We Built a Fake Review Detector That Worked Perfectly — Until Someone Ran It Through BypassGPT
The first thing that broke my confidence wasn't a fake review. It was a price list.
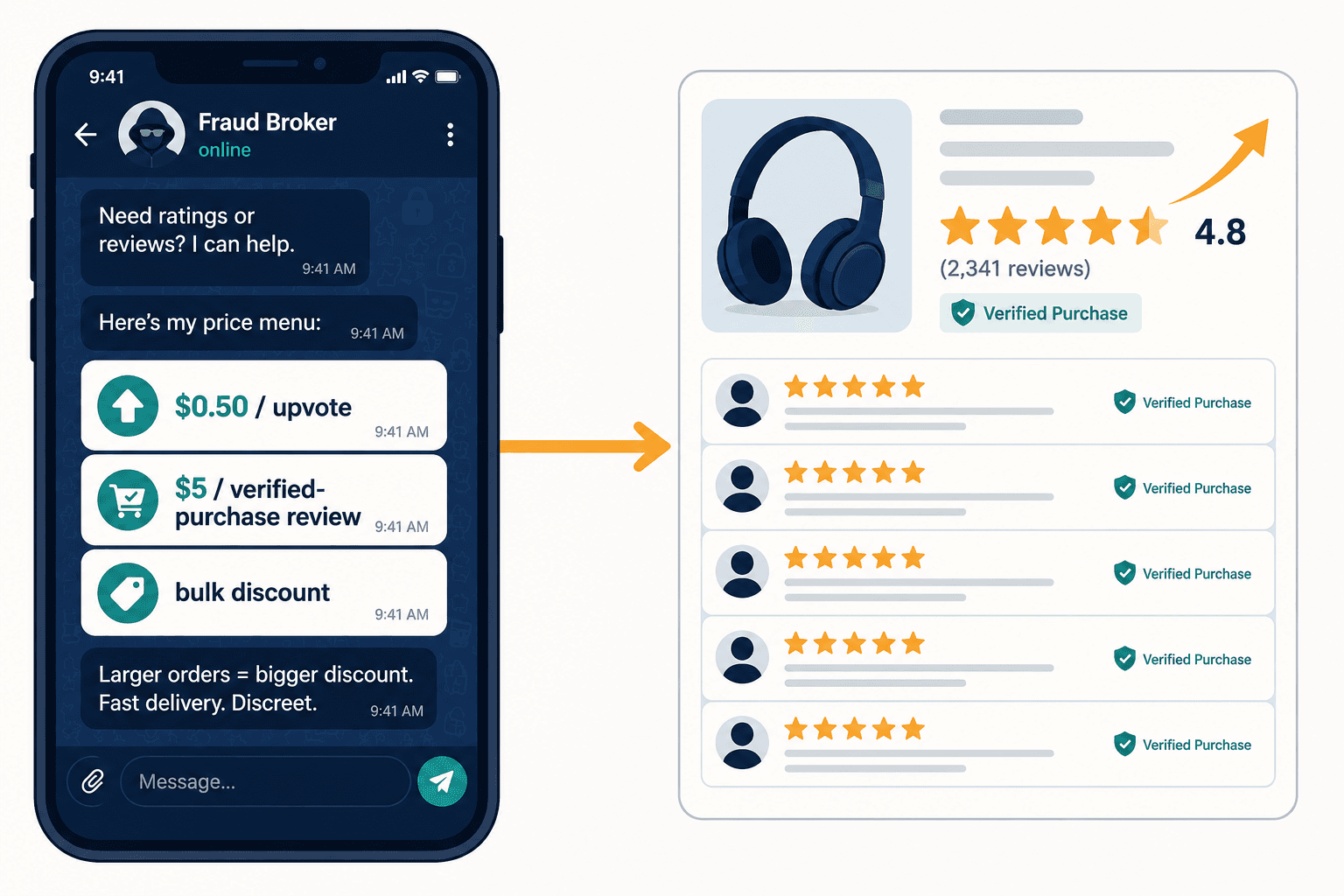
A broker on a Telegram channel — one of the open ones, 13,000-plus members, no password, no pretense — had posted a menu. Fifty cents an upvote. Five dollars for a review from an account with a "Verified Purchase" badge. Bulk discounts. The accounts on offer weren't freshly minted burner profiles a spam filter could catch in its sleep; they were two, three, four years old, with real purchase histories and the kind of irregular activity a human leaves behind. I had spent weeks assuming fake review detection was a hard machine-learning problem. Staring at that menu, I understood it was a hard machine-learning problem that the other side was funding better than most of the brands it targeted.
