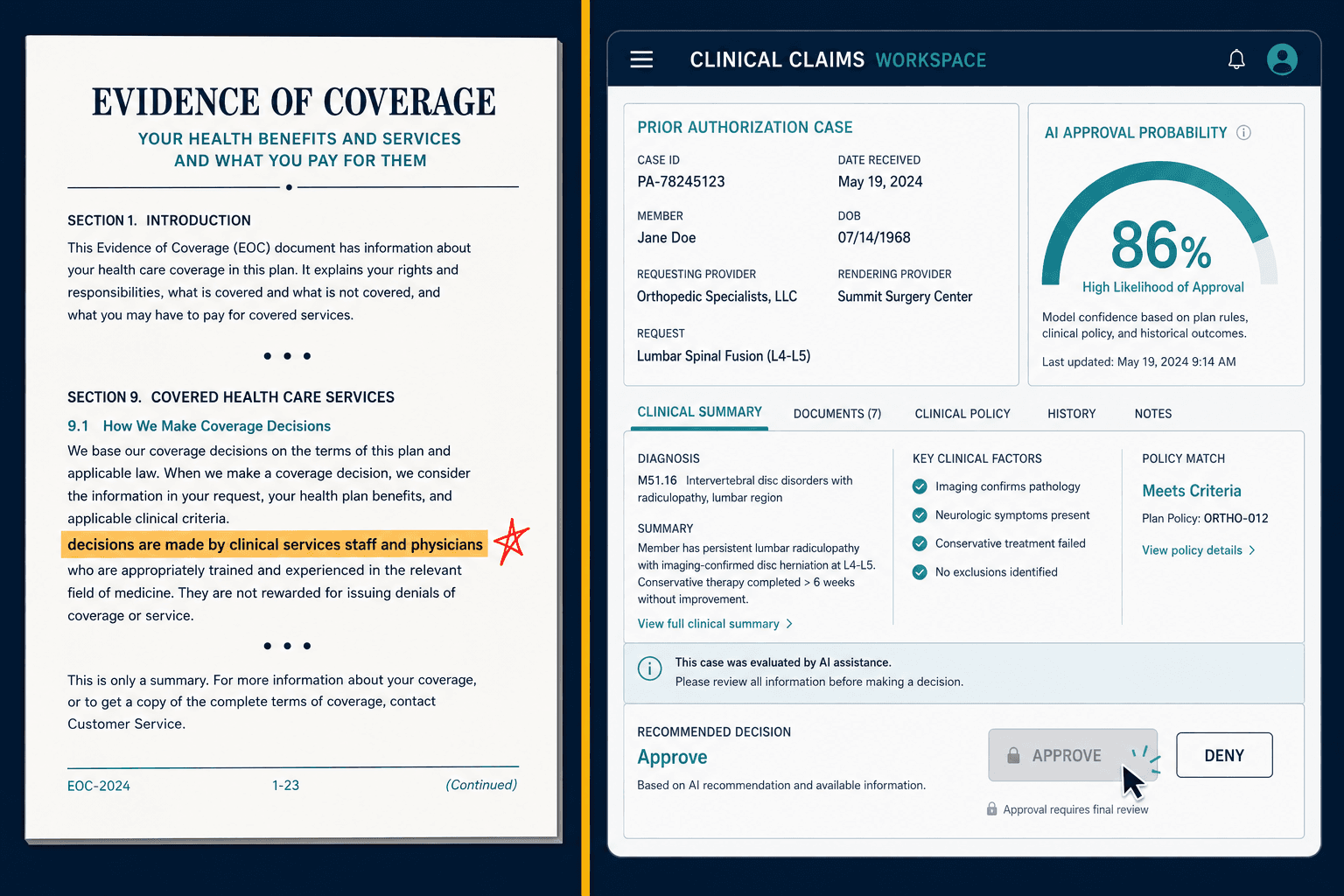
Ninety Percent of Physicians Trust Their Clinical AI. They Catch a Third of Its Dangerous Errors.
