The AI Dropped an Eligible Patient Because It Couldn't Tell a Heart Cath From an IV Line
The first patient we lost, we lost to a word.
A Phase III anticoagulant trial we were piloting on excluded anyone who had undergone a "cardiac catheterization." Reasonable — it's a heart procedure with bleeding risk, exactly the kind of history that disqualifies someone from a blood thinner study. Our matching system flagged a candidate as ineligible and moved on. Clean. Confident. Wrong.
The patient had never had a cardiac catheterization. Her chart contained a note about a "central venous catheter placement" — an IV line threaded into a vein in the ICU so she could receive medication. Different procedure. Different part of the body. Different risk profile entirely. To a nurse, these aren't remotely confusable. To the AI we'd built, "catheter" plus "venous" plus a cardiovascular-sounding context scored as a near-match, and an eligible woman quietly fell out of the funnel.
I want to tell you how I came to spend the better part of a year obsessing over that single dropped patient, because it taught me the thing nobody selling clinical trial recruitment AI wants to say out loud: the problem in patient matching was never finding enough people. It's that the machines doing the matching read words, and trial eligibility is about medical concepts — and those are not the same thing.
80% of trials miss their enrollment timelines. The industry keeps treating that as a supply problem. It's a precision problem.
The mistake I made first
I'll own this up front, because it's where the whole story turns. When we started, I was in the camp that believed this was basically solved.
The reasoning went like this. For years, trial matching ran on keyword search — crude, brittle, miserable. Then large language models arrived, and suddenly software could read an unstructured doctor's note the way a person does. I looked at that and concluded the hard part was behind us. We'd take a strong model, feed it eligibility criteria and patient records, tune the prompts, and the matching would just work. I argued for it. I told my team the gap left to close was small, a matter of better retrieval and more careful prompting.
We built that system. It demoed beautifully. On the easy cases — the patient who clearly has stage II breast cancer, the criterion that clearly says "no prior chemotherapy" — it was genuinely good. The numbers you see in vendor decks come from exactly these cases. Tempus, after acquiring Deep 6 AI in early 2025 and expanding to over 750 provider sites, reports its Patient Query agent hitting 94.39% accuracy across a set of evaluated queries. That number is real. I believe it. It's also measuring the cases that were never the problem.
