1,500 Megawatts Vanished in 82 Seconds — And the Grid Operators Never Saw It Coming
On July 10, 2024, a lightning arrestor failed on a 230-kilovolt line near Fairfax, Virginia. Within 82 seconds, roughly 1,500 megawatts of data center load — about a third of all the households in Virginia, in electrical terms — simply disappeared from the grid. Grid operators scrambled to ramp down 600 megawatts of gas plants in Pennsylvania and pull 300 megawatts off a nuclear unit just to keep the frequency from surging high enough to damage equipment.
I spent a long evening with the NERC incident-review PDF after that, and the thing that has stayed with me is what didn't happen. There was no voltage violation. The fault triggered an automatic protection sequence — the line tried to re-close three times from each end, producing six brief voltage dips over those 82 seconds. Every single dip stayed inside the ANSI C84.1 normal band of plus-or-minus 10 percent. By the book, nothing went wrong on the wire.
What went wrong was firmware. Most data center uninterruptible power supplies run a "three-strike" rule: three voltage disturbances inside one minute and the system transfers the whole facility to diesel. The re-closing sequence hit that threshold across roughly 60 data centers at once. The grid didn't fail the data centers. The data centers walked off the grid, in lockstep, because of a counting rule nobody outside the buildings knew existed.
The grid stayed inside spec for all 82 seconds. The data centers left anyway.
That event is why Veriprajna built a data center grid interaction system — AI that orchestrates how a facility responds to grid signals, participates in capacity markets, and proves its flexibility to regulators. But I didn't start there. I started, like almost everyone in this space, by solving the wrong problem.
What Did I Get Wrong First?
The obvious read of the byte blackout is "the UPS reacted too fast." So our first prototype was a smarter reactive layer — software that watched grid frequency and voltage and made the facility's UPS fleet behave like a good citizen during a disturbance. Disconnect cleanly, ride through the transient, reconnect on a stagger instead of all at once. It demoed beautifully. Frequency wobbles, the system holds, everyone nods.
It was also nearly useless, and the person who made me see that was an energy lead at a colocation provider who looked at our 30-second ride-through feature and asked what it did for his capacity bill.
Nothing. It did nothing for his capacity bill.
Because the disturbance is not where the money or the regulatory pressure lives. Schneider Electric already ships a Fast Frequency Reserve capability that lets a data center disconnect for up to 30 seconds to support grid stability. Eaton sells bidirectional UPS systems built for exactly this twitch-speed response. That layer of the problem has vendors. What none of them had — what the colo operator actually needed — was something that worked on the timescale of hours and auctions, not seconds.
