Your Tenant-Screening AI Passed the Fairness Test. It Was Still Discriminating.
The first time I sat down with a property management company's compliance team, I made a mistake that I think most engineers make. I assumed I was there to fix one algorithm.
They had a tenant-screening model that scored applicants and a revenue-management tool that set rents. To me, walking in, those were two features of the same software stack — both "the AI," both my problem to make defensible. By the time I left, I understood the thing that has organized all of our housing AI compliance work since: those are not one problem with two faces. They are two completely different lawsuits waiting to happen, governed by two unrelated bodies of law, and the same company is exposed on both at once.
That gap — between how a builder sees these systems and how a court sees them — is exactly what makes housing AI compliance so easy to get wrong. So I want to walk through what I got wrong first, because the failure is more instructive than the fix.
The Four-Fifths Rule That Lied to Us
We started where everyone starts: fairness in screening. The legal anchor here is the Fair Housing Act, and the operational test most teams reach for is the four-fifths rule — if your approval rate for any protected group falls below 80% of your highest-approval group, you have a presumptive disparate-impact problem.
So we built an audit that computed exactly that ratio across the model's decisions. The aggregate numbers came back clean. Approval rates across racial groups sat comfortably above the 80% threshold. I remember the relief in the room. We were ready to write it up as compliant.
Then one of our engineers pulled the voucher holders out into their own column.
The picture inverted. Among applicants paying with housing-choice vouchers — guaranteed government income — the model was declining at a rate that would have been indefensible in front of any regulator. The four-fifths rule had passed because the disparity was hiding inside the approved pool. Once you disaggregated the subsidized tenants, it was right there in red.
A screening model can pass the four-fifths rule on aggregate and still encode the exact discrimination the rule exists to catch.
This is almost precisely what happened to SafeRent. Their Registry ScorePLUS algorithm scored voucher holders low because it weighted credit history heavily without accounting for the guaranteed income stream a voucher provides. The model treated a credit score as a neutral predictor. It is not neutral. Median FICO scores break along racial lines — 727 for White applicants, 667 for Hispanic, 627 for Black — and over half of White households sit above 700 while only about a fifth of Black households do. Feed credit history in as a primary feature and you are pouring those disparities straight into your approval rates.
