Every Tax AI I Tested Got the Same Deduction Wrong — Because the Internet Did
I had two monitors open. On the left, the statute: Internal Revenue Code Section 63(b)(7), the provision the Omnibus Budget Reconciliation Act used to create a new deduction for interest on qualified passenger vehicle loans. On the right, H&R Block's own website, describing that same deduction as an "above-the-line incentive."
Those two screens cannot both be right. Section 63(b)(7) reduces taxable income — it is a below-the-line deduction. It does not touch adjusted gross income. "Above-the-line" means the opposite. One of the largest tax-prep brands in America had the direction of a deduction backwards on its public site, and as of April 2026 it still did.
That would be a footnote, except for what happened when I started asking AI about it. I put the question to several leading large language models — the same tax compliance AI tools that firms are now wiring into return preparation. Every one of them told me, with clean grammar and a plausible citation, that the deduction was above-the-line. They had all read the same internet. And the internet was wrong.
When every AI gives you the same wrong answer, it's not a glitch. It's the training data voting, and the truth losing.
That was the moment the company I was building came into focus. The industry was racing to make AI prepare tax returns faster. Almost no one was building the thing that catches it when the AI is confidently, systematically wrong. That gap is what Veriprajna's tax compliance AI verification layer exists to fill.
The Error That Cascades
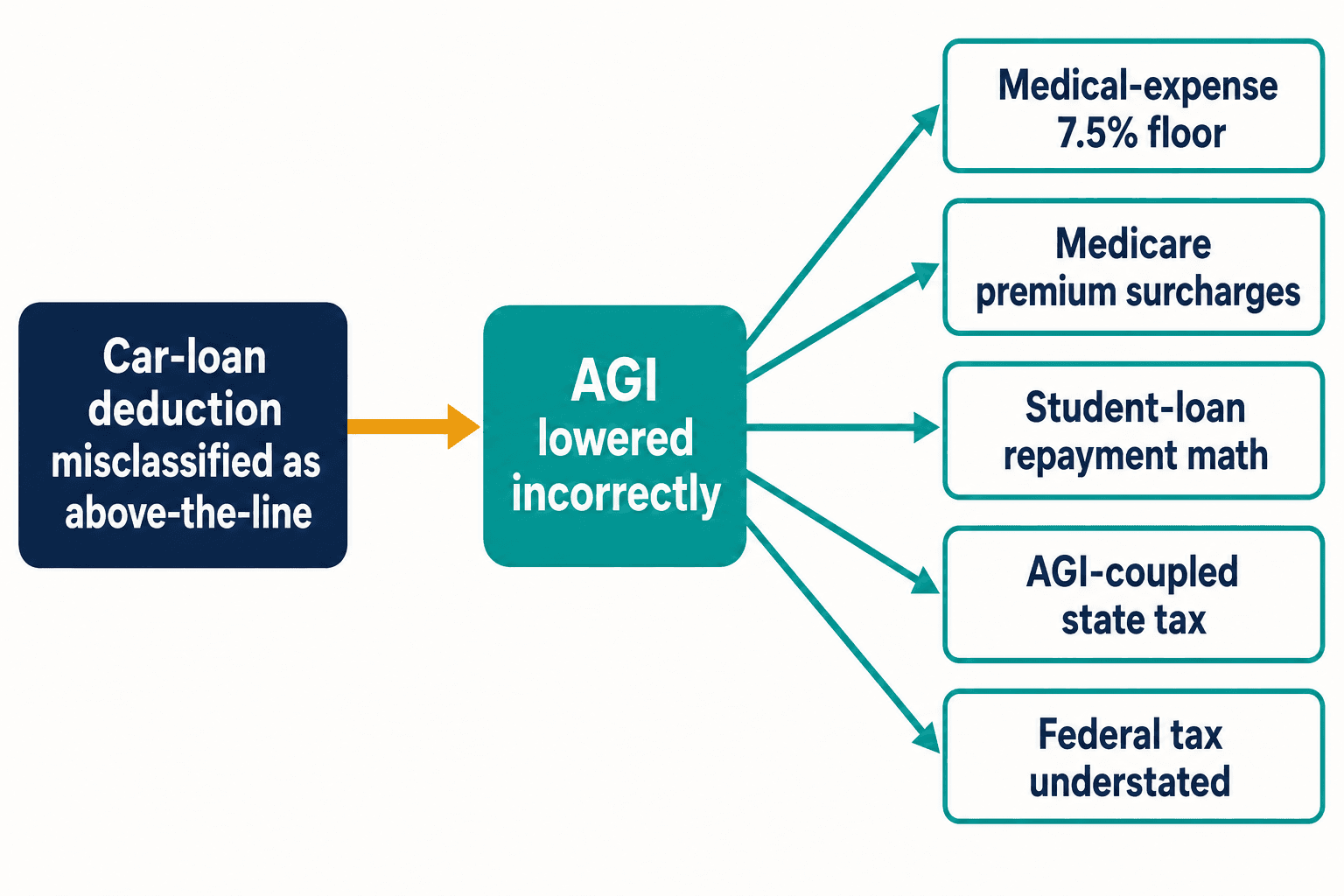
Here's why a single backwards deduction kept me up. A misclassification like the car-loan one doesn't stay contained. Treat that deduction as above-the-line and you lower adjusted gross income that should never have moved. AGI is load-bearing in the tax code. It feeds the medical-expense deduction floor of 7.5%. It feeds Medicare's income-related premium surcharges. It feeds the income-driven repayment math on student loans. In states whose tax is coupled to federal AGI, it quietly understates state tax too.
