 1,200 miles from the scene of the crime. She spent 108 days in jail before the charges were dismissed on Christmas Eve 2025. The Fargo police chief publicly apologized on March 27, 2026. Civil rights claims are being prepared.
A system produced a number. Nobody checked whether that number was reliable given the image quality, the age gap between the probe photo and the gallery image, or how the algorithm performs on her demographic group. The match score was treated as evidence. It wasn't evidence — it was a probability with no calibrated confidence attached to it, and someone read it as a name.
Lipps isn't an outlier. The Washington Post has documented at least eight Americans wrongfully arrested after facial recognition matches, with investigators in every case skipping fundamental steps like checking an alibi. Harvey Murphy's wrongful detention ran ten days, included a physical assault, and turned into a $10 million lawsuit. In Reno, Jason Killinger's casino-facial-recognition wrongful-arrest case is heading for trial, with an officer on record saying it "never should have happened."
This is why the regulators have stopped accepting human oversight as a checkbox. The standard now converging across jurisdictions is meaningful, not ceremonial review — and "meaningful" is precisely what most deployments fake. I've reviewed human-in-the-loop procedures where the SOP had a box labeled meaningful oversight with nothing underneath it. A reviewer who rubber-stamps the machine's output at the same speed the machine produces it is not oversight. Validating that the review workflow actually meets the regulatory bar — that a human can and does override the system, with the information needed to do it — turned out to be one of the hardest and most important parts of every audit we run.
The Patchwork You're Actually Liable Under
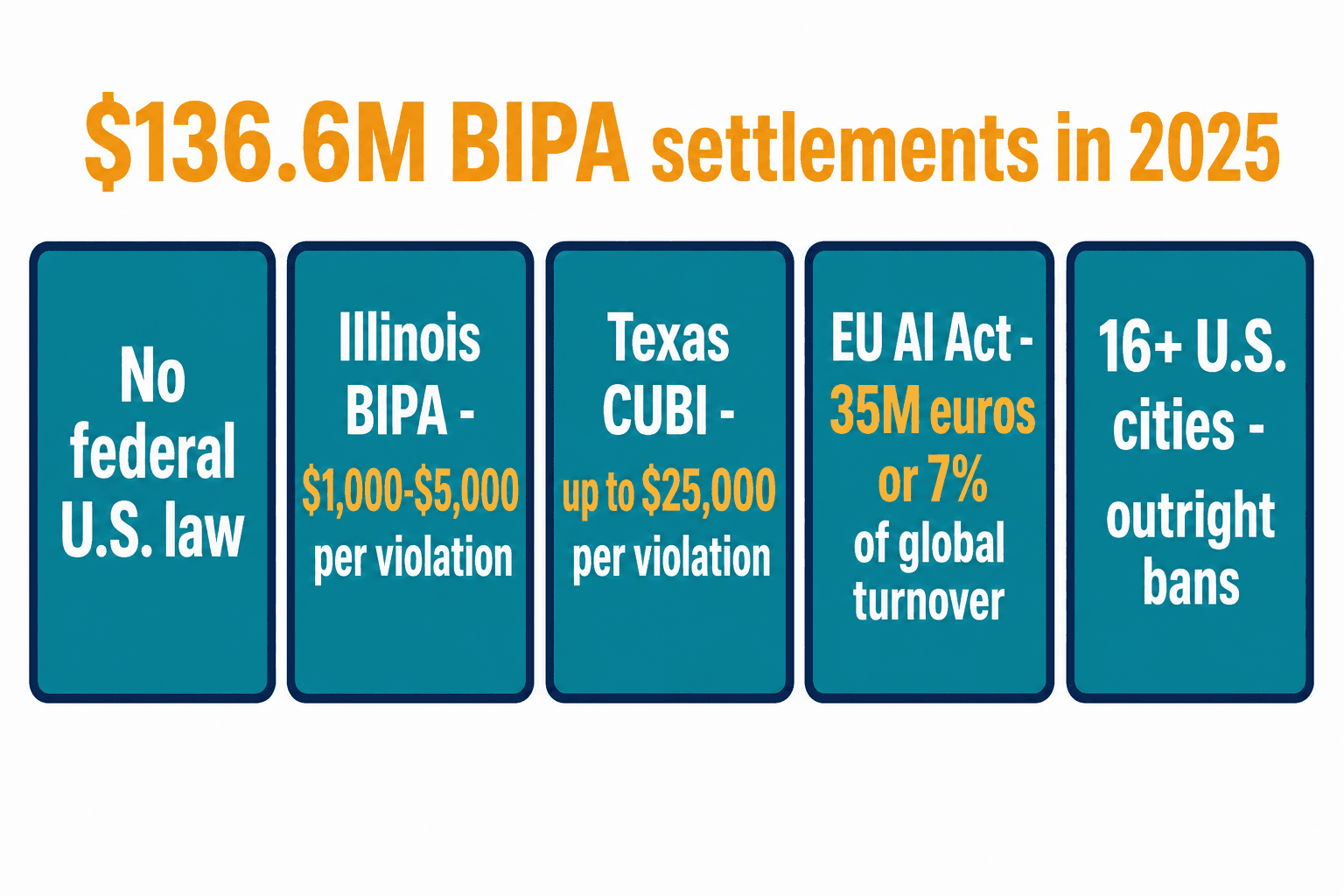
People always ask me for "the facial recognition law" they need to comply with. There isn't one. No federal U.S. statute governs facial recognition. What exists instead is a patchwork, and the penalties are not symbolic.
Illinois BIPA is the one with teeth, because it carries a private right of action — anyone can sue. Per-violation damages run $1,000 for negligent and $5,000 for intentional violations, and in 2025 alone settlements totaled $136.6 million across 107-plus new class actions. The all-time numbers are larger still: Facebook settled for $650 million, Clearview AI for $51.75 million. Texas CUBI carries penalties up to $25,000 per violation and produced a $1.375 billion Google settlement, though Texas enforces only through its attorney general and its 2025 TRAIGA law carved out exemptions for security and fraud prevention.
