Eleven Words in an Annual Report Can Now Be Securities Fraud
The first time I really understood AI washing, I was staring at a single paragraph in a company's annual report. Eleven words, something like "our AI-driven platform analyzes risk in real time." A clean, confident sentence. The kind of line a marketing team writes in five minutes and a CEO approves without blinking.
Then I asked the engineers which model produced that analysis, what data it ran on, and where in the decision flow it actually fired. The room went quiet. Not because they were hiding anything. Because nobody had ever connected that sentence to a system. The claim lived in the filing. The system lived in production. And there was nothing in between — no document, no map, no evidence — linking the two.
That gap is the whole story. AI washing isn't a story about bad AI. It's a story about the distance between what you said your AI does and what your AI actually does — and whether you can close that distance on demand. The SEC, the FTC, and state attorneys general have all figured out that this gap is where the cases are. I built Veriprajna's AI verification and anti-AI-washing practice because I kept watching companies discover the gap only after the examiner's letter arrived.
The day "does your AI work" stopped being the question
I came to this from securities-enforcement work, the unglamorous side — assembling the binders companies hand an examiner when the document-request letter shows up. So I read every AI washing action the way I read an old fraud case: what did they say, what did they do, and what was the daylight between the two.
The pattern is brutally consistent. Delphia and Global Predictions, the first two AI-washing settlements back in March 2024, paid a combined $400,000 not because their AI was bad but because Delphia claimed machine-learning-powered investing it had never actually integrated. The data they bragged about feeding the model? It never reached the model.
Then Presto Automation, January 2025 — the first AI-washing case against a public company. Presto's drive-thru voice AI was marketed as eliminating human order-taking. The SEC found that more than 70% of orders still required a human, and at some locations it was 100%. The system was real. It just wasn't doing the thing the marketing said it did.
And then Nate. In April 2025 the SEC and DOJ filed parallel actions against the founder of Nate Inc., who had raised more than $42 million on the promise of an AI-powered shopping app. The actual automation rate was, in the SEC's words, essentially zero — hundreds of contractors in the Philippines were manually completing the purchases the AI was supposed to handle. The DOJ charges carry up to 20 years. That's the case I think about when someone tells me AI washing is a marketing-disclosure footnote. There was a press release with a founder's name on it and a criminal fraud charge underneath.
Every one of these cases turns on the same daylight: what the filing promised, and what the system in production actually did.
In February 2025 the SEC made it structural: it stood up a dedicated Cybersecurity and Emerging Technologies Unit inside the Division of Enforcement. And its 2026 examination priorities say it plainly — examiners will "review for accuracy registrant representations regarding their AI capabilities." That sentence is a document-request letter waiting to be mailed.
Three agencies, one move

What surprised me, once I started mapping this, was how little the enforcement theory varies across agencies. They all run the same play: line up the claim against the reality, then ask for the evidence.
The FTC came at it through Section 5 of the FTC Act — unfair or deceptive practices — under a sweep it named Operation AI Comply, launched September 2024. DoNotPay, the self-styled "world's first robot lawyer," settled over claims it couldn't back. Workado advertised an AI-detection tool as 98% accurate; the FTC's own testing put real-world accuracy around 53%. Roughly a coin flip, sold as near-certainty. The detail that should frighten any general counsel is the FTC's instrumentality theory: liability runs down the chain, from the base-model developer to the enterprise that deploys it to the end user. If you repeat a vendor's accuracy number in your own materials, the FTC treats it as your claim — not the vendor's.
I cannot stress that one enough, because it's the trap I see smart companies walk into. You license a third-party model, you copy the vendor's benchmark into your 10-K or your investor deck, and you assume the vendor owns that number. They don't. The moment it appears in your filing, it's your representation, and "our vendor told us" is not independent substantiation.
The states piled on with their own tools. New York's AI-companion law carries penalties up to $15,000 a day per violation. Colorado's AI Act, effective June 30, 2026, demands impact assessments, consumer notification, and reasonable care for high-risk systems, at $20,000 per violation. Texas's Responsible AI Governance Act, live as of January 1, 2026, hands the attorney general broad civil-investigative-demand power off a single complaint — one consumer letter and the document request is on your desk. And when the federal government floated preempting state AI laws, a bipartisan coalition of 36 state attorneys general lined up against it. Whatever the courts eventually decide, the enforcers are not waiting.
Even the private bar joined. The Stanford Securities Class Action Clearinghouse counted 53 AI-related securities class actions through the first half of 2025, with a median settlement of $11.5 million. One of them, Tucker v. Apple, filed June 2025, alleges Apple's WWDC promises about Apple Intelligence moved investors to buy in on features the complaint says had no functional prototype. A keynote slide became Exhibit A.
Why doesn't "we have an AI governance policy" save you?
Here's the part where I was wrong early, and it cost me a few months of building the wrong thing.
