
We Built a Faster Airline Crew Solver. It Just Failed Faster.
The first time I sat in an airline operations control center during a real cascade, it was a little after 3 AM and a winter storm had closed a key station hours earlier. The video wall along the front of the room was filling with red — cancellation after cancellation — and the thing I remember most is that nobody was using the multi-million-dollar crew scheduling solver the airline had paid for. The dispatchers had pushed their keyboards aside and were working broken crew pairings by hand, on spreadsheets and a whiteboard, at the exact moment the software was supposed to earn its keep.
That image is what eventually led us to build airline crew scheduling AI for IROPS recovery — but not in the way I expected, and not before I backed the wrong fix and watched it fail. IROPS, if you've never had the pleasure, is the industry's word for irregular operations: the storms, the closures, the cascading mess when a schedule comes apart. It costs the airline industry an estimated $60 billion a year, roughly 8% of global airline revenue, according to IATA. About one in five flights worldwide is touched by it. And the dirty secret I learned that night is that the most sophisticated optimization software in aviation is essentially designed to be useless during the very events that cost the most.
The Solver Was Optimizing an Airline That No Longer Existed
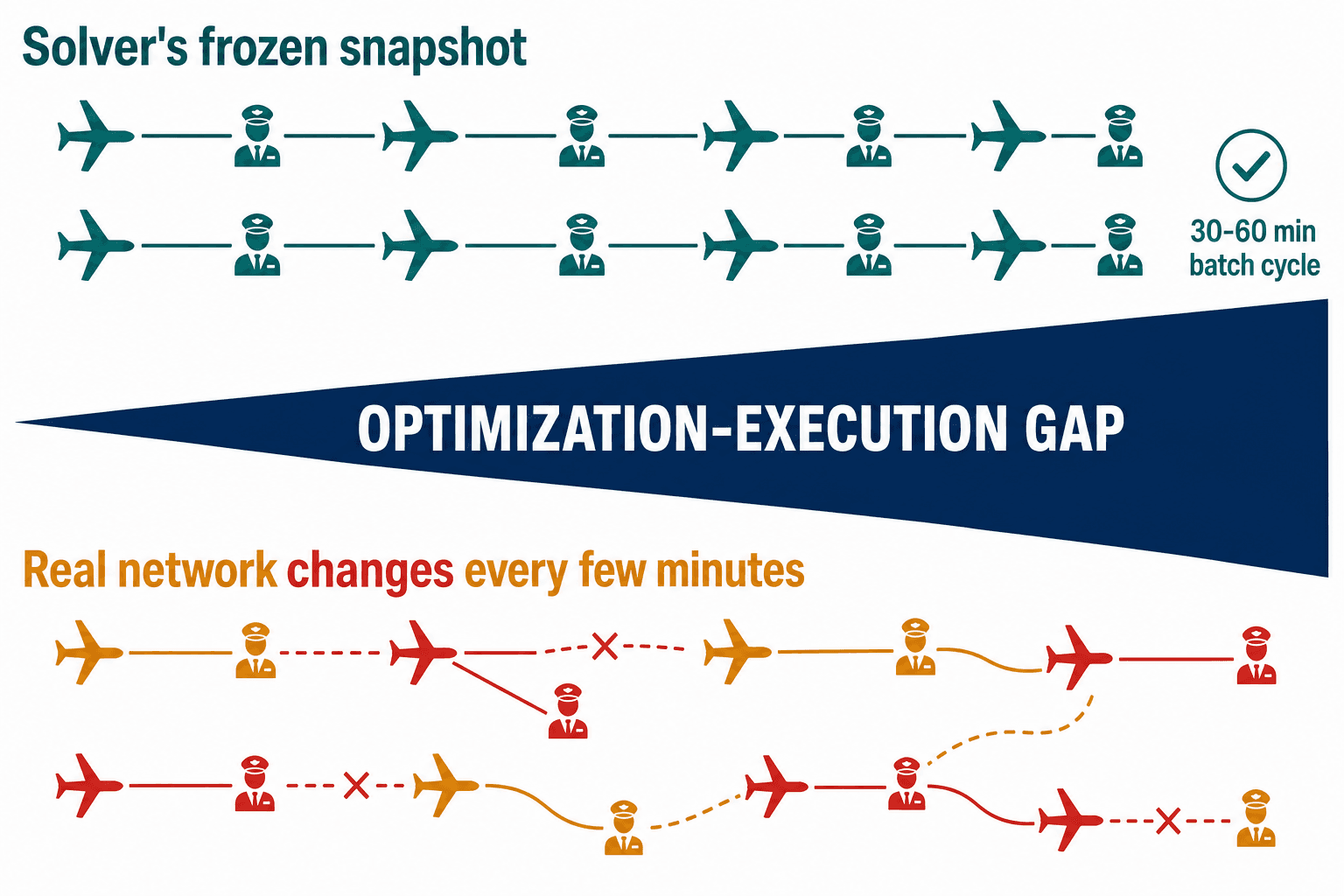
It helps to know what the legacy crew solvers actually do. They run column generation — a branch-and-price optimization technique that's genuinely brilliant at finding the cheapest legal way to staff a known schedule. The catch is in the word known. The solver takes a snapshot of the network, freezes time, and computes the optimal crew assignment for that frozen world. It runs on batch cycles, typically every 30 to 60 minutes.
During normal operations, that's fine. The world barely moves between cycles. But during a cascade, the network state changes every few minutes. Crews move. Connections break. Aircraft strand. By the time the solver returns a solution, the inputs it was given are already wrong — so the answer is a perfect plan for an airline that no longer exists.
I started calling this the Optimization-Execution Gap: the distance between the world the solver assumed and the world that's actually out there on the ramp. The gap is harmless during an isolated delay. During a cascade, it's fatal, because the solver was built for efficiency — the cheapest schedule in a known world — and what you desperately need at 3 AM is resilience: a survivable schedule in an unknown one.