Then there's the EU AI Act, whose prohibited practices — including bans on real-time remote biometric identification — became enforceable in February 2025, with penalties up to €35 million or 7% of global turnover. Its high-risk-system deadlines were pushed out to December 2, 2027, after the European Parliament voted to extend them, which buys time but changes nothing about the prohibitions already live. Layer on Colorado's amended Privacy Act, Washington's biometric law, and outright bans in 16-plus U.S. cities including San Francisco, Boston, Oakland, and Portland — with 10 or more additional states expected to pass biometric protections by the end of 2026 — and you have a deployment that's legal in one zip code and a class-action magnet in the next. Amazon's Ring "Familiar Faces" feature, launched in December 2025, was blocked in Illinois, Texas, and Portland within weeks of release.
A real audit has to map a single deployment against all of these at once. No off-the-shelf tool does that, which is exactly why we had to build the capability.
Why Isn't Buying the Top-Ranked Vendor Enough?
Early on, an advisor told me the whole thing was simpler than I was making it: buy the highest-ranked NIST vendor, and you're compliant. I believed it for about a week — until the pilot proved that a top vendor on a great benchmark still produced a store full of false alerts.
The vendor landscape rewards skepticism. The full-stack leaders — NEC, IDEMIA, Thales — are all genuine FRVT top performers, and software specialists like Paravision and Rank One Computing rank among the best. But the rankings leave out the line that matters most in the contract: vendors routinely disclaim any warranty of accuracy. The enterprise assumes all liability for outputs it cannot independently audit. The big cloud players read the room and left — Amazon placed an indefinite moratorium on police use of Rekognition, Microsoft did the same for Azure Face, and IBM exited facial recognition entirely back in 2020. Clearview AI, the most aggressive collector, is banned outright in the EU.
If your vendor won't warrant accuracy and the regulator holds you liable for the output, the vendor's benchmark rank is the least interesting fact about your deployment.
