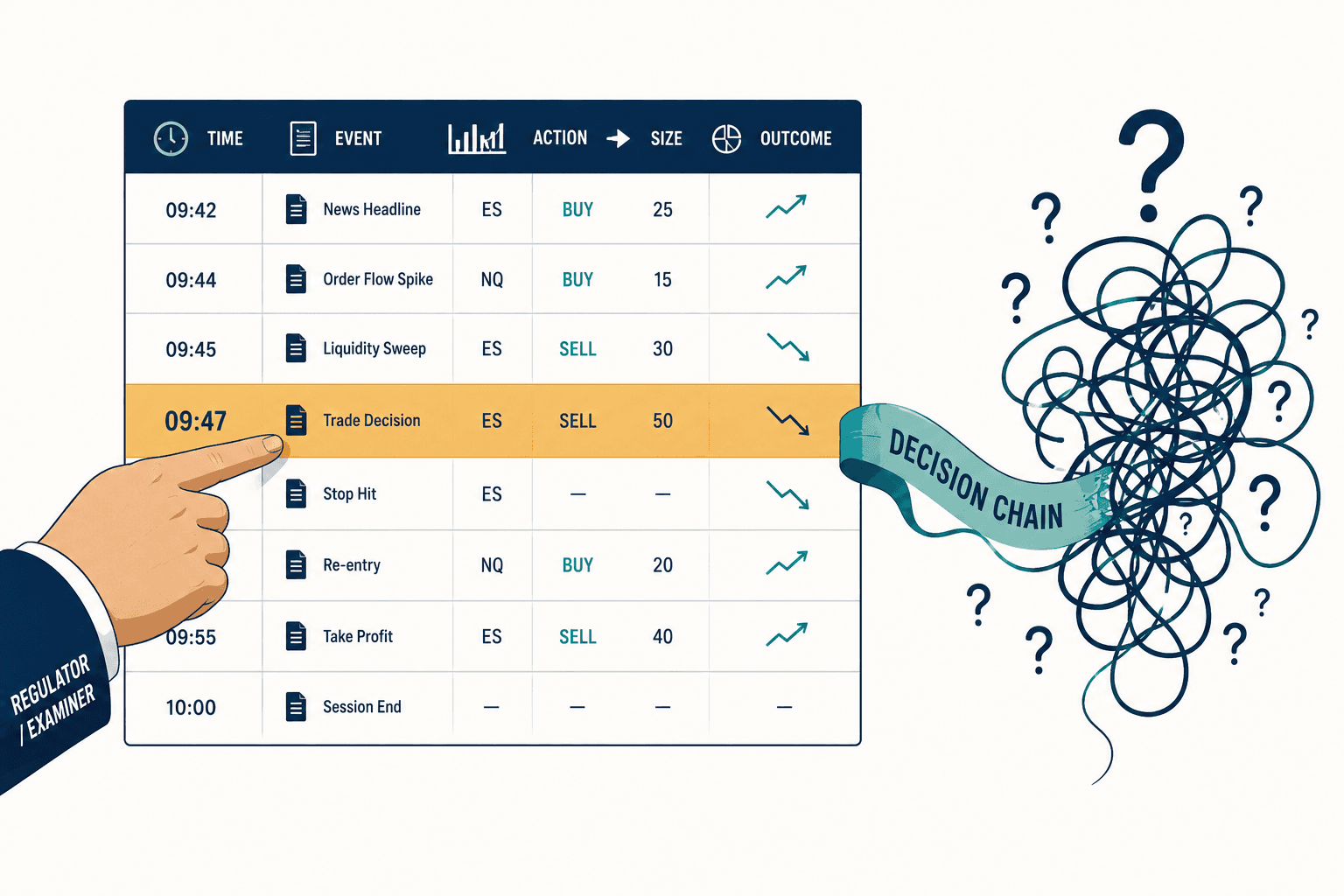
The Green Dashboard Lied: What Enterprise AI Validation Actually Has to Test
I have spent a good part of my career as the person in the room whose job is to say "no, that model isn't validated yet." In banking that function has a dry name — independent model validation under SR 11-7, the Federal Reserve and OCC guidance that has governed model risk since 2011. The work is exactly as glamorous as it sounds. You read the limitations appendix nobody else reads. You ask the vendor how the model behaves on the cases that aren't in the demo. And every so often you sit in an audit committee in front of a dashboard that is entirely, reassuringly green — every box ticked, every policy mapped, every compliance status nominal — while knowing, with a sinking feeling, that the green tells you almost nothing about whether the thing actually works.