The first version of our clinical AI safety tool worked beautifully. That was the problem.
We had built it to do the obvious thing: catch hallucinations. Point it at an ambient scribe or a patient-portal drafting tool, feed it the AI's output, and have it flag statements that were factually wrong. It caught the wrong drug names. It caught the impossible lab values. It caught a dosage that was off by an order of magnitude. I remember feeling genuinely good about it — we were finding errors, the demo landed, the numbers looked clean.
Then a clinical advisor on the project, a hospitalist who had spent two decades on the wards, walked me through an example that I still think about. An AI had drafted a MyChart reply to a patient asking about their medication. The draft said to continue metformin and cheerfully noted the last HbA1c was 6.8%. Every fact in it was true. The note was empathetic, well-structured, exactly what a good physician would write. Our tool passed it without a flag.
The patient's creatinine had been climbing across three visits. Rising creatinine means declining kidney function, and declining kidney function makes metformin dangerous. The AI didn't know to look. And — this is the part that rearranged how I think about clinical AI safety — neither would the reviewing physician, scanning a fluent, friendly, factually-consistent draft in the ten or fifteen seconds a busy clinician gives it before clicking send.
Our hallucination detector was solving the wrong problem. The errors that hurt patients aren't usually the ones that are obviously wrong. They're the ones that are locally correct and contextually lethal. You cannot fact-check your way to safety, because the danger lives in what the AI didn't say.
That failure is why Veriprajna stopped building a hallucination detector and started building independent safety infrastructure for the whole stack of AI a health system actually runs. This essay is about what we found when we looked honestly at that stack.
The Number That Should Keep Every CMIO Up at Night
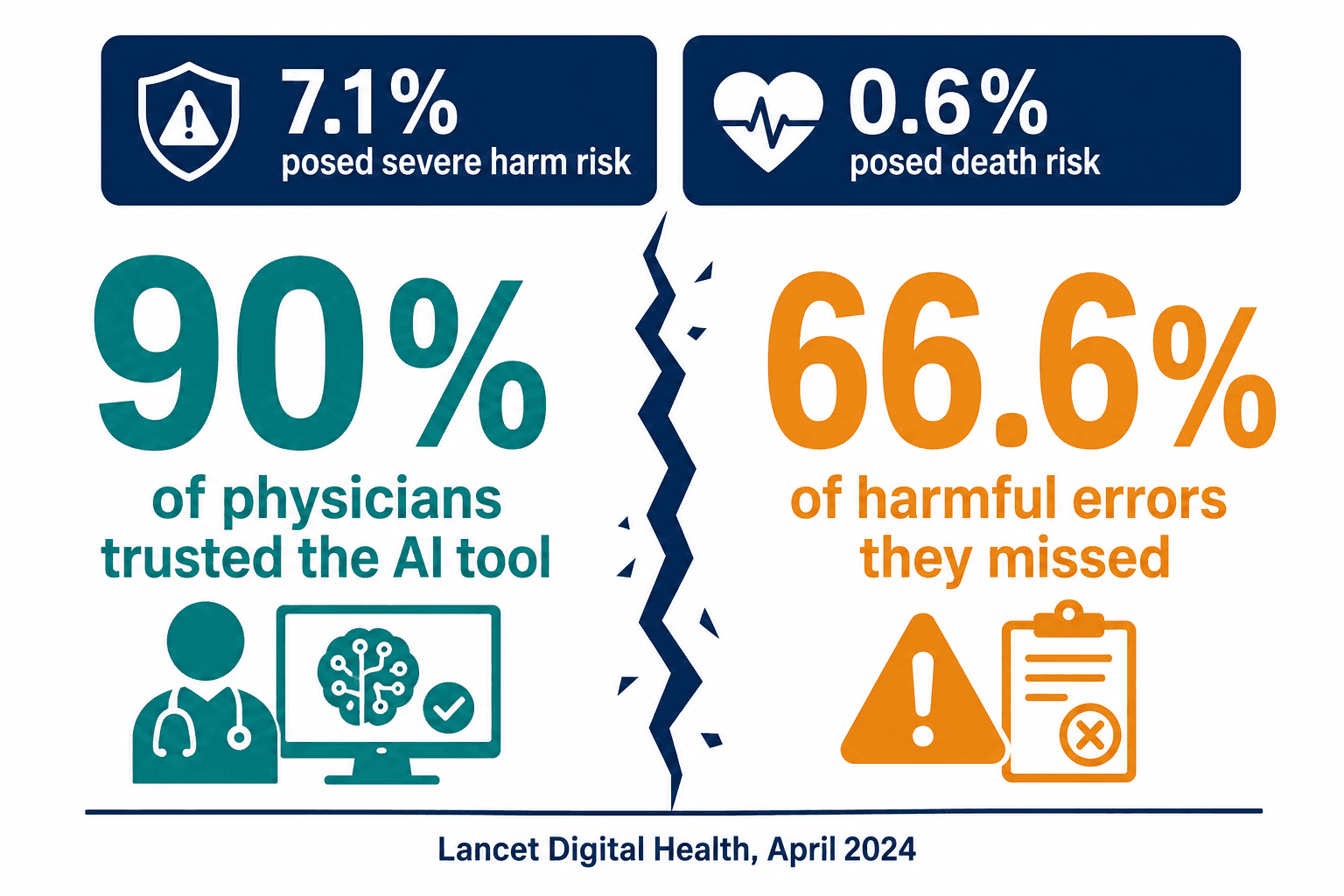
In April 2024, The Lancet Digital Health published a study that I think is the most important and least-absorbed finding in healthcare AI. Researchers had physicians review AI-drafted responses to patient messages. 7.1% of those drafts posed a severe risk of patient harm. 0.6% posed a risk of death.