That was the moment I stopped thinking about fake reviews as bad text and started thinking about them as a coordinated economy. Everything we eventually built at Veriprajna — and everything I got wrong first — followed from that shift.
Fraud stopped being a quality problem the day it became a priced commodity. You cannot out-filter a market.
A 47-review attack that passes every tool you own
Let me describe what a modern attack actually looks like, because the gap between how people imagine fake reviews and how they really work is most of the reason existing tools fail.
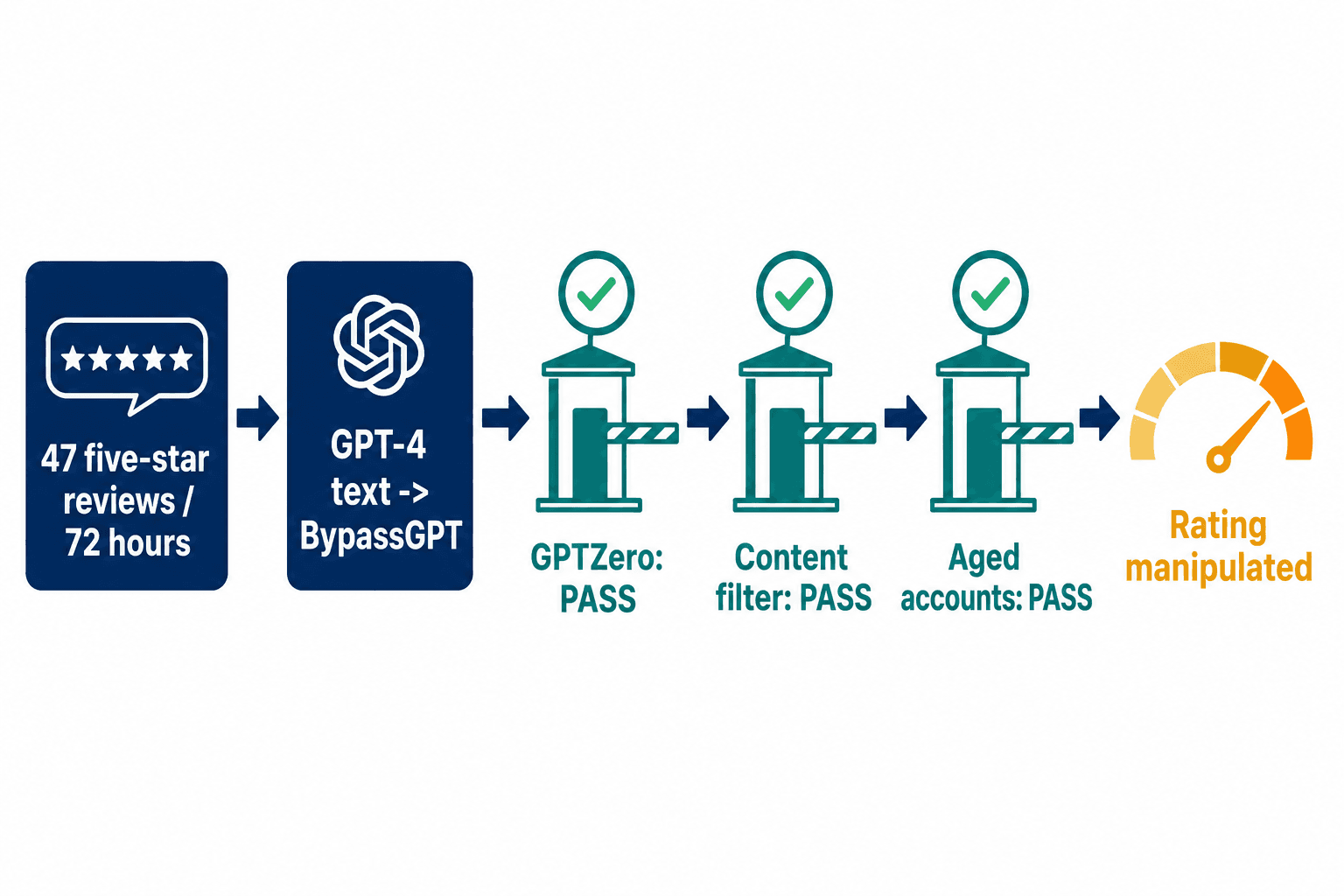
A competitor wants to bury your product. They hire a broker through one of those Telegram groups. The broker controls a stable of aged, compromised accounts and deploys them against a single listing. Over 72 hours, 47 five-star reviews land on the competing product — yours stays clean, theirs climbs. The review text was written by GPT-4, then passed through a tool like BypassGPT to defeat the perplexity-based detectors that look for "too smooth" machine writing. Each review name-drops a specific product feature scraped from the listing's own Q&A section. The posting times are staggered across three time zones so nothing clusters.
Every individual review looks legitimate. They clear the content filters on the major review platforms. They pass GPTZero. The accounts are old enough to dodge any "new account" heuristic. Your brand-protection team doesn't notice anything — until your numbers move, and they do: an extra fraudulent star can lift a competitor's demand by 38%, and fake negatives can cut a target's revenue by as much as a quarter, all while your average rating quietly absorbs the damage.
