The Day Our Private AI Handed an Employee a Salary It Shouldn't Have Seen
The Memo That Doesn't Work
Somewhere in your company right now, someone has pasted a customer contract into a chatbot to summarize it. They didn't ask. They're not malicious. They had a deadline and a tool that worked, and the tool happened to send that contract to a server owned by a company on another continent.
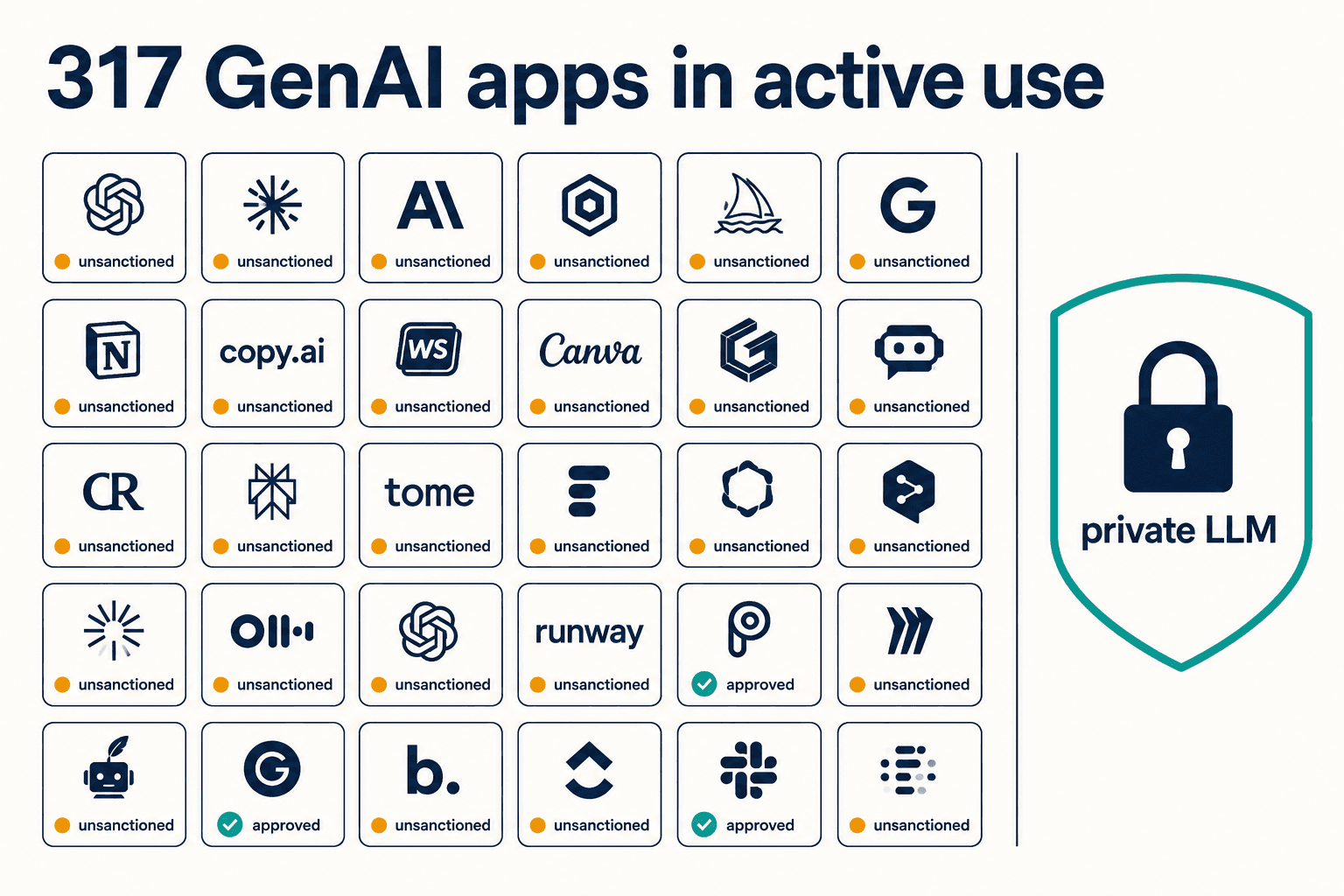
I know this because every CISO I've worked with has the same dashboard, and it tells the same story. One of them pulled up Netskope in a meeting and showed me 317 distinct generative-AI apps in active use across his org. He had sanctioned a handful of them. The rest were his employees solving their own problems, one paste at a time.
That gap — between the AI you've approved and the AI your people are actually using — is the problem I've spent the last stretch of my career building Veriprajna to solve. We do private LLM deployment: we put a capable large language model inside your own infrastructure, under your own controls, so the work your employees are already doing with AI stops leaking out the side of the building. Sovereign AI isn't a philosophy pitch about national tech independence. It's the practical answer to a question every security leader is already failing to answer: where is our data going, and can we prove it?
