
A Court Ruled Your Chatbot Is a "Product." That One Word Rewrote AI Product Liability.
In January 2026, a federal court in Florida wrote one word that I think most enterprise legal teams are still pricing as if it didn't happen. The word was product.
The case was Garcia v. Character.AI. A fourteen-year-old had died by suicide after months of conversations with a chatbot, and the families went to court. Character.AI and Google reached for the two shields that have protected internet companies for a generation — Section 230 immunity and the First Amendment — and argued the chatbot's words were speech, or at most third-party content they merely hosted. The court didn't buy it. It ruled the chatbot was "a product for the purposes of plaintiff's claims arising from defects in the Character.AI app rather than ideas or expressions within the app." The companies settled with families in Florida, Colorado, Texas, and New York. The product classification stayed on the books.
I read the ruling the week it came out, and I'll be honest about my first reaction: I thought it was an edge case. A consumer chatbot, a tragic but unusual fact pattern, a court reaching for an analogy. That instinct was wrong, and it took me a couple of months and one uncomfortable conversation with a general counsel to understand how wrong. This is the story of what changed, what my team built the wrong way first, and why I now believe AI product liability is the single most under-priced risk on most enterprise balance sheets.
Speech Has No Defects. Products Do.

Here's why that one word matters so much. If your AI's output is speech, the legal questions are about expression, intent, and immunity — and Section 230 has spent twenty-five years making those questions go away for platforms. If your AI's output is a product, you've walked into a completely different body of law. Products don't have opinions. They have defects. And the manufacturer of a defective product is liable for the harm it causes whether or not the manufacturer was careless.
That last clause is the whole game. Under a negligence standard — the world legal teams were operating in until this year — a plaintiff has to prove you failed to exercise reasonable care. Under strict product liability, they don't. They prove the product was defective and that the defect caused harm. Your diligence, your good intentions, your "we followed best practices" — none of it is a defense. You manufactured the thing. The thing was defective. You pay.
Negligence asks whether you were careful. Strict liability asks whether your product was defective. Most enterprise AI was built to answer the first question, and the courts are now asking the second.
Two more cases from the same quarter made the pattern impossible to dismiss as a one-off. In Nippon Life v. OpenAI, filed in the Northern District of Illinois in March 2026, an insurer sued for $10.3 million after ChatGPT allegedly drafted forty-four court filings for a self-represented litigant — complete with fabricated case citations — and encouraged her to fire her attorney and bring further litigation. The insurer spent roughly $300,000 defending against filings a machine wrote. Notice who got hurt there: not the user of the AI, but a third party downstream of its output. And in Bouck v. Meta, also March 2026, a California court denied Section 230 immunity for AI-generated advertisements, holding that once Meta's system created the ad content and Meta acquired actual knowledge it was fraudulent, the platform couldn't claim it was just hosting someone else's words.
By February 2026 there were more than 2,200 active cases alleging that AI and engagement-maximizing algorithms cause real harm. This is not a frontier. It's a docket.
The Quarter the Legislatures Caught Up
Courts move case by case. Legislatures move in bulk, and in 2025 and 2026 they moved faster than most people building AI noticed.
The one I'd point any enterprise GC to first is the AI LEAD Act, the bipartisan Durbin–Hawley bill introduced in September 2025. It would create a federal product liability cause of action specifically for AI systems, with strict liability — the text reaches developers even when they exercised "all possible care." It covers design defects and failure-to-warn theories, carries a four-year statute of limitations, and — this is the part that should end a particular boardroom conversation permanently — it prohibits waiving that liability through terms of service. The "by clicking Accept you agree this is provided as-is" clause your vendors love? The bill is written to make it unenforceable for this class of harm.
California didn't wait for Washington. AB 316, effective January 2026, forecloses what I've started calling the orphan defense — the argument that "the AI did it on its own, so we're not responsible." You can no longer point at your own system's autonomy as a reason you're off the hook. And across the Atlantic, the EU Product Liability Directive 2024/2853 explicitly classifies software, including AI systems and large language models, as products under strict liability. Member states have to transpose it by December 9, 2026. The EU AI Act's high-risk requirements become fully applicable on August 2, 2026, with fines reaching €15 million or 3% of global turnover.
