Your Algorithm Sold $1.4 Billion Before Anyone Hit Cancel. Can You Explain Why?
There's a single question that ends most regulatory examinations before they really begin. It isn't "do you have controls?" Everyone has controls. It's quieter than that, and worse:
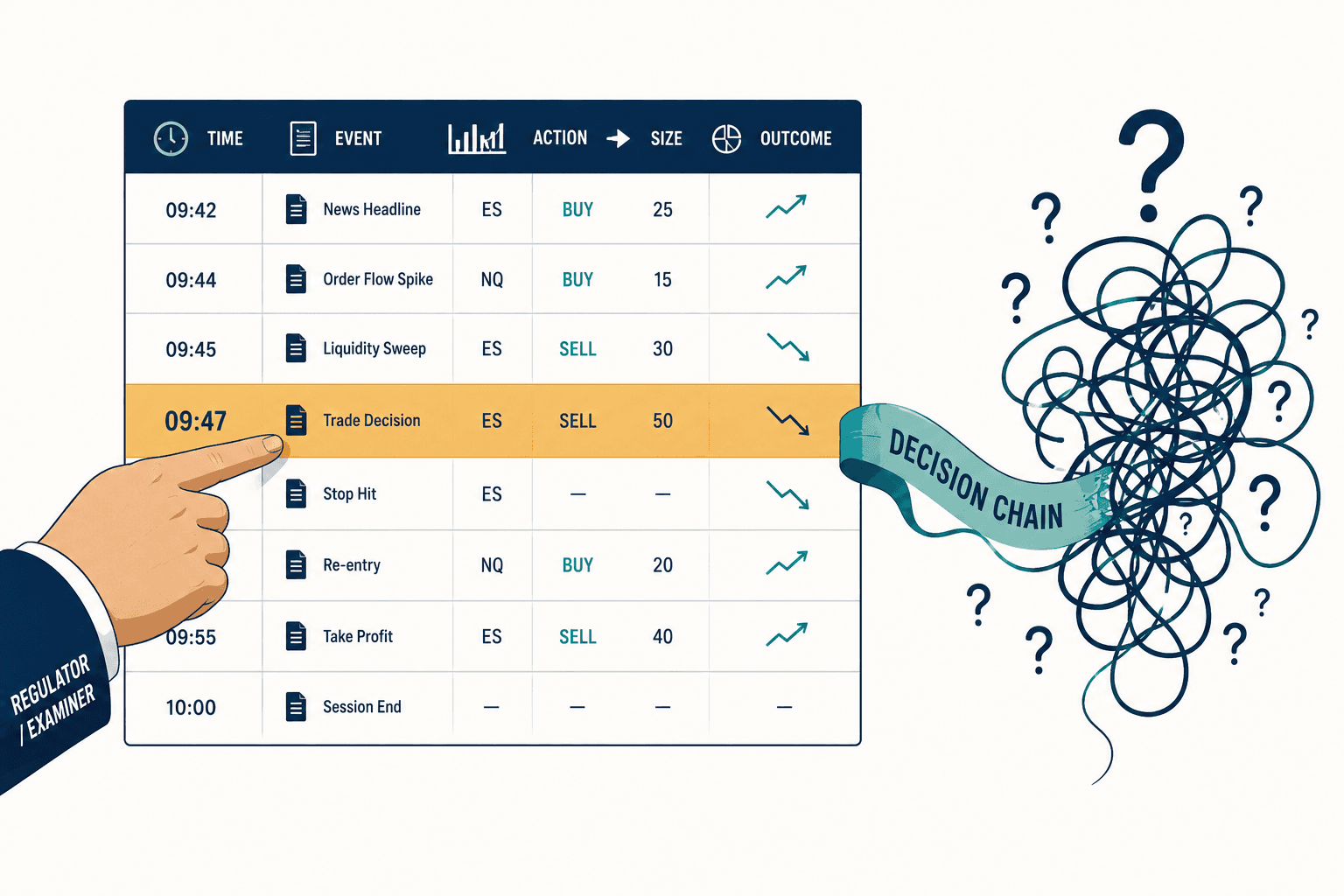
"Walk me through exactly what this algorithm did on August 5th at 9:47 in the morning."
