73,000 Smart Meters Went Dark Overnight — And the Firmware Had Passed Every Lab Test
In November 2024, a utility in Plano, Texas pushed a routine firmware update to 88,000 water meters. The update was supposed to fix premature battery drain — a good-faith repair of a known problem. In the lab, it worked. In the field, 73,000 meters went dark and never came back.
I keep coming back to that number because of what it implies. This wasn't a hack, a storm, or a manufacturing defect. It was a software update that had been tested and approved, behaving exactly as designed — and it still bricked 83% of a fleet. That gap between "passed the lab" and "killed the field" is the whole problem in smart meter AI, and it's why we built an AMI predictive maintenance system at Veriprajna that watches the signals an analytics dashboard was never built to see.
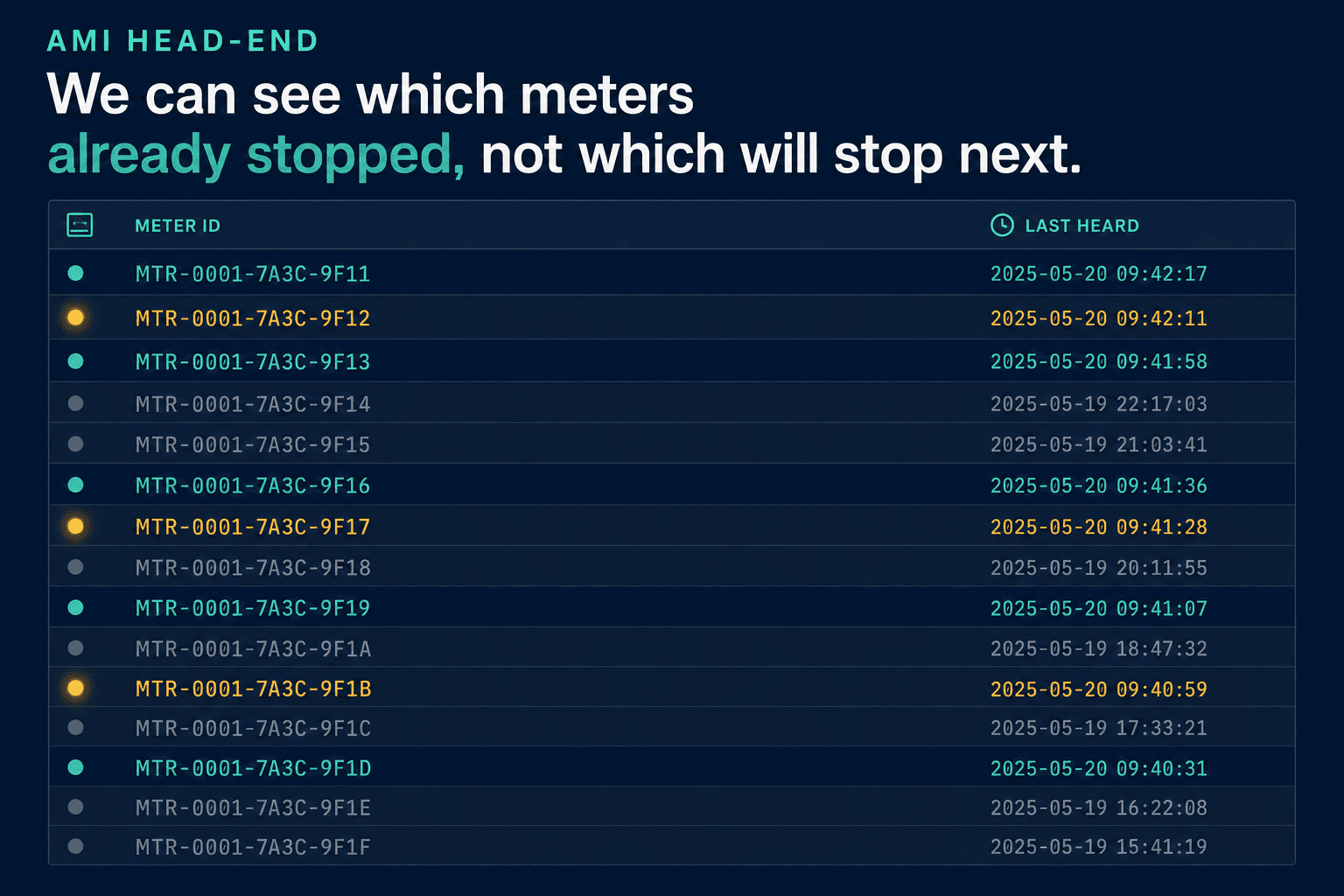
The first time I sat with a municipal utility's operations lead and looked at their AMI head-end — the system that collects readings from every meter — I expected a control room. What I got was a spreadsheet. Last-heard timestamps, one row per meter, and a slow scroll of cells going stale. He could tell me, precisely, which meters had stopped talking. He could not tell me which ones would stop next. That asymmetry — perfect hindsight, zero foresight — is the entire market.