SafeRent settled that class action for $2.275 million in November 2024. The part that should keep vendors up at night isn't the dollar figure. It's that the court rejected SafeRent's "neutral vendor" defense outright. They argued they merely supplied a score; the landlord made the decision. The court didn't buy it. If a landlord relies primarily on a third-party score, the provider of that score shares liability for the discriminatory outcome.
That ruling killed a comfortable assumption I'd carried in: that being the tooling vendor, one step removed from the lease decision, was a legal shield. It isn't. The model is the decision.
When Does Your Pricing Engine Become a Cartel?
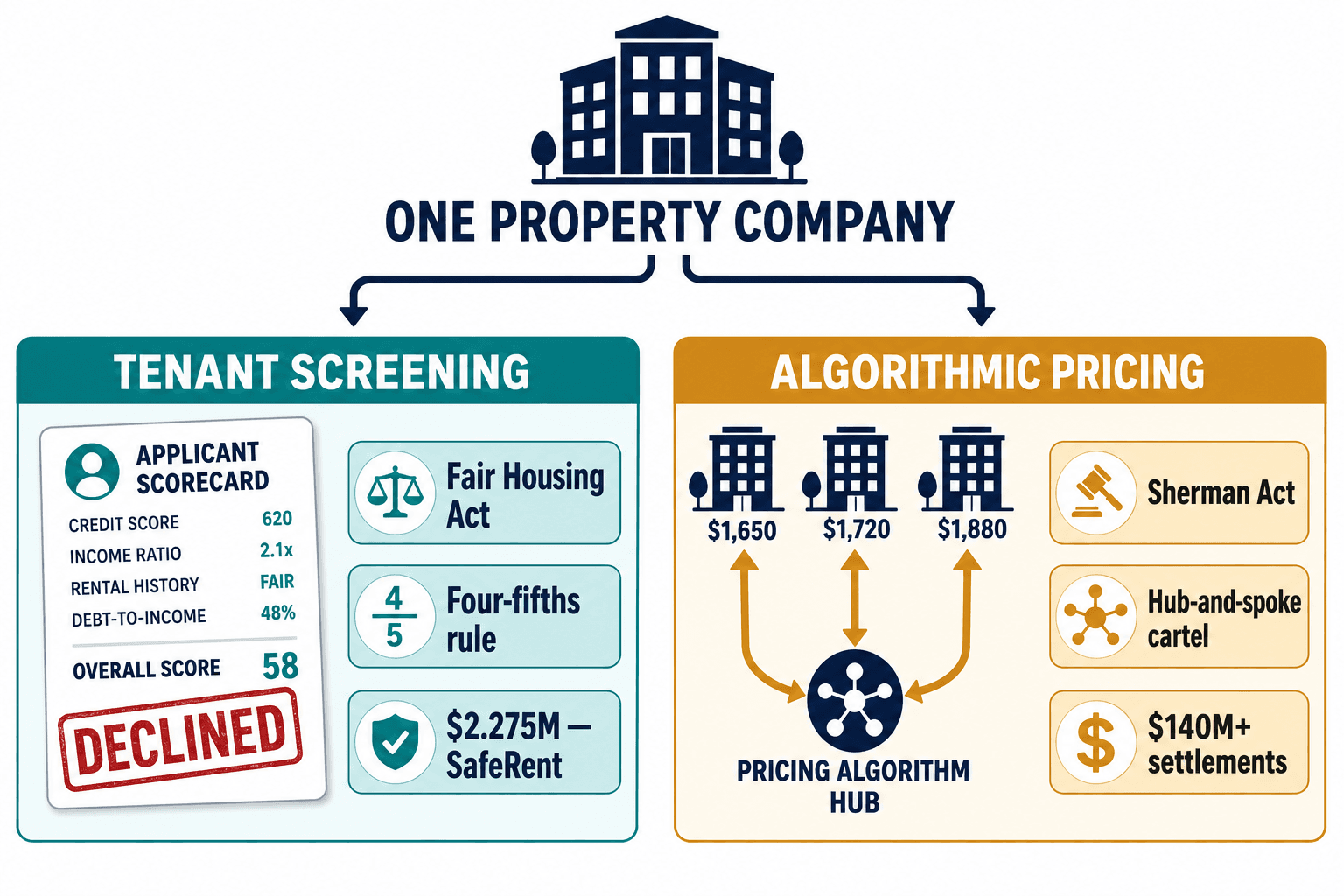
Here's the part that genuinely surprised me, and it's why I now refuse to scope a housing engagement around screening alone.
While we were heads-down on disparate impact, the bigger legal earthquake was happening on the pricing side — and it had nothing to do with fairness. RealPage's revenue-management products, AIRM and YieldStar, collected non-public rental rates, lease terms, and occupancy data from competing landlords, then used that pooled data to generate pricing recommendations designed to move rents, in the DOJ's words, "in unison."
The Department of Justice didn't treat that as a privacy problem or a fairness problem. They treated it as a hub-and-spoke cartel under Section 1 of the Sherman Act. RealPage was the hub. Every landlord feeding competitor data through the platform was a spoke. The shape of the antitrust theory is the thing to internalize: nobody had to sit in a room and agree to fix prices. The algorithm was the agreement.
What made it worse was the automation defaults. AIRM would auto-accept its own price recommendations within a 3% daily and 8% weekly change — and most landlords never touched those settings. The algorithm was effectively setting rents with no human in the loop. ProPublica's analysis, cited in the DOJ filings, put the cost to renters at roughly $70 a month, around 4% of rent, totaling something like $3.8 billion in added rental costs in 2023 alone.
The landlords paid for it. Greystar settled for $50 million plus another $7 million to states. BH Management for $15 million. Simpson Property Group for $6.5 million. Add the smaller ones and you're past $140 million in landlord class-action settlements by October 2025. FPI Management paid $2.8 million just for using Yardi's pricing tool. The vendor's algorithm; the operator's liability.