This isn't a thought experiment. Amazon filed its first joint lawsuit with the Better Business Bureau against the review broker ReviewServiceUSA.com in July 2024. Trustpilot removed 4.5 million fake reviews in 2024 — 7.4% of everything submitted, up from 6.1% the year before. Tripadvisor intercepted 2.7 million fraudulent submissions, some of them AI-generated property photos creating "ghost hotels" that travelers actually booked and showed up to find an empty lot. The scale is not marginal. Researchers estimate roughly 30% of online reviews are fake, costing U.S. businesses around $152 billion a year, according to the World Economic Forum.
So that's the problem I thought I understood. Here's where I got it wrong.
The detector that worked perfectly, then didn't
Our first version was a text classifier. It read review text and scored how likely it was machine-generated. This is the obvious thing to build, and I want to be honest: I backed it. It demoed beautifully. On our test set it caught AI-written reviews with the kind of accuracy that makes you start drafting the launch post in your head.
Then we ran it against reviews that had been through a humanizer.
There are more than 30 of these tools now — BypassGPT, Undetectable.ai, StealthWriter, Humanize AI, a dozen others. They take machine-generated text and rough it up just enough to break a detector: stripping the tell-tale commas, splicing in connecting words, swapping out the vocabulary that classifiers learn to associate with GPT output. Our accuracy didn't degrade gracefully. It fell off a cliff. The reviews we'd been catching at high confidence were now sailing through at "looks human."
I remember the argument that followed. Half the team wanted to keep tuning — more training data, adversarial examples, chase the humanizers. It's a reasonable instinct and it's a trap. I'd looked at the research: of more than 30 humanizer tools someone had tested, only 13 reliably produced text that fooled the best detectors. The best-in-class text classifier, Originality.ai, still catches most of them. But "most" is the wrong bar when an attacker can run a review through five humanizers and submit the one that scores cleanest. A text-only detector is in a footrace it has structurally already lost.