Why Does Firmware That Passes the Lab Brick the Field?
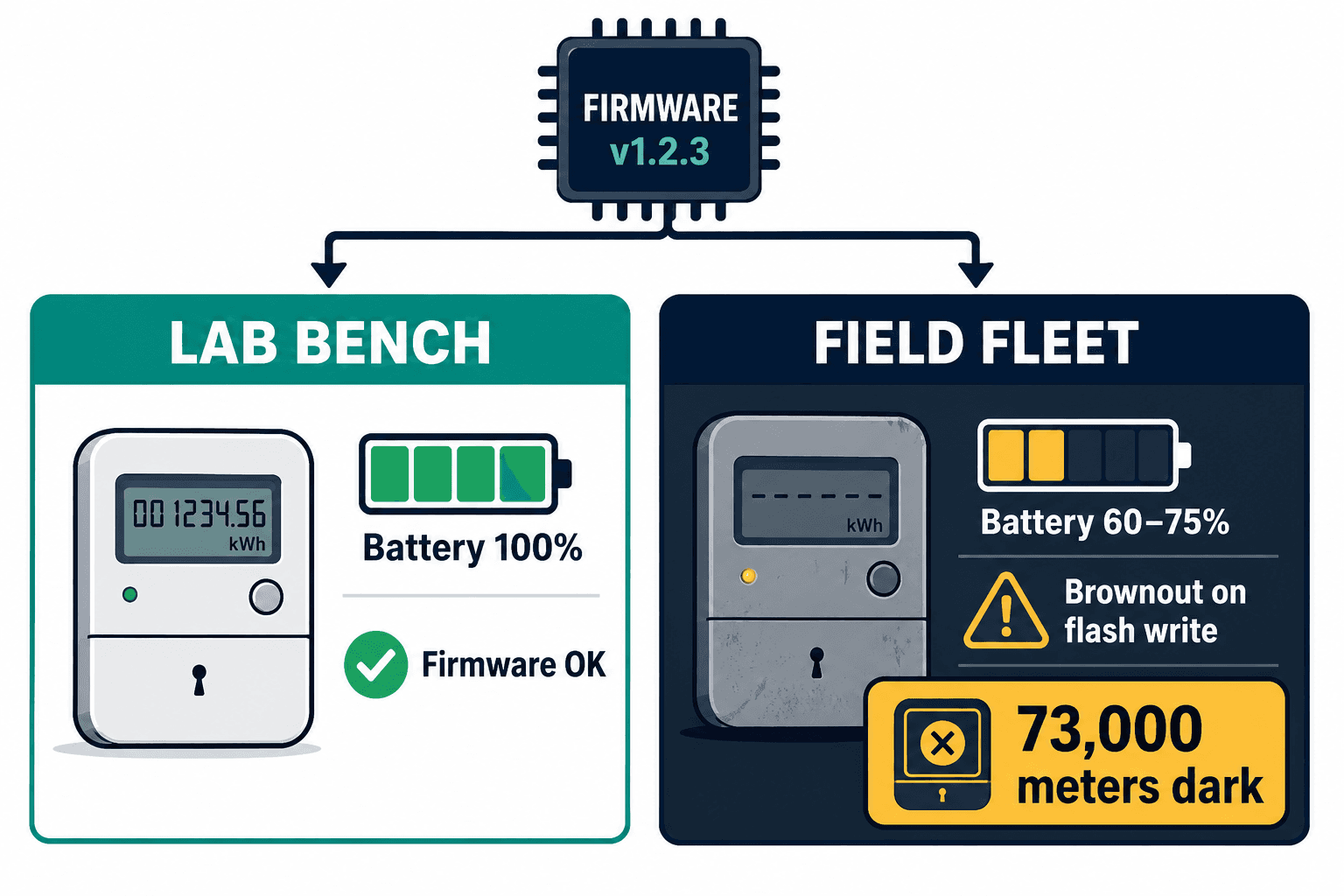
Here is what actually happened in Plano, and it's the single most useful story in this domain.