I've watched smart, well-funded firms freeze on that question. They can pull the order logs. They can show you the trades. What they cannot do is reconstruct the decision chain — why the model sized the position the way it did, why the risk threshold sat where it sat, why a code change three weeks earlier didn't trip anyone's radar. And in 2026, that gap is the whole ballgame. Algorithmic trading compliance has quietly shifted from proving you have guardrails to proving you can explain, after the fact, every move your machine made.
I want to tell you how I came to believe that, because I got it wrong first — expensively wrong — and the way I got it wrong is the same way most of the industry is still getting it wrong.
The $189 Billion That Got Through

Start with Citigroup, because it's the clearest lesson I know.
In May 2022, a Citi trader meant to sell a basket of equities worth $58 million. Through a manual error, they created a basket worth $444 billion instead. Citi's pre-trade controls did their job — mostly. They blocked $255 billion. But $189 billion slipped past the controls and reached a trading algorithm, which dutifully chopped it into sell orders and pushed roughly $1.4 billion into European markets before anyone hit cancel. It triggered a flash crash across European exchanges.
Here's the part that should keep compliance officers up at night. When BaFin and the UK regulators came in, the damning question wasn't "what happened." Citi could answer that. The question was why — why did the controls let $189 billion through, and why were the thresholds calibrated where they were? Citi could show the orders. They could not adequately reconstruct the algorithm's reasoning or defend the parameters that governed it.
That gap cost them. BaFin fined Citi €12.975 million; two days earlier, British regulators had added £61.6 million for the same incident. Roughly $92 million for one algorithmic failure, across three jurisdictions.
The controls weren't the failure. The inability to explain the controls was the failure.
I keep coming back to that because it inverts how most firms budget. They spend on building more controls and almost nothing on being able to narrate them under oath.
What Does the Examiner Actually Ask?
When I started talking to compliance heads at mid-market banks and asset managers — the firms below the bulge-bracket tier — I'd ask them to role-play an examination with me. It always unraveled in the same three steps.
"Show me your algorithm inventory." This is the opener, and it's a quiet killer. The UK's Financial Conduct Authority ran a multi-firm review of ten principal trading firms in August 2025 and found most had incomplete or out-of-date documentation — no clean inventory of who owns each algorithm, which markets it trades, what risk parameters govern it. Some firms had omitted entire RTS 6 elements from their self-assessments. (RTS 6 is the MiFID II rulebook for algorithmic trading firms — governance, testing, risk controls.) If you can't produce a current, complete inventory naming the registered person responsible for each strategy, the exam effectively stops there. Under FINRA's rules, the people who design or significantly modify trading algorithms have to be registered as Securities Traders — so "who owns this algo" isn't a trivia question, it's a regulatory one with a name attached.
"Walk me through what this one did, that morning." This is the Citigroup question. Most firms can show the orders. Almost none can reconstruct the decision. And if you're an asset manager rather than a broker-dealer, this question doesn't land on a trading desk — it lands on your quant research team, where a single tampered parameter buried in a model can run undetected for months. (Two Sigma found that out the hard way; more on that later.)
"How do your compliance staff technically review these algorithms?" The FCA had a wonderfully diplomatic phrase for what they found here: "variable technical knowledge in compliance." Translated, that means compliance teams can read an alert report but can't interrogate the model's logic, challenge a risk parameter, or verify that last sprint's code change didn't quietly open a new regulatory hole. The industry's answer has been to hire quant-literate compliance staff — except the people who genuinely understand both CFTC market-access rules and graph neural network architectures are vanishingly rare, and they get paid like the hedge funds that also want them.
