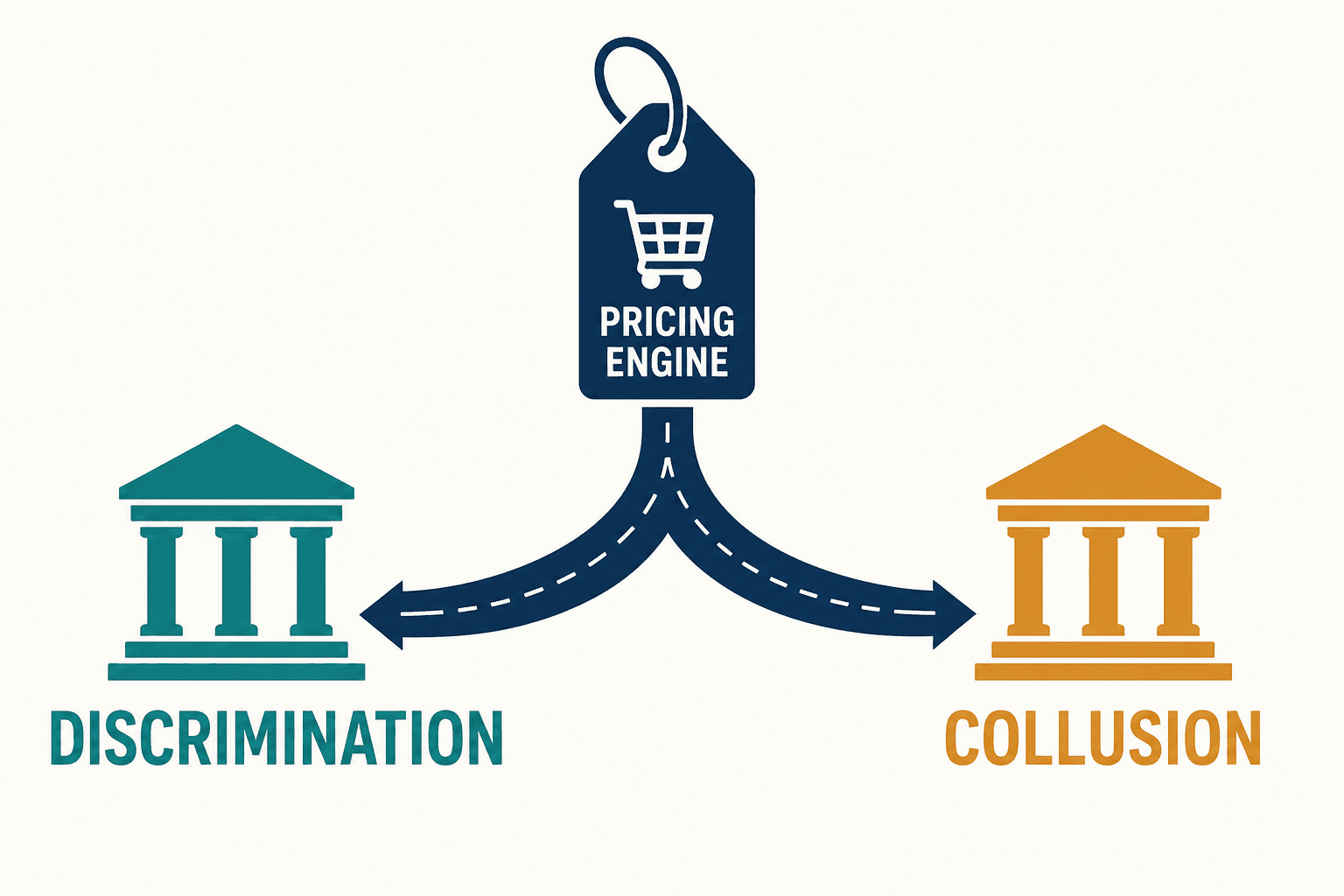
Your Pricing Algorithm Is Two Lawsuits, Not One — And Most Companies Only Defend Against One
The first pricing engine my team audited passed clean.