So the company sitting in front of me wasn't facing one risk profile. It was facing Fair Housing disparate-impact exposure on the screening side and Sherman Act antitrust exposure on the pricing side, simultaneously, from two systems its own engineers thought of as "the AI."
What Actually Won a Case: Architecture, Not Intent
For a while I assumed the pricing problem was about behavior — don't pool competitor data, don't auto-accept, document your good intentions. Then I read how Yardi actually won.
In the California state case, Yardi got summary judgment in its favor. Not because they argued their hearts were pure, but because their Revenue IQ product could prove something architectural: it "does not and by design cannot use any client's confidential pricing information for any other client." The data was isolated at the system level. Cross-client contamination wasn't merely against policy — it was structurally impossible.
That single line reorganized how I think about compliance engineering.
Data isolation is not a promise you make in a policy document. It's a property you can prove in an architecture diagram.
Yardi's federal case is still ongoing, and a judge there let antitrust allegations proceed — so this is no clean victory lap. But the contrast is the lesson. The defensible posture wasn't intent. It was a system that, when a regulator demanded "show me you can't share competitor data across clients," could draw the isolation boundary on a whiteboard and show that no data path crossed it. Most teams I meet have built the opposite: a shared model, a shared data lake, and a deck full of assurances about how they use it responsibly.
The same logic now runs through the RealPage consent decree the DOJ secured in late 2025. Look past the headline and the teeth are operational: model training is limited to historical data at least 12 months old. Runtime pricing can't incorporate non-public rival statistics. The "governor" features that cap price changes have to be symmetrical — equal weight to cuts and increases, not a one-way ratchet upward. And the auto-accept features have to be configurable and manually set by a human. That last one matters more than it looks. The old workflow — set it to 3% daily, 8% weekly, walk away — is now itself the violation. The settlement runs seven years, with no financial penalty and no admission of wrongdoing, which tells you the DOJ wanted the architecture changed, not a check.
This is when our work shifted from auditing models to engineering them. You can't bolt these properties on afterward. Twelve-month data aging, provable client isolation, symmetric governors, a human gate on auto-accept — those are design decisions you make before a single price ships, or you litigate them later.
