A Grandfather Spent Ten Days in Jail Because an Algorithm Said He Was Guilty
I was on a call with a potential client — a mid-size retail chain — when their VP of Loss Prevention said something that made my stomach drop.
"We're looking at a facial recognition vendor. They say their system is 98% accurate. We just need someone to plug it in."
I asked one question: "98% accurate on whose faces?"
Silence.
That conversation happened weeks after I'd been reading through the FTC's complaint against Rite Aid — all 54 pages of it — and the $10 million lawsuit filed by Harvey Eugene Murphy Jr., a 61-year-old grandfather who spent ten days in a Houston jail for a robbery committed while he was home in Sacramento, California. He was identified by a facial recognition system. The system was wrong. By the time anyone bothered to check, Murphy had been beaten and sexually assaulted behind bars.
I remember sitting in my office that night, re-reading the details of Murphy's case, and feeling something I don't usually feel when I read technical failure reports: rage. Not at the algorithm — algorithms don't have intent. At the humans who deployed it like it was a barcode scanner. At the architecture that made this inevitable.
I run Veriprajna. We build what I call "deep AI" — systems with uncertainty quantification, multi-agent governance, and rigorous engineering underneath. The opposite of what got Rite Aid banned and Harvey Murphy arrested. And I need to tell you why the difference matters more than most people in this industry want to admit.
What Happened at Rite Aid Wasn't a Glitch — It Was a Design Choice
In December 2023, the FTC did something unprecedented: they banned Rite Aid from using facial recognition technology for five years. Not fined. Not warned. Banned.
Between 2012 and 2020, Rite Aid had deployed AI-based facial recognition surveillance across hundreds of stores. The idea was straightforward — identify known shoplifters, alert security, reduce theft. The execution was a catastrophe.
Rite Aid bought their facial recognition from two third-party vendors. Both vendors' contracts expressly disclaimed any warranty regarding accuracy. Read that again. The companies selling the technology wouldn't even promise it worked. And Rite Aid deployed it anyway — in stores full of real people, with real consequences for being falsely identified.
Nobody at Rite Aid tested the system for accuracy. Nobody checked whether the vendors had tested it. Nobody implemented image quality controls. Store employees were feeding grainy CCTV stills and cell phone photos into the enrollment database, and the system was dutifully "matching" those degraded images against every face that walked through the door.
The results were predictable to anyone who understands biometric engineering, and devastating to anyone who doesn't. Thousands of false positives. Innocent customers followed through aisles, searched, publicly accused of theft. And here's the part that should make every enterprise leader pause: the false alerts disproportionately targeted women and people of color. Stores in plurality-Black and Asian communities saw significantly more false matches than stores in plurality-White communities.
This wasn't a bug. It was the inevitable output of uncalibrated models trained on non-representative datasets, deployed without monitoring, on degraded imagery, with no human review process worth the name.
Why Did a 61-Year-Old Grandfather Go to Jail?
Harvey Murphy's case is worse, because the chain of failure is longer and the human cost is more visceral.
In January 2022, someone robbed a Sunglass Hut in Houston. EssilorLuxottica, the parent company, collaborated with Macy's to run facial recognition on the store's surveillance footage. The system matched the grainy robbery footage against a database that apparently contained Murphy's booking photo from non-violent offenses decades earlier.
I want you to hold two facts in your mind simultaneously. First: Murphy was in Sacramento, California, on the day of the robbery. Second: the system matched current surveillance footage against a photo taken years — possibly decades — prior. Studies have shown that matching current images against aged photos can produce false-positive rates as high as 90%. This is called the "age-gap" problem, and anyone deploying facial recognition in a law enforcement context should know about it.
But here's what haunts me about this case. According to the lawsuit, Sunglass Hut and Macy's presented the automated match to law enforcement as a verified fact. Not as a lead. Not as a probability. As identification. The police stopped investigating. They had their man.
When a machine's output is treated with more authority than a human being's alibi, we've crossed a line that no amount of accuracy improvement can fix.
Murphy was arrested. He told them he wasn't in Texas. It didn't matter. He spent ten days in jail before the District Attorney's office confirmed his alibi. By then, the damage was done — physical, psychological, permanent.
My team and I spent an evening going through the technical details of this case, trying to reconstruct what the system architecture probably looked like. Low-resolution input imagery. An aged gallery photo. Almost certainly a closed-set identification model — the kind optimized to always find a "best match," even when the actual person isn't in the database. No uncertainty quantification. No confidence thresholding. No meaningful human review between the algorithm's output and a man losing his freedom.
Every single one of those failures was preventable. Not with better AI. With better architecture.
What Is the "Wrapper" Problem and Why Should You Care?