We had built a fairness scanner — the obvious thing. Point it at a pricing algorithm, check whether the model uses race, gender, age, any protected category as an input, and flag it if it does. We ran it against a mid-market retailer's personalization stack and it came back green. No protected fields. Nothing to see.
I almost sent the report. Then I pulled the feature-importance plot for the model — the ranked list of which inputs actually moved the price — and the third-strongest signal was device_type. Below it: ZIP code. Below that, the hour of the day the session started.
The algorithm had never seen race or income. It didn't need to. A user browsing on an older Android phone, from a lower-income ZIP code, at 11 PM, was getting systematically different prices than an iPhone user in a wealthy suburb at 2 in the afternoon. And census data will tell you exactly what those input clusters correlate with. Our scanner said "compliant." A disparate-impact regression would have said "indefensible." We had built a tool that checked for the crime nobody commits anymore.
That was the moment I understood what AI pricing compliance actually is, and why almost everyone gets it wrong.
In 2025 the FTC collected $2.56 billion from two companies, and they weren't sued for the same thing

Here's the number that should be on a whiteboard in every e-commerce GC's office. In a single year, the Federal Trade Commission settled algorithmic pricing cases with Instacart for $60 million and with Amazon for $2.5 billion. Different companies, different conduct, different legal theories — and that distinction is the entire game.
Instacart's case was about discrimination. Its Eversight pricing tool ran experiments that produced up to five different prices for the same item at the same store, with variation reaching 23%. Three-quarters of the catalog was subject to algorithmic price variation. The FTC's settlement didn't hinge on anyone proving Instacart meant to charge poorer shoppers more. It hinged on the outcome: certain consumer profiles paid systematically more, to the tune of an estimated $1,200 a year per household.
Amazon's case was about collusion. Project Nessie extracted an estimated $1.4 billion in excess profit by predicting when competitors would follow a price increase, then raising prices on more than 8 million items. There was no meeting, no agreement, no phone call between executives. Just one algorithm that had learned most competitors ran tit-for-tat pricing rules, and exploited it. The antitrust trial, FTC v. Amazon, is set for October 2026 and will test whether tacit collusion via algorithm violates Section 5 of the FTC Act.
One pricing engine. Two enforcement tracks. Most companies build a defense for one and never see the other coming.
This is the trap. A pricing team hears "compliance" and reaches for a disclosure banner — the consumer-protection answer. Or it hears "antitrust" and calls a law firm for a memo. Almost nobody is looking at the single algorithm sitting in production and asking both questions at once: is this output discriminatory, and is it colluding?
Read what we built for both tracks →
Why the disclosure-banner instinct is a trap
For about a week, early on, I was convinced this whole problem was a UI exercise.
New York had just passed its Algorithmic Pricing Disclosure Act, effective November 2025 — "clear and conspicuous disclosure" whenever prices use personal consumer data, $1,000 per violation. It read like a cookie-banner problem. Slap a notice on the page, log consent, done. I had a draft of the disclosure language redlined and ready.
Then I read the California Cartwright Act amendments, and the banner idea fell apart.
California's AB 325 and SB 763, effective January 2026, don't care about your disclosure. They make it statutory liability to use a "common algorithm" — defined as one used by two or more parties to influence prices using competitor information. They lowered the pleading standard so a plaintiff no longer has to rule out independent action just to survive a motion to dismiss. And they raised the corporate fine to the greater of $6 million or twice the gain, with treble damages and attorneys' fees in private suits. No banner on earth disclosures your way out of that. The exposure isn't in what you tell the consumer; it's in what your algorithm shares, directly or through a vendor, with the rest of the market.
That was the real turning point for us. Disclosure is the floor of the consumer-protection track. The collusion track runs underneath it on completely different physics, and the most dangerous part is that you can trip it through a vendor you've never thought of as a risk.