The catheterization patient was the moment my version of the system died. I sat there tracing why she'd been dropped, expecting a bug. There was no bug. The system had done exactly what vector similarity does — scored two strings by how close they sit in semantic space — and two procedures that share the word "catheter" sit very close indeed. No amount of prompt engineering was going to teach it that one lives under "procedure on the heart" and the other under "catheterization of a vein." It didn't have a concept of the heart. It only had words about the heart.
Why do language models confuse medical terms?
Here's the distinction that reorganized how I think about this entire field.
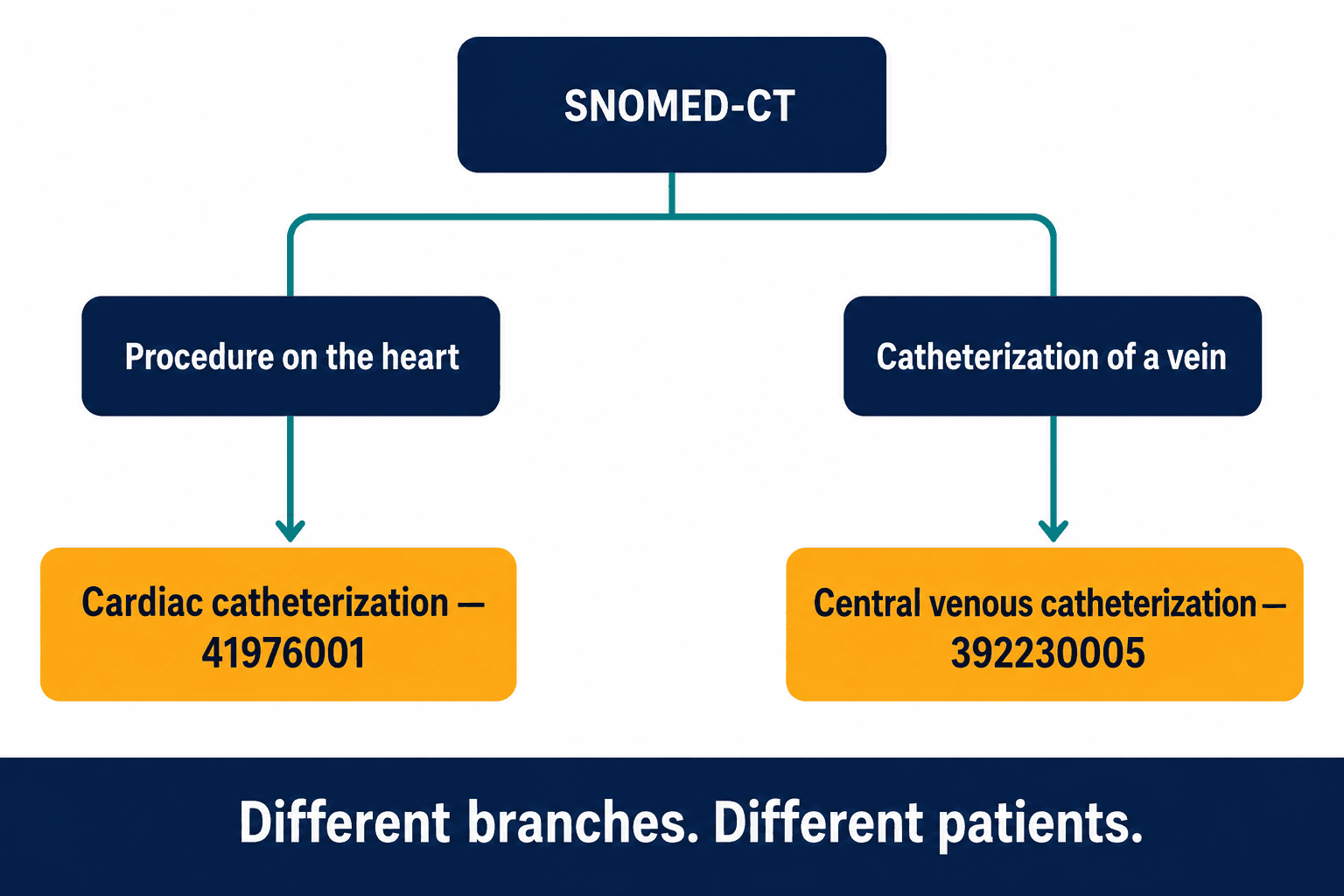
When a clinician reads "central venous catheter placement," they don't process five tokens. They retrieve a concept — a specific node in a vast, structured hierarchy of medical knowledge, with parents and children and siblings, with a precise place that says this is a vascular access procedure, not a cardiac one. That hierarchy actually exists, formally, as a clinical ontology called SNOMED-CT. In it, cardiac catheterization is concept ID 41976001, filed under procedures on the heart. Central venous catheterization is 392230005, filed under catheterization of a vein. Two different branches of the tree. A system that reasons over the tree cannot confuse them. A system that reasons over word-proximity confuses them constantly.
This isn't a quirk I stumbled onto privately. Published evaluations have documented AI models making this exact "cardiac catheterization equals central venous puncture" error (Fierce Biotech, 2025). It represents a whole class of failures — anywhere procedures, conditions, or medications share vocabulary but diverge medically. Coronary angiography and peripheral angiography. They share "angiography." One is a cardiac procedure; the other is vascular access. A language model scores them as cousins. The ontology knows they're strangers.
Now multiply that by a protocol's worth of criteria, across a portfolio of trials, and you don't have an edge case. You have a systematic eligibility leak running quietly in the background of every probabilistic matcher in the industry.
A language model knows that "catheter" appears near "cardiac." It has no idea that one is a heart procedure and the other is an IV line. That gap is where eligible patients disappear.
The exception clauses that broke everything twice
Once I started looking, the word-versus-concept gap turned out to be only the first crack.
Another one lives in the grammar of eligibility itself. Real protocols don't say "exclude hypertension." They say "exclude patients with hypertension unless well-controlled on stable medication for three or more months." That sentence is not a keyword — it's a conditional with a time window buried inside it. I watched our early system handle that clause two ways, both wrong. Sometimes it saw "hypertension" and excluded the patient, losing someone who actually qualified. Sometimes it waved them through and skipped the three-month check entirely. It never reliably did the thing a coordinator does without thinking: hold the exception, then verify the duration.
