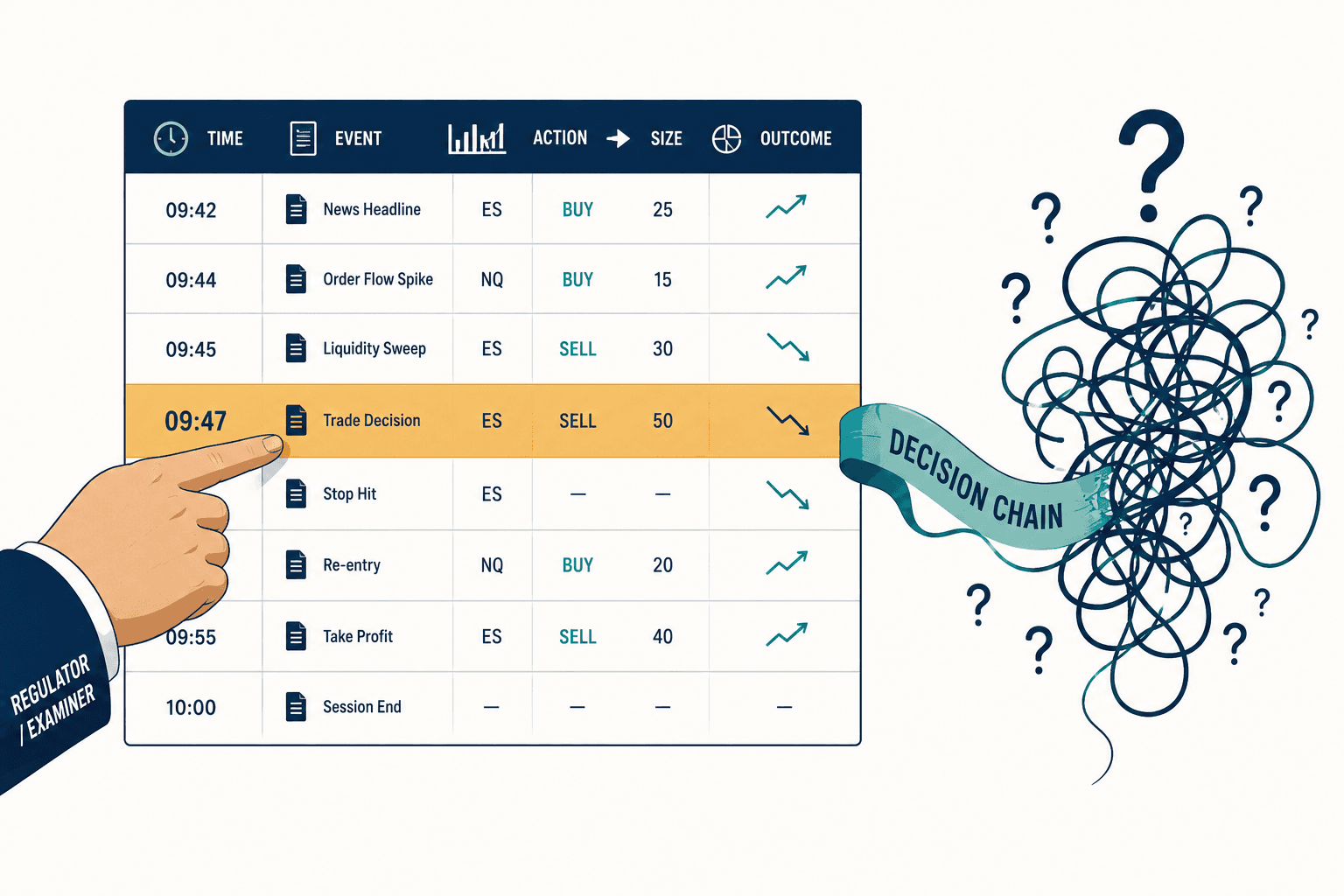
90% of AI Coverage Denials Get Reversed on Appeal. A Court Just Called That a Breach of Contract.
