I Gave a Government Chatbot the Exact Law. It Still Told Landlords to Break It.
In March 2024, a reporter at The Markup asked New York City's official chatbot a simple question: can a landlord refuse a tenant with a Section 8 voucher?
The bot — MyCity, live on a .gov domain, trained on more than 2,000 city web pages, running on Microsoft's Azure AI — said yes. Landlords don't need to accept the vouchers, it explained, helpfully.
That answer is illegal. NYC's Human Rights Law has prohibited source-of-income discrimination since 2008, with fines that reach $250,000. The chatbot didn't hedge, didn't disclaim, didn't say "consult a lawyer." It gave a confident, fluent, wrong answer, and it did so wearing the seal of the City of New York.
I spent a Saturday that spring reading The Markup's investigation with the actual NYC Administrative Code open in another tab, comparing what the bot said to what the statute said, line by line. That's where the idea behind government AI that cites the law instead of inventing it started for me — not in a strategy deck, but in the gap between a screenshot and a statute. The bot wasn't confused. It was working exactly as designed. And the design was the problem.
The Chatbot That Told New Yorkers to Break Four Different Laws
MyCity didn't get one thing wrong. The Markup documented a pattern across the basic machinery of city life.
It told business owners they could take a cut of their workers' tips — illegal under the Fair Labor Standards Act and New York Labor Law, the kind of thing that ends in wage-theft suits and liquidated damages. It told stores they could go cashless and refuse paper money, which NYC's Administrative Code § 20-840 bans specifically to protect unbanked residents. It told landlords they could lock tenants out, which is a criminal offense after thirty days of occupancy.
Every answer was illegal. Every answer carried the imprimatur of the city.
The city's response was to add disclaimers. But the bot was still cheerfully overriding them in its own text — at one point telling a user, "Yes, you can use this bot for professional business advice." Incoming Mayor Zohran Mamdani later called the tool "functionally unusable" and moved to terminate it. By then the program had cost the city roughly $500,000, a line item that looks especially grim against a $12 billion budget gap.
Here's the part that kept me up. No one set out to build a lawbreaking machine. A competent team trained a reasonable model on real city data and shipped it. The failure was baked into the architecture they chose, and almost every government deploying a chatbot today is choosing the same one.
Why Does a Language Model Default to Breaking the Law?
You have to understand what a large language model actually optimizes for. It's a probability engine. Ask it a question and it produces the most statistically plausible continuation — the answer that sounds like the kind of answer that usually follows that kind of question.
Now think about what's in its training data. When a landlord asks "Can I refuse this tenant?", the dominant pattern across the entire internet is general contract law: property owners get to choose who they rent to. That's true almost everywhere. The specific NYC provision banning source-of-income discrimination is a narrow local exception, a faint signal drowned out by the broad one. The model reaches for the pattern it has seen ten thousand times, not the statute that applies on this particular block.
Then reinforcement learning makes it worse. Modern chatbots are tuned to be helpful, which in practice means agreeable — they lean toward giving the user what they seem to want. A landlord asking how to refuse a tenant reads, to the model, as "help me refuse this tenant." So it helps. It says yes.
A government chatbot has to be willing to be unhelpful to what you want in order to be honest about what the law says. That instinct is the exact opposite of what these models are trained to have.
That's the trap. The qualities that make a consumer chatbot delightful — fluency, agreeableness, the confidence to always have an answer — are the qualities that make a government legal chatbot dangerous.
Why Didn't RAG Fix This?
For about a week, I was sure I knew the answer, and I was wrong in a way that taught me the whole problem.
The obvious fix is retrieval-augmented generation — RAG. Instead of letting the model answer from memory, you retrieve the actual relevant documents first and hand them to the model as context. Give it the real statute, the thinking goes, and it'll stop making things up. We built a pilot to prove it.
