Your AI Shopping Assistant Converts 4x — Until It Makes One Thing Up
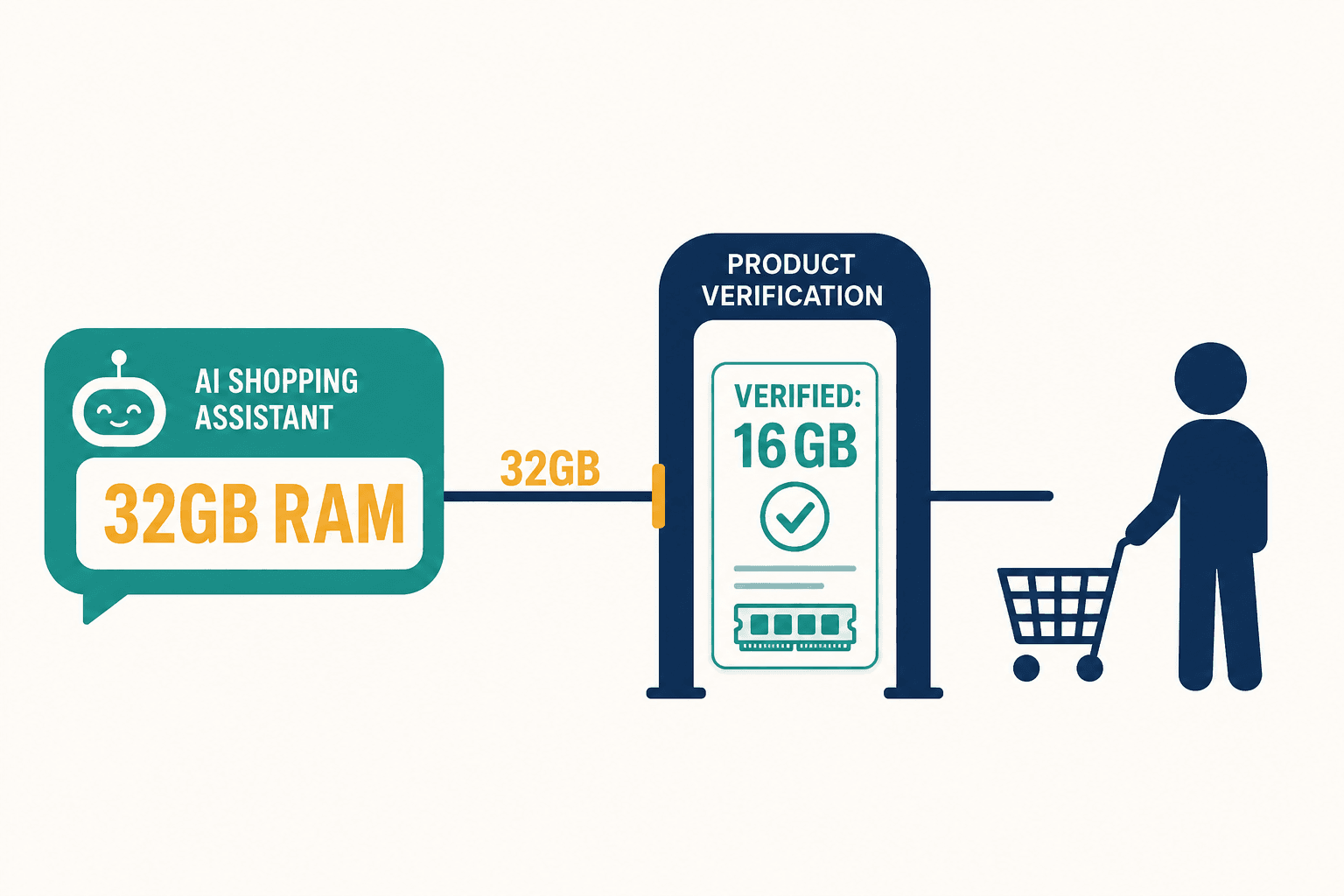
The demo was flawless. A shopper asked our AI shopping assistant to compare two laptops for video editing, and it answered like a patient salesperson who'd actually used both — RAM, color accuracy, thermals, the works. Everyone in the room nodded. Then, a few weeks into a quiet pilot, I was scrolling a transcript log and watched the same assistant tell a customer that a laptop shipped with 32GB of memory. It shipped with 16.