That matters more every year, because protocols are getting baroque. Median eligibility criteria in oncology protocols roughly grew from 17 a generation ago to 27 in the more recent cohort, and the number of procedures per protocol has climbed 139% since 2005 (IQVIA). Every "unless" and "except" and "within six months" is a place a word-matcher silently guesses. And when amendments arrive — the average amendment now takes 260 days to implement (Applied Clinical Trials, 2025) — every guess has to be re-guessed.
The failure that genuinely scared me, though, was different — it cut at whether I could stand behind this work in front of a regulator at all. Run the same patient through a language-model matcher twice, with slightly different surrounding context, and you can get two different answers. For most software, a little non-determinism is tolerable. For a clinical trial, it's disqualifying. A regulator doesn't want a probability that a patient was eligible. They want the exact, reproducible reason each person was included or excluded — a trail they can read line by line. A system that might decide differently on a Tuesday cannot produce that trail.
What I should have built the first time
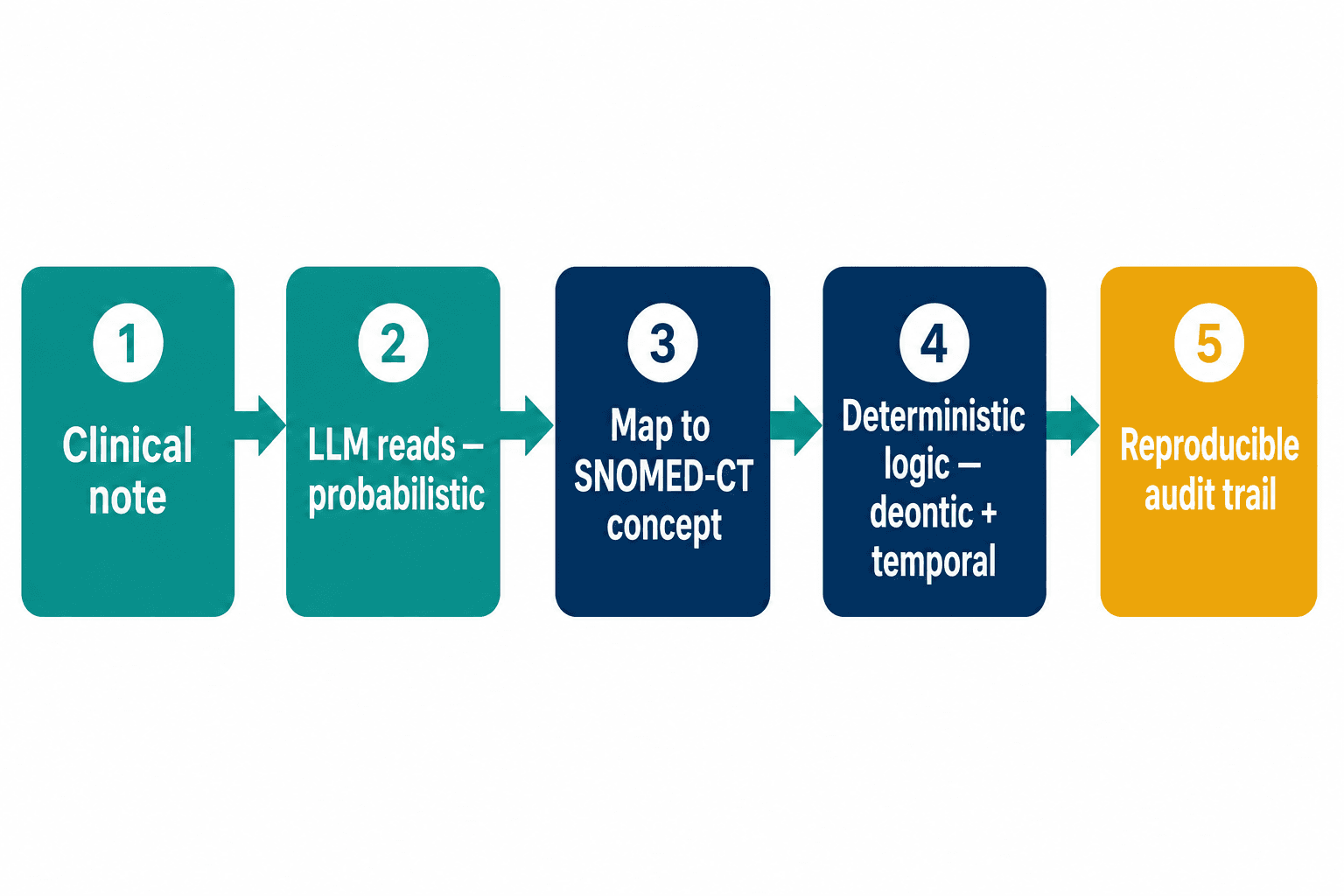
The rebuild was not subtle. We stopped trying to make a probabilistic system behave deterministically and built a system that was deterministic by construction.