The cruelest part of a legacy crew solver is that during a meltdown it keeps working — calmly handing you a flawless plan for a network that fell apart while it was computing.
Why Couldn't We Just Make the Solver Faster?
This is the part I'm not proud of, and it's the part that actually matters.
When my team first looked at the problem, our diagnosis was the obvious engineer's diagnosis: the solver is too slow. The world is changing every five minutes and the optimizer takes thirty to an hour, so close the gap — make it faster. We spent real time building a faster recovery engine, leaning on cheaper heuristics to get a feasible answer inside the operational decision window instead of waiting for a provably optimal one.
And it worked, in the narrow sense that it returned answers faster. Then we tested it against real disruption data and I watched it confidently produce recovery plans that were already invalid, just sooner. We had built a machine that optimized a phantom airline at higher speed.
The mistake was treating speed as the bottleneck. It wasn't. The bottleneck was that the inputs were fiction. The solver — ours included — needs hard facts: "Captain Smith is at Gate B7 in Denver." But during a cascade, Captain Smith might be at the hotel, might be on the employee shuttle, might have rented a car and be halfway to Colorado Springs. The honest state of the world is "probably in Denver," and a column-generation solver cannot do anything with probably. We had been sharpening the answer to a question whose data was garbage.
That failure is the reason the product exists. If we'd shipped the fast solver, we'd have sold airlines a quicker way to make the same expensive mistake.
The $1.2 Billion Data Black Hole
If you want to see this exact failure at full scale, look at what happened to Southwest in December 2022. The meltdown cost the airline roughly $1.2 billion, cancelled around 16,900 flights, and stranded close to two million passengers over the holidays.
The popular story is "old software." The real story is more specific and more useful. Southwest's crew scheduling system, SkySolver, hit a combinatorial explosion it couldn't compute through. But underneath that, the airline lost track of where its own pilots and flight attendants physically were. Crew position reporting ran largely through phones — crews stranded at outstations calling a scheduling center where hold times climbed into hours. That latency created what I think of as a data black hole: the system was generating schedules for crews who weren't where it thought they were. It was optimizing a phantom network, and the point-to-point route structure meant there were no hub "regeneration points" where crews and aircraft naturally reconverge, so the blast radius just kept spreading station to station.