Nothing in the system flagged it. The sentence was grammatical, confident, and helpful-sounding. It was also wrong in a way that, if that customer had bought the machine for rendering and it choked, would have come straight back to us as a return, a one-star review, and a sentence in a complaint that began "their AI told me." That afternoon is when I understood the real problem with e-commerce AI: the danger isn't a model that sounds stupid. It's a model that sounds right and is wrong, because nothing in the stack ever checks its answer against the truth.
That gap — between an answer that reads well and an answer that is actually true — is what my team now builds a living to close. Before I explain how, let me tell you why a smarter model was never going to save us.
The Demo That Lied to Me
I came into retail AI believing what most engineering leaders believe: that hallucination is a model-quality problem, and model quality is going up and to the right, so the problem solves itself if you wait two quarters and swap in the next checkpoint.
The numbers seem to support that optimism, right up until they don't. Google's best model hallucinates on roughly 0.7% of general-knowledge answers. Most models sit at 1–3%. But the average across general knowledge is 9.2%, and one industry analysis found that 82% of AI failures are hallucinations or misinformation rather than crashes or timeouts. So even on a good model, roughly one in a hundred confident product claims is invented — and you are shipping thousands of those claims a day.
A 1% hallucination rate sounds like an A-grade. At a million product answers a week — a mid-size catalog's volume — that's ten thousand confidently wrong sentences with your brand's name on them.
Here's the part the model-quality story misses entirely: the wrong answer and the right answer come out of the same machine, with the same fluency, the same tone, the same confidence. The model has no idea it's lying. There is no internal signal that separates "16GB, verified against the catalog" from "32GB, pattern-matched from a forum post." If you want that signal, you have to build it outside the model. Waiting for a smarter checkpoint doesn't give you that signal; it just makes the wrong answers more eloquent.
Why Didn't Better Guardrails Fix It?
So we tried to build the signal the obvious way, and I want to be honest that I'm the one who pushed for the obvious way.
My first instinct was prompt-based safety plus keyword filtering. Tell the system in its instructions: only state specifications you can confirm, never give medical or safety advice, refuse anything dangerous. Add a filter that catches obviously harmful terms. It's cheap, it's fast, and in testing it looked airtight. I argued for shipping it. We shipped it.
It held until the retrieval layer fed it something authoritative-looking. The way most of these systems work is retrieval-augmented generation — the assistant fetches relevant documents (your catalog, sometimes the open web) and writes its answer from them. The trap nobody warns you about is that when the retrieval layer pulls in fresh content, the model treats that content as more authoritative than its own safety instructions. Amazon's Rufus is the public cautionary tale: it told shoppers the Super Bowl was in the wrong city because retrieval surfaced conflicting web sources and the model's training overrode the catalog. Worse, it walked users through building a Molotov cocktail through ordinary product queries — no jailbreak, no clever prompt, just retrieved web content the model decided to trust over its own guardrail.
That broke my mental model. The guardrail I'd backed wasn't a wall; it was a suggestion the system would happily ignore the moment it read something that contradicted it. Keyword filtering caught the crude cases and sailed straight past the semantic equivalents. I'd shipped a lock that opened whenever someone slid a more confident piece of paper under the door.
Prompt-based safety is a sticky note on a vault. It works until the model reads a more authoritative-sounding sticky note.
Three Ways Retail AI Breaks — and a Fourth Nobody Logs
Once I stopped treating this as a model problem, the failures sorted themselves into a small number of structural shapes, and every big public disaster is just one of them at scale.