The regulatory direction behind all three questions is not subtle. The SEC and CFTC together brought a record $25.3 billion in enforcement actions in 2024. The EU AI Act requires high-risk financial AI systems to carry technical documentation, risk management, and human-oversight capability by August 2, 2026. DORA — the EU's operational-resilience regime — has been live since January 2025. And in India, SEBI now requires a unique Algo-ID and exchange approval for every strategy before it goes live. The question stopped being whether your algorithms get examined. It's whether they survive the examination.
The Thing I Built That Nobody Wanted
So I went and built a better detector.
This was my mistake, and I want to be honest about how seductive it was. The buyer pain that everyone complains about loudest is alert fatigue — in one survey of banks and broker-dealers, 70% reported false-positive rates above 25% in their trade surveillance. Compliance teams drowning in noise, chasing phantom spoofing alerts. So we built something genuinely good at cutting false positives: behavioral context, market-regime awareness, adaptive thresholds. In testing it was clean and fast. I was proud of it.
Then we ran it in front of an actual mid-market compliance officer. She watched the dashboard, nodded along, and asked the question that detonated three months of work:
"This is nice. But when the examiner asks why the model fired — or why it didn't — what do I show them?"
I didn't have an answer in the product. We'd built a faster way to generate alerts. We had not built a way to explain them. And I realized, sitting there, that I'd reproduced the exact thing the regulators were punishing: a black box that produces outputs without a reconstructable reasoning chain. A better black box is still a black box.
That was the turning point. Detection was never the unmet need. The unmet need was audit-readiness — turning algorithmic decisions into explanations a non-quant compliance officer could review, challenge, and carry into an exam room. We threw out the framing and started over.
Building for the Examiner, Not the Alert
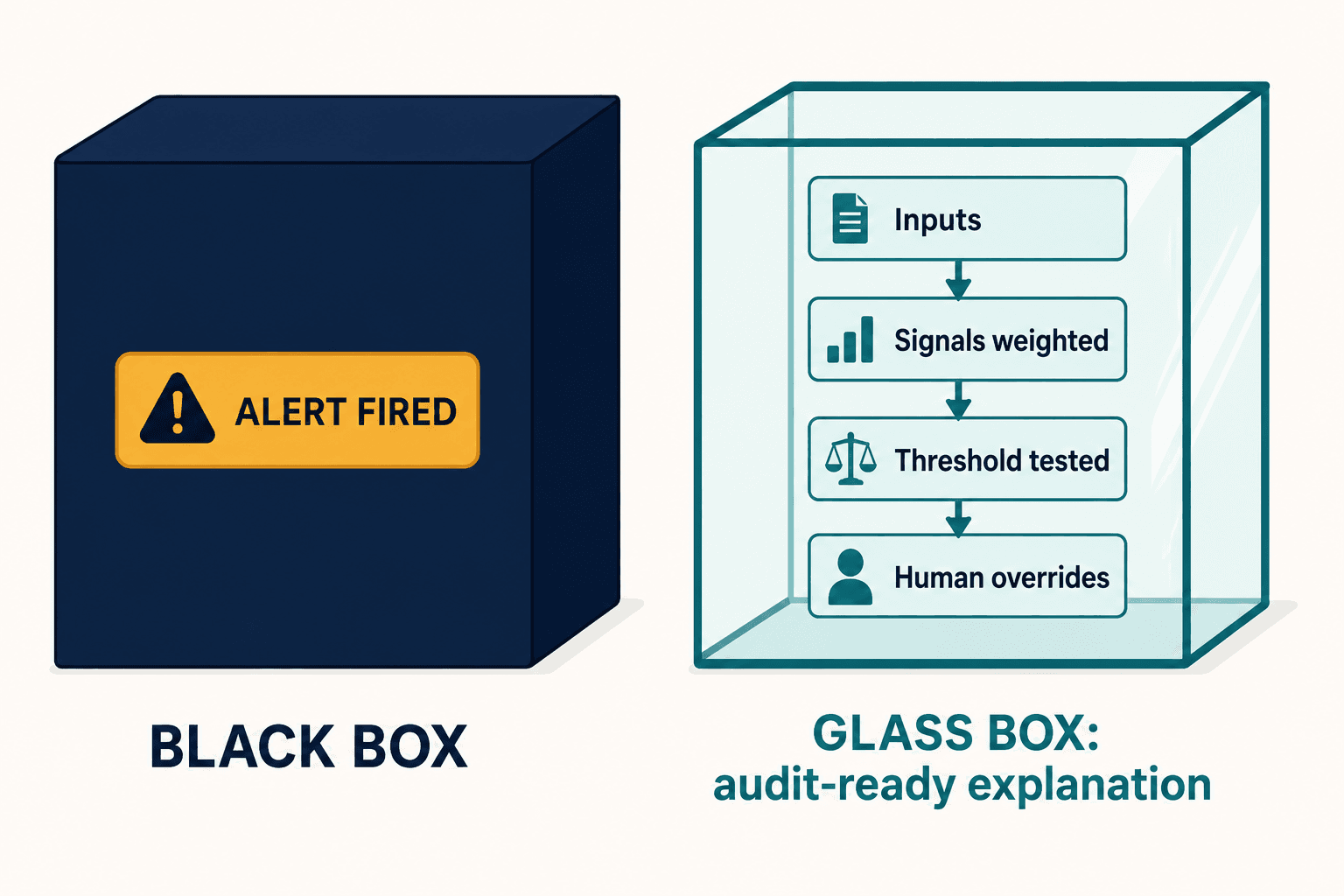
The system we ended up building — the algorithmic trading compliance intelligence layer we now deploy — starts from a different first principle: every decision a production algorithm makes should leave behind an audit-ready, time-stamped explanation of why, not just what.
That sounds obvious until you try it. The first design problem was that the people who need the explanation can't read the model. So the explanations had to translate the algorithm's logic — its inputs, the market signals it weighted, the threshold it tested against, the human overrides — into something a compliance officer can interrogate without reading source code. Not a confidence score. An account of the reasoning.