This is not ancient history that everyone has since fixed. In July 2024, Spirit's scheduling system created conflicting assignments for 43% of its available flight crews, an estimated $50–100 million event, because the system lacked the flexibility to reassign crews cleanly during the disruption. The pattern repeats because the underlying architecture — optimize a frozen snapshot, demand certain inputs — is the same across the industry.
Southwest, to their credit, responded by spending: about $1.7 billion on technology in 2024 as part of a larger multi-year program, an AWS migration that cut their data center footprint dramatically, and a roughly 30% faster scheduling algorithm. That's the right instinct. But a faster version of the same architecture — which is the trap we nearly fell into ourselves — closes the speed gap while leaving the data certainty gap wide open.
What Happens Now When a Delay Crosses Three Hours?
For most of aviation history, a slow recovery cost you goodwill. Angry passengers, bad press, some vouchers. That math changed on October 28, 2024.
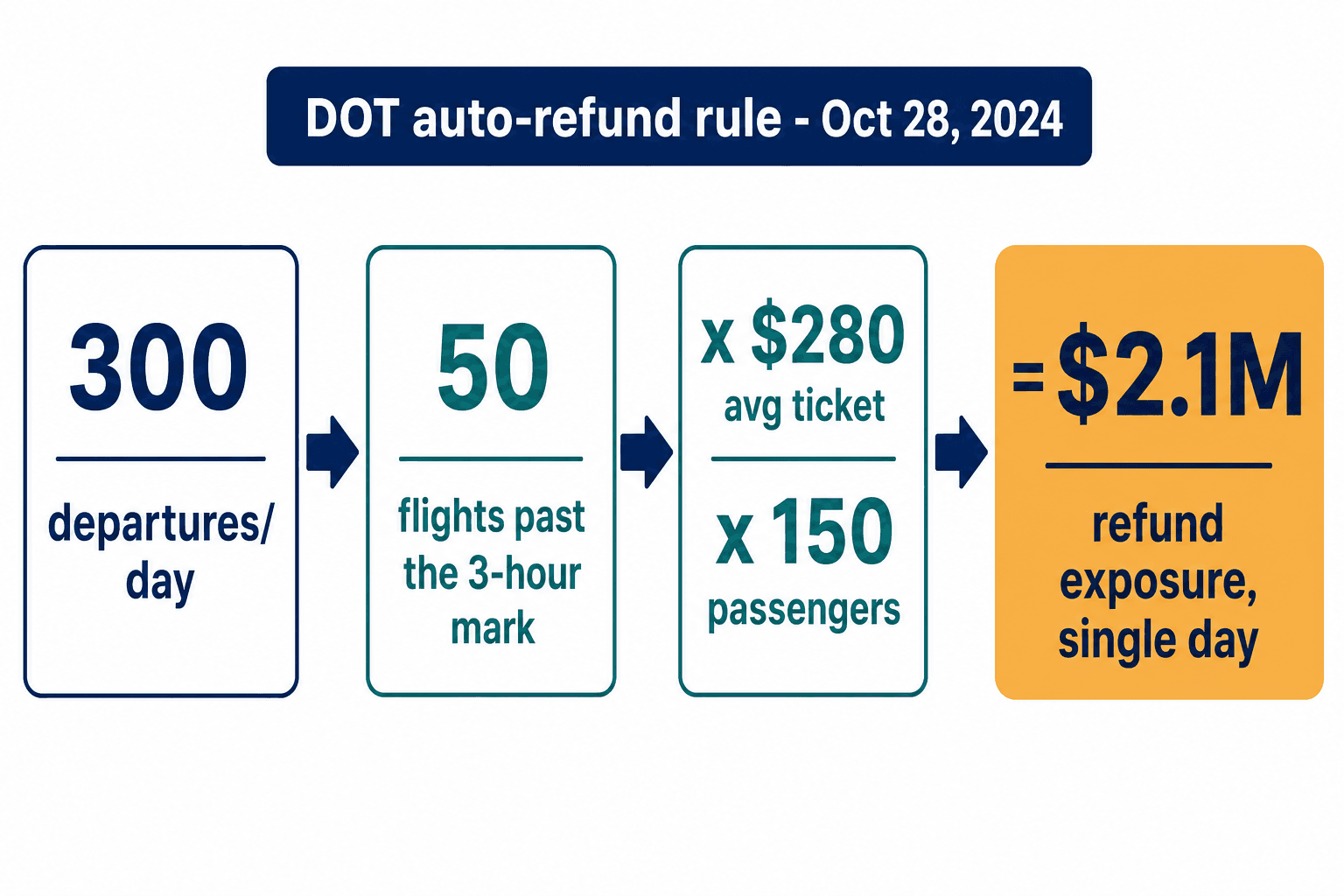
That's when the U.S. Department of Transportation's automatic refund rule took effect — the first-ever mandatory automatic refund requirement. Any domestic delay over three hours (six for international) now triggers a cash refund, paid within seven business days, without the passenger even asking. Not a voucher. Not a rebooking. Cash.