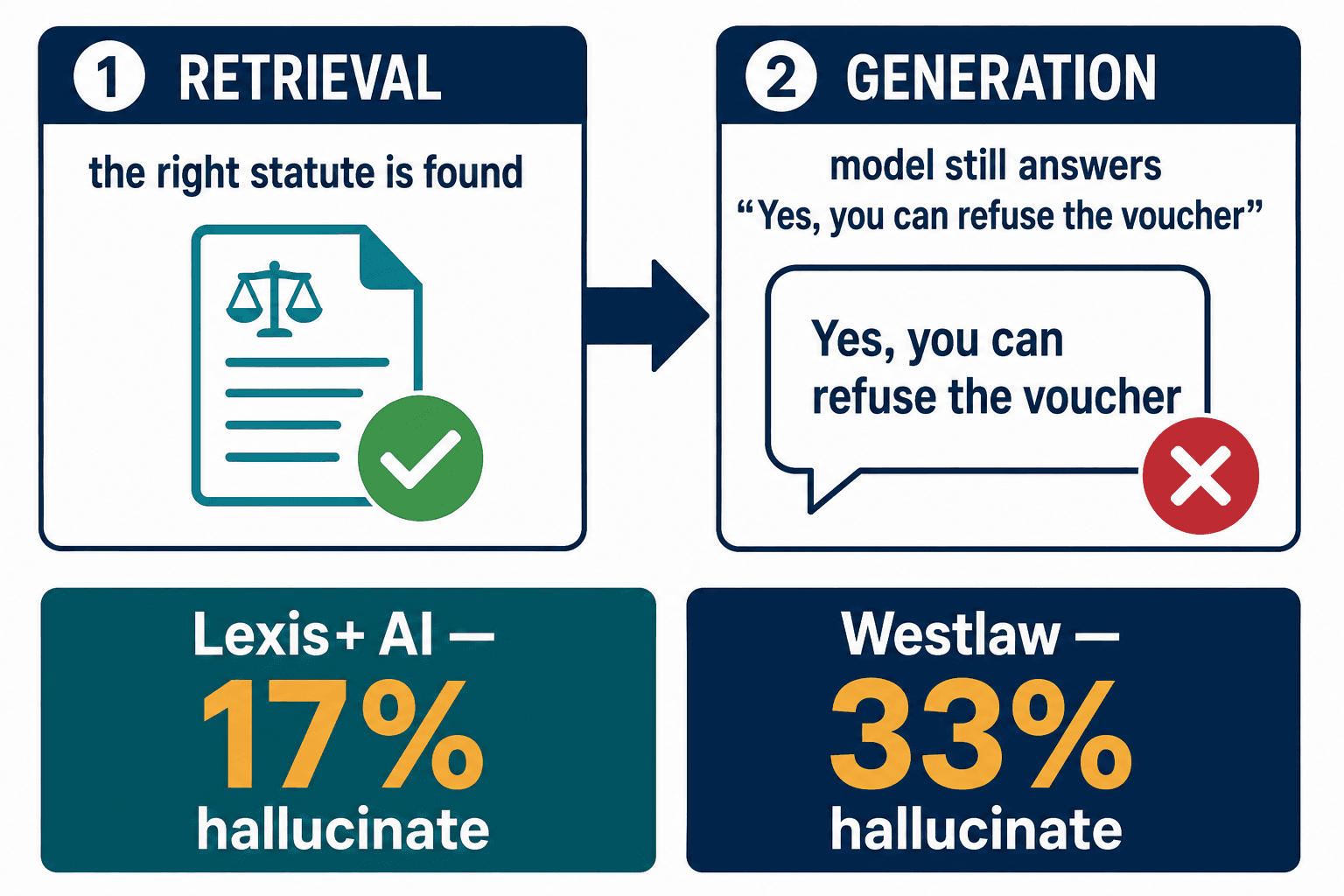
It retrieved beautifully. I'd ask the Section 8 question and watch the system pull the exact source-of-income provision into context — the right law, sitting right there in the prompt. And then the model would read it and still answer "yes, you can refuse the voucher." I remember staring at that, because it was worse than I expected. The retrieval worked. The reasoning didn't. The model had the correct statute in front of it and chose its training prior anyway, or misread the provision, or stitched together a plausible answer from the wrong combination of retrieved passages.