I'm deliberately not reciting the whole map — Colorado's SB 205 with its $20,000-per-violation penalties and June 2026 enforcement date, New York's proposed RAISE Act with penalties up to $30 million for repeat violations. The point isn't the catalogue. The point is the direction, and the direction is unanimous: across jurisdictions that otherwise agree on nothing, the standard for AI harm is converging on strict liability, and the contractual escape hatches are being welded shut.
Your Insurance Quietly Read the Same Rulings
Lawyers debate. Underwriters price. And the insurance industry priced this faster and more ruthlessly than almost any legal team I've talked to expected.
As of January 2026, the standard language to exclude AI claims entirely now exists, pre-drafted and ready to staple onto your renewal. The Insurance Services Office — the body whose forms most U.S. commercial policies are built on — released endorsement CG 40 47, which carves generative-AI bodily injury, property damage, and personal and advertising injury out of a standard commercial general liability policy. There's a lighter sibling, CG 40 48, that excludes only the advertising-injury coverage. And carriers like W.R. Berkley have gone further with "absolute" AI exclusions written into directors-and-officers, errors-and-omissions, and fiduciary policies — language that voids coverage for any claim "based upon, arising out of, or attributable to" the use, deployment, or development of AI.
I've now sat in enough renewal conversations to tell you what the underwriter's question has become. It used to be: do you use AI? It is now: show us the documented governance evidence for every AI system you deploy. Show us the adversarial red-team results. Show us the model lineage. Show us that the human-oversight controls are actually running, not just written down in a policy PDF that someone updated last quarter.
The underwriter stopped asking whether you use AI. Now they ask you to prove your system is defensible — and a policy document is not evidence.
There's a trap inside the trap. When the CGL exclusions push AI exposure out of general liability, that risk doesn't evaporate — it migrates onto cyber and technology E&O policies that were never designed to absorb product-liability claims. So a company can read its policy stack, see "AI covered" somewhere, and be catastrophically wrong about which policy and what it actually pays. The firms that walked into 2026 with real documentation found that evidence had become the currency of insurability. The firms without it are discovering their carrier already drafted the exclusion endorsement.
The Version We Built First — and Why It Failed
This is the part I got wrong, and I'd rather tell you than let you assume we arrived at the answer cleanly.
When my team first started working with legal and engineering leaders on this, our instinct was the obvious one: the problem is documentation, so build a governance layer. Inventory the models, score the risks, generate audit-ready reports, produce the dashboards an auditor wants to see. It's a reasonable instinct — it's exactly what the mature governance platforms do, and they do it well. Credo AI, which has raised over $45 million and was named to Fast Company's Most Innovative list in 2026, ships pre-built policy packs mapped to the EU AI Act, the NIST AI Risk Management Framework, and ISO 42001. IBM's watsonx.governance does lifecycle governance across the enterprise stack. Holistic AI is strong on algorithmic bias auditing; OneTrust brings a privacy-compliance heritage. We were, in effect, building a thinner version of that.
Then a general counsel I respect looked at what we'd produced and asked a question I couldn't answer. She said, roughly: if this system gets sued for a defective output, I'm going to raise the reasonable-alternative-design defense — I'm going to argue there was no safer design the manufacturer should have used. Where, in all of this, is the record showing what architectural choices were made before deployment, and why?
I went back to the dashboards. They could tell her, in beautiful detail, what the system was doing now. They could not tell her why it had been built the way it was, what alternatives the team had considered and rejected, or what the engineers knew about the failure modes at the moment they shipped. The governance layer monitored the present. The defense she needed lived in the past — in decisions nobody had recorded as evidence because, at the time, nobody knew they were making evidence.
That was the failure that paid for everything we did next. Governance platforms monitor and report. They do not architect. You cannot bolt a defense onto a system that was never designed to be defended, the same way you cannot photograph a crash-test that was never run.
What Does "Defensible by Design" Actually Mean?