A family paid $16,768 out of pocket to keep their mother in a hospital bed.
She had methemoglobinemia — a blood disorder that starves the body of oxygen. The algorithm deciding her coverage did not know that, or rather, it knew and did not care. It had been trained to predict length of stay from her diagnosis group, and the average patient in that group was ready to go home. So the system flagged her for discharge on a population timeline while her actual blood oxygen told a different story. Her family found the money. Most families cannot — and most never even try: in the UnitedHealth litigation, only about 0.2% of Medicare beneficiaries appealed their denials at all.
That case sits at the center of Lokken v. UnitedHealth, the class action over nH Predict, the AI tool used to project recovery timelines in Medicare Advantage utilization management. And the number that should stop every health-plan executive cold is this: roughly 90% of the AI-generated denials in that litigation were reversed on appeal — among the sliver of members who bothered to contest them. When I first read that, my instinct was the same as most engineers' — a 90% reversal rate is a model-accuracy problem, something you fix with better training data and tighter thresholds. I was wrong, and the court told me why. A federal judge is treating that 90% not as a technical defect but as evidence of a breach of contract. That single reframing is what Medicare Advantage AI governance actually has to answer for, and it is the reason I ended up building a company around it.
A 90% appeal-overturn rate is not a tuning parameter. It is a confession that the system was never deciding medical necessity in the first place.
The lawsuit is about a sentence in your contract, not a flaw in your model
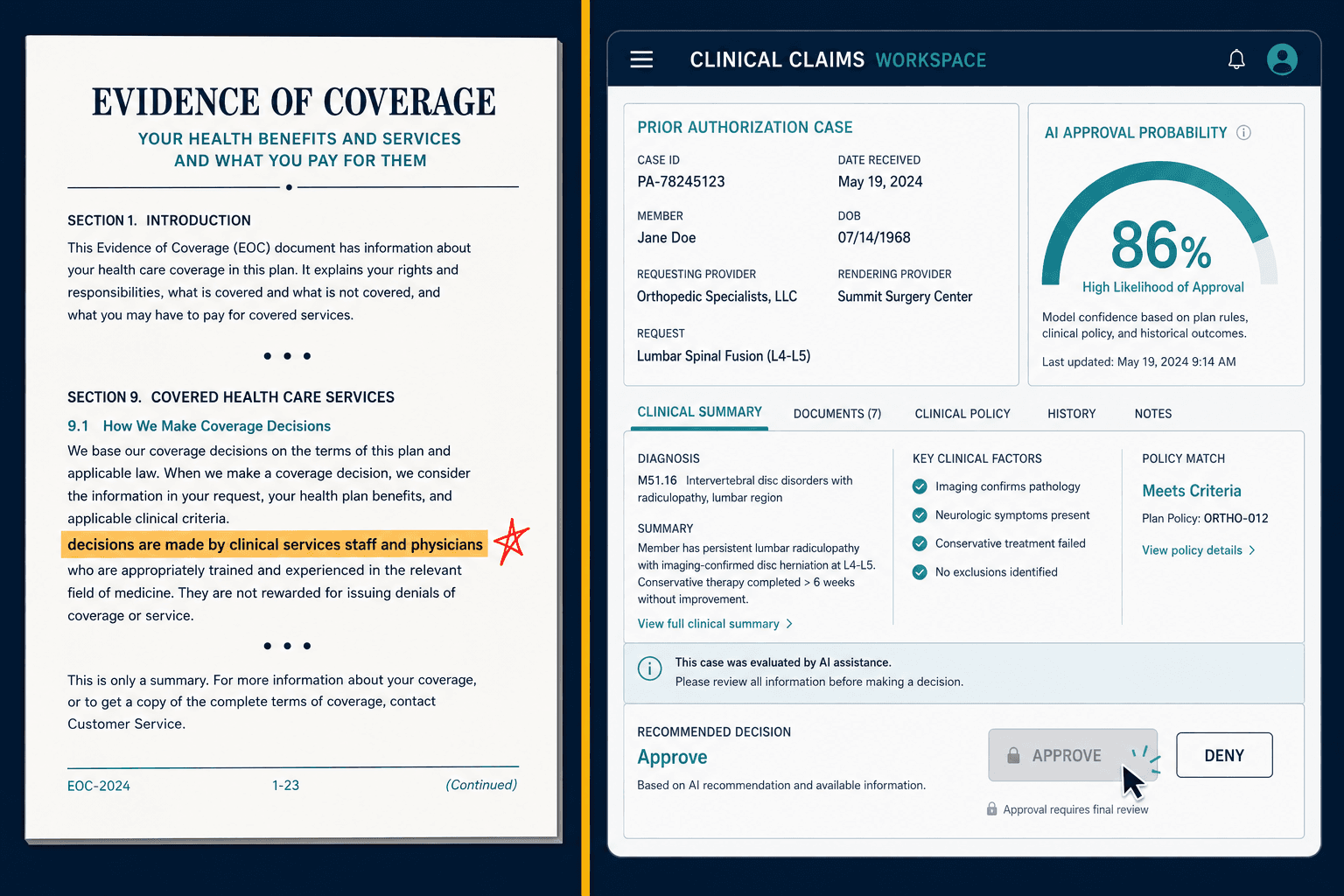
What took me embarrassingly long to understand is that the legal exposure in these cases does not live in the model weights. It lives in your Evidence of Coverage.
Your EOC — the contract every member signs — promises that coverage decisions are made by clinical services staff and physicians. That is the deal. When I started pulling EOC language for plans and laying it next to their actual auto-adjudication queues, the gap was almost always there in black and white. The contract says a doctor decides. The workflow shows an algorithm scoring the request and a human clicking approve on whatever it returns. Opposing counsel does not need a data scientist to find that gap. They need a paralegal and a highlighter.