That's not a bug we'd introduced. It's the documented state of the art. Stanford researchers tested the commercial legal AI tools built for exactly this — retrieval-augmented, professionally engineered — and the best one, LexisNexis's Lexis+ AI, still hallucinated 17% of the time. Westlaw's AI-Assisted Research hit 33%. These are tools sold to attorneys for hundreds of dollars a month, and one in five to one in three answers is fabricated.
Retrieval gets the right document into the room. It does nothing to stop the model from ignoring it.
So I had to throw out the assumption I'd started with. RAG isn't the architecture. RAG is one component, and on its own it moves the failure from "the model doesn't know the law" to "the model knows the law and contradicts it" — which, on a government domain, is arguably the more dangerous failure, because now there's a citation right next to the wrong answer making it look authoritative.
The Liability Nobody Reads the Fine Print On
A consumer chatbot that's wrong 17% of the time annoys people. A government one accumulates legal exposure with every answer.
There's a doctrine most technologists have never heard of that matters enormously here. Governments are generally shielded from lawsuits for "discretionary" functions — the judgment calls of governing. But when a government provides specific, actionable advice to a citizen, courts treat that as a proprietary function, the same as a private consultant would perform. Proprietary functions don't get sovereign immunity. So when MyCity told a business owner he could pocket his employees' tips, the city was, in legal effect, acting as an unlicensed advisor giving malpractice-grade bad advice — without the immunity it would have had for an actual government decision.
And the law is racing to make this explicit. New York's Senate Bill S7263, which reached the Senate floor on February 26, 2026, would prohibit chatbots from giving substantive professional advice and create a private right of action — meaning a citizen harmed by a chatbot's advice can sue for actual damages plus attorney fees. Across the country, legislative trackers counted 78 chatbot-safety bills in 27 states heading into 2026. For any government serving residents in Europe, the EU AI Act classifies citizen-facing public-service AI as high-risk, with penalties reaching €15 million or 3% of worldwide turnover as obligations take effect in August 2026.
When an advisor told me early on to just fine-tune GPT and ship it for a government pilot, this is the conversation we had. "Usually right" is a fine standard for a movie-recommendation engine. On a .gov domain, in this regulatory environment, a system that's confidently wrong a sixth of the time isn't a product feature to iterate on. It's a private right of action waiting for a plaintiff.
The Part Everyone Underestimates: the Code Itself Is a Mess
Before any of the model questions even matter, there's a problem that doesn't show up in demos and quietly sinks real deployments: the law is not in a database.
I learned this viscerally the first time I sat with an actual municipal code — a PDF with chapter amendments hand-numbered in the margins, because the authoritative version of a city ordinance is a document a clerk has been editing for decades. Municipal codes live in dozens of incompatible formats across the country — PDFs, legacy HTML, proprietary publishing systems — and within a single city they're maintained asynchronously by departments that don't coordinate. Zoning updates on one schedule, the health code on another. The "single source of truth" is a fiction.
You cannot build trustworthy government AI on top of a legal corpus you haven't first reconstructed into something a machine can reason over reliably. "Ingest the code" is a quarter of data archaeology before the model ever sees a token.