That gap is what this whole essay is about, and it's why we built Veriprajna's enterprise AI validation practice around a single unfashionable idea: you have to test the answers, not the process. A governance dashboard certifies that a procedure was followed. It does not certify that your AI gave the right answer for this policyholder, this loan, this statute. The two get confused in board meetings constantly, and the confusion is expensive.
Let me show you how expensive.
Klarna Saved 40% — Then Lost $99 Million
In 2024, Klarna told the world its AI assistant had replaced 700 customer service agents. The assistant was handling roughly two-thirds of chats across 35 languages. Cost per transaction dropped from $0.32 to $0.19 — about 40% — and the headlines wrote themselves. This was the future: leaner, faster, cheaper.
By mid-2025 they were reassigning software engineers and marketers to staff the call centers. CSAT scores had dropped 22%. Customers were hitting what the press called a "Kafkaesque loop" on the hard stuff — disputed charges, contested refunds, account closures. Klarna's Q1 2025 closed with a $99 million net loss, up from $47 million the year before, despite 15% revenue growth. The CEO admitted that automating at scale had "led to a drop in service quality."
Here's the part that took me a while to internalize, and it's the opposite of the lesson most people drew. Klarna's AI worked. It really did save money on password resets and order-status questions. The failure wasn't that the AI was bad. The failure was that nobody validated whether it could handle the 20% of interactions that carry most of the financial and reputational weight — the disputes, the edge cases, the things that turn into churn and complaints. A toxicity filter would have passed every one of those broken conversations. The AI was polite while it failed.
The AI didn't say anything offensive. It just couldn't navigate a multi-currency refund involving a cancelled flight and a disputed charge — and that was the 20% that mattered.
Klarna is not an outlier. It is the visible version of something happening quietly across every enterprise I talk to. Somewhere between 70% and 85% of enterprise AI projects never reach production at all — a figure RAND, Gartner, BCG and McKinsey have all landed near independently. MIT's NANDA study in 2025 found that 95% of AI pilots delivered no measurable profit-and-loss impact. McKinsey reported that 42% of companies abandoned most of their AI initiatives in 2025, up from 17% the year before. The pilots demo beautifully. They die on contact with the cases the demo never showed.
We Built the Wrong Thing First
I want to be honest about how we arrived at testing answers instead of process, because we didn't arrive there by being clever. We arrived by shipping something that didn't work and watching it fail in front of a customer.
Our first version of an AI validation layer was, in retrospect, exactly the thing the market was already selling. We wired up a respectable guardrail framework — content moderation, PII detection, jailbreak checks — bolted on drift and fairness monitoring, and rendered the whole thing as a clean compliance view. Inputs scanned. Outputs scanned for toxicity and leaked personal data. A dashboard that went green. I was proud of it. It looked like governance.
We put it in front of a pilot in a regulated financial workflow, and within the first weeks the AI produced an answer that was confident, well-formatted, free of anything toxic, contained no leaked PII — and was simply wrong about a domain rule. Our system passed it. Every check we'd built was green. The error was in the substance of the answer, in a place none of our guardrails were looking, because none of them understood the domain well enough to know the answer was wrong.
That was the month I stopped believing in the category we'd built into. I'd spent years in model validation knowing this in the banking context, and I'd still built a tool that made the same mistake I'd spent my career catching. Security is not correctness. Safety is not correctness. A green dashboard is not correctness.
An AI that is secure against prompt injection can still miscalculate a reserve, cite a repealed statute, or approve a loan that violates fair lending rules. Safety and correctness are different problems, and almost nobody is testing the second one.
Why Do the Tools You've Heard Of Stop Where They Stop?