Run the arithmetic for a mid-size carrier flying 300 departures a day. On a genuinely bad day, if even a sixth of them — 50 flights — slip past the three-hour mark, at an average ticket value of $280 and 150 passengers a flight, you're looking at around $2.1 million in mandatory refund exposure from a single day. Slow IROPS recovery used to be a reputation problem. Now it's a line item that hits the same week.
There is now a meter running on every hour your recovery falls behind, and since last October it pays out in cash, automatically, to every passenger it touches.
This is the part that reframed the whole conversation for me. The cost of the Optimization-Execution Gap is no longer abstract. It compounds, in dollars, against a clock that started the moment the storm did.
Augment the Solver, Don't Replace It
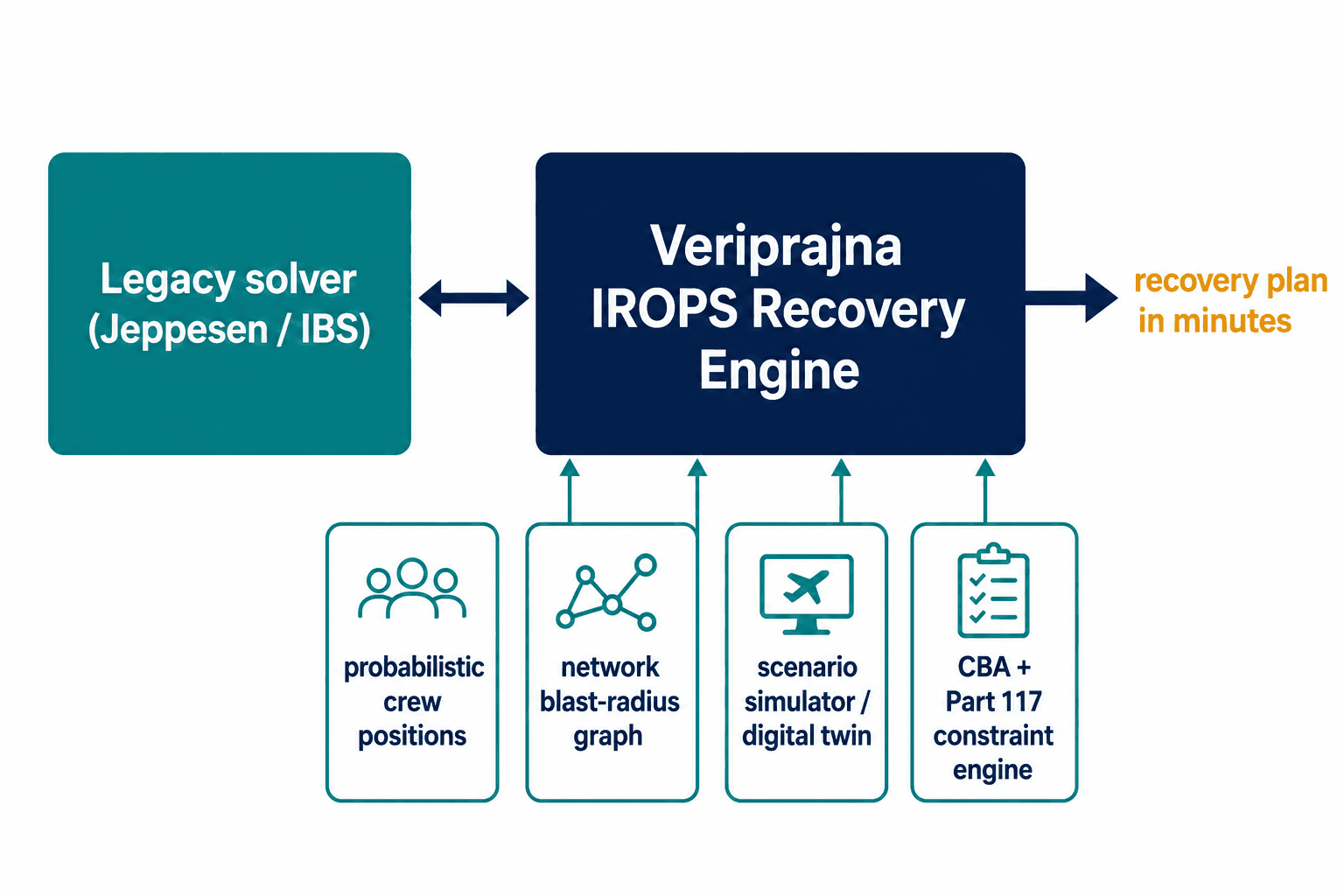
Here's the decision that defines our approach, and it's a deliberately unsexy one: we do not replace your solver.
The incumbent solvers encode decades of airline-specific domain knowledge, and the field around them is consolidating, not collapsing. Jeppesen — the industry standard, with more than a hundred airline clients — was sold by Boeing to Thoma Bravo for $10.55 billion in April 2025, one of the largest tech divestitures in aerospace history, and has since launched Stratosphere, an AI layer for predictive disruption management. IBS Software's iFlight platform is winning modern, cloud-native deployments — Korean Air went live in early 2026, with carriers like Aeroitalia and Groupe Dubreuil's airlines also moving onto it — backed by a co-engineering arrangement with AWS. Optym's CrewSolver delivers a documented 3–7% crew cost reduction on the planning side.