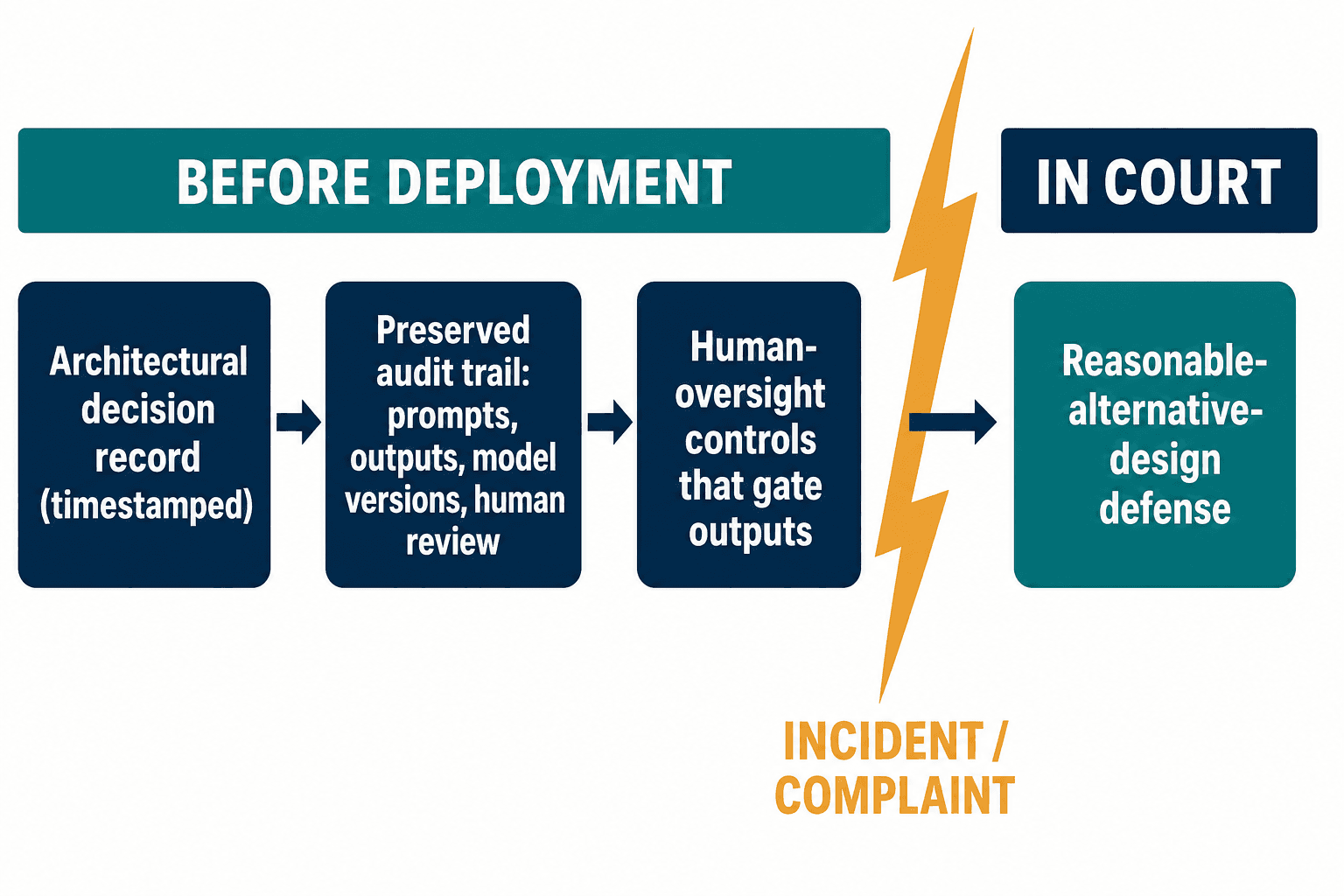
So we threw out the dashboard-first approach and inverted it. The question stopped being how do we document this system? and became how do we design a system whose history is the documentation? That inversion is what Veriprajna's AI Product Liability Defense practice is built around — defensible architecture and litigation-ready evidence, not another monitoring layer bolted onto a system after the fact.