The March 2026 discovery order in Lokken (2026 WL 658883) made this concrete. The court granted plaintiffs access to AI development documents, training-data specifications, and validation reports. I keep a printout of that order with one clause circled, because it changed how I talk to every plan: your AI documentation is now discoverable. If your model cannot produce a structured decision log, version-controlled training data, and documented validation results, you cannot reconstruct why you denied a claim — and you cannot defend what you cannot reconstruct.
The moment "human-in-the-loop" becomes a fiction
For a while I assumed the plans getting sued were reckless outliers running fully automated denials. The reality is more uncomfortable, and it is the detail I now lead with whenever a chief medical officer tells me they're safe because a clinician signs off.
The break happens at a single operational decision that no one outside the room ever sees. nH Predict's managers narrowed the acceptable variance from the model's projection from 3% down to 1%. On paper that is a tuning change. In practice it converted a decision-support tool into an automated gatekeeper, because clinicians who deviated more than a hair from the algorithm's number were now out of compliance. Some who overrode the system faced disciplinary action.
That is the instant the human-in-the-loop stops being a safeguard and becomes theater. A doctor whose job is at risk if she disagrees with the model is not exercising clinical judgment — she is rubber-stamping. And every denial that flows through a performative review carries the full contractual and regulatory liability of an automated one, because functionally that is what it is.
The variance band is buried in a committee's meeting minutes. That is where the lawsuit is won or lost, not in the model architecture.
I cannot count the number of governance conversations that skip right past this. Plans audit their model. They almost never audit the workflow policy that surrounds it — the threshold, the override rules, the disciplinary structure. That policy is what determines whether your clinician is a decision-maker or a liability shield that does not actually shield anything.
Why we built the wrong thing first
When my team started, we did the obvious thing. We built monitoring.
It made sense on a whiteboard. The market is full of AI observability — Fiddler ships SHAP and LIME explainability with drift and bias detection; IBM's Watsonx.governance has OpenScale for fairness; Credo AI and Holistic AI sell policy packs and compliance dashboards that auto-collect evidence. The logic of the whole category is: you have models in production, you bolt on a layer that watches them, and now you have governance. So we built a layer that watched a pilot plan's utilization-management AI and produced beautiful fairness metrics.