Why Is Housing AI Compliance a Map, Not a Model?
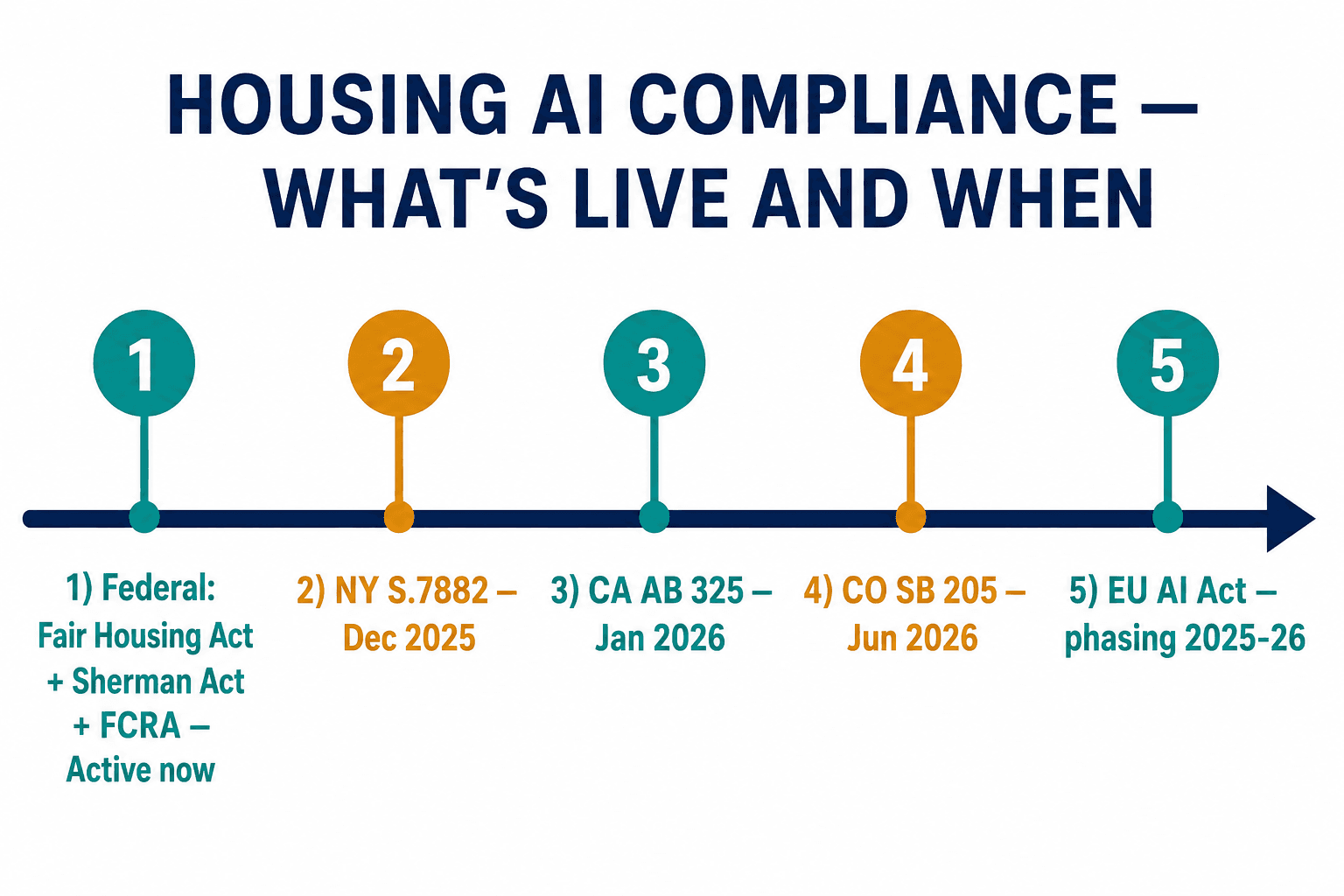
When people ask what we actually deliver, the honest answer is that the hardest deliverable isn't a model. It's a regulatory matrix that a compliance officer can take into an internal meeting and trust.
Housing AI compliance is not one regulation. It's a patchwork that's hardening fast, and federal and state law are moving in opposite directions at the same time. Federally, enforcement is weakening — HUD's AI guidance came off the website, CFPB has shed staff, and there's been an executive push to deprioritize disparate-impact enforcement. If you only watched Washington, you'd conclude the risk was receding.
Watch only Washington and you'll think the risk is receding. The states are where it actually lives now.
The states tell the opposite story, and they're where the exposure now lives. California's AB 325, effective January 1, 2026, amends the Cartwright Act to prohibit "common" pricing algorithms — defined as tools used by two or more parties — that rely on competitor data, and it rejects the tougher federal pleading standard, which makes it materially easier for plaintiffs to get into court. New York's S.7882, effective in December 2025, goes further: a blanket ban on residential pricing tools with a "coordinating function," with no distinction between public and non-public data, and a private right of action for tenants under the Donnelly Act. RealPage is challenging it on First Amendment grounds, so enforcement is stayed pending that fight — but you don't get to assume you'll win someone else's constitutional case. Colorado's SB 205, effective June 30, 2026, classifies tenant screening as a "consequential decision" and demands annual impact assessments, risk-management programs, and adverse-decision disclosures that describe how the AI contributed, what data it used, and how an applicant can appeal.
Underneath all of that runs a federal statute most teams forget is even in play: the Fair Credit Reporting Act. Any algorithmic score that functions as a consumer report has to comply with FCRA's two-step adverse-action process — which means when your model declines someone, you owe them specific reasons, not "the algorithm said no." That single requirement is incompatible with a black-box screening model, and it's why the adverse-action notice template is one of the first documents I ask to see.
There's a detail in AB 325 that quietly changes the whole build calculus: it only bites tools used by two or more parties. A shared, multi-tenant pricing product is squarely in scope. A bespoke, single-operator model is not. The regulation is, in effect, paying you to abandon the pooled-data SaaS architecture that created the antitrust problem in the first place.