The vendor problem: your pricing software might be your liability
If you license a third-party pricing tool — Pricefx, PROS, Zilliant, Competera — you've outsourced your optimization. You have not outsourced your liability. You may have imported it.
The Ninth Circuit drew the line in Gibson v. Cendyn in August 2025, the first federal appellate ruling on algorithmic pricing antitrust. The good news: independently subscribing to the same pricing algorithm as your competitor is not, by itself, illegal. The bad news is the three conditions that blow the safe harbor. You lose protection when the tool pools competitively sensitive non-public data across clients, when the vendor markets its ability to "raise prices industry-wide," or when it facilitates the exchange of non-anonymized competitor data. Same vendor is fine. Same vendor pooling your rivals' live numbers into the model that prices your catalog is hub-and-spoke conspiracy exposure, even if you never spoke to a competitor.
So one of the first questions I now ask any client is not "what does your pricing model do" but "have you read your vendor's data-processing addendum?" Because the clause that quietly permits cross-client data pooling is where the antitrust risk lives, and it's three layers down in a contract the legal team signed and the pricing team never saw.
This is also where the FTC's 6(b) surveillance-pricing study matters. In 2024 it sent orders to eight firms — including Mastercard, PROS, Accenture, and McKinsey — demanding to know how they use consumer data to set prices. Some of the most common pricing platforms are named in that study. Their algorithm may be your liability, and "we just bought the software" has never been a defense.
What does the RealPage consent decree actually require?
The most instructive document in this entire space isn't a statute. It's the DOJ's RealPage consent decree from November 2025, and the reason it matters to e-commerce — even though RealPage is a rental-housing case — is that it's the first time a regulator wrote down, in technical detail, what a compliant pricing algorithm looks like.
I keep a printed copy. The headline coverage was "DOJ cracks down on rent-setting software." The actual teeth are an engineering specification:
- No training on lease data younger than 12 months — the model can't react to live market signals from competitors.
- No geographic analysis narrower than the state level — no using sub-market clustering to pinpoint pricing power.
- The "governor" guardrails — the floors and ceilings on what the algorithm can recommend — must be symmetric, so the tool can't be quietly tuned to only ratchet prices up.
- Auto-accept functions require user-set parameters, a 180-day implementation deadline, and a dedicated antitrust compliance officer for a seven-year term.
The RealPage decree is the closest thing we have to a regulator handing you the spec sheet for a defensible algorithm. Most companies read the press release and missed the blueprint.
When I read that the first time, my reaction was that the government had just done half my product roadmap for free. Symmetric governors, data-aging requirements, geographic floors — these aren't legal abstractions. They're constraints you can implement, test, and prove. That's the difference between a compliance memo and a compliance system.
The forensic problem nobody budgets for
Watch what actually happens when an FTC civil investigative demand lands on a pricing team's desk, with its 30-day production clock.
They cannot answer it. Not because they're guilty — because they never logged the right data. They can tell you what the algorithm priced last Tuesday, but not why: which inputs drove that specific price, whether the spread across user segments correlated with anything protected, whether a competitor's number influenced the output. So they spend six to twelve months in forensic data extraction, reconstructing decisions the system made thousands of times a second and never recorded.
This is the part I find genuinely unfair to good companies. A retailer can be running a perfectly defensible pricing strategy and still be unable to prove it, because proving it requires a model card for every price — a timestamped log of which inputs were used, what the output was, and how it tested against demographic proxies — and nobody builds that until the demand arrives.
We started designing for the demand first. Audit trail as a first-class output of the pricing decision, not an archaeology project after the fact. When the California AG launched its investigative sweep in January 2026 — letters to retail, grocery, and hotel businesses asking exactly how they use shopping history, browsing, location, and demographics to set prices — the companies that could answer in days instead of quarters were the ones who'd instrumented the decision, not just the price.
Why does agentic pricing make all of this worse?
The compliance frameworks everyone is scrambling to build right now assume a human reviews pricing decisions. That assumption is already expiring.