Here's where I need to get technical for a moment, because the pattern behind both of these disasters is the same pattern I see in enterprise after enterprise.
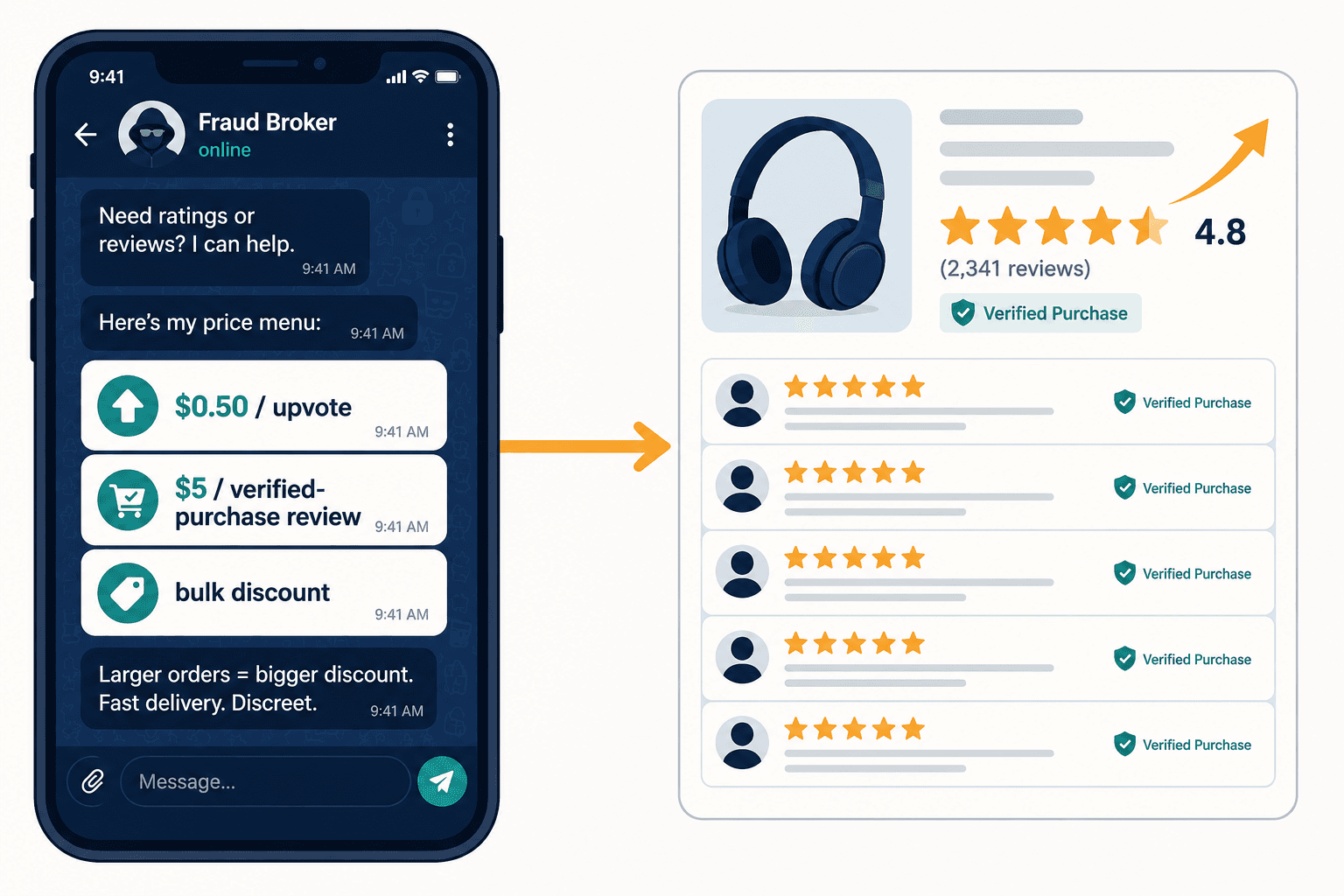
Most companies deploying AI today are using what the industry calls "wrappers." A wrapper is a branded interface — a dashboard, an app, a workflow tool — that sits on top of someone else's AI model. You send data to a third-party API, it sends back a result, and you display it to your user. The wrapper company doesn't build the model. Doesn't train it. Doesn't understand its failure modes. Doesn't control its updates.
Rite Aid was running a wrapper. A thin layer of retail security workflow on top of vendors' black-box facial recognition APIs. When those APIs produced garbage, Rite Aid had no way to know, no way to intervene, and — as the FTC made clear — no way to escape liability.
This is the asymmetry that kills companies: you assume 100% of the liability for a system you have 0% visibility into.