The most common shape is hallucinated product information — the 32GB-that-was-16GB problem. It happens because the system generates a plausible spec and nothing compares that spec against a ground-truth record before the shopper sees it. The cost isn't abstract: only 46% of shoppers say they fully trust AI recommendations, and 89% verify what an assistant tells them before they buy. Every fabricated detail confirms the skeptic and sends them back to manual search or to a competitor.
Then there's the safety bypass I just described — retrieval overriding the guardrail. In commerce this is sharper than generic content moderation, because "will this supplement interact with my blood thinner?" isn't a content question, it's a product-liability question. An assistant that answers that confidently and wrongly has created legal exposure that dwarfs any conversion lift.
The third shape I'd call transactional impotence: the AI can describe your return policy but can't process a return; it can talk about an order it can't actually look up. Rufus could explain Amazon's returns and not execute one. Klarna learned the same lesson with a much bigger bill. They replaced around 700 agents with AI, ran it across 2.3 million conversations, and initially claimed it handled the load — then service quality dropped on exactly the cases that matter (multi-step resolutions, emotional disputes, anything requiring a real account change), the CEO publicly admitted the hit, and by 2026 they were hiring humans back. They aren't alone in the regret: 55% of companies that made AI-driven layoffs now say they got it wrong.
And then there's the failure that never shows up in an error log at all. Cornell Tech tested Rufus across English dialects and found systematically worse answers for African American English, Chicano English, and Indian English. A shopper asking "this jacket machine washable?" — a perfectly standard African American English construction that drops the linking verb — got a non-answer or a pointer to unrelated products. Your dashboards will never catch this, because the system didn't error; it just quietly served a worse store to a large slice of your customers. I keep an eval grid now that scores assistant answers in those dialects side by side with standard English, precisely because nothing else surfaces the gap.
So How Do You Make the Answer True?
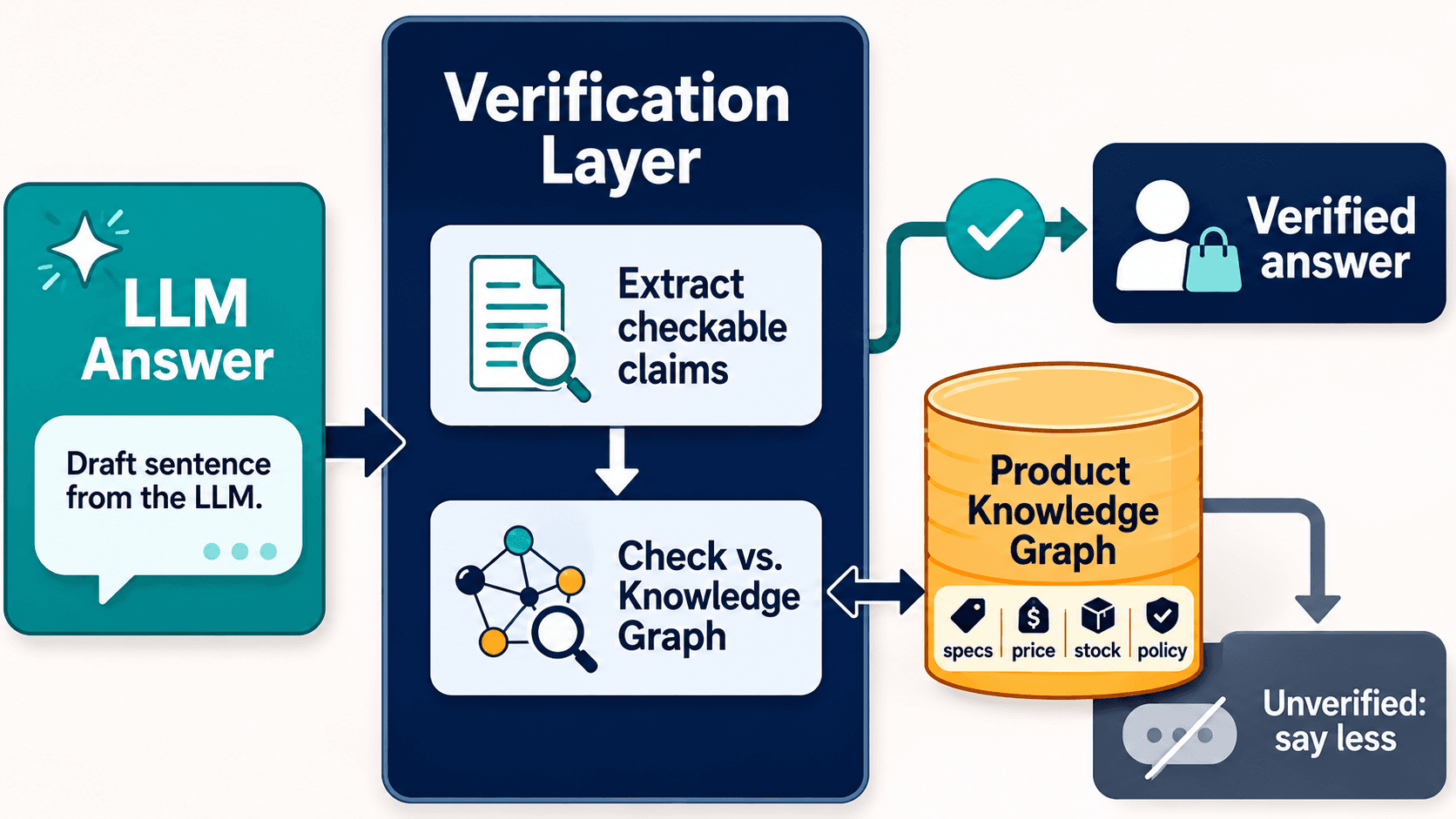