A 30-second reflex doesn't help you when the threat is a 24-month price curve.
The Number That Reorganized Everything
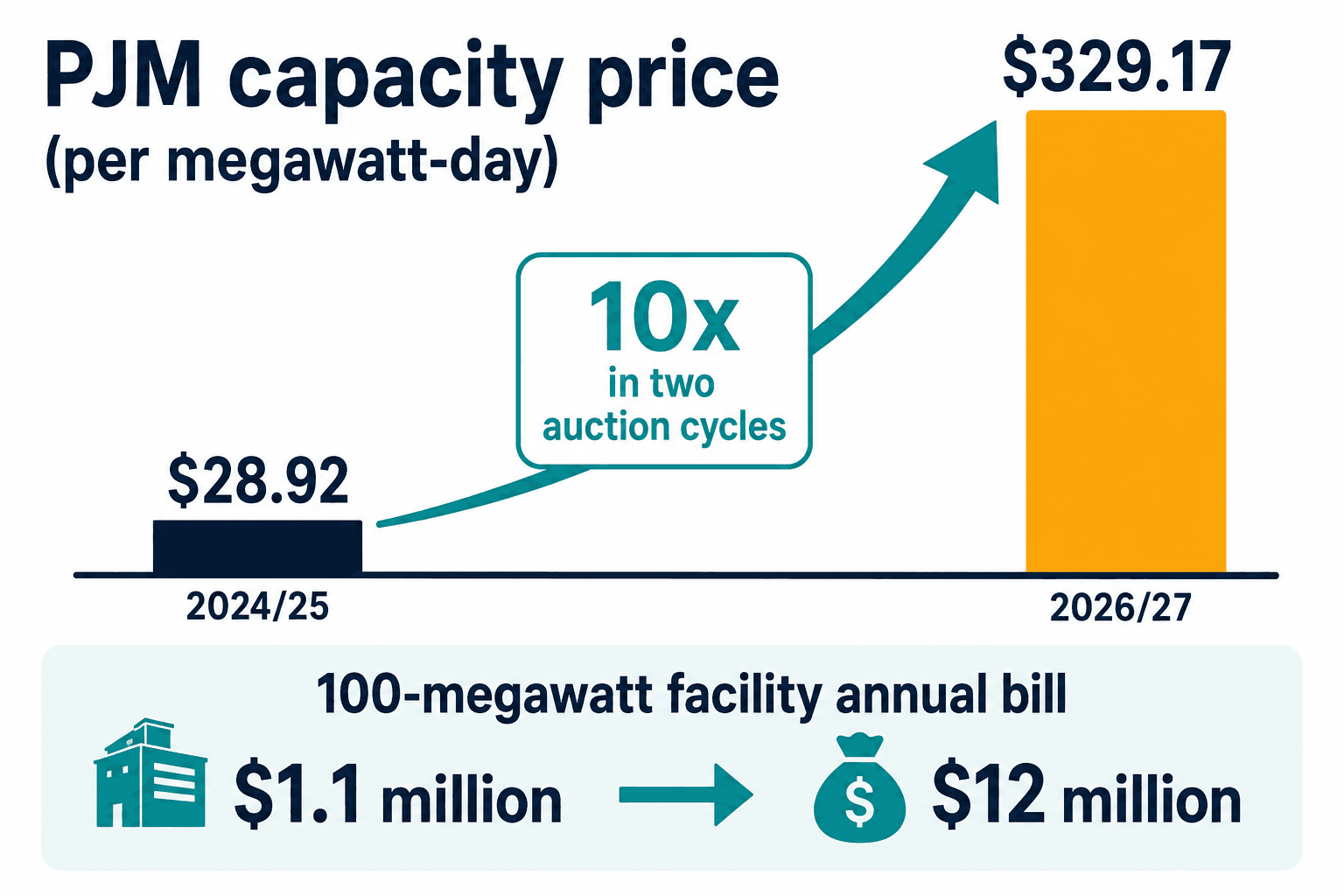
Here is the figure that reorganized how I thought about this entire market. In the PJM region, which covers the Mid-Atlantic and a chunk of the Midwest, the capacity price — what you pay per megawatt to guarantee your power is there when the grid is stressed — went from $28.92 per megawatt-day in 2024/25 to $329.17 in 2026/27. That is a tenfold increase in two auction cycles.
For a 100-megawatt facility, the annual capacity obligation went from about $1.1 million to roughly $12 million. That is not a sustainability line item anymore. That is a number a CFO circles in red and brings to the board, and data centers know exactly why it happened: they drove 63 percent of the price increase in the 2025/26 auction, which translates to $9.3 billion recovered from every ratepayer in the region. Starting June 2026, PJM ratepayers collectively pay an extra $1.4 billion a year, and a meaningful slice of that lands on residential bills — around $18 a month in western Maryland, $16 in Ohio.
Once I understood that, the political backlash made sense. Virginia legislators spent the 2026 session debating a moratorium on new data centers and settled instead on a new "GS-5" rate class for any load over 25 megawatts, effective January 1, 2027. Dominion Energy, which fields over a gigawatt of new data center power requests every month against 70 gigawatts of total filed demand, publicly admitted it cannot meet what's being asked. When the local utility says out loud that it can't serve you, your interconnection queue stops being a scheduling problem and becomes an existential one.
So the real problem was never "ride through a voltage dip." It was: can this facility prove it helps the grid instead of hurting it — financially, operationally, and to a regulator? That reframing is the whole company.
Why Didn't the Standard Protocol Just Work?
My next assumption was that the plumbing already existed. There is an open standard for this — OpenADR, the Open Automated Demand Response protocol, now in version 3.0 with a clean REST API. Utilities send demand-response events; buildings respond. We wired it up expecting it to be the easy part.
It was the part that taught me the most. OpenADR was built for buildings. It can tell a facility "shed load now," but it has no concept native to a data center — no event type for curtailing a GPU training cluster, shifting a cooling thermal load, or coordinating UPS islanding across tenants. Worst of all, it is workload-blind. It cannot distinguish a machine-learning training job that could happily pause for two hours from a live inference request that a customer is waiting on right now. To a data center, that distinction is everything. Defer the wrong workload and you've broken an SLA; defer the right one and the customer never notices.