The firmware was tested against meters with fresh batteries and a strong radio signal — a clean bench. But the deployed fleet was four to five years old, and most of those batteries were sitting at 60 to 75% of their original capacity. The updated power-management routines drew slightly more current during the initial flash write. On a new battery, irrelevant. On a degraded one, that extra draw was enough to trip the brownout protection. The transmission modules reset, lost their network registration, and never recovered.
The firmware didn't fail. It met spec. The fleet had simply aged out from under the test bench, and nobody was modeling that.
That sentence is the thesis of everything we build. The defect wasn't in the code. It was in the assumption that a lab meter and a field meter are the same machine. They aren't, and the difference compounds silently for years before anyone pushes the button that exposes it.
These failures cluster. The same vendor's firmware has produced similar incidents in Minneapolis, Toronto, and New York. Toronto Hydro found roughly 470,000 transmitters degrading early and spent $5.6 million on the first round of remediation alone. Memphis ran an 8% systemic failure rate and stood up a $9 million repair fund. In the UK, around one in five smart meters don't work as they should; more than 600,000 have been reconnected since July 2024. None of these utilities lacked an analytics platform. They all had one. The platform just wasn't watching the thing that broke.
The Mistake I Backed Far Too Long
I want to be honest about the version of this we got wrong, because it's the part most people skip.
When we started, the obvious move was anomaly detection. A meter that's about to fail should look weird in its data — consumption readings drifting, gaps in reporting, odd patterns. So we built a model that watched the consumption stream and flagged anomalies. It was clean. It demoed beautifully. I defended it in room after room.
Then we ran it against a real degradation wave on a pilot fleet, and it sat there green while meters quietly went bad underneath it. I remember the specific feeling of watching the dashboard stay calm and being certain the model was broken. The model wasn't broken. I had pointed it at the wrong signal.
Consumption-anomaly detection is exactly what the existing Meter Data Management Systems already do. Oracle shipped AI-powered anomaly detection for its utilities platform in June 2025; SAP is an IDC MarketScape leader in the category. These tools are good at what they do — they catch a meter that's reporting strange numbers. The problem is that a meter heading toward firmware death doesn't report strange numbers. It reports perfectly normal numbers, right up until it reports nothing. We had rebuilt the thing that already existed and re-inherited its blind spot.
A failing meter doesn't look sick in its consumption data. It looks healthy, then it's gone. The signal you need lives somewhere the billing stream can't see.
What the MDMS Can't See: Two Signals That Actually Predict Failure
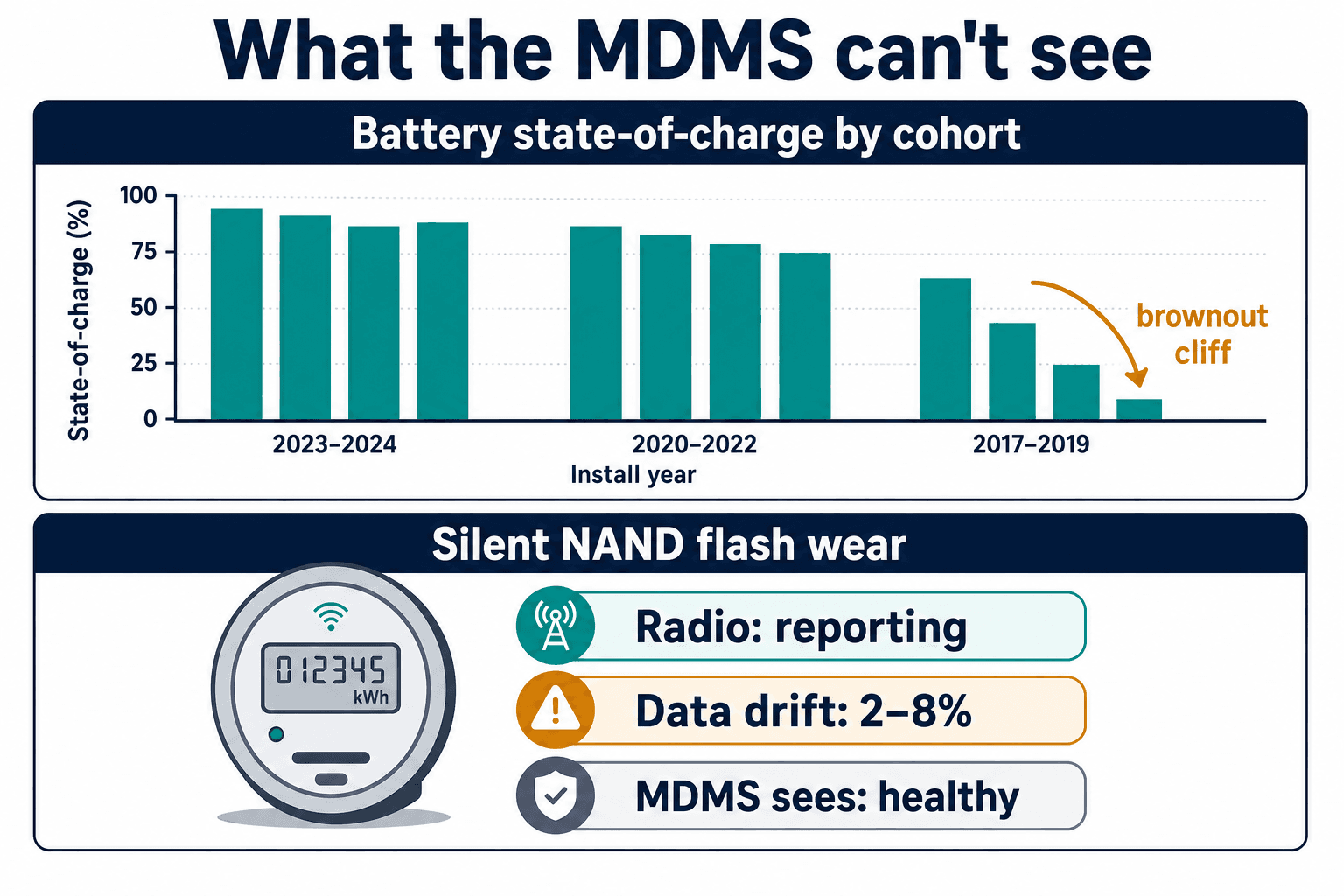
The turn came when we stopped asking "is this reading anomalous?" and started asking "what physically wears out in a meter, and can we measure it before it breaks?"
Two answers mattered.