A single-signal detector isn't a weak detector. It's a detector you've told the attacker exactly how to beat.
The deeper problem was one I should have seen on the day I read that Telegram price list. Some of the most damaging fraud isn't AI-written at all. When a broker pays a network of real people to post — incentivized humans, the modern version of the old Mechanical Turk farm — the text is genuinely human. There is no linguistic tell to find, because there's no machine in the loop. A text classifier looking at a paid review from a real person sees nothing wrong, because at the level of language, nothing is. And the asymmetry is widening from both ends — by early 2026, 23% of review writers admitted using AI at least sometimes, while only 31% of consumers were confident they could spot an AI-written review.
That's when we threw the text model out as the centerpiece. Not out entirely — it's still a signal — but it stopped being the signal.
What Actually Catches a Coordinated Campaign?
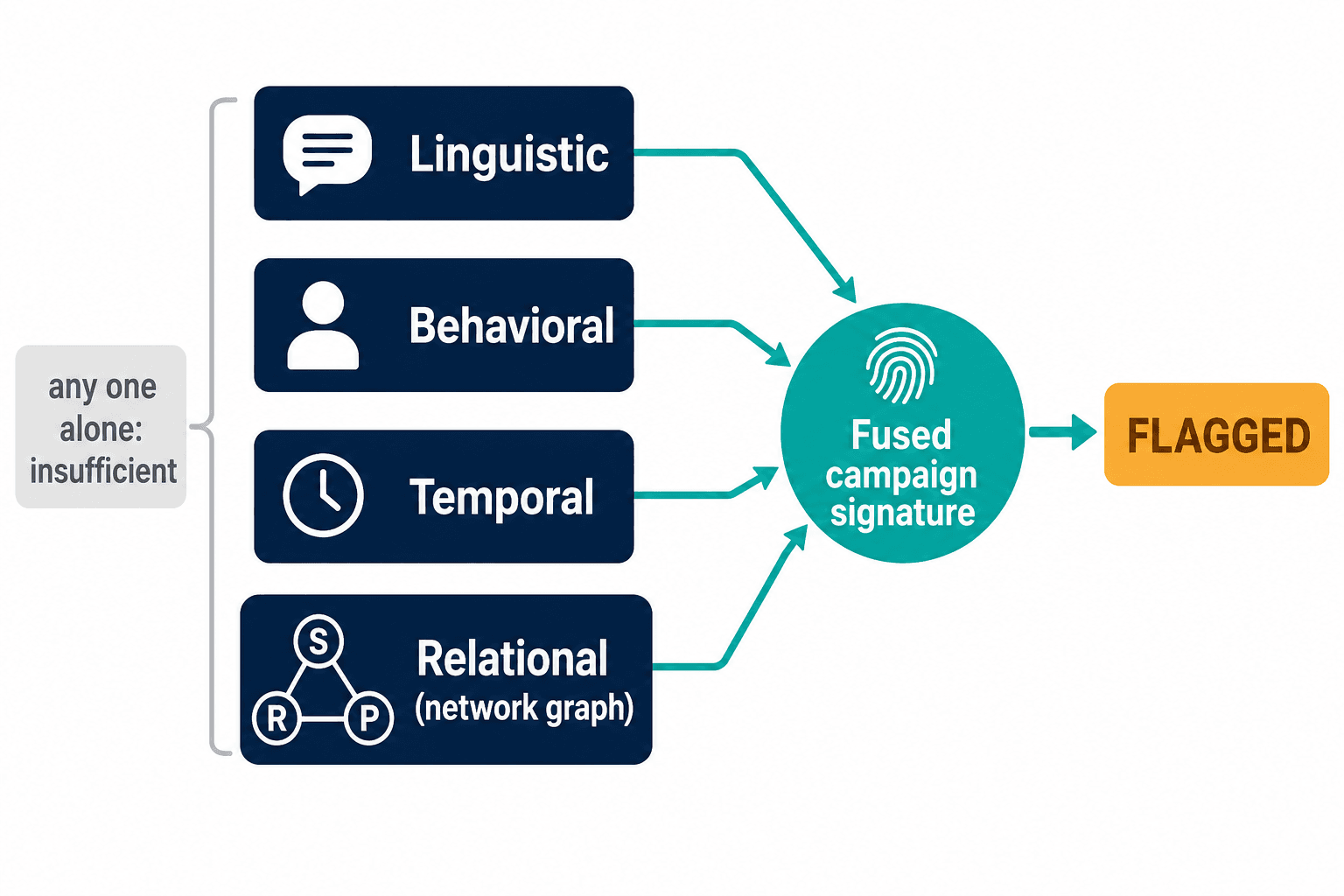
The reframe that saved the project: an individual fake review is nearly impossible to catch, but a campaign leaves fingerprints the individual reviews don't.