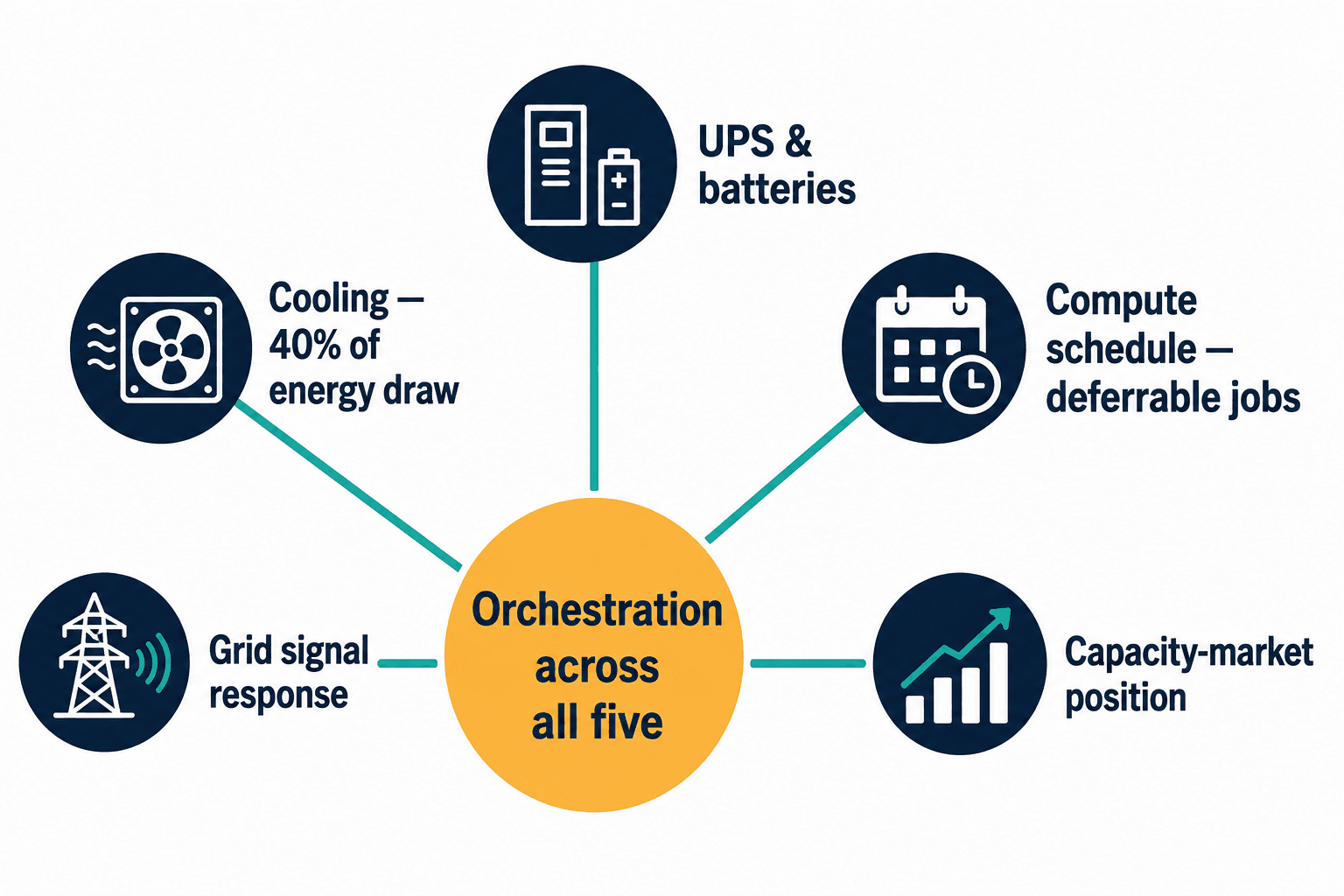
That was the dead end that pointed at the actual architecture. The flexibility in a data center isn't one lever. Cooling is roughly 40 percent of total energy draw — that's a flexible load you can pre-cool against. The UPS and batteries are a dispatchable resource. The compute schedule itself is flexible if you know which jobs are deferrable. And sitting above all of it is the capacity-market position you're trying to optimize. No vendor I could find was orchestrating across all of those at once. Schneider does power and cooling hardware. Emerald AI does compute plus on-site generation. Nobody was doing all five layers together, which is exactly the gap we walked into.
The Tenant Problem Nobody Builds For
There's a reason most of the serious money in this space is aimed somewhere else. Emerald AI — founded by former Department of Energy official Varun Sivaram, $68 million raised in 16 months, with NVIDIA, Eaton, GE Vernova, and even the CIA's venture arm on the cap table — is the clear leader. Their Conductor platform demonstrated a 25 percent power reduction sustained over three hours during a grid-stress event, validated in Nature Energy. It's genuinely impressive work.
It is also built for single-tenant hyperscaler AI factories — NVIDIA GPU clusters where one operator controls every workload. Google has done the same in-house, folding a full gigawatt of demand response into its utility contracts because Google can simply decide to shift its own machine-learning jobs.