One wrong token, five downstream miscalculations — and that's from a single provision. The Internal Revenue Code has thousands. Congress made an average of 420 changes a year to it between 2000 and 2020, according to the Taxpayer Advocate Service. Every fresh change is a fresh opportunity for the blogosphere to get there before the official guidance settles, and for the next generation of models to learn the wrong version by sheer repetition.
And the person who pays is not the algorithm. When a return is wrong, the 20% accuracy-related penalty under the IRS manual lands on the human whose name is on the signature line, signed under penalty of perjury. The model that drafted it has no PTIN and no liability. I kept coming back to that asymmetry. We were about to hand the drafting to machines and leave the exposure with people.
Why I Stopped Believing Retrieval Would Save Us
My first instinct was the same one everyone has: feed the model the actual law. Retrieval-augmented generation — RAG, where the system looks up the real statute and hands it to the model before it answers — was supposed to be the fix. Blue J, which raised a $122M Series D, built exactly this: RAG on top of GPT-4.1, with an IBFD partnership spanning 220+ jurisdictions. Serious engineering by serious people.
So we built a retrieval prototype of our own. And I watched it pull up the correct text of Section 63(b)(7) — and then summarize it wrong anyway.
That was the demo that broke my assumption. The retrieval worked. The interpretation didn't. Amendment language in the tax code reads like "Section 163(h) is amended by inserting…" — you have to reconstruct the current state of the law from fragments, and a model whose internal weights have absorbed millions of "above-the-line" blog posts acts as a biased reader. It sees the right statute and still hears the wrong consensus. Handing a probability engine the correct document does not make it reason; it just gives a confidently wrong answer a better-looking citation.
Retrieval gets the model the right text. It does nothing about the model having already made up its mind.
We started calling this Consensus Error — when every AI converges on the same wrong answer because the public record it learned from is itself wrong. It's not hallucination in the usual sense. A hallucination is random. This is systematic, repeatable, and shared across every model trained on the open web. That distinction changed how I thought about the whole problem.
"Just Wrap GPT and Ship It"
There was a stretch where I genuinely wondered if I was overcomplicating it. An advisor I respect told me, more or less, to stop philosophizing — wrap a good model, add retrieval, ship it, let the market decide. Plenty of well-funded companies were doing precisely that.
The argument we had came down to one number that gets quoted constantly: Blue J reports a disagree rate under 1 in 700. It sounds like an accuracy figure. It isn't. It measures how often users disagree with the tool — and a practitioner who doesn't already know the correct answer cannot disagree with a wrong one. The metric is silent exactly where the danger lives: the confident, plausible, wrong answer that nobody on the other side has the knowledge to challenge.
A disagreement rate measures the users' confidence, not the model's correctness. On a high-penalty position, those are not the same thing — and the gap between them is where the penalty lives.
I lost sleep over whether "probably right" was a product. On a question of formatting, it is. On a tax position where the accuracy penalty is 20% of the underpayment and the fraud penalty is 75%, "probably right" is a liability you've automated and scaled. That was the argument that ended the wrap-GPT plan. Probabilistic is the wrong tool for a deterministic question, no matter how good the probabilities get.
What Does Deterministic Verification Actually Buy You?
The vendors who get this best aren't the chatbots — they're the indirect-tax engines. Vertex maintains over 300 million tax rates. Avalara, which took a $500M BlackRock investment in late 2025, and Sovos run filing across more than 12,000 jurisdictions. For the scenarios they cover, they're 100% deterministic with full audit trails. Ask them the same rate question a thousand times and you get the same answer a thousand times, and you can show an auditor exactly why.