In practice that meant treating the architectural decision record as a first-class artifact — timestamped before deployment, capturing what the team tried, what it rejected, and the reasoning, so that the reasonable-alternative-design defense has source material that predates the lawsuit rather than being reverse-engineered after a complaint lands. It meant building audit trails that survive litigation discovery: not application logs that roll over every thirty days, but a preserved chain of prompts, outputs, model versions, and human-review actions, because a litigation-hold memo for an AI system has to name all of those as things you'll be asked to produce. Most enterprise legal teams haven't updated their hold templates to list a single one of them — which means the preservation duty is already attaching to data the company is quietly destroying on a rolling log rotation, long before a complaint ever lands. And it meant designing the human-oversight controls as load-bearing parts of the system that genuinely gate outputs — because an underwriter, and eventually a plaintiff's expert, will test whether your "human in the loop" actually has the authority and the interface to stop a bad output, or is a checkbox on an org chart.
There's a subtlety here that separates the firms who'll weather this from the firms who won't. Privilege does not save you. In February 2026, Judge Rakoff ruled that a company's consumer-AI documents were not protected by attorney-client privilege when employees had used the tool without counsel's direction. You cannot retroactively wrap your AI decisions in a privilege blanket. The evidence will be discoverable, which is precisely why it has to be good evidence, created deliberately, from the start.
You can't bolt a defense onto a system that was never designed to be defended. The architecture is the alibi — and the alibi has to exist before the incident, not after.
This is also where the agentic-AI wave makes everything harder. When a system acts autonomously — taking actions without a human pressing the button each time — the old contractual disclaimers strain past breaking. Singapore's IMDA released a draft Agentic AI Governance Framework in January 2026, and firms like Clifford Chance have flagged the "liability gap" in standard contracts that quietly assume a human is always the actor. California's AB 316 already says you can't blame the agent. So the autonomy you built for efficiency is, legally, additional surface area you now own. That has to be designed for, not disclaimed away.
Why Can't the Obvious Vendors Close This Gap?
People ask me a fair question: if governance platforms, law firms, and the big system integrators all exist, why is there anything left to build?
Because each of them does part of the job and none of them does this part. The governance platforms — Credo AI, IBM, Holistic AI, OneTrust — govern systems that already exist; they don't restructure a wrapper into a defensible architecture, and they don't generate the design-decision evidence a motion to dismiss leans on. Law firms give you the legal theory — they'll tell you exactly what the reasonable-alternative-design defense requires — but they don't write the code or make the architectural choices that create the evidence. And the big integrators implement the platforms they're partnered with, which makes them structurally biased toward Salesforce or Microsoft Copilot rather than the vendor-neutral, defensible custom system your specific exposure calls for.
The gap is the seam between what outside counsel advises and what an engineering team can actually implement. I've watched that seam fail in real time — a Slack thread where the lawyer keeps writing "we need defensible architecture" and the engineer keeps replying "tell me which file to change." Someone has to stand in that gap who can read the ruling and the repository. That's the work my team does — building around architecture and evidence rather than dashboards and reports, so the lawyer and the engineer are finally pointing at the same artifact.
The Question Worth Sitting With
I'll leave you with the thing I keep coming back to. The average cost of a data breach in 2025–2026 ran about $4.44 million, and the industry built an entire discipline — budgets, insurance products, board reporting — around that number. AI product liability is a strict-liability exposure with no upper bound, with the contractual escape hatches being legislated shut, and with carriers actively writing it out of the policies that used to cover it. And most enterprises are managing it with a policy binder and a vendor's as-is clause.
A policy binder is what you hand the regulator. It is not what survives a deposition. Picture the moment that's now coming for a lot of companies: a plaintiff's expert sits across from your engineers and asks what safer design you considered before you shipped. The answer is either a timestamped record or a silence — and under strict liability, the silence is the defect. When your AI's words became a product, your architecture became your defense, and a defense you didn't design before the incident is one you don't have. If you can't open that record today, you don't have a documentation problem. You have an undefended product in the market. That's worth fixing before December 9th, not after the complaint arrives — and closing that gap is the work we do.