Walmart filed two AI pricing patents in January 2026 and is rolling out digital shelf labels to all 5,200 of its stores by year-end — though it's careful to call this "algorithmic merchandising," not "dynamic pricing," and insists prices stay consistent regardless of who's shopping. McKinsey is calling agentic commerce the defining e-commerce trend of 2026: AI agents that autonomously research, compare, and buy. Forrester expects one in five sellers to deploy seller-controlled pricing counter-agents by 2027.
This is the version of the problem that keeps me up, because the compliance question has no answer yet. When a buyer's AI agent negotiates a price with a seller's AI agent, and the agreed price turns out to be discriminatory — who's liable? There is no regulatory framework for agent-to-agent pricing. A system designed to scale to thousands of autonomous decisions per second cannot have a human in the loop checking each one for proxy discrimination or collusive convergence. The compliance has to be in the agent, or it doesn't exist.
That's not a future problem. It's the design constraint for any pricing system being architected today.
"Isn't this just a cost center?"
The objection I hear most, usually from a CRO, is that compliance tooling is overhead on a function whose whole job is to make money.
I'd put the numbers next to each other and let them argue. A full pricing compliance program — demographic impact analysis, collusion-risk assessment, multi-jurisdiction disclosure, audit-trail generation — runs roughly $100,000 to $505,000 in the first year, with continuous monitoring adding meaningfully on top. Instacart's settlement was $60 million. Amazon's was $2.5 billion. A few hundred thousand dollars of compliance against a nine-figure settlement isn't a cost center; it's the cheapest insurance policy in the building.
The second objection is subtler: won't disclosure and fairness constraints kill the optimization? And here's the thing I didn't expect when we started — 62% of US adults told Talker Research in December 2025 they're concerned about personalized pricing. Walmart's pricing patents drew social-media backlash. The brand risk of being the next Instacart headline is real and quantifiable. And I remind the CRO that Project Nessie's $1.4 billion in excess profit didn't survive contact with the FTC — revenue you can't defend is revenue you'll eventually refund. A pricing engine you can stand behind in public is worth more than a few extra basis points you have to hide.