But those engines can't read a sentence. They can't reason about a facts-and-circumstances test, and adding a new rule means a human encoding it by hand. So the field splits cleanly: the engines that are reliable can't understand language, and the systems that understand language aren't reliable.
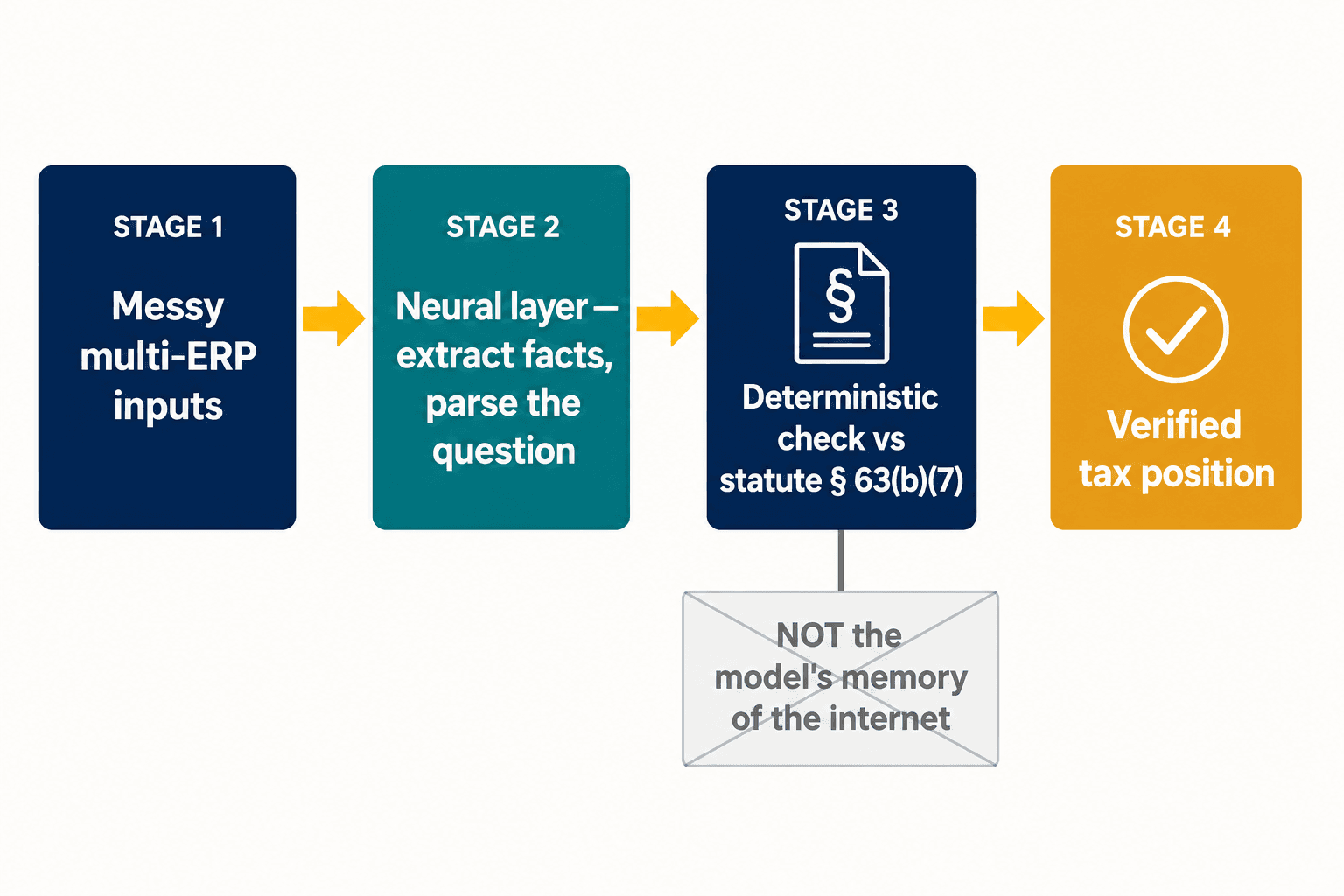
That split is the whole design problem, and it's where we landed our architecture. We don't try to make one model both creative and certain. We let a neural layer do what neural models are good at — reading messy inputs, extracting structured facts from a return, parsing what a practitioner is actually asking. Then, for the provisions where correctness is non-negotiable, the answer is checked against a deterministic representation of the statute itself, not against the model's memory of what the internet said about it. The car-loan deduction lives below the line because Section 63(b)(7) says so, full stop — not because the model weighed the evidence and the evidence happened to be wrong.