The first is battery state of charge, modeled by deployment cohort rather than as a fleet average. The Plano lesson is that a firmware push is only dangerous against a particular distribution of battery health — and that distribution is knowable. If you bin every endpoint by install date and build state-of-charge histograms per cohort, you can see the brownout cliff coming before you flash anything. We started staging firmware against the actual age-and-capacity profile of the fleet, not a bench full of new units.
The second is silent NAND flash wear, and this one genuinely changed how I think about the whole category. Smart meters log data to flash memory — every reading, every event, at 15-minute intervals for demand response. Every write physically wears the cells. Manufacturers spec 20-year lifespans, but high-frequency logging burns through write cycles far faster than those projections assumed. And here's the insidious part: as the flash degrades, stored consumption readings drift by 2 to 8% while the meter keeps reporting normally. The radio still talks. The MDMS shows a healthy, communicating endpoint. Meanwhile the numbers are quietly wrong, billing disputes pile up, and public trust erodes — and by the time the meter goes fully silent, the flash is too degraded to even accept a corrective firmware fix. That unit needs a truck and a replacement at $650 to $1,400 a pop.
So the dashboard's "meter reporting" column and its "data quality" column can disagree for months, and almost nobody reads the second one. We made disagreement between those two the loudest alarm in the system.
"Oracle Already Does This. Why Are You Building It?"
An advisor I respect put it bluntly early on: the analytics space is crowded, the incumbents are serious, why build?
It's a fair question, and the honest answer is that the incumbents are crowded around a different problem. Itron's Distributed Intelligence platform is genuinely impressive — 16 million-plus enabled meters, 100 million-plus endpoints under management, a March 2026 partnership with NVIDIA to run AI at the grid edge. Landis+Gyr's Revelo, with a Sense collaboration, does appliance-level load disaggregation at 1 megahertz. Sensus launched Evolve in early 2026 to reposition meters as active grid sensors. The whole industry, DistribuTECH's 2026 theme made official, is moving "from AMI to AI."
But every one of those analytics stacks works only with that vendor's own endpoints. Itron's intelligence sees Itron meters. Landis+Gyr's sees Landis+Gyr. Real utilities run mixed fleets, accreted over a decade of procurement cycles — some Aclara, some Itron, some Sensus — and no single vendor's analytics spans them. And none of them, proprietary or not, offers pre-deployment firmware simulation against your specific aged fleet. The gap that bricked Plano is, structurally, unowned.
The incumbents will tell you a meter is reporting. The OT security tools will tell you it's running vulnerable firmware. Neither will tell you it's three months from a hardware death.
The security vendors are worth naming here, because people assume they cover this. Claroty, Nozomi, Armis — they do excellent asset discovery, right down to the firmware version on each endpoint, and they understand the industrial protocols. But they're built to find the meter running an exploitable firmware build, not the meter whose battery cohort can't survive the next flash write. Maintenance and security look at the same device and ask different questions. We needed the maintenance question, and it wasn't being asked.