What we actually built
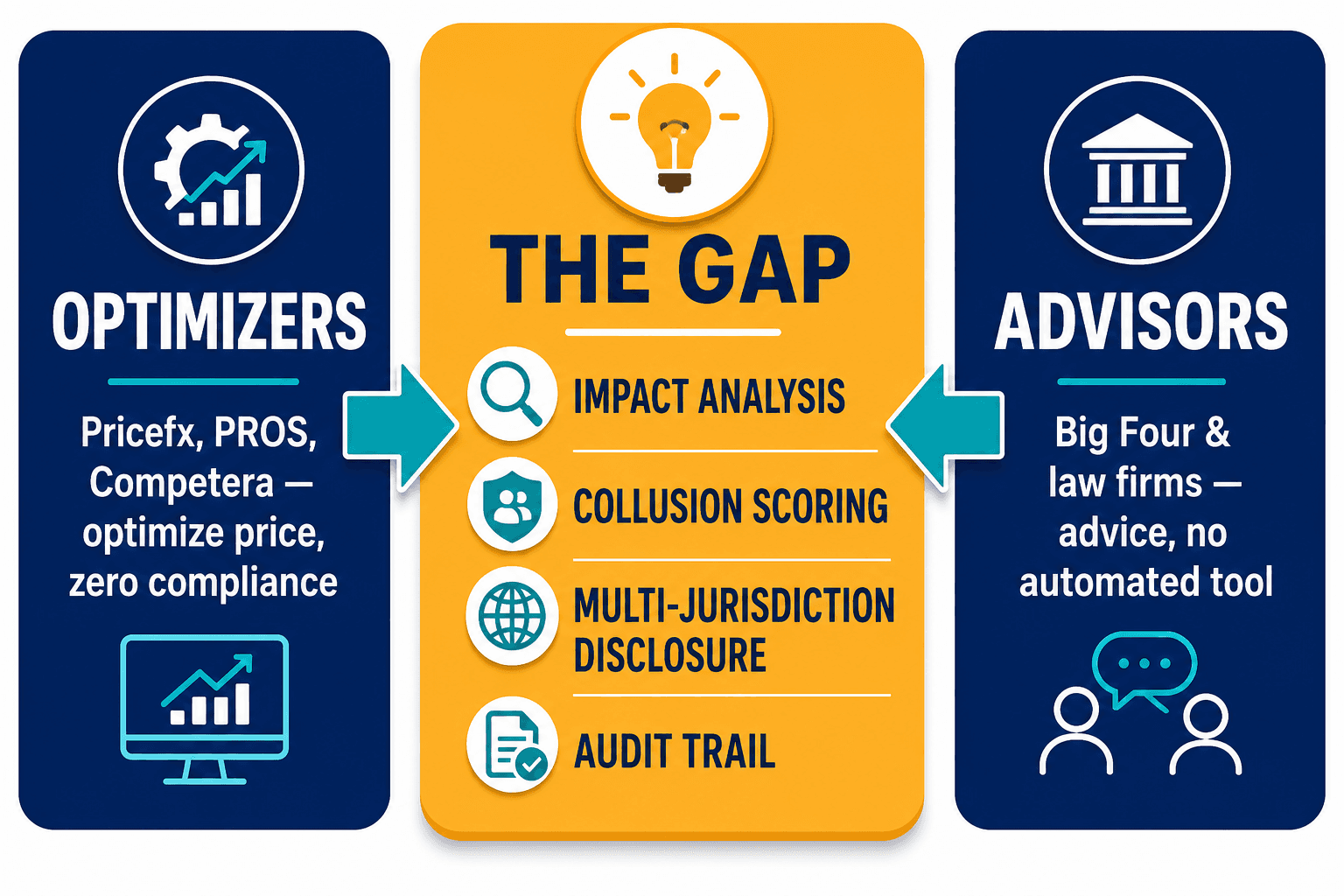
The gap I kept running into is that the market splits cleanly down the middle and serves neither side. Pricing platforms optimize prices and offer zero fairness testing, zero collusion monitoring, zero disclosure automation — their algorithm may be your liability. Law firms and the Big Four write excellent advisory memos and run nothing automated; a Deloitte or McKinsey antitrust engagement is consulting at $500K and up, with no tool at the end of it. ORCAA and FTI bring real audit and economic expertise, but consulting-only, litigation-shaped.
Nobody sat in the middle: an integrated layer that does demographic impact analysis on personalized pricing, scores algorithmic collusion risk, automates the multi-jurisdiction disclosure logic for New York, California, Colorado and the EU AI Act, and generates the audit trail an FTC or DOJ investigation will demand. That space — between what the optimizers do and what the lawyers do — is what we built Veriprajna's pricing compliance system to fill.
The regulatory map it has to cover is not stable, and that's the point of automating it. Colorado's AI Act takes effect June 2026, and for high-risk systems making consequential decisions it demands impact assessments before deployment, every year after, and again within 90 days of any substantial model change. The EU AI Act's high-risk obligations land August 2026, carrying penalties up to €35 million or 7% of global turnover. There were 51 algorithmic-pricing bills across 24 states in 2025, with Tennessee and New Mexico already moving in 2026. No human team tracks that matrix by hand and stays current. A compliance system that updates with the law is the only version that works.
I think about that first clean audit a lot.
The scariest thing about algorithmic pricing isn't the company that sets out to discriminate or collude. It's the one that does both, accidentally, through a model that was only ever told to maximize revenue — and finds out when the civil investigative demand arrives that it can't prove otherwise. The algorithm never intended anything. The output is illegal anyway, and intent was never the question.
Your pricing engine is making a legal argument every time it sets a price. The only thing in doubt is whether you'll be able to read it back.