There is now a real, well-funded market of AI tools, growing at something like a 45% compound annual rate, and I don't want to be unfair to it. Most of these products do their actual jobs well. The problem is that their actual jobs are not the job most buyers think they're buying.
The governance platforms — Credo AI, IBM's watsonx.governance, ModelOp — map your AI initiatives to regulatory frameworks and track compliance status. Credo AI was ranked #6 in Applied AI on Fast Company's 2026 list, alongside Google, Nvidia and Anthropic; this is serious work. But policy compliance is not output correctness. A green policy dashboard means the paperwork is in order, not that the AI gives right answers for your specific use case.
The monitoring tools — Arthur, Galileo, Arize — watch model-level metrics in real time: drift, fairness, latency, token distributions. Useful. But they monitor the model's behavior in aggregate, not whether a particular insurance calculation is correct given a particular policyholder's coverage terms. The security tools go a layer deeper — Cisco paid around $400 million for Robust Intelligence in October 2024 and folded it into Cisco AI Defense, mapping detections to OWASP and MITRE ATLAS. That's necessary. It's also still about whether the model can be attacked, not whether it's right.
Then there are the guardrail frameworks, NVIDIA's NeMo Guardrails and the like, which are good at content moderation and PII and topic filtering — and which NVIDIA itself is careful to say can't catch everything, because the self-check mechanisms depend on the very models they're guarding. And there are the Big Four, who will sell you a governance strategy for somewhere between $500K and $5M over 6 to 18 months and hand you a PowerPoint and a vendor shortlist at the end — a framework, not a running system that tells you your AI is wrong on a Tuesday.
Every one of these has a column where its usefulness stops. Stack them all and you have covered policy, security, drift, and content safety. You still have not answered the question that actually determines whether the deployment lives or dies: is the answer correct for this case?
The 69% Problem
If you want the number that made this concrete for me, it's this. On legal due-diligence tasks, independent testing has put AI error rates between 69% and 88% — far above what the vendor benchmarks suggest. Sit with that. Not 6.9%. Sixty-nine to eighty-eight.
And these are not errors a guardrail catches, because they aren't offensive or insecure. They're wrong in the way that only someone who knows the domain can see. By the end of 2025 there were more than 729 documented incidents of AI hallucinations in legal filings — up from 280 the year before. Courts started fining people. In one case, Doiban v. OLCC, the sanction worked out to $500 for each of 15 fabricated citations plus $1,000 for opposing counsel's time hunting down phantom cases that didn't exist. One of the largest US law firms logged three separate hallucination incidents in six months.
These are professionals, double-checking their work, in a field where being wrong has consequences — and the AI still fabricated case law convincingly enough to get into a court filing. That is the texture of the failure. It is fluent, plausible, and false, and it lives precisely in the domain knowledge that generic monitoring has no way to evaluate.
What Do You Validate When the Vendor Won't Open the Box?
In regulated industries this stops being an interesting engineering problem and becomes a legal one. If a model influences underwriting, reserving, or capital, SR 11-7 in US banking — and Solvency II Pillar 2 for European insurers — requires it to be independently validated, documented, and continuously monitored. That obligation now applies to large language models too; a regulator does not care that your model happens to be an LLM.