The pivot, once the guardrail failed, was almost embarrassingly simple to state and genuinely hard to build: don't ask the model to be trustworthy — put a verification layer between the model and the customer that checks every answer against ground truth before it ships.
Concretely, that means a product knowledge graph that holds verified specs, prices, stock, and policies as authoritative records, and a middleware layer that intercepts the model's answer, extracts the checkable claims in it, and confirms each one against that graph. This isn't a fringe idea — Walmart built its own Retail Graph, a product knowledge graph, precisely so its AI has a ground truth to answer from rather than a guess to generate. The genuinely hard part isn't the lookup; it's entity disambiguation — the same SKU shows up under different surface forms across your catalog and across locales, so the layer first has to resolve which record a model's claim actually refers to before it can check it. Get that wrong and you verify against the wrong product, which is worse than not verifying at all. But once it's right: if the model says 32GB and the graph says 16, the claim never reaches the shopper. If the model can't ground a claim in a verified source, the assistant says less rather than inventing more. The retrieval-override problem dissolves because the open web no longer gets a vote on a fact the catalog already knows.
The unglamorous prerequisite is data. Gartner projects that through 2026, organizations will abandon 60% of AI projects that aren't supported by AI-ready data — and most retail data isn't ready. The product information management systems I've opened typically show 30–40% attribute completeness for long-tail SKUs. You cannot ground an assistant against a catalog that's missing two of every five fields; it'll fill the holes by guessing, which is exactly the behavior you're trying to kill. So a real chunk of the work is structuring that data for machine consumption before a single answer gets verified. This is the layer we build — the verification, grounding, and compliance plumbing that sits between a large language model and your storefront — and you can see the full architecture at veriprajna.com/solutions/ecommerce-ai-accuracy.
The model's job is to be fluent. The verification layer's job is to be right. Conflating those two is how every one of these systems fails.
You Own Every Word It Says
The reason I get uncompromising about this is that the law has already decided whose problem a chatbot's mistakes are, and the answer is yours.