When I first started designing for this, I assumed the answer was governance — the category that platforms like Credo AI, IBM's watsonx.governance, Holistic AI, OneTrust, and Fiddler already serve well. We built toward a governance posture: policies, an AI inventory, dashboards, oversight workflows. I demoed an early version to a compliance officer at a mid-sized firm and felt good about it. She let me finish, then asked the only question that mattered: when an examiner demanded the evidence that one specific claim was true, which button was she supposed to press?
There wasn't a button. There wasn't a document. What I had built told her she should document her systems. It didn't contain the documentation. I'd built a thing that pointed at the gap instead of filling it. That was the failure that reframed the whole company for me.
Governance tells you that you should document your AI. Substantiation is the documentation — tested, dated, and ready for an examiner who is reading it cold.
The governance platforms are good at what they do. They monitor, they inventory, they enforce policy. But there's a layer underneath them that almost nobody builds: the actual evidence chain an SEC examiner or a state AG asks to see. That's the gap I rebuilt the practice around.
What does an examiner actually ask you to produce?
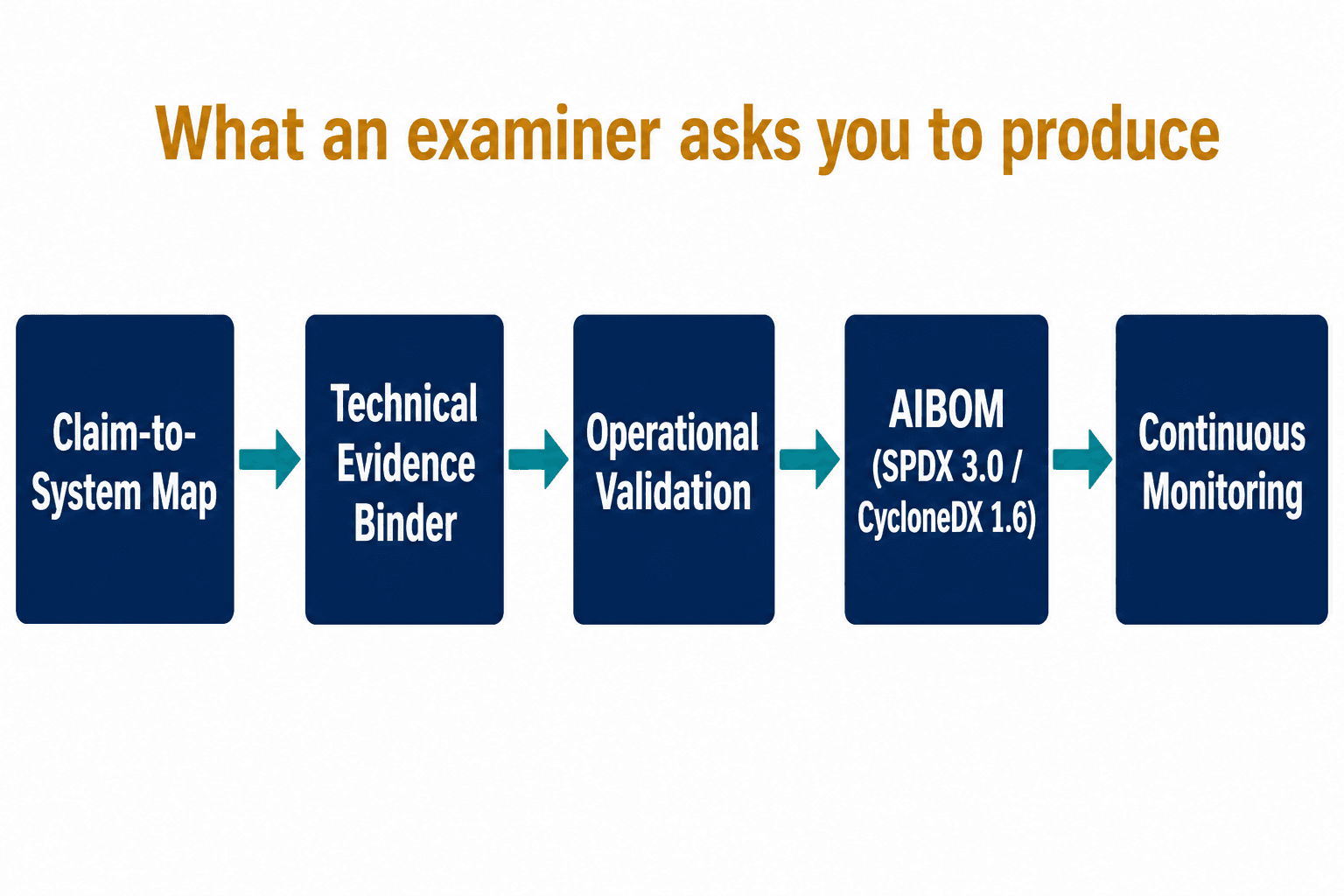
When I sat down to define what we'd deliver, I didn't start from a product spec. I started from the "please produce" list — the literal document request an enforcement letter contains — and worked backward. A defensible substantiation package, the thing we now build, has a few load-bearing parts.