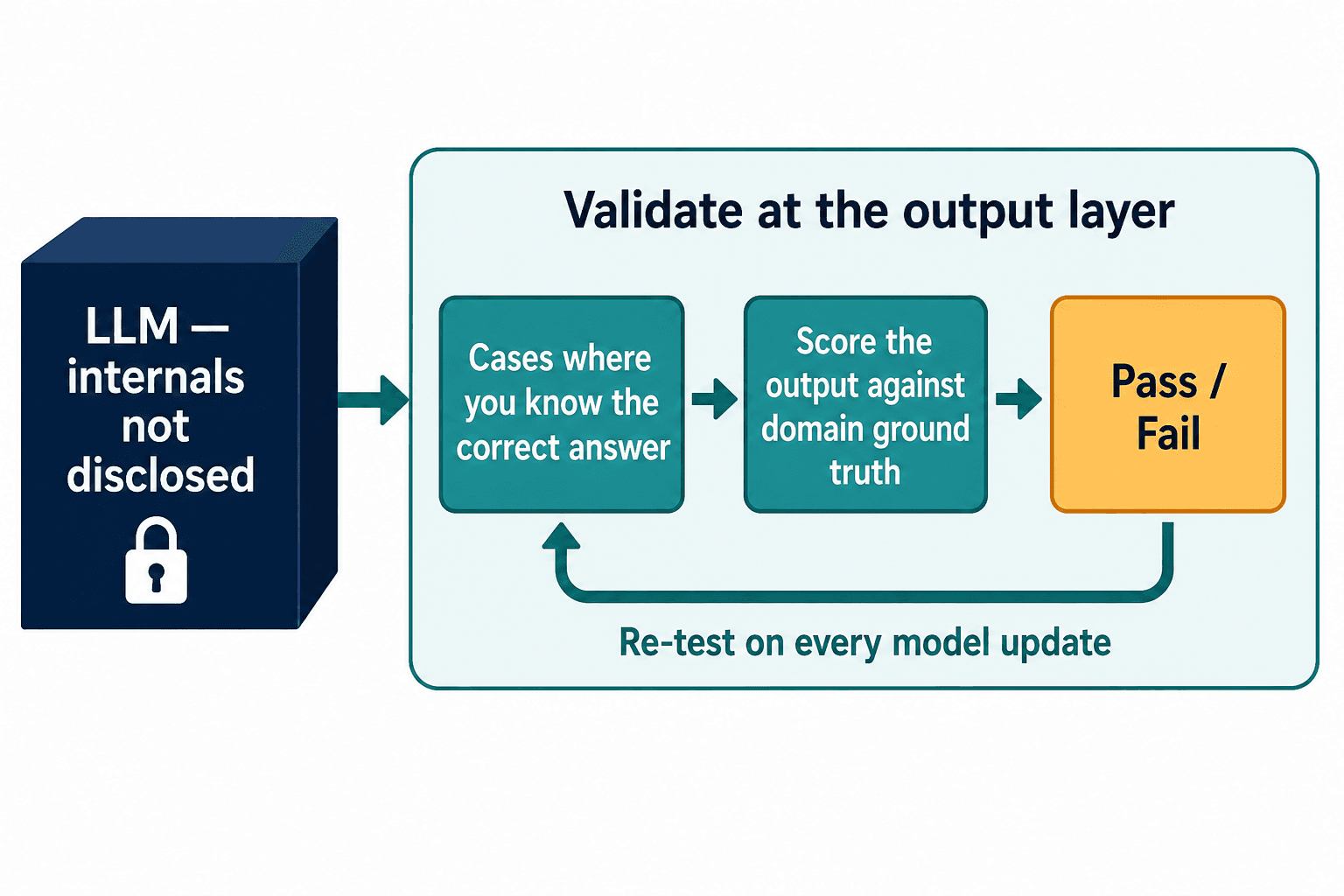
And here is the bind I kept running into. SR 11-7 validation traditionally leans on understanding the model — its assumptions, its internals, its boundaries. But the LLM providers will not tell you how the model works. I have the email in my archive, in various phrasings: we can't disclose the model's internals. You are legally required to validate something the vendor refuses to open.
The only way out of that bind is to stop trying to inspect the weights and start scoring the outputs against domain ground truth. You build a body of cases where you know the correct answer — the way a long-tail liability reserve should be set when a policy's sub-limit and a coverage exclusion interact, what a repealed statute means, how a fair-lending rule applies — and you test whether the AI gets them right, at scale, continuously, every time the model is updated or re-tuned. You validate the behavior you can see, because it's the behavior the regulator and the customer experience anyway. That's the core of what we now build, and it's the one approach that works whether or not the vendor ever opens the box.
When you can't see inside the model, the output layer is the only honest place left to validate — and conveniently, it's the only layer your customer and your regulator ever actually touch.