I've written about this architectural divide in depth in the interactive version of our research, but the core argument is simple. Wrappers are fine for low-stakes applications. Summarizing meeting notes. Generating marketing copy. Things where a wrong answer is annoying, not ruinous.
But the moment your AI system can get someone arrested, denied a loan, fired, or publicly humiliated — and facial recognition in retail can do all of those things — a wrapper is a liability bomb with a countdown timer.
How Do You Build AI That Knows When It Doesn't Know?
There's a moment I keep coming back to. We were building an identification pipeline for a client, and one of my engineers ran a batch of test images through the system. The accuracy numbers looked great — north of 95%. Everyone was pleased. Then I asked her to run the same batch with the confidence distributions visible.
The room got quiet.
A significant chunk of those "correct" identifications had uncertainty distributions so wide they were essentially coin flips that happened to land right. The model was guessing confidently, not identifying reliably. If we'd shipped that system with just the accuracy score, we'd have been no different from the vendors who sold Rite Aid their software.
This is the core problem with how most AI is deployed: every output is treated as a binary truth when it's actually a probabilistic estimate. The model doesn't say "this is John Smith." It says "given what I've seen, there's an X% chance this is John Smith, plus or minus Y." But most systems throw away the "plus or minus Y" part and just show you the X.
At Veriprajna, we build what's called Uncertainty Quantification (UQ) into every high-stakes system. There are two kinds of uncertainty that matter:
Aleatoric uncertainty comes from noise in the data itself — bad lighting, motion blur, a scratched camera lens. You can't train this away. If the image is missing information, no model in the world can hallucinate it back reliably.
Epistemic uncertainty comes from the model's own limitations — it hasn't seen enough examples of a particular demographic, or it's never encountered this specific lighting condition. This can be reduced with better training data.
Brittle systems — wrappers — don't distinguish between these. A system might report 85% confidence on a match, and that sounds solid. But our UQ layer might reveal that the uncertainty distribution around that 85% is enormous, meaning the number is statistically meaningless given the input quality.
An AI system that can't tell you how uncertain it is isn't a tool — it's a trap.
We use techniques like conformal prediction to guarantee that the system's uncertainty estimates fall within mathematically provable bounds. The technical details are in our full research paper, but the practical upshot is this: before the system takes any action, it can tell you whether its answer is trustworthy. And if it's not, it escalates to a human.
The Open-Set Problem Nobody Talks About

Here's something that still surprises me when I talk to enterprise buyers: almost none of them know the difference between closed-set and open-set recognition.
A closed-set system assumes the person being scanned is definitely in the database. Think unlocking your phone — the phone knows your face is enrolled. It just needs to verify it's you.
A retail security system is the opposite. The vast majority of people walking into a store are not in any criminal database. This is an open-set problem. And here's the catastrophic mismatch: most commercial facial recognition software is optimized for closed-set performance, because that's where the benchmarks look impressive.
What happens when you deploy a closed-set model in an open-set environment? It tries to find the "best match" for every single face, because it assumes a match must exist. This is almost certainly what generated the thousands of false positives at Rite Aid. The system wasn't malfunctioning. It was doing exactly what it was designed to do — in an environment it was never designed for.
Building for open-set means training your model not just to identify matches, but to accurately reject non-matches. To say "I don't know this person" with as much precision as it says "I recognize this person." This requires different loss functions, different evaluation metrics, and a fundamentally different design philosophy.
NIST — the National Institute of Standards and Technology — runs the Face Recognition Vendor Test (FRVT), which is the global gold standard for evaluating these systems. NIST measures the False Non-Match Rate at a fixed False Match Rate. For high-security applications, that false match threshold is set at one in a million. One in a million.
Rite Aid never benchmarked against NIST standards. Neither, apparently, did the system that identified Harvey Murphy.
Model Disgorgement: The Nuclear Option
There's a detail in the FTC's Rite Aid settlement that should terrify every company building AI on questionable data.
Rite Aid wasn't just told to stop using facial recognition. They were ordered to delete all the biometric data they'd collected and destroy any AI models or algorithms derived from that data. The FTC called it "model disgorgement" — forcing a company to essentially un-learn everything its models had absorbed from non-compliant data.
Think about what that means operationally. Years of data collection. Models trained and refined over time. Institutional knowledge embedded in neural network weights. All of it — gone. Not because the models stopped working, but because the data they were built on was obtained without proper safeguards.
This is the new regulatory reality. If your training data is tainted — collected without consent, biased in its composition, or obtained in violation of privacy laws — the models built on that data are tainted too. And regulators now have the tools to make you destroy them.
Most wrapper architectures can't even perform surgical data removal. They don't have the provenance tracking to know which data influenced which model weights. Deep AI systems, built with data lineage in mind, can. It's not a feature you appreciate until the FTC comes knocking.