The instinct, when you first see that dashboard, is to send a memo. Ban the tools. I tried that thinking on for size early, and I want to tell you exactly why it falls apart — because the failure is the whole reason this company exists.
Banning AI doesn't remove it from your company. It just removes your visibility into it.
The numbers make the case better than I can. IBM's 2025 Cost of a Data Breach report found that one in five organizations has already suffered a breach tied to shadow AI — unsanctioned tools used without IT's knowledge. Those breaches cost on average $670,000 more than traditional incidents, and they took 247 days to detect versus 241 for everything else. A separate survey put it bluntly: 43% of employees admit to sharing sensitive work information with AI tools their employer never approved. A ban doesn't change that behavior. It just guarantees you'll be the last to know when it goes wrong.
Why Doesn't a Private Chatbot Fix Shadow AI?
So if you can't ban it, you build the safe alternative. Stand up an internal chatbot, point it at a good model, tell everyone to use that instead. This is where I made my most expensive mistake, and it's worth dwelling on because almost everyone makes it.
The first internal deployment I was close to looked great in the demo. Clean interface, fast responses, a model that knew the company's documents. We were proud of it. Then, during the pilot, someone in a junior role asked it a question about a compensation plan — and it answered. Fully. Accurately. With details pulled from a document that person had no business reading.
Nothing had been hacked. The retrieval system did exactly what we built it to do: find the most relevant documents and feed them to the model. We had just never taught it that relevance and permission are different things. The chatbot was a faithful librarian who'd been given the master key to every locked room in the building.
That afternoon reframed the entire problem for me. The model was never the hard part. The hard part is permission.
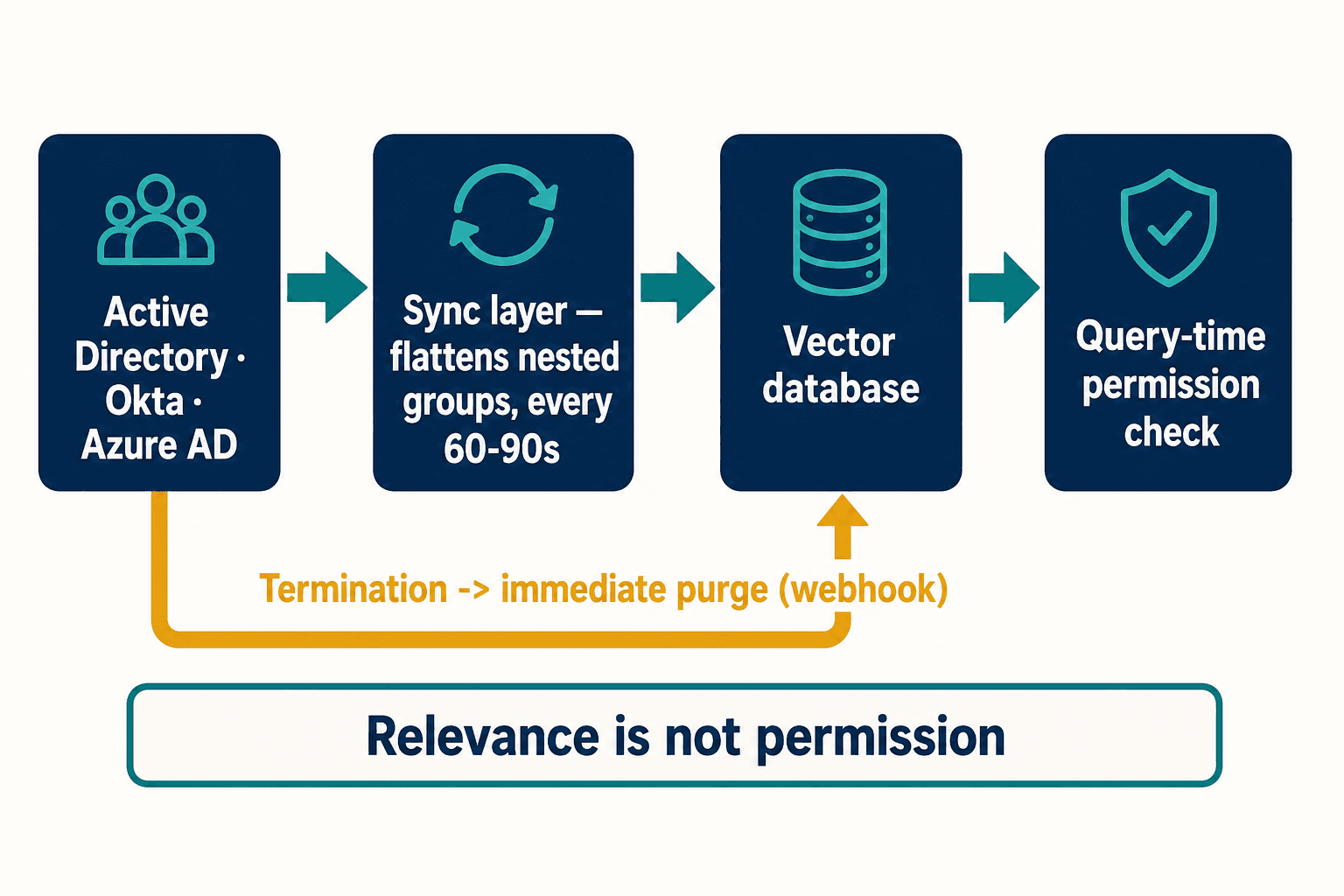
Here's the thing nobody tells you in the vendor demos: most enterprises carry years of accumulated access logic buried in Active Directory — nested security groups, inherited permissions, distribution lists, organizational units layered on top of each other by people who left years ago. When you build a retrieval system, the naive move is to tag each chunk of text with a flat list of who can see it. That collapses the moment you hit real-world group nesting. A document inherits access from a group, which inherits from another group, which a contractor was added to for a single project years ago.