None of those are the enemy. But notice what they're each strong at: planning-phase optimization and predictive analytics — the known world, computed beautifully. The real-time, uncertain-input recovery problem is the gap that stays open. A full platform replacement is also a 12-to-18-month project, and no operations leader wants to rip out the system that works 350 days a year to fix the 15 that don't. For the CIO who actually signs the contract, the math is worse than the calendar: ripping out a system with decades of carrier-specific CBA logic encoded in it — at the very moment Jeppesen's own ownership has just changed hands for $10.55 billion and its long-term roadmap is an open question — is a bet most tech orgs won't make. Sitting alongside the existing install, consuming its feeds rather than replacing its schema, is the only integration they'll green-light.
So we built an ML-powered IROPS recovery engine that sits alongside an existing Jeppesen or IBS installation and handles the thing the core solver can't: cascading disruptions with uncertain crew positions, network-wide blast-radius analysis, and recovery plans produced in minutes rather than the 4-to-12 hours manual recovery typically takes. Regional case data suggests automation can cut that recovery time by around 78%. The point isn't to be smarter than the incumbent. It's to be useful in the exact conditions the incumbent was never designed for.
Teaching a Model to Work With "Probably in Denver"
Once we stopped trying to make the solver faster, the actual engineering problem came into focus: build something that thrives on uncertainty instead of choking on it.