Then a medical director at that plan — someone who had sat on her own UM committee for years — looked at our dashboard and asked the question that sent us back to the drawing board. "This tells me the model is behaving consistently. It doesn't tell me the model should be making this decision at all. nH Predict was consistent too."
She was right, and it stung. We had built a very precise instrument for measuring a fundamentally flawed thing. nH Predict did not fail because it was unmonitored. It failed because it weighted diagnosis-group averages over individual clinical indicators — blood oxygen, caregiver availability, comorbidity interactions — in a domain where individual variation is the definition of medical necessity. Monitoring that model more closely would have produced a tidy record of a system reliably doing the wrong thing. The 90% reversal rate would have been beautifully documented.
That was the failure that paid for everything we built next. Observability tells you whether the model is stable. It does not tell you whether the decision is defensible. Those are different problems, and the entire governance-platform category was, for the buyer I cared about, solving the first one and calling it the second.
What Does Medicare Advantage AI Governance Actually Have to Do?
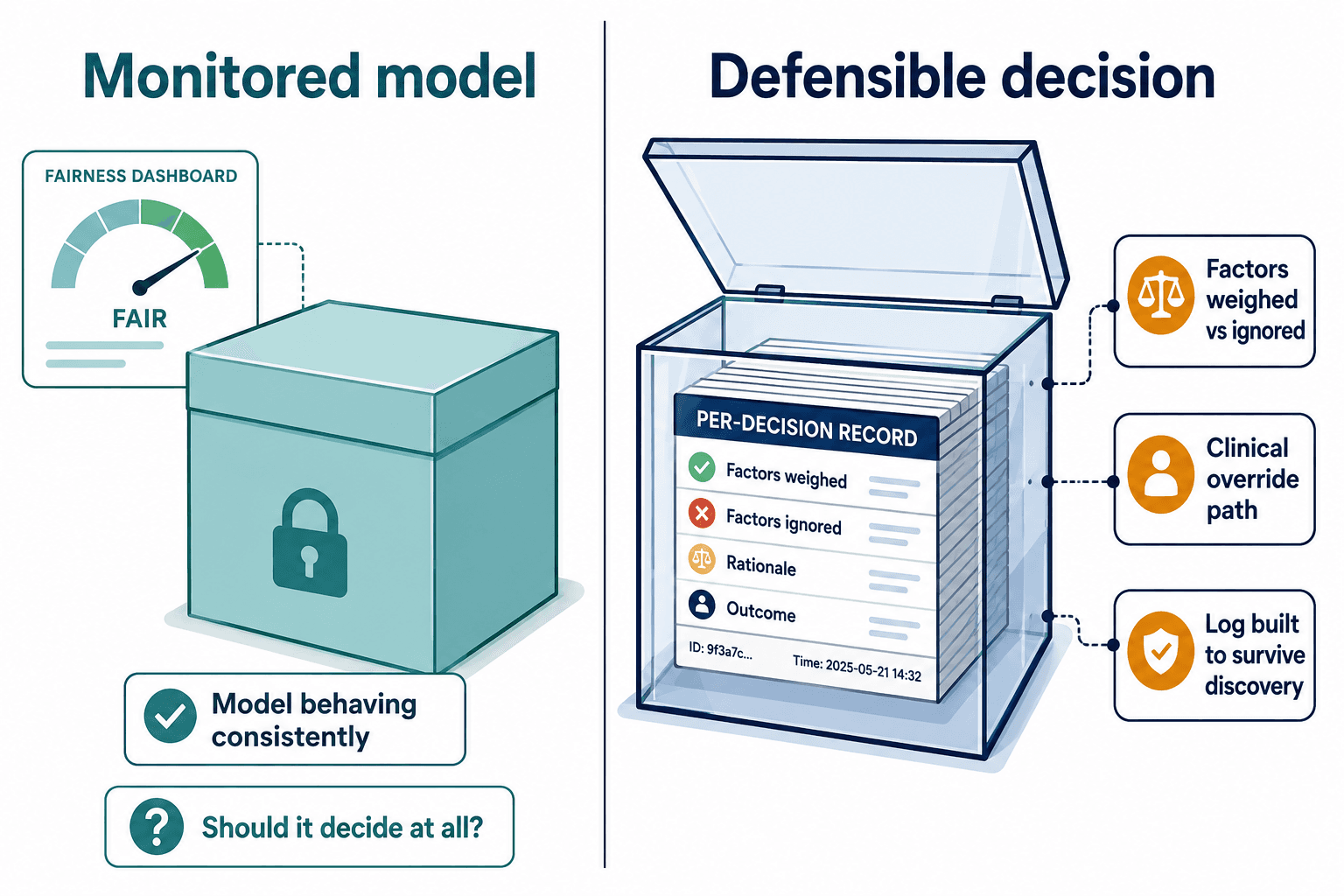
So we tore up the monitoring premise and started from the only question that matters in a courtroom: can you defend this specific denial of this specific person?