And for anyone with European tenants, the EU AI Act treats both screening and pricing as high-risk uses, with fines up to €35 million or 7% of global turnover — and its high-risk obligations phase in across 2025 and 2026, so the clock has already started for any operator with EU exposure. Stack the Fair Housing penalties on top — $26,262 for a first offense, up to $131,308 for repeat violations under the 2025 adjustments — and the cost of getting the map wrong isn't theoretical.
I keep a single spreadsheet for this, color-coded by effective date, because the question a GC actually asks isn't "are we compliant?" It's "which of these is live in the states where we operate, and what does each one specifically require?" Producing that answer, defensibly, for a given operator's footprint, is most of the value.
The horizontal AI-governance platforms — Credo AI, Holistic AI, FairNow and the rest — are genuinely good at policy management and fairness monitoring, but they're built to be industry-agnostic. None of them maps a tenant-screening model to HUD guidance, the four-fifths rule, FCRA adverse action, and the antitrust posture of your pricing engine at the same time. That intersection is the whole job in housing, and it's exactly what a general-purpose tool leaves to you. We built the housing AI compliance practice around delivering exactly that map alongside the audited models — because the model is worthless if you can't tell the board which law it's being judged against.
Can't You Just Strip Out the Protected Attributes?
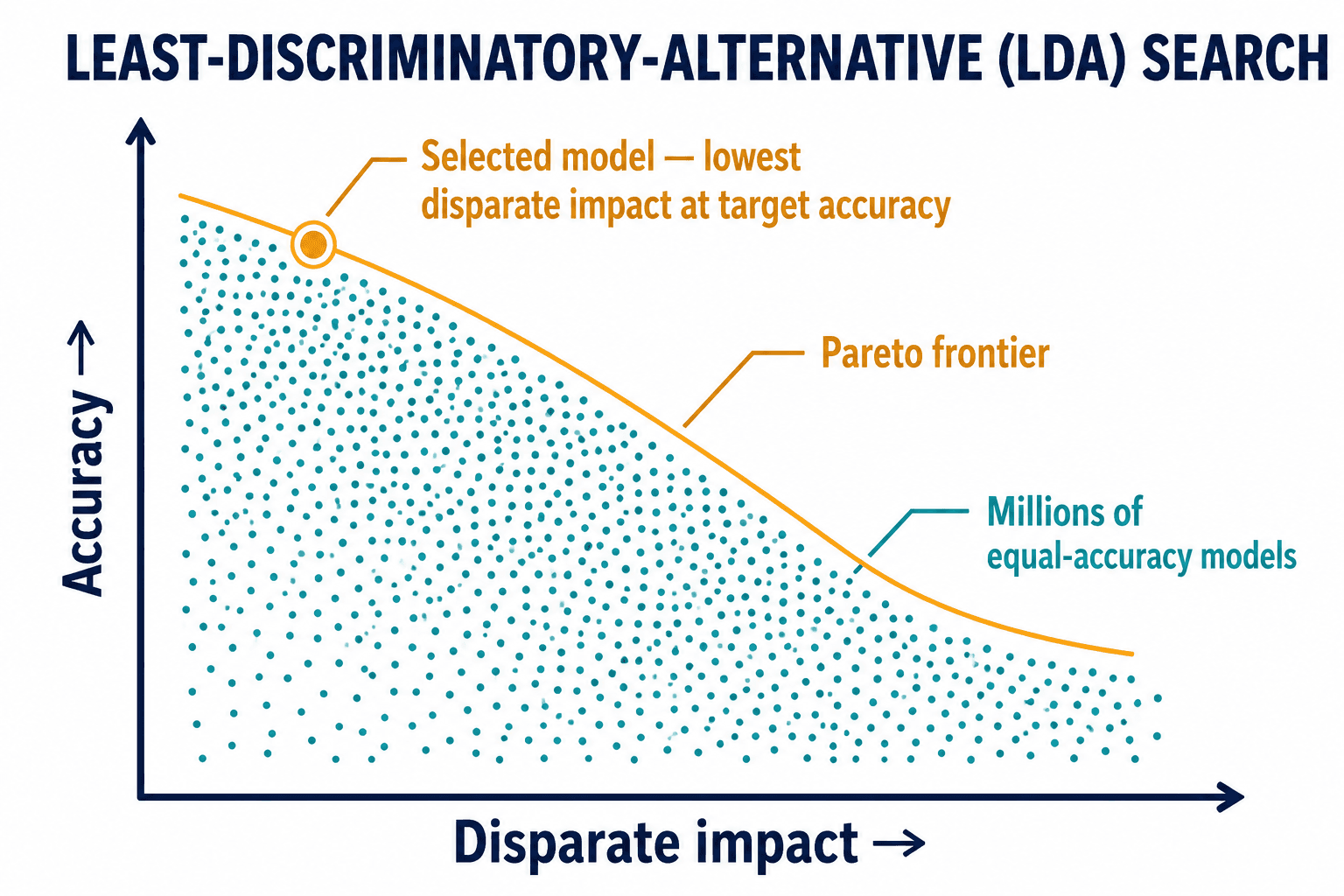
This is the objection I hear most, and it's wrong in an interesting way. The intuition is: remove race, remove gender, and the model can't discriminate. But credit score, eviction history, and criminal-background data are all proxies that carry the disparity right back in — that's exactly how SafeRent's "neutral" credit weighting produced a racial skew without ever seeing race.
The real tool is less famous and more powerful: a least-discriminatory-alternative search, or LDA. The premise comes out of the observation that for any given prediction problem, there isn't one model — there are millions of models that achieve roughly equal accuracy but wildly different fairness profiles. So you use integer programming — the kind of exhaustive optimization solvers like CPLEX or Gurobi run — to search that whole space and map the trade-off between accuracy and disparate impact as a Pareto frontier. Then you can show, with evidence, that you didn't just pick a model that worked; you picked the least discriminatory model that still met your performance bar.