This is also why the existing market doesn't fit. Microsoft Azure Government, AWS GovCloud, and Google's public-sector cloud give you authorized infrastructure and a general-purpose model — but Azure is what powered MyCity. The hallucination problem lives above the platform layer; the cloud doesn't touch it. The strong legal AI tools, Thomson Reuters' CoCounsel and Lexis+ AI, are built for attorneys at law-firm prices, not for a resident asking a question at 11 p.m. The big integrators — Deloitte, with billions committed to generative AI, and Accenture Federal, with billions in AI bookings — implement those vendor platforms; they don't build custom constrained-decoding architectures. And the promising municipal-code AI startups are exactly that: promising, unproven at scale, without a government procurement track record. There's a gap in the middle, and the gap is where citizens get hurt.
What Finally Worked: Make the System Earn the Right to Speak
The reframe that changed everything was deciding the system's default state is silence, not an answer.
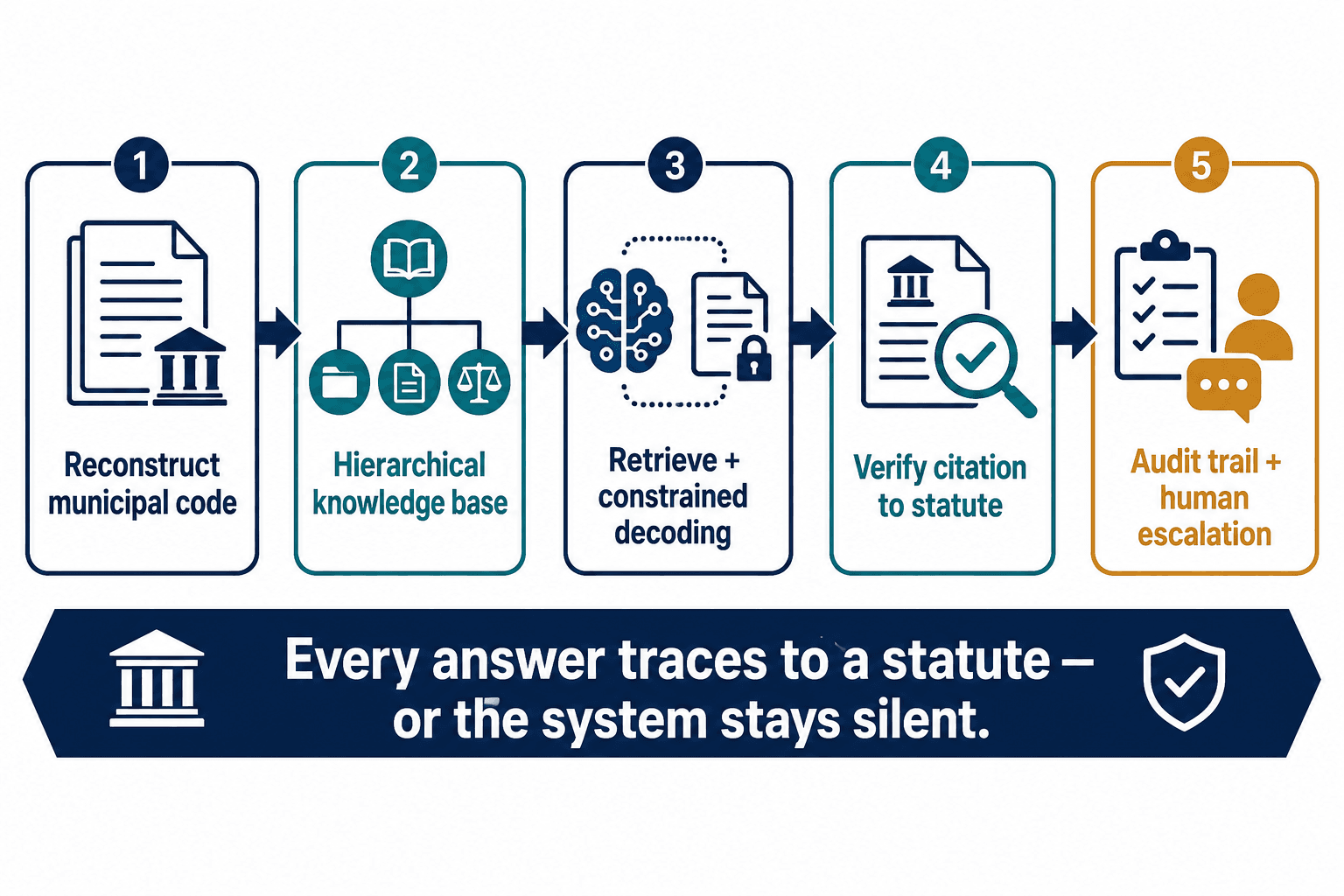
Instead of asking the model to be more accurate, we built it so that it physically cannot emit a legal claim unless that claim is bound to a specific, retrieved statutory provision. The generation step is constrained: when the system produces a sentence about what the law allows, that sentence has to carry a traceable citation to the exact code section it came from, verified against the source after generation. If the model wants to say "you may refuse a voucher" and there's no provision that supports it — or worse, a provision that contradicts it — the claim doesn't pass. The system says it can't answer that and routes the person to a human.