The point isn't to replace Thomson Reuters or Wolters Kluwer. CCH Axcess Expert AI is embedded across 10,000 firms; ONESOURCE claims a 65% reduction in routine reporting time. Those tools are good at preparation, and preparation is largely a solved problem now. The verification layer sits on top of whatever you already run, vendor-neutral, and catches the systematic errors before they reach the IRS. Thomson Reuters verifies Thomson Reuters. Wolters Kluwer verifies Wolters Kluwer. Nobody was verifying across all of it, against ground truth, for the positions that actually carry penalties.
For large multinationals the problem compounds before the AI ever opens its mouth. Roughly 78% of companies run four to seven different ERP systems, and EY found half of tax leaders cite the lack of a sustainable data and technology plan as their single biggest barrier. Layer on Pillar Two — the global minimum-tax regime that demands entity-level data and reliable intercompany reporting, which only about 15% of organizations in some regions report being fully ready for — and the weakest link isn't the model's reasoning at all; it's whether the structured facts feeding it are right in the first place. That's the other half of the work: the neural extraction layer that turns messy multi-system inputs into something either an AI or a deterministic engine can trust.
Why Is Tax AI Suddenly a Privilege Question, Not a Security One?
For a while I thought of the closed-system requirement as a security preference — nice to have, enterprise hygiene. Then in February 2026 the SDNY handed down the Heppner ruling, and it stopped being optional.
The short version: pasting a client's facts into a public AI tool can waive attorney-client privilege over those communications. For a tax department, that reframes everything. The choice between a public chatbot and a closed, enterprise-controlled system is no longer about data hygiene — it's about whether your privileged analysis stays privileged. The IRS reinforced the direction the same season: its AI governance policy, IRM 10.24.1, now classifies generative-AI outputs that serve as the principal basis for a decision with legal or material effect as "high-impact," demanding enhanced oversight. The regulators are telling you, in their own language, that an unverified AI tax position is a high-impact risk.
Post-Heppner, the architecture you choose for tax AI is a privilege decision before it's an engineering one.
This is not a hypothetical harm. Accountancy Age reported in March 2026 that half of UK accountants were aware of businesses suffering direct financial losses from incorrect AI advice. Researchers have logged roughly 800 AI citation-error cases across 25 countries. Meanwhile the IRS is raising its large-corporate audit rate from 8.8% toward 22.6%. More AI-drafted positions, more audits, and a penalty that lands on the signer — that's the collision course.
The Objections I Hear Most
People ask me whether better models will just solve this on their own. They won't, and not because the models aren't improving. Consensus Error is a property of the data, not the model size. A bigger model trained on the same wrong internet learns the wrong answer more fluently, not less. You can't out-scale a problem that scales with you.
The other thing I hear: isn't a deterministic layer just brittle hard-coded rules that can't keep up with 420 code changes a year? It would be, if we tried to encode the entire code. We don't. The verification layer targets the high-penalty, high-cascade provisions — the handful where being confidently wrong costs real money — and leaves the routine ninety percent to the preparation tools that already handle it well. You don't need certainty about everything. You need certainty about the things that bite.
And every so often someone asks why a tax department should build this rather than wait for one of the Big Four. EY is targeting 80% automation of foreign tax compliance; KPMG launched a Tax AI Accelerator in February 2026. But those tools are built for the firm's own engagements, sold inside six-and-seven-figure projects, and they verify the firm's work — not yours. The verification layer you actually control is the one that protects the signature you actually sign.
What I'd Tell My Earlier Self
Tax compliance costs US businesses more than $126 billion a year, and the industry is right to throw AI at that number. Preparation should be automated. The mistake is assuming that once the AI can draft the return, the job is done — when in fact the bottleneck just moved downstream, to verification, where it's harder to see and more expensive to get wrong.
I started this thinking the hard part was teaching a machine tax law. The hard part turned out to be the opposite: knowing which questions a machine should never be allowed to guess at, and building the layer that refuses to let it. The day every tax tool runs on AI, the only real question left is who checks the AI — and "the same AI, asked more politely" is not an answer. If you want to see how we built that check, it's here.
The internet was wrong about a car-loan deduction, and every machine that learned from it inherited the error without blinking. Somewhere in the code there are thousands more of those, waiting. The work isn't making AI smarter. It's making sure that when the whole world is confidently wrong, your tax position isn't.