That reframe changes the build completely. You are no longer instrumenting a model — you are engineering a decision so that, years later, under a discovery order, it reconstructs itself. For a Medicare Advantage plan that means three things have to be true at once, and getting them true is the work Veriprajna does at veriprajna.com/solutions/medicare-advantage-ai-governance.
First, every decision has to carry its own explanation — not a global fairness score, but a per-decision record of which clinical factors the model weighed and which it ignored, in language a clinician and a judge can both read. This is the part everyone underestimates, and it is where I have to deliver bad news. The legacy claims platforms most plans run on — Facets, QNXT — were never designed to emit a per-decision feature-attribution record. They store the outcome, not the reasoning. So real explainability on a Medicare Advantage stack is not a matter of picking a better model off a shelf. It is middleware: a layer that captures the model's inputs, weights, and the clinical override path, and writes them to a log built to survive discovery. That is unglamorous integration work, and it is most of the job.
The harder requirement is that the compliance architecture has to map to the regulations arriving at the same time — which brings me to a trap I watched a sophisticated plan walk straight into.
The metric that looks clean and isn't
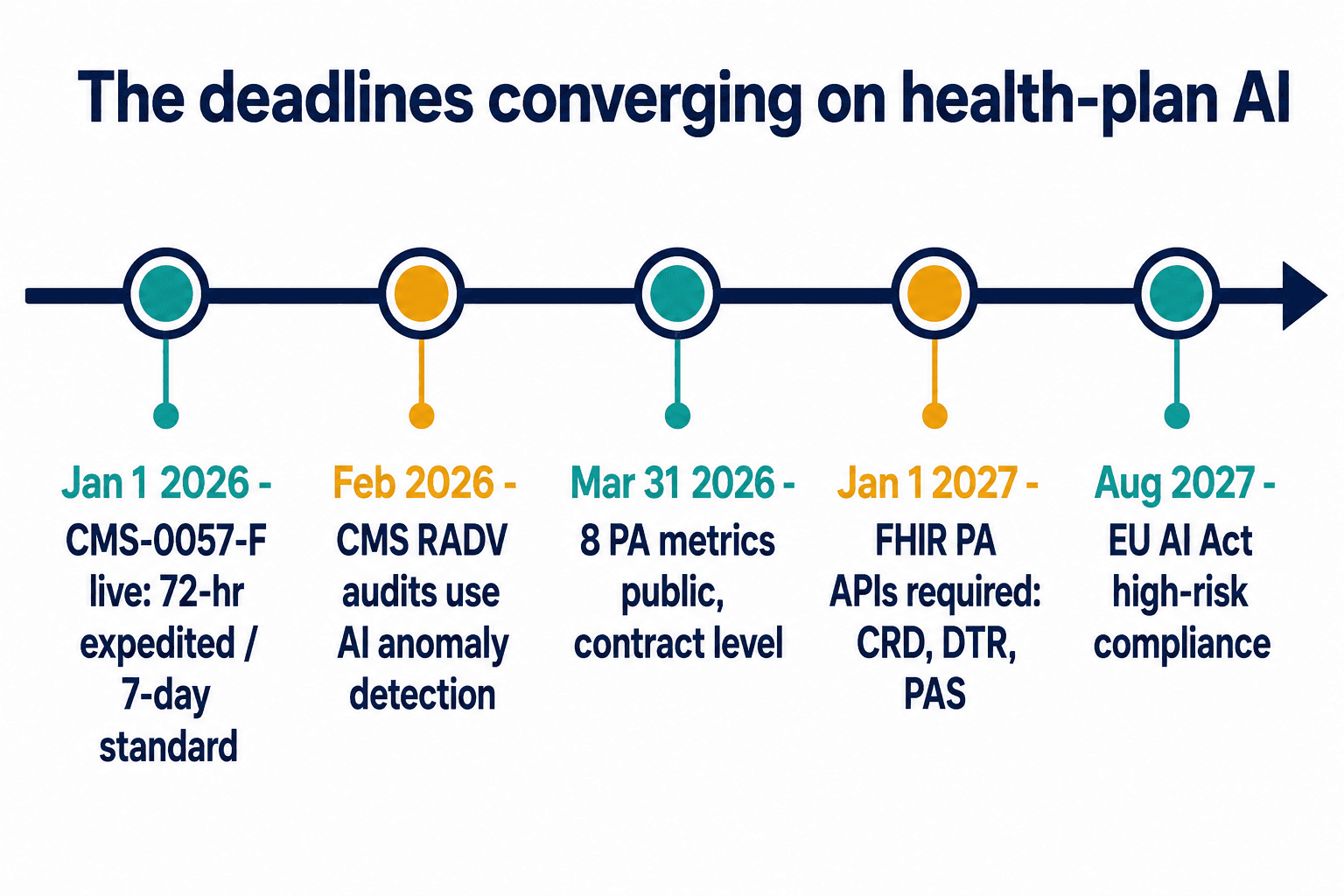
CMS-0057-F, the prior-authorization final rule, started biting in January 2026 — 72-hour turnaround on expedited requests, seven days on standard ones, no reopening approved inpatient admissions except for fraud. Then on March 31, 2026, the first public reporting deadline hit: plans had to report eight prior-authorization metrics at the contract level, including denial rates, turnaround times, and appeal-overturn rates.