The CFPB has explicitly called for "regular testing for disparate impact, including searches for less discriminatory alternatives." It's mature in fair lending. Almost nobody offers it for housing. When a regulator asks why you chose the model you chose, "it was accurate" is not a defense — it's the gap a plaintiff drives a disparate-impact claim through. "Here is the frontier, and here is the point we selected and why" is the answer that holds up under a deposition.
Agentic Leasing: Where Housing AI Compliance Breaks Next
The reason I think this gets harder, not easier, is sitting in roughly one of every twelve U.S. multifamily units already: agentic leasing AI.
The next wave of property-management software isn't a screening score or a price recommendation. It's autonomous agents that field inquiries, schedule tours, pre-screen applicants, and negotiate lease terms with no human in the loop. One platform claims a 65% reduction in lead-to-lease time. The efficiency is real. So is the exposure.
Every decision an autonomous agent makes is a potential Fair Housing violation or an antitrust touchpoint. An agent that varies its response quality by an applicant's demographics, or steers certain applicants toward certain buildings, or applies pricing concessions unevenly, is generating liability that scales with every single interaction — at machine speed, across thousands of conversations, with no human who can later say "I'd have caught that." The compliance architecture for agentic leasing doesn't exist yet, in the way that data-isolation architecture for pricing barely existed until Yardi's lawyers needed it.
That's the frontier we're building toward now. Not a fairness dashboard bolted onto a model someone else trained, but systems where the screening logic can survive a disaggregated four-fifths audit, the pricing logic can prove client isolation in an architecture diagram, and an autonomous agent's every decision leaves a record a regulator can read. The full picture of how we approach it lives on our housing AI compliance page.
I came into this thinking my job was to make one algorithm fair. What I'd tell any property operator now is simpler and harder: you are running two algorithms, and a court will judge each one by a different statute you've probably never heard your own engineers mention. SafeRent's lawyers learned that a credit score is not neutral. RealPage's learned that an algorithm can be a conspiracy. The cheapest place to learn both lessons is a whiteboard — before a regulator stands at yours and asks you to draw the isolation boundary and prove that no data ever crossed it.