Why "Just Buy a Platform" Stopped Being the Answer
There's a quiet revolt happening in how enterprises build AI, and it bears directly on validation. Retool's 2026 build-versus-buy report found that 35% of teams have already replaced at least one SaaS tool with a custom build, and 78% expect to build more. Custom solutions, aligned to specific business logic, have been showing 3 to 5 times the return of generic wrappers — partly because roughly 65% of software cost arrives after deployment, in the integration and the maintenance and the things the wrapper didn't quite do.
But there's a catch that the "just build it yourself" crowd skips over. Building custom validation properly requires ML infrastructure teams that most companies don't have. So the real landscape isn't wrapper-versus-custom. It's three options: a generic wrapper that doesn't understand your domain, a do-it-yourself project you're not staffed for, or domain-expert systems built for your specific vertical by people who've done this validation work before. That third option is the gap we decided to live in. Not a dashboard you license. Not a platform you staff. A validation layer built around the actual truth of your domain.
"Doesn't the Governance Tool We Already Bought Cover This?"
People ask me a version of this constantly, usually with a note of hope, because they've already spent the budget. The honest answer is that your governance tool covers governance — and governance is genuinely necessary. Keep it. It just doesn't validate correctness, and it was never built to.
The second thing they ask is about the AI they can't see — the shadow AI. This one keeps risk officers up at night, and the numbers say it should: 78% of employees use AI tools their employer didn't provide, and 77% of them have fed sensitive or proprietary information into those tools. Samsung and Amazon both discovered their own proprietary code sitting in public AI services. The average shadow-AI breach runs $4.63 million. Gartner's own framing is the uncomfortable one — the large majority of unauthorized AI activity comes from internal policy violations, oversharing and misuse, not external attackers. Your governance platform cannot govern what it cannot see, and validation has to start with discovering what's actually running.
The third question is the one that's coming fastest. Gartner projects 40% of enterprise applications will embed autonomous AI agents by the end of 2026 — agents that don't just answer, they act: modifying databases, executing transactions, sending customer communications. Only about a third of organizations report mature governance for any of this. When an agent can take an irreversible action, the validation question moves from "did it say the right thing" to "did it do the right thing," and a wrong action you can't take back is a different category of risk than a wrong sentence. The monitoring built for chatbots was never designed for it.
The Penalty Table Nobody Wants on the Board Slide
I'll close with the number that tends to end the debate, because it makes the cost of not validating legible to a CFO in a way that error rates don't.
Starting August 2, 2026, most of the EU AI Act's remaining obligations go live — the rules for high-risk systems, the transparency requirements under Article 50. The penalty for prohibited practices runs up to €35 million or 7% of global turnover; high-risk non-compliance, up to €15 million or 3%. Finland became the first member state with fully operational enforcement powers in January 2026. This is no longer a future memo. It's a line item with a date on it.
Add up the rest of the bill for skipping validation: $4.63 million per shadow-AI breach, over $1 million an hour during a major AI outage, $99 million when service quality quietly collapses, six-figure sanctions per hallucination incident, and an EU penalty measured in points of global revenue. Against all of that, the cost of validating your AI properly — testing the answers, against your domain, continuously — is a rounding error. Yet most enterprises still treat validation as a checkbox they tick once, not a discipline they run.
The green dashboard told them everything was fine. The trouble is that the dashboard was grading the wrong thing. It checked that they'd followed the process — the one thing that is easy to audit and safe to own, which is exactly why it survives in board decks long after it stops meaning anything. It never once asked whether the answer was right — and the answer being right was the only thing the customer, the regulator, and the loss column ever cared about. If you want to see how we test for that instead, we wrote up the approach here.
I still keep the SR 11-7 four-pillar checklist where I can see it, and the fourth pillar is monitoring — which only means something if you're monitoring the right thing. A dashboard that grades your process will sit there green while your AI quietly fumbles the multi-currency refund, the disputed reserve, the repealed statute. Klarna's was green too, right up to the quarter it lost $99 million. The validation that actually protects you is the unglamorous work I've been doing my whole career: collect the cases where you already know the correct answer, and check — again, and again, every time the model changes — whether the machine still gets them right.