The detail that matters is the kind of thing you only catch if you have read the Federal Register corrections, not just the headline. In June 2025, CMS suspended the plan-level breakdowns and the health-equity expertise requirements on UM committees. What remains public is aggregate, contract-level metrics. So a plan can publish a perfectly respectable contract-level appeal-overturn rate and look clean — while its individual decision logs, the ones a Lokken-style discovery order reaches straight into, tell an entirely different story.
The public metrics are the part you choose to show. The decision logs are the part a court takes. Governance has to win on the second, not the first.
I have sat across from executives who pointed at their March 31 filing as proof they were covered. The filing is necessary. It is not a defense. The plaintiff's bar is not reading your aggregate dashboard; they are subpoenaing the record behind one member's denial.
Then there is January 1, 2027, when the HL7 FHIR prior-authorization APIs — CRD, DTR, and PAS — become required, creating a full electronic transaction trail for every PA decision. That trail is either your best evidence or your worst, depending entirely on whether the reasoning was captured when the decision was made. You cannot backfill it later. I have an integration ticket open against a QNXT instance right now that is, in essence, a bet on which of those two futures a plan ends up in.
The patchwork no single platform was built for
And it has to survive a regulatory map that no off-the-shelf product covers. The first time I laid one multi-state client's obligations out on a single spreadsheet, the columns stopped agreeing with each other — and that is by design. The requirements are deliberately inconsistent.