There's a deeper procurement trap most buyers never see. The FTC's Rite Aid action didn't just ban facial recognition for five years — it ordered model disgorgement: the destruction of all the biometric data and every model trained on it. Disgorgement is becoming a standard tool; a May 2025 case forced an edtech company to delete its models too. The principle is that you cannot profit from data, or algorithms derived from data, you weren't allowed to collect. So the question a procurement lead should be asking a vendor isn't "how accurate are you." It's "can you prove the accuracy you're selling me wasn't built on data that could get the model itself deleted." That's a due-diligence question, and almost nobody asks it.
Banks Have the Opposite Problem — and the Same Gap
Retail is the vivid case, but financial institutions sit in an equally tight spot from the other direction. Their biometrics aren't watchlist screening — they're electronic Know Your Customer checks: identity-document verification combined with facial matching and liveness detection to confirm a real person is opening a real account. The deployment is consented and narrow, which sounds easier. It isn't, because the bar moved.
As of January 1, 2026, FinCEN expanded its anti-money-laundering requirements, and the broader 2026 supervisory shift is from presence of controls to demonstrable effectiveness of controls. It is no longer enough to say you run liveness detection. You have to show it works — that your liveness check survives a presentation attack (a printed photo, a replayed video, a silicone mask held up to the camera), that your false-match rate holds across demographics, that the control does something measurable rather than merely existing. A bank using a vendor like FacePhi for banking liveness is in the same position as the retailer: holding all the liability for a system it can't independently evaluate, now being asked by its regulator to prove effectiveness it never measured.
The thread connecting the loss-prevention manager and the bank's compliance officer is the same gap. Both bought a biometric system on a vendor's claim. Neither can read a NIST FRVT report well enough to translate it into a procurement decision, audit the quality of the data they're feeding the system, or prove their human-review process is meaningful rather than ceremonial. That gap is widening as biometric decisions get handed to autonomous AI agents — only 23% of organizations have any formal strategy for managing agent identity, and the identity-verification firm iProov has been warning about an "accountability vacuum" when agents make high-impact decisions with no one clearly answerable for them.
What Does Calibrated Doubt Actually Buy You?
The fix that mattered most was the least glamorous. Facial-recognition vendors report a match score — a number — without calibrated confidence bounds around it. The system says "0.94" and the operator reads "that's her." But 0.94 against a clean studio headshot and 0.94 against a decade-old booking photo of someone from a demographic the algorithm handles poorly are not the same claim, and the raw score hides the difference.
What's missing is an uncertainty layer: a way to attach honest, calibrated confidence to each match so a borderline result announces itself as borderline and routes to a human instead of to a security guard's radio. That kind of middleware doesn't exist commercially. Building the assessment for it — the thing that would have told a Fargo officer "this match is low-confidence given the image quality and the subject's demographic group, do not act on it alone" — is the work I wish had existed before the Lipps case, not after.
You can see the institutions that already get this. Essex Police in the UK paused their facial recognition program over bias risk following an audit by the Information Commissioner's Office. They didn't wait for a wrongful arrest to find out their system had a demographic blind spot. That's the posture: treat the system as a liability until an independent audit proves otherwise, rather than the reverse.
A benchmark score is what you show a vendor's sales deck. A calibrated confidence bound on each match is what you show the regulator and the courtroom — and only one of those survives cross-examination.
The Real Question to Bring to Your Next Vendor Call
If you've deployed facial recognition, the uncomfortable truth is that your benchmark certificate is measuring a different system than the one running in your stores or your onboarding flow. The accuracy is real and almost beside the point. What determines your exposure is the open-set math of your environment, the hygiene of the gallery you built, whether your jurisdictions are mapped, and whether a human can actually catch the machine before it confronts the wrong person.
None of that shows up in a vendor rank. All of it shows up in a class action, an FTC consent order, or a grandmother's 108 days in a cell. We built our biometric and facial recognition compliance audit for the buyer who would rather find those gaps in a report than in a lawsuit.
So the next time a vendor hands you a 99% accuracy number, don't ask how they got it. Ask what it doesn't cover — and then go count how many of the faces walking past your cameras every day were never on any list to begin with.