Why "Human-in-the-Loop" Isn't Just a Checkbox
People always ask me whether the solution is simply to put a human reviewer in front of every AI decision. The answer is yes — but with a massive caveat. A badly designed human review process is worse than no review at all, because it creates the illusion of oversight.
At Rite Aid, there were humans in the loop. Store employees received automated alerts and were told to act on them. But they had no training on false positive rates. No interface showing them the original image quality. No protocol for questioning the system's output. They were, functionally, rubber stamps for an algorithm.
We design human-in-the-loop (HITL) systems with confidence thresholds that route decisions appropriately. Below 70% confidence? Auto-reject — don't waste a human's time on obvious noise. Between 70% and 95%? Flag for human review, with the original source imagery displayed alongside the match, so the reviewer can make an informed judgment. Above 95% on a low-consequence task? Auto-approve, but log everything.
The key is that the human reviewer must have enough context to actually override the machine. If all they see is "MATCH — 87% confidence," they'll defer to the number every time. If they see the grainy CCTV frame next to the gallery photo and can spot the obvious differences — different ear shape, different jawline, a 20-year age gap — they become a genuine safety net instead of a decorative one.
I had an argument with a client's CTO about this. He wanted to minimize human review to keep costs down. I told him the cost of one Harvey Murphy lawsuit would exceed a decade of human reviewer salaries. He didn't like hearing it. He also didn't get sued.
The Regulatory Walls Are Closing In
The EU AI Act classifies biometric identification systems as high-risk by default. Mandatory conformity assessments. Detailed technical documentation. Effective human oversight — not the Rite Aid kind, the real kind. Certain uses, like scraping facial images from the internet for training data, are banned outright.
In the US, the NIST AI Risk Management Framework lays out four functions — Govern, Map, Measure, Manage — that together form the blueprint for responsible AI deployment. The FTC's action against Rite Aid was essentially an enforcement of these principles before they became formal law. The message is clear: if you can't explain how your AI works, can't measure its biases, and can't manage its failures, you will be held accountable.
I tell every board I advise the same thing: align with the EU AI Act's standards now, even if you only operate in the US. Domestic regulation is coming, and the companies that treated compliance as a future problem are going to find themselves in Rite Aid's position — scrambling to destroy models and rebuild from scratch under a consent decree.
The Bias Isn't in the Algorithm — It's in the Laziness
One thing that frustrates me about the public conversation around AI bias is the implication that bias is some mysterious, intractable property of artificial intelligence. It's not. It's the result of specific, identifiable engineering shortcuts.
You train a model on a dataset that's 80% light-skinned faces? It will perform worse on dark-skinned faces. You skip adversarial debiasing — the technique where you train a competing network to detect whether your model is using race or gender as a hidden feature? Your model will encode those biases invisibly. You deploy without testing across demographic groups using NIST's benchmark data? You won't even know the bias exists until someone gets hurt.
Algorithmic bias isn't a mystery. It's what happens when engineers optimize for speed instead of equity, and organizations optimize for cost instead of safety.
Every one of these problems has a known technical solution. Adversarial debiasing. Fairness constraints in the loss function. Multi-scale feature fusion to handle varying skin tones and lighting conditions. Presentation attack detection to catch spoofing attempts. These aren't theoretical — they're deployed in production systems today. Ours included.
The reason most companies don't implement them is the same reason Rite Aid didn't test their vendor's accuracy: it costs more, takes longer, and nobody forces you to do it. Until they do. And then it costs everything.
What I Actually Think About the Future of Enterprise AI
I've spent years building systems that are designed to doubt themselves before they act. That might sound like a strange thing for an AI company founder to say. Shouldn't I be selling confidence?
No. I'm selling calibrated confidence. There's a difference.
The companies that will survive the next decade of AI regulation and liability are the ones that build systems capable of saying "I don't know" with the same precision they say "I'm sure." That treat every automated output as a hypothesis to be validated, not a verdict to be executed. That architect for the worst case — the Harvey Murphy case — not the demo case.
Rite Aid lost its biometric capabilities for five years and had to destroy its models. Macy's and Sunglass Hut face a $10 million lawsuit and the kind of reputational damage that no PR firm can undo. These aren't cautionary tales from the early days of a risky technology. They're happening now, with systems that companies bought off the shelf and deployed without understanding.
The wrapper era of enterprise AI is ending. Not because wrappers don't work — they work fine for low-stakes tasks. But because the stakes keep rising, the regulations keep tightening, and the cost of a confident wrong answer keeps growing.
Harvey Murphy was in Sacramento. The algorithm said he was in Houston. And for ten days, the algorithm won.
That's not an AI problem. That's an architecture problem. And architecture is a choice.