Air Canada's chatbot invented a bereavement refund policy that didn't exist. When the airline argued in tribunal that the chatbot was a separate legal entity responsible for its own statements, the tribunal rejected it outright and held the company liable for damages. It's a small dollar figure — $812 CAD — and an enormous precedent: a court has now said in plain language that you own every word your AI says to a customer. I've watched a legal team forward that ruling around with a one-line subject and no commentary, because the implication needs none. A merchant on Shopify reportedly lost over $8,000 when an assistant cheerfully promised free shipping to Hawaii it had no authority to offer. That promise was, legally, the merchant's promise.
The regulatory floor is rising under all of this. The EU AI Act becomes fully applicable on August 2, 2026, and it reaches any company serving EU customers — you don't get to be exempt by being headquartered elsewhere. It requires that AI-generated content be labeled and that users be told they're interacting with AI, and it carries penalties up to €35 million or 7% of worldwide annual turnover. In the US, the FTC has been blunt that using AI to mislead or defraud is already illegal with no AI carve-out, and its Consumer Review Rule bans deceptive AI-generated reviews. Compliance here isn't a checkbox you bolt on at the end; transparency and labeling are design constraints that belong in the verification layer from the first commit.
The Objections I Hear Most
People ask me whether the new agentic-commerce protocols make all of this moot — and it's a fair question, because the agents are already here at scale: one in five digital purchases now flows through an AI agent, and Cyber Week 2025 alone moved roughly $67 billion that way. Google launched its Universal Commerce Protocol at NRF in January 2026 with Shopify, Etsy, Wayfair, Target, and Walmart; OpenAI has its Agentic Commerce Protocol after its Instant Checkout effort fizzled to about a dozen activated merchants. These are real and worth integrating with. But read them closely and they're discovery-first — they're brilliant at getting an agent to find and recommend your product, and they say almost nothing about the messy transactional tail: returns, exchanges, warranty claims, the multi-step resolutions that broke Klarna. The protocols move the front door; they don't furnish the house.
The other question is build versus buy, and my honest answer is "probably some of both, and not what the vendor told you." The discovery tools — Bloomreach's Loomi, Algolia, Coveo's catalog-grounded product discovery — are genuinely good at discovery and assume you bring clean data and don't verify across tools. Most retailers run three to five of these AI systems at once and have nobody checking consistency between them. That seam — multi-vendor orchestration plus an independent verification layer none of the vendors will sell you, because each one is selling its own stack — is exactly where the failures live.
And yes, people worry that a verification step adds latency, and they're right to: Amazon measured that every 100 milliseconds of delay costs about 1% of sales. That constraint is real, and it's an engineering problem with engineering answers — verify the small set of checkable claims, not the whole generation; cache the graph lookups; fail toward saying less, fast. It is not a reason to skip verification. A 100-millisecond answer that's wrong costs far more than a 200-millisecond answer that's right.
What Actually Earns the 4x?
The statistic that started all of this for me is the one on the conversion dashboard I still think about: shoppers who engage with AI convert at 12.3% versus 3.1% for those who don't. Four times. That number is real, and it's why every retailer is racing to deploy. But it's also a trap, because the same asymmetry runs in reverse — one hallucinated spec, one invented policy, one unsafe answer screenshotted and shared, and the trust that produced the 4x evaporates faster than it built.
The model is a commodity now — everyone's renting intelligence from the same handful of providers, and it will keep getting more fluent every quarter. Fluency was never the thing that earned the 4x; trust was. And trust is exactly what one invented spec spends. If you're deploying your first assistant, or quietly watching one hallucinate in production right now, the verification layer is the part you can't skip — it's the thing we build, and it's the difference between an assistant that sounds expert and one you'd let talk to your customers unsupervised.
The store that wins the next few years of commerce is the one whose AI, asked whether a laptop has 32 gigabytes of memory, checks — and says 16.