The first piece is crew position intelligence. Instead of demanding a certain location, we feed a model probabilistic positions — fusing whatever real-time signals exist with historical behavior, so the system reasons about where a crew likely is rather than waiting for a phone call that's four hours deep in a hold queue. That single shift — from "certain or nothing" to "probability distribution" — is what lets a recovery plan survive contact with a real cascade.
The second piece is treating the network as a graph and analyzing where failures will propagate before they do — the blast radius, mapped to this specific airline's route structure, so you can see which station closure quietly cancels six downstream flights two hours from now.
The third piece is a scenario simulator, effectively a digital twin of the operation, so an ops team can rehearse a winter-storm scenario in advance and test recovery strategies when there's no actual storm and no actual clock. Aviation already trusts digital twins where the data is rich — Lufthansa's AVIATAR platform ingests 23.7 terabytes a day across 34 airline integrations and hits 93.6% accuracy on maintenance failure prediction. Crew and scheduling twins are still nascent, which is precisely where the opportunity is.
And running through all of it is the constraint engine. Every recommendation has to be legal under FAA Part 117 fatigue rules — the 8-to-9-hour flight time limits, the 9-to-14-hour duty periods — and under the airline's union contract, which is frequently more restrictive than the regulation. Most vendors treat those rules as "configuration." We treat encoding a carrier's specific collective bargaining agreement, by fleet and by domicile, as core engineering, because a recovery plan that violates a CBA clause isn't a plan — it's a grievance.
Why We Run in Shadow Mode First
People in this industry are right to distrust a black box telling them how to move pilots at 3 AM. So I'll tell you the objection I hear most, because I had it myself.
An ops VP early on told us, more or less, that they'd just licensed the AI disruption add-on from their incumbent and didn't see why they needed us. Fair. Then the next storm came, the add-on gave them predictions and not executable crew recovery, and the dispatchers were back on the whiteboard. The distinction that conversation taught me: there's a world of difference between agentic AI for passenger-facing chat — the conference-circuit buzzword of 2026 — and AI that makes operational decisions about crews and aircraft. A chatbot that re-accommodates a passenger is a fine thing. It is not the same engineering problem as recovering a network.
That's why the first time any airline runs our engine, it doesn't touch operations. It runs in shadow mode: our model's recommendation sits beside the human dispatcher's actual decision, and we measure the gap, day after day, on the airline's own disruptions. Trust isn't asserted in a sales deck. It's earned on a comparison sheet, with no operational risk, until the ops team decides for themselves that the recommendations are better than the whiteboard.
You don't earn the right to reroute someone's pilots with a benchmark. You earn it by being right, quietly, next to a human, for weeks, before anyone has to believe you.
The honest truth is that watching shadow mode is when I understood what we were actually selling. Not an optimizer. Not speed. We were selling a way for an operations leader to believe a machine on the worst night of their year — and belief has to be built before the storm, not during it.
What the 15 Days Are Really Worth
If you run a mid-size airline's operation, your crew solver works fine 350 days a year. I'm not here to argue otherwise. The question is what happens on the 15 days it doesn't — and those are the days that produce the billion-dollar headlines, the 43%-of-crews-misassigned audits, and now, since last October, the automatic cash refunds metered by the hour.
The mistake the whole industry keeps making — the mistake I made first, with my own faster solver — is treating those 15 days as a speed problem to be solved by computing harder. They're not. They're a certainty problem, and you don't solve a certainty problem by demanding more certainty from a world that's actively coming apart. You solve it by building something that reasons under uncertainty, rehearses the disaster before it arrives, and proves itself in the shadows before it's ever trusted in the light. That's the engine we built, and it's described in full at our airline crew scheduling AI solution.
Somewhere tonight there's an ops control center where the video wall is calm and green, and a crew solver is humming through its batch cycle exactly as designed. The work we do is for the night that room turns red — when the phones back up, the pairings break faster than anyone can write them down, and a dispatcher reaches for a whiteboard because the certainty the software demands has quietly left the building. The whole point is to make sure that, on that night, the machine is still reasoning honestly about an airline it can no longer fully see.