The spine of it is the ontology. We map every term in a patient's record and every term in the eligibility criteria to its SNOMED-CT concept — so the matcher is comparing nodes in a medical hierarchy, not strings. Cardiac catheterization and central venous catheterization stop being neighbors and become what they are: distant relatives on separate branches. The catheterization patient, run through this, comes back eligible. Correctly. Every time.
On top of the ontology we put explicit logic for the parts language models fumble — the "unless," the "except," the "within three months." That kind of reasoning is really two disciplines stitched together: deontic logic to model the obligation-and-exception structure of an "unless" clause, and temporal interval reasoning to evaluate "within three months" against the actual dates in the record. Neither is pattern-matchable; both have to be modeled explicitly. And because every decision is a chain of explicit steps over named concepts, the system emits exactly the artifact regulators want: a reproducible audit trail showing precisely which concept matched which criterion and why a patient landed where they did.
I'm careful to say neuro-symbolic, not "we threw out the language models." We didn't. They're excellent at the messy first step — reading a rambling clinical note and pulling structured meaning out of prose. We let them do that. We just don't let them be the judge of eligibility. The reading is probabilistic; the reasoning is deterministic. That division of labor is the whole design.
This is the system we now build for pharma sponsors, CROs, and academic medical centers, and it's what our clinical trial recruitment AI work is organized around — custom matching that reasons over SNOMED-CT ontology graphs with deterministic logic, rather than one more probabilistic scorer.
Why haven't the big platforms just built this?
This is the question I get from every sponsor, and it's fair. Tempus, IQVIA, Medidata, ConcertAI, TriNetX — these are serious companies with enormous data. Why hasn't one of them simply built the ontology-grounded version?
Part of the answer is that they're optimizing for a different thing, and it's a reasonable thing. IQVIA unveiled IQVIA.ai, a unified agentic platform built with NVIDIA, in March 2026, sitting on more than 250 million patient records. TriNetX runs a federated network of similar scale for feasibility and cohort work. ConcertAI launched its agentic Accelerated Clinical Trials platform in February 2026, claiming 10-to-20-month timeline reductions. Medidata's AI Study Build plugs matching into its Rave electronic data capture system across hundreds of studies. Every one of these is real and good at what it targets — breadth, scale, end-to-end workflow.
There's a quieter gap underneath all of them, too. Even when a platform matches well, the output usually lands as a list a coordinator then re-keys into the trial-management system of record — Rave, Veeva Vault, Oracle Clinical One. The match and the system that runs the study don't actually talk, so a manual handoff persists exactly where you'd want the automation to be tightest.
But breadth and ontological depth pull in opposite directions. A platform serving every therapeutic area at 250-million-record scale is built to be generically good, and generically good is precisely where the catheterization class of error lives. The deep, branch-aware reasoning that a complex oncology, rare-disease, or CNS protocol needs is expensive to build and expensive to maintain — SNOMED updates twice a year, the MedDRA adverse-event dictionary updates quarterly, and keeping an ontology current is permanent headcount, not a one-time project. It's the kind of unglamorous, never-finished engineering a platform racing toward breadth tends to defer.
The platforms aren't wrong. They're solving for scale. Ontological precision is a different problem, and it's the one that decides whether your eligible patients actually get found.
The other honest answer is data gravity. Several of these platforms match best inside their own network — their data, their sites. If your patients live in your own electronic health record, behind your own firewall, that's a different deployment entirely. And a lot of sponsors and hospitals, for very good HIPAA reasons, will not send patient records to someone else's cloud to be matched.