The second problem was the inventory itself. We treat the algorithm inventory the way an engineering team treats code: every strategy in production carries its approved markets, position limits, the registered owner, and a full change history, so the "show me your inventory" question becomes a query, not a fire drill. The same backbone maps each control to multiple regulatory frameworks at once — SEC Rule 15c3-5, MiFID II's RTS 6, the EU AI Act, DORA, SEBI's Algo-ID regime — because mid-market firms trade across borders and no incumbent vendor maps controls across all of them from one place. Today most multi-jurisdictional firms cobble together separate compliance processes per regulator. That redundancy is exactly the kind of work software should eat.
The third problem was the kill switch. Citi's controls weren't absent — they caught $255 billion. They just weren't graduated. Most circuit breakers are binary: on or off. So we built intelligent, multi-tier circuit breakers — behavioral anomaly detection that triggers a proportionate response rather than a single panic button, the difference between catching $255 billion and catching the $189 billion that slipped through.
Why Doesn't Everyone Just Buy a Platform?
This is the objection I hear most, and it deserves a real answer.
The trade-surveillance market is heading from roughly $1.3–3 billion in 2025 toward $4.2–9.3 billion by 2033, and the top five vendors hold 55–59% of it. NICE Actimize, Nasdaq's Surveillance AI, Eventus's Validus — these are genuinely capable platforms. I'm not here to tell you they don't work.
I'm here to tell you what they cost and where they stop. A full NICE Actimize deployment runs $1–5 million-plus a year, priced and architected for Tier-1 institutions. They're superb at cross-asset detection and weak at exactly the thing the examiner now asks for: algo-decision explainability and unified multi-regulatory mapping. Nasdaq's platform is exchange-centric, built for the sell side. Eventus is detection-first. None of them was designed around the compliance officer's exam-day problem.
So a Tier-2 bank or a mid-size asset manager faces the same regulatory bar as JPMorgan with a fraction of the budget and none of the in-house quant bench. Their options have been: overpay for an enterprise platform that doesn't fit, build it themselves for $2–10 million plus a million a year in maintenance while competing with hedge-fund compensation for the talent, or hire a Big Four firm — which, in my experience, advises on what to build, hands you a PowerPoint target-operating-model deck, and then reaches for the same Tier-1 vendor it would have recommended anyway.