Those 47 reviews share something even when each one is clean. They arrive in a burst. They reference the same scraped feature. The accounts that posted them, when you map the relationships between sellers, reviewers, and products, light up as a cluster that doesn't occur naturally — the same set of accounts reviewing the same narrow set of products in the same window. This is why the platforms that take fraud seriously moved to graph methods: Amazon's stack runs deep graph neural networks over the seller-reviewer-product network precisely because the network structure betrays coordination that the text never will. We built in the same direction — fusing behavioral signals (how an account acts over time), temporal signals (when reviews arrive relative to each other), and relational signals (who's connected to whom) on top of the linguistic layer.
No single one of those is sufficient. A burst can be a genuine viral moment. A cluster can be a real fan community. But the combination — a burst, of feature-scraping text, from a relationally suspicious cluster, with staggered timing engineered to look unstaggered — is the signature of a paid campaign, and it survives the humanizer because the humanizer only rewrites the words.
The same logic extends to images, which is the frontier nobody has solved cleanly. Ghost hotels and fabricated product shots are spreading because AI image generation got cheap — and for a hospitality brand the stakes are not abstract: McAfee put AI-driven travel scam losses at roughly $13 billion in 2025, about a thousand dollars a victim, much of it routed through listings that looked real until check-in. There's a content-provenance standard, C2PA, that cryptographically signs an image at capture — Samsung's Galaxy S25 became the first consumer phone to sign photos natively, and 2026 is genuinely a turning point for that ecosystem. But here's the operational catch I'd warn any brand about: platforms strip the metadata during image processing. The credential that proves a photo is real gets erased the moment it's uploaded to the marketplace where it matters most. Provenance is a real tool with a real hole in it for e-commerce, and pretending otherwise sells a brand false comfort.
Why didn't the platforms' tools solve this already?
This is the question I get most, and it's fair. Amazon spends more than $500 million a year and has 8,000 people working on fake reviews. It blocked over 275 million of them in 2024. Why would anyone need to build anything?
Because the platforms are fighting their war, not yours. Amazon protects Amazon — and even at that spend, 49% of U.S. consumers say they're confident they've seen fake reviews there. The review-management platforms have the same boundary drawn the other way. Bazaarvoice runs more than 1,000 fraud-detection rules across 2.3 billion shopping sessions a month, and it's genuinely good at it — within its own network. A fake review about your product sitting on Amazon is simply invisible to Bazaarvoice. Worse, syndication cuts both ways: a fake review that clears Bazaarvoice's ingestion can propagate across 50-plus retailer sites within 48 hours, which means remediation has to happen at the source node, not whack-a-mole on every downstream listing.
The text detectors have their own ceiling — they're a single signal, as I learned the hard way. The audit services like The Transparency Company do daily sweeps and file disputes, but they're tuned to known patterns and struggle against the custom broker tactics that adapt specifically to evade them. And the one tool consumers actually trusted to check this for them, Fakespot, shut down in July 2025 after nine years — Mozilla couldn't find a sustainable model. The safety net got smaller right as the attacks got better.