The cost nobody puts on the slide
Let me make the stakes concrete, because the human and financial sides of this are easy to abstract away.
Financially: a day of delay in a trial costs an estimated $800,000 in lost prescription sales (Tufts CSDD), and for some therapeutic areas it's far worse — cardiovascular delays run to roughly $1.4 million a day. Every screen failure averages about $1,200, and screen failure rates run anywhere from 20% to 80% depending on the indication, reaching as high as 88% in Alzheimer's trials. The catheterization patient — the eligible one we dropped — is pure waste in this math: a person who should have advanced, didn't, and someone paid to screen her into a "no."
But the cost I didn't appreciate until I sat with site staff is human, and it compounds. Coordinators are juggling five or six studies at once and spending 40 to 60% of their time on pre-screening. When a matching tool throws off false positives above roughly 30%, they stop trusting it — and they abandon it, often within three months. I watched this happen to us before the rebuild. A coordinator at a pilot site had simply stopped opening our flags. Not out of spite — out of triage. The tool had cried wolf often enough that checking it was slower than her own chart review. A matcher that erodes the trust of the one person who has to act on it isn't a productivity tool. It's another browser tab she's learned to ignore.
That's the real reason precision beats reach. It isn't only the eligible patients you lose to false negatives. It's that every false positive spends the scarcest resource in the whole enterprise — a burned-out coordinator's attention — and once that's gone, the best data network in the world still dead-ends at a coordinator who's stopped looking.
"Isn't this what FHIR and Epic integration are for?"
People ask me this a lot, so let me take the objections head-on.
Start with the data-standards objection: surely FHIR and Epic solve the matching problem? They solve the plumbing problem, which is necessary and not sufficient. FHIR and Epic integration get clean, structured data flowing — but getting the data is the part before the hard part. You still have to reason about what the data means, and that's exactly where the ontology does its work. And the plumbing isn't trivial either: Epic's App Orchard certification is a six-to-twelve-month security review before you touch a single chart. Anyone promising fast, deep EHR matching either has already paid that cost or hasn't met it yet.
Then there's the regulatory worry: doesn't a deterministic, rules-heavy system count as a regulated medical device, with all the burden that implies? This is where recent guidance actually helps. The FDA's updated clinical decision support guidance, issued in January 2026, clarified which CDS functions fall outside the device definition — and matching patient records against trial eligibility criteria can qualify as non-device CDS. The same body's January 2025 framework laid out a seven-step credibility assessment for AI in drug development. A system whose reasoning is transparent and reproducible is far easier to walk through that framework than one whose logic is a probability distribution.
And the bluntest version: is any of this faster than just hiring more humans? The performance data says emphatically yes — when the matching is trustworthy. Reported AI screening has cut screen-failure rates by 73% in one deployment, from 54% down to 14% (Trially), and reduced manual chart-review hours by roughly 90%. The catch is that those gains only materialize if coordinators believe the output enough to act on it. Speed built on false positives isn't speed. It's a faster way to lose the room.
What the dropped patient actually taught me
I keep coming back to her, the woman with the IV line that an algorithm mistook for a heart procedure. She was eligible the entire time. The trial needed her. She was sitting right there in the data. And we lost her not because the technology was weak but because it was pointed at the wrong problem — reading the surface of language when the job was reasoning about medicine underneath it.
The whole field spent five years replacing keyword search with language models and declared the matching problem handled. It wasn't. It was repositioned. We traded crude word-matching for sophisticated word-matching, and the cases that decide whether a trial enrolls on time — the exception clauses, the shared-vocabulary procedures, the criteria that need a regulator to be able to read why — were never about words at all.
If you run trials and you're evaluating recruitment AI, the question I'd put to a vendor isn't their headline accuracy number, because that number is measured on the cases that were never going to be missed. Ask them to walk a cardiac catheterization and a central venous line through their matcher and show you, by concept, why one excludes and one doesn't. The answer to that one question tells you whether you've bought a system that reads, or one that actually understands. We chose to build the second kind — the clinical trial recruitment AI that reasons over the ontology — because the first kind already cost us a patient we couldn't afford to lose.