There's a void in the middle of this market: firms with bulge-bracket obligations and mid-market budgets, served by no one.
That void is who we build for. Custom compliance intelligence at a price point that isn't enterprise ransom, with no vendor lock-in.
The Harder Problem Coming: Autonomous Agents
If explainability is the problem of today, agentic AI is the problem of next year, and almost nobody is ready for it.
Roughly 44% of finance teams are expected to use agentic AI in 2026 — a more-than-600% jump — and one firm already reports 60 autonomous agents in production with plans for 200 more. These systems can automate up to 70% of manual compliance work. They can also trigger trades, adjust risk models, and authorize transactions on their own.
What terrifies anyone who's sat through an exam is what comes next. The governance framework the whole industry leans on — the Fed and OCC's SR 11-7 model-risk guidance — was written in 2011 for models with stable, deterministic behavior. As GARP's risk analysts put it in early 2026, SR 11-7 "remains one of the few stable reference points for model governance" — and agentic AI breaks its core assumptions, introducing opacity, randomness, and autonomy, often riding on third-party infrastructure that can change without notice. You cannot reconstruct the decision of a system that decides differently each time and depends on a vendor's model you don't control.
To be clear about where we actually are: the FMSB's practitioner reviews note that market-facing AI doesn't yet operate autonomously — it's embedded in trading infrastructure under human supervision. Good. That's the window. The right time to build governance for autonomous trading agents is before they're trading autonomously, not in the post-mortem. We design that explainability and oversight layer in now, so the audit trail exists before the regulator asks for it.
There's real technical leverage available here, too. Graph-based models — graph neural networks that map the web of counterparty exposures — have hit AUC-ROC scores around 0.891 for detecting risk contagion in research settings, well ahead of conventional methods, with early-warning lead times extended by nearly twelve days. Almost no surveillance vendor offers graph-based contagion analysis as a standard feature. For a firm with interconnected counterparty risk, that's the difference between seeing a cascade coming and reading about it in an enforcement order.
"Isn't This Just More Compliance Software?"
People ask me a version of that, and the fair answer is: not if it's built right.
The reason compliance feels like pure cost — large banks spend over $200 million a year on it, and the time their employees spend on it grew 61% in a decade — is that most of it is manual reconstruction of things the systems should have recorded automatically. When the explanation is generated as the algorithm runs, the exam stops being an archaeology dig. The inventory is a query. The decision chain is already written down. The cross-jurisdictional mapping is one model, not five.
The other thing people ask is whether explainability slows the algorithms down — whether you're trading microseconds for paperwork. You're not. The reasoning capture sits alongside execution; it's a record, not a brake. The firms that resolved this stopped treating compliance as a tax on speed and started treating it as a property of the system, present from the first line of code rather than bolted on before the audit.
I think about the Two Sigma case here. A senior researcher quietly altered fourteen investment models over nearly two years — nudging a single parameter — and produced $165 million in client losses before anyone caught it; the firm paid $90 million to settle. Those models weren't unsupervised in name. They were unexplainable in practice. Nobody could see, in real time, that the reasoning had been corrupted. That's not a detection failure. That's an explainability failure wearing a detection failure's clothes.
The Citi trader's $444 billion mistake took seconds to make and years to litigate. The thing that turned an embarrassing error into a $92 million one wasn't the size of the basket. It was that, when the regulators leaned in and asked why, the answer was a shrug.
Every firm running algorithms is one bad morning away from that question. The ones that will be fine aren't the ones with the most controls or the most expensive platform. They're the ones who, when the examiner points at 9:47 AM, can pull up the decision and walk through it line by line — and who built that capability into the compliance layer long before they needed it. Build the explanation while the machine is still trading. By the time someone asks, it's already too late to start writing it down.