Getting this right is the actual work. We built a synchronization layer that sits between the identity provider — Active Directory, Okta, Azure AD — and the vector database where the documents live. It resolves group membership recursively, flattens those inheritance chains, and refreshes the access metadata on a tight cadence. For most deployments we sync every 60 to 90 seconds. But the case that keeps you up at night is the termination: someone gets walked out at 9 a.m., and you cannot have the system still answering with their access at 9:05. So revocations don't wait for the next sync — an Okta or Azure AD webhook fires an immediate purge the instant the account is disabled.
Relevance and permission are not the same thing, and a retrieval system that confuses them will hand the right answer to exactly the wrong person. No major RAG platform solves this out of the box — I went looking.
That's not marketing confidence — it's what I found looking. TrueFoundry, Databricks, the cloud-native search products all have partial answers: read-only permission checks, periodic syncs. None of them inherit the full picture of group policies and attribute-based rules — time-limited access, "only from a managed device," classification levels — that a regulated enterprise actually runs on. So we build that policy engine as custom work, because there's no shortcut to it. If you want the full architecture of how this permission enforcement works end to end, it's laid out on our sovereign AI and private LLM deployment page.
Does a Frankfurt Data Center Make Your AI European?
There's a second trap, and it's subtler because it looks like compliance. A lot of enterprises reach for a managed option — Azure OpenAI, AWS Bedrock — and feel safe. The data stays in their cloud tenant. There are VPC endpoints, private networking, a stack of certifications. For plenty of companies, that genuinely is the right answer, and I'll say so to a client's face when it is.
But there's a legal fact underneath the technical one that I watch people miss constantly. Hosting your AI in a Frankfurt data center does not make it European. Microsoft and Amazon are US-headquartered companies, and that makes them subject to the US CLOUD Act, which lets American law enforcement compel a US company to hand over data it stores anywhere in the world. GDPR's Article 48 says a foreign court order is only valid here with an international agreement. Those two laws point in opposite directions, and your data sits in the gap.
This stopped being theoretical in March 2026. Austria's Data Protection Authority fined a Vienna fintech EUR 450,000 for running credit scoring through a US-based AI API — ruling it an unlawful data transfer under GDPR. The company had assumed, like nearly everyone does, that European-region hosting was enough. It wasn't. I keep that ruling bookmarked because it's the cleanest illustration I've found of a risk most boards don't know they're carrying.
The mirror-image case is a US hospital chain: there the CLOUD Act barely registers, but HIPAA's business-associate requirements and — the moment you touch federal contracts — the NIST AI Risk Management Framework and FedRAMP High become the line you're drawing instead. The jurisdiction question keeps the same shape; only the statute on the wall changes.
For a US financial firm with no European customers, none of this matters and Azure OpenAI is often exactly right. For a European bank processing its own customers' data, the calculus inverts — and the only configuration that removes CLOUD Act exposure entirely is a self-hosted deployment on open-weight models running on infrastructure whose operator isn't subject to US jurisdiction. That's the actual function of the European sovereign cloud providers — OVHcloud, Scaleway, the new Blackwell capacity coming online in Europe. Not patriotism. Jurisdiction.
And the deadline is real. The EU AI Act's Article 50 transparency obligations become enforceable on August 2, 2026. Stack the AI Act's penalties on top of GDPR's and the combined ceiling reaches EUR 55 million, or 11% of global annual turnover. That is not a fine you absorb. That is a number that ends careers.