It starts with a claim-to-system map: every public AI claim — from the 10-K, the website, the press releases, the pitch deck — linked to the specific model, data pipeline, and decision point that delivers it. When a filing says "AI-driven risk analysis," the map names which model, which data, which decision. This is the artifact that would have saved Delphia, because it forces the question "is this claim actually wired to a system?" before a regulator asks it.
Then a technical evidence binder — architecture, training methodology, and performance benchmarks measured against the exact metric you've claimed. Tested, not theoretical. If your materials say a number, the binder shows the test that produced it under a real-world methodology, not a cherry-picked demo. Workado is the cautionary tale: 98% in the brochure, 53% under test.
Then operational validation, which is where Presto died. The system existed. What was missing was proof that the AI actually drove the decisions the marketing described, rather than running alongside humans who did the real work. Proving operational reality is harder than proving a model exists, and it's exactly what examiners now probe.
Underneath all of it sits an AIBOM — an AI Bill of Materials, a machine-readable inventory of every component: training-data lineage, model versions, third-party dependencies, infrastructure. The standards finally exist to do this properly; SPDX 3.0 added an AI profile in October 2024 and CycloneDX 1.6 supports machine-learning bills of materials, with the OWASP AIBOM project pushing tooling forward. The honest truth is most firms today still track this in a spreadsheet that goes stale the moment a model is retrained. I've opened model cards carrying a version number two retraining cycles out of date — documentation describing a system that no longer exists. An AIBOM that updates with the pipeline is the difference between a snapshot and a living record.
And finally continuous-monitoring evidence — drift-detection results, automated test logs, the ongoing proof that the claim stayed true after launch. A substantiation package isn't a one-time binder you file and forget. It's a record that keeps breathing, because your model keeps changing and your filing doesn't.
The hallucination bill nobody is putting on the balance sheet
There's a second front to this, and it's the one that pulled me past securities filings into content itself.
A claim isn't only something you say about your AI in a disclosure. It's also every output your AI generates and you put your name on — the report, the analysis, the customer-facing summary. And those outputs hallucinate. Stanford's RegLab found large language models hallucinate on specific legal queries somewhere between 69% and 88% of the time. There are now more than 600 documented cases of AI hallucinations surfacing in court filings, with over 100 lawyers implicated and judges imposing sanctions north of $10,000.
The enterprise cost is staggering and weirdly invisible. One analysis put global losses from AI hallucinations at $67.4 billion in 2024, with companies spending around $14,200 per employee per year just on mitigation — the hours people burn fact-checking their own tools. When nearly half of enterprise AI users have made a major decision based on hallucinated content, "the AI generated it" is not a defense. It's the admission.
That's why content verification belongs in the same practice as claim substantiation: both are about provenance. The EU AI Act's Article 50, effective August 2026, requires AI-generated content to be machine-readable and detectable as such, with a content-labeling code of practice arriving alongside it. The C2PA provenance standard — the one Samsung's and Google's flagship phones already sign with natively — is becoming the plumbing for proving where a piece of content came from. If your AI produced a report and it later turns out to contain a fabrication, the only thing standing between you and liability is an audit trail back to the source. Most companies don't have one.
Provenance cuts the other way too. Sixty-five percent of businesses reported a deepfake incident in 2023, and the detection market is racing from $5.5 billion toward a projected $15.7 billion by 2026. Proving your own content is real is becoming as urgent as proving someone else's is fake — and the same C2PA signature that authenticates your AI's output is the one that lets you disown a forgery wearing your brand.
The questions I get, and the ones I wish I got
People always ask me whether ISO 42001 certification handles all this. It helps — it's a real, auditable standard, and third-party certification carries weight with boards and procurement. But it runs $90,000 to $200,000-plus in the first year and takes the better part of a year to stand up, and it certifies that you have a management system, not that any specific marketing claim is true. Certification and substantiation are different jobs. You can be certified and still unable to answer the examiner's question about one sentence in your 10-K.
The other question, usually from founders, is whether this is just a big-company problem. Nate raised $42 million and the founder is facing criminal charges. Delphia was not a household name. The Texas AG can open an investigation off one complaint. The size of the enforcement risk tracks the size of the claim you made, not the size of your company.
The question is no longer whether your AI works. It's whether you can prove it does what your filings say it does.
If I could plant one idea in every general counsel and chief compliance officer reading this, it's that the gap between marketing and engineering reality is now a legal liability with a dollar figure on it — and the only thing that closes it is evidence you built before anyone asked. That's the entire premise of what we build at Veriprajna: not another dashboard that tells you to document your AI, but the substantiation package itself — the claim-to-system map, the evidence binder, the AIBOM, the provenance trail — assembled and tested before the document-request letter lands.
I keep coming back to that annual report. Eleven words, filed and forgotten, with nothing behind them — no map, no binder, no log connecting the sentence to a system. The model under it probably worked fine; most of them do. What was missing was the one thing an SEC examiner, an FTC investigator, and a plaintiff's lawyer all ask for in the same flat sentence: show me. Write the claim you can prove, and build the proof before anyone asks.