The Texas Responsible AI Governance Act took effect in January 2026 with broad civil-investigative-demand power — and Texas had already shown its hand by settling the first healthcare generative-AI investigation, against Pieces Technologies, back in September 2024 over inflated accuracy claims. Pennsylvania has gone a different direction, with legislation requiring human provider review before any AI-driven denial, mandatory disclosure that AI is even in use, and annual compliance statements. A multi-state Medicare Advantage organization now faces a patchwork where each state wants different transparency, audit, and disclosure controls. And for any plan with global operations, the EU AI Act classifies healthcare AI as high-risk under Annex III, with full compliance due August 2027 and penalties reaching 6% of global annual turnover.
This is exactly the seam the big consultancies fall into. Deloitte and Accenture will deploy a packaged platform — a Credo AI or an IBM Watsonx — and call it governance. But a packaged platform does not know your specific Facets configuration, and it does not reconcile Texas's investigative demands with Pennsylvania's pre-denial-review mandate with the EU's risk-management-file requirement. The claims-system vendors are worse positioned still: the same companies that maintain Facets and QNXT also sell the AI add-ons for them, so they are not exactly incentivized to surface governance gaps in their own platforms. Nobody in that landscape was building the one thing the buyer needed — technical controls mapped, decision by decision, to every regulation that applies to them at once.
Why Can't a Plan Just Buy Explainability Software?
People ask me a fair question: if explainability and bias monitoring already exist, why can't a plan just buy Fiddler or stand up causal AI and be done?
Two reasons. The monitoring vendors are genuinely good at what they do — but their entire premise is that the model in production is the thing worth governing. When the model's decision architecture is the flaw, as it was with nH Predict, watching it more carefully just gives you a higher-resolution recording of harm. Causal AI — causaLens is the most credible name here — is the academically right answer, modeling cause instead of correlation, but it is commercially immature and aimed mostly at financial services; healthcare-specific causal models for coverage decisions are still largely research-stage. And the prior-authorization automation vendors like Cohere Health are optimizing the wrong variable entirely. Cohere will cut your PA administrative cost by 47%. That is a real number and a real benefit. But speed is not defensibility. A faster denial that you still cannot reconstruct in court is a faster path to the exact liability Lokken defined.
The other reason is scale, and it is the part I cannot talk a plan out of. Gartner expects 80% of ambulatory claims to be processed through AI-enabled real-time adjudication by 2028. Yet only 12% of U.S. hospitals have a formal AI governance framework today, by Censinet's count. The volume of automated coverage decisions is about to multiply far faster than anyone is building the infrastructure to defend them. And CMS is not waiting politely — its Payment Year 2020 RADV audits began in February 2026 using AI-powered anomaly detection to flag unsupported diagnoses. The regulator is auditing your AI with AI while requiring you to govern it yourself.
The plans that move first turn this into an advantage
I want to end on the thing I actually believe, not a warning.
Every plan I talk to treats governance as a cost — a tax on deploying AI, a brake on the agentic automation everyone wants. I understand the framing. The admin economics are brutal from both sides: providers spend $19.7 billion a year fighting denials, and plans carry their own cost on every contested claim. The temptation is to automate harder and govern as little as the rule requires.
But that math runs backward. The denials that get reversed on appeal were never cost savings — they were liability the plan booked as revenue and will pay back with interest in court. A plan that can produce, for any denial, a clean record of which clinical factors were weighed, signed by a clinician who genuinely had the freedom to disagree, mapped to every regulation that applies, does not just avoid the lawsuit. It can deny faster and with more confidence, because each decision is built to survive the scrutiny that is now coming as a matter of routine. We built the Medicare Advantage AI governance architecture for exactly that plan.
The methemoglobinemia patient's family did not lose because an algorithm made a mistake. They lost, temporarily, because the system could not explain itself and no human in the loop was free to overrule it. Build the system so it can explain itself, and free the human to overrule it, and you are no longer hoping the discovery order never comes. You are ready for it.