No vendor watches the whole field where your brand lives. They each guard their own yard, and the fraud lives in the street between them.
That gap — cross-platform, brand-side, signal-fused — is the thing we set out to occupy. Not to replace the platforms, but to give a brand one view across Amazon, Google, Yelp, Trustpilot, and Tripadvisor at once, with detection built around its product category instead of a generic ruleset. That's what the review integrity and synthetic-content detection system we built is for.
The customer who didn't want a cleaner review page
I had been pitching detection accuracy — recall, precision, how many fakes we'd catch. Then I got on a call with a brand-protection lead who reframed the entire product for me in about two minutes.
She didn't lead with accuracy. She asked what we could hand the FTC.
In October 2024 the FTC's Consumer Reviews and Testimonials Rule took effect, and it did something subtler than "fake reviews are banned." It created a "should have known" standard. If fake reviews are sitting on your listings and you don't have a reasonable process to detect and respond to them, the absence of a detection system is itself the violation. The penalty is $53,088 per violation, inflation-adjusted as of January 2025, and each day a violation continues counts separately. A coordinated campaign of 100 fake reviews, left unaddressed, is $5.3 million in exposure. The FTC sent its first warning letters under the rule to 10 companies in December 2025, so this stopped being theoretical about a year ago.
And it isn't only U.S. brands. The UK's Competition and Markets Authority opened five investigations in March 2026 under the new Digital Markets, Competition and Consumers Act, with penalties up to 10% of global turnover. The EU AI Act's Article 50, requiring machine-readable disclosure of AI-generated content, takes effect in August 2026. California's SB 942 added AI-content disclosure requirements in January 2026. The regulatory floor moved under every brand at once.
What that lead taught me is that detection is necessary but not sufficient. The deliverable a regulated brand actually needs is evidence of due diligence — an audit log showing that a reasonable detection-and-response process existed and ran, whatever any single fake review slipped through. You can't buy that off a shelf today; the platforms won't give you their detection data, and the point solutions don't generate compliance-grade records. So we built the system to produce that trail as a first-class output, not an afterthought. The defensible artifact under a "should have known" rule isn't a spotless review page — it's the documented proof you were looking.
Should a Brand Build This, Buy It, or Wait for the Platforms?
People ask me whether they can just wait for the platforms to catch up. My honest answer: the platforms are running as fast as they can on a problem they've defined as protecting themselves, and the regulatory clock is now running on you, separately. Waiting is a position, and after October 2024 it's a position with a dollar figure attached.
The second question is usually whether they can build this internally. You can — but look at what serious internal programs cost. Amazon's half-a-billion-dollar, 8,000-person operation is the benchmark for what it takes to do this at scale, and most brands aren't standing that up to watch their own listings across five marketplaces. The realistic options are a custom system tuned to your category or a stack of partial tools you stitch together and hope overlap. The big consultancies will sell you the latter wrapped in a framework, six to twelve months before any technology actually runs.
The third thing they raise is the arms race — if humanizers keep improving, isn't any detector temporary? It's the right worry, and it's exactly why the answer can't be a text classifier. A multi-signal system degrades slowly when one signal is attacked, because the attacker has to defeat behavior, timing, and network structure simultaneously, not just rewrite words. You don't win an arms race by having a better gun. You win it by making the attack cost more than the payoff. When fraud is priced at fifty cents an upvote, raising the cost of a successful campaign is the whole game.
The Telegram price list taught me something before any model did, and it's the thing I keep returning to. The other side treats this as a business with a P&L. For years brands treated it as a nuisance to be filtered. The brands that come out of this decade with their ratings intact will be the ones who started treating their review ecosystem the way the attackers already do — as contested infrastructure worth defending on purpose. That's the shift I'd make first, and it's the one the system we built assumes from the first line of code.
A fake review you never catch costs you a sale. A detection system you never built, after October 2024, costs you $53,088 a day. Those are not the same problem, and the second one is the one most brands haven't priced yet.