The colocation operator who'd questioned my first prototype said the thing that defined our wedge: he didn't control his tenants' workloads, and our software had quietly assumed he did.
He was right, and it's the assumption baked into nearly every product on the market. A multi-tenant colo doesn't own the compute schedule. It has a building full of customers running everything from enterprise databases to AI training to latency-sensitive inference, on a mix of NVIDIA, AMD, and custom silicon, behind UPS lineups from different vendors that — as the byte blackout proved — don't even count voltage disturbances the same way. Some count per-phase, some aggregate. Orchestrating flexibility in that environment, without controlling the workloads and without locking the operator into one GPU vendor, is a fundamentally harder and almost completely unserved problem. That's where we decided to live: vendor-neutral, multi-tenant, built for how colocation actually works.
Everyone is building the data center that controls its own compute. Almost nobody is building for the operator who doesn't.
The Compliance Gap the Blackout Left Open
The most uncomfortable thing I learned is that the exact failure mode behind July 2024 is still wide open, almost two years later.
NERC — the body that sets reliability standards for the North American grid — has a Large Loads Working Group racing to write the first standards specifically for data center loads, with an initial deadline of end of 2026. They've introduced a new load-modeling classification for data centers, called PERC1, that's supposed to let utilities simulate how a cluster of facilities will behave during a fault. The problem: PERC1 needs facility-specific parameters — your actual UPS ride-through behavior, your real counting logic — and there is no commercial tool that extracts that data from a facility's monitoring systems. Utilities need the data. Data centers have no way to produce it. The disclosure gap that caused the blackout is, structurally, still there.
That's not an abstract standards debate to an operator. FERC's large-load interconnection rulemaking (docket RM26-4-000, final action due April 30, 2026) floats 60-day expedited interconnection studies for loads that can prove they're flexible. In a region where the standard queue runs three to five years, a 60-day path is the difference between opening in 2026 and opening in 2030. But to qualify, you need monitoring and verification you almost certainly don't have today. Flexibility you can't document is flexibility that doesn't count.
So part of what we built isn't sexy at all: it's the layer that reads a facility's own behavior — UPS thresholds, ride-through response, load composition — and turns it into the artifacts a regulator and a utility actually ask for. The unglamorous truth is that "prove it" is becoming the whole game, and proof requires instrumentation nobody installed.
"Won't Nuclear Just Fix This?"
People ask me some version of this constantly, so let me answer the three objections head-on.
The first is nuclear. Meta, Microsoft, and Google have all signed splashy small-modular-reactor and nuclear-restart deals — Meta alone for up to 6.6 gigawatts. But no commercial SMR operates in the United States today, and the realistic online dates cluster around 2028 to 2032. Grid interaction is a this-year problem. And even with a reactor next door, you still have to manage the transition, sell excess generation back, and ride out the years before it's live.
The second is "isn't this just demand response, which utilities have run for decades?" Traditional demand response is manual, utility-mediated, and blunt — shed load, get paid. What's changed is the price and the precision. At roughly $120,000 per megawatt-year in capacity value, a 100-megawatt facility offering even 20 percent flexibility is looking at around $2.4 million a year, and a facility that structures itself to avoid the capacity obligation entirely can be looking at the full ~$12 million. Numbers that size justify automated, workload-aware optimization that the old programs never needed.
The third is "why not just buy the hardware from Schneider or Eaton?" You should — they make excellent equipment. But hardware is the body; the orchestration is the nervous system, and it's why Eaton invested in Emerald AI rather than building the software themselves. The decision layer that watches grid signals, market prices, thermal headroom, and deferrable compute all at once, and acts across them in coordination, is its own discipline. That's the part we build, and we build it to sit on top of whatever hardware you already own.
The Asset on the Other Side of the Liability
Veriprajna's data center grid interaction system exists because of a conviction I didn't have when I started. I'm now convinced the operators who survive the next few years aren't the ones who lock in the cheapest power contract. They're the ones who can hand a utility a verified flexibility profile and a regulator a documented ride-through behavior — and get a faster interconnection and a lower capacity bill for it.
The byte blackout was a near-miss. Roughly 60 facilities walked off the grid because of a counting rule, and the system absorbed it — barely, by yanking power plants offline in two states. PJM expects to operate with minimal reliability margin through the summer of 2026 and may fall below its standards by June 2027. The next event won't have the same slack to catch it.
A data center can be the largest, most controllable, most valuable flexible load on the entire grid. Every megawatt that walked off the wire in 82 seconds could instead have been a megawatt that chose to step back, on a signal, and got paid for it. That is the whole difference between a liability and an asset — and right now it comes down to whether the building can decide for itself, in time, with proof. That decision is software. We decided to write it.