"Just Use the API" — The Conversation I Have Every Month

The pushback I hear most is financial, and it's fair: self-hosting sounds expensive. Why buy GPUs and hire a team when an API is a credit-card charge away?
Because the math flips, and the place it flips is more specific than people expect. For a self-hosted 70-billion-parameter model, inference runs around $0.013 per thousand tokens. The same work through a hosted API like GPT-4o mini costs $0.15 to $0.60 per thousand. That's not a rounding difference. But it only matters above a certain volume, because self-hosted GPUs cost money whether you're using them or sitting idle.
The break-even sits around two million tokens a day. Below that line, APIs win — you're not paying for idle hardware, and I'll tell a client to stay on APIs without blinking. Above it, self-hosting saves 60 to 85% on inference. One fintech I know cut its monthly AI bill from $47,000 to $8,000 by moving to hybrid self-hosting.
But — and this is the part the GPU price tags hide — the hardware is rarely the biggest line item. At today's prices an H100 rents for $2.50 to $3.50 an hour, and a single one running an open-weight model like Llama 3.3 70B serves 30 to 50 concurrent users at sub-two-second latency. The expensive part is the people. You need MLOps engineers — two minimum for production reliability — at $200,000 to $350,000 each, plus monitoring, evaluation pipelines, a rollback strategy. For a team new to running models, total cost of ownership lands around 3.2x the raw API cost in year one. For a mature team with existing tooling, it drops to about 1.8x.
That fintech that cut its bill so dramatically? It worked because they already had a Kubernetes team and 18 months of operational scar tissue. The same move would have bankrupted a team learning on the job.
The GPU is the cheapest part of self-hosting. The two engineers who keep it running are the line item that decides whether the math actually works — and anyone who answers "should we self-host?" faster than "it depends on your volume and your team" is selling you something.
The good news underneath all this is that the open-weight models got good enough to make the question worth asking at all. Llama 3.3 70B hits 86% on the MMLU benchmark and runs roughly 25 times cheaper self-hosted than the equivalent API. DeepSeek-V3 scores 88.5% — edging out a frontier proprietary model on that measure. For the large majority of enterprise tasks, the model you can run inside your own walls is no longer the compromise it was two years ago.
What Happens When the AI Stops Just Talking
One development turns all of this from prudent into urgent. The AI in your company is about to stop being a chatbot and start being an agent — software that doesn't just answer questions but takes actions, with standing access to your systems.
Gartner expects 40% of enterprise applications to embed AI agents by the end of 2026, up from under 5% a year earlier. But only about 5% of enterprises have actually moved agents from pilot into production, and the security picture is genuinely alarming: 92% of security leaders say they lack full visibility into the AI identities already operating in their environment. An agent that can read your CRM, file tickets, and move money is a very different risk than a chatbot that can summarize a PDF.
Everything I've described — the permission enforcement, the jurisdiction control, the runtime guardrails that catch prompt injection — stops being a nice-to-have the moment your AI can act. A chatbot that retrieves the wrong document is an embarrassment. An agent with standing access and no permission boundary is an incident waiting for a date.
This is the reframe I'd leave you with. The guardrail layer matters here too — and it's worth knowing that off-the-shelf options like NVIDIA's NeMo Guardrails add real latency, 100 to 300 milliseconds per call, which is why we tune the policy logic to the specific compliance pattern instead of bolting on a generic filter. But the deeper point is architectural. You can't put an agent on infrastructure you don't control and call it governed.
The Part People Always Push Back On
People ask me whether they really have to choose — whether they can keep some cloud APIs and still call themselves sovereign. Yes: most deployments I'd recommend are hybrid, sensitive workloads on private infrastructure and low-risk ones on managed APIs, with a clear policy boundary deciding which is which. Sovereignty was never an all-or-nothing vow; it's drawing the line in the right place and being able to prove where it sits.
The other question is timing — isn't it early? The Austrian fine already landed. The Article 50 deadline is on the calendar. Your employees are pasting data into hundreds of tools you haven't approved while you read this. The cost of moving early is a project. The cost of moving late is measured against an eleven-percent-of-turnover ceiling.
I started Veriprajna because I watched a faithful little chatbot hand a junior employee a salary it should never have shown them, and I realized the whole industry was selling models when the actual problem was control. The model is the easy part. It always was.
Your people aren't waiting for permission to use AI. The only open question is whether the AI they're using answers to you.
If you want to see how we design that control for a specific risk profile — where the line between private and managed should sit, how the permission layer gets built, what the real total cost looks like for your team — that's what we lay out, honestly and vendor-neutral, on the Veriprajna sovereign AI page. Bring your dashboard. I already know roughly what it says.