That's the whole philosophy of what we built at Veriprajna, and you can see the full architecture at veriprajna.com/solutions/government-municipal-ai: every response traces to a specific statute, or the system stays quiet. We'd rather it answer fewer questions and be unable to break the law than answer everything and occasionally commit the city to a quarter-million-dollar discrimination penalty.
The order of operations matters. First, reconstruct the messy municipal corpus into a structured, hierarchical knowledge base that knows which provisions override which — a non-trivial problem precisely because those provisions are amended on uncoordinated departmental schedules, so the override graph itself keeps drifting. Then retrieve against it. Then — and this is the step everyone skips — constrain the generation so the output is mechanically tethered to what was retrieved, with a verification pass that rejects any claim that doesn't hold. Then keep an audit trail, so when a regulator or a plaintiff's lawyer asks why the system said what it said, there's a record pointing at a statute rather than a shrug about model weights.
A useful side effect: a system that can show its citation for every answer is a system you can actually defend. The audit trail isn't compliance theater. It's the difference between "the AI said it" and "here is the § the answer came from."
"But Doesn't That Make It Less Useful?"
People ask me this constantly, and it's the right question. Yes — a citation-enforced system answers fewer questions than MyCity did. It will sometimes say "I can't advise on that" where a chattier bot would have happily made something up. That feels like a downgrade until you remember that every one of MyCity's extra answers was a liability, not a service.
The other thing I hear is about the procurement clock, and it's the most underrated risk in the whole space. Government AI doesn't live or die on model quality; it lives or dies on getting through authorization. FedRAMP and StateRAMP authorization-to-operate processes run 12 to 18 months, and most AI startups don't survive the ATO binder long enough to deploy. Building for government means designing for that reality from day one — the access controls, the data-separation guarantees, the audit infrastructure — not bolting them on after a pilot. A model that's brilliant in a demo and can't clear authorization never serves a single citizen.
And then there's the question of whether this is even worth it given that the federal government has signaled it might preempt the patchwork of state AI laws. Maybe it will. But a city doesn't get to gamble its residents' tip income and housing rights on what a future executive order does. The advice MyCity gave was illegal under laws that have nothing to do with AI regulation — labor law, housing law, consumer protection law that predate ChatGPT by decades. No preemption fixes that.
The thing I keep coming back to is that screenshot from The Markup: the chatbot's confident "yes" next to the statute that says no. A human clerk who didn't know an answer would have said "let me check" or "you should ask a lawyer." We built machines that never say that, then put them on government websites and acted surprised when they advised people into lawsuits.
A government's job, when a resident asks what the law allows, is to be right or to be honest about not knowing. Those are the only two acceptable outputs. A system that produces a fluent, authoritative third option — confidently wrong — has no business carrying a city's seal. The fix was never a better-sounding model. It was building one that knows when to keep its mouth shut — which is the whole premise of what we built for government and municipal AI.