The Bench Where Firmware Goes to Fail on Purpose
The piece I'm proudest of is the least glamorous: an emulation bench where firmware fails before it reaches a customer's meter.
We stand up a QEMU environment — software that emulates the meter's actual hardware — and flash a candidate firmware image against simulated endpoints carrying the fleet's real battery-and-signal profiles. The degraded-battery cohort, the weak-RF cohort, the high-write-cycle cohort. The first night we ran a profile modeled on an aged fleet and watched the emulated unit brown out exactly the way the field does and the lab never does, I finally understood that Plano wasn't an accident. It was reproducible. It had just never been reproduced before deployment, because the test environment didn't exist.
That's the inversion. Today, the field is the test environment, and the customers are the test subjects. We move the failure into a lab where bricking a thousand simulated meters costs nothing and teaches you everything.
Doesn't Predictive Maintenance Just Mean More False Alarms?
The objection I hear most from operations people — the ones who've been burned by tools that cry wolf — is that prediction is just a fancier way to generate noise.
It's the right worry. A health-scoring model that flags 30% of your fleet every week is worse than useless; crews learn to ignore it, and you've spent budget to recreate the alert fatigue you started with. So we calibrated against cost, not anomaly counts. The benchmark wasn't "how many failures did we catch" but "how many truck rolls did we prevent relative to the ones we triggered." Industry data on AI-driven predictive maintenance points to up to 30% reductions in maintenance cost and meaningful downtime cuts when it's done against the right signal — and the right signal, again, is physical wear, not data weirdness. A prediction that doesn't change a dispatch decision isn't a prediction. It's a notification. This is, I think, why so many utilities pilot AI maintenance and then stall — BCG's 2026 utility work calls out the pilot-to-production gap explicitly — they prove a model can flag failures, then can't justify the rollout because the flags never tied back to a dispatch a crew chief would actually trust.
Firmware Management Just Became a Compliance Document
There's a regulatory turn here that I think a lot of utilities haven't fully absorbed, and it raises the stakes considerably.
As of April 1, 2026, NERC CIP-003-9 is in effect. Its Requirement R1, Part 1.2.6 imposes vendor remote-access security controls on low-impact grid cyber systems — which is how most smart meters are classified. In plain terms: the over-the-air update path you use to push firmware is now a regulated control surface, and the penalties for getting it wrong run up to $1 million per day. The same OTA channel that bricked Plano is now also a compliance artifact you have to produce evidence for.
That changes the buyer conversation entirely. Firmware management used to be an operations chore. Now the access logs, the staging records, the rollback procedures — they go in a binder an auditor reads. A system that validates firmware before deployment isn't just preventing outages anymore; it's generating the evidence that you managed the update path responsibly.
There's a quieter standard underneath this one that procurement teams ask about and rarely get a straight answer on: IEC 62443, the industrial-cybersecurity standard for AMI. Very few meter vendors have pursued full IEC 62443 certification at the component level — the firmware itself. Most certify at the system layer and leave the endpoint firmware uncertified, which means the exact layer that bricked Plano is also the layer with the thinnest security attestation. That gap is why we do component-level security audits across mixed AMI supply chains, not just the head-end. On the other side of the Atlantic, the UK's Ofgem standards now mandate automatic compensation — £40 per instance — for supplier-fault meter failures, paid out within 10 working days. The cost of a dead meter is no longer just the truck roll. It's the fine, the compensation, and the audit finding.
What I'd Tell the Operations Lead With the Stale Dashboard
If I went back to that spreadsheet of stale timestamps now, here's what I'd say.
The number that should keep you up isn't the meters that have already gone quiet. It's the 29% — the share of endpoints some utilities discovered had failed silently, radios dead, with no alert ever raised, surfacing only when someone went looking. Your platform isn't lying to you. It's answering a narrower question than the one you actually have. It knows who stopped talking. You need to know who's about to.
The smart meter market is heading toward $112 billion by 2035, and the installed base in North America already sits past 150 million units. Every one of those endpoints is a small computer with an aging battery and a wearing flash chip, sitting on the side of a building, waiting for a firmware push tested somewhere it doesn't live. The next Plano is already provisioned. The only open question is whether anyone modeled the fleet it's about to land on. If you'd rather find out on a bench than on 73,000 customers' walls, that's the system to build.
The firmware that bricked Plano passed every test it was given. We just never gave it the right one.