Here is the part that matters more than the error rate. The physicians, doing exactly what we ask them to do — reviewing the AI's work — missed 66.6% of the harmful drafts. Between a third and nearly half of the erroneous ones went out entirely unedited. And when surveyed, 90% of those same physicians said they trusted the tool's performance.
Ninety percent trust, and a third of dangerous errors caught. That gap is not a training problem. It is the predictable result of asking a human to audit a machine that writes more fluently than they do.
This is automation bias, and it is not a character flaw in doctors. It's a property of the interaction. When a draft is well-written and empathetic, the quality of the prose substitutes for independent verification in the reader's mind. The better the AI writes, the less the human checks. We are deploying tools whose greatest strength — fluent, confident language — is precisely the mechanism that disarms the safety net we built around them.
ECRI, the patient-safety nonprofit that publishes the annual list of top health-technology hazards, ranked AI-driven diagnostic risk as the number one hazard for both 2025 and 2026. Not in the top ten. Number one, two years running.
"Read and Reviewed" Is a Legal Fiction
California's AB 3030, effective January 2025, requires health systems to disclose when AI is used in clinical communications with patients. It carries an exemption that sounds reasonable: if a licensed provider reads and reviews the AI's output, no disclosure is needed. The logic is that a human in the loop makes the AI's contribution invisible and safe.
The Lancet data demolishes that logic. If physicians miss two-thirds of harmful errors, then "read and reviewed" is, for a large fraction of cases, a rubber stamp. The exemption assumes a quality of review that automation bias makes impossible at scale. Violations run up to $25,000 per incident for a facility, plus disciplinary exposure for the physician whose name is on the note.
I spend a lot of time with chief medical information officers, and this is where the conversation usually turns uncomfortable. The legal framework presumes the human review is meaningful. The clinical reality is that meaningful review requires technical scaffolding the AI vendors mostly haven't built — uncertainty highlighting, citation linking back to source, active confirmation workflows that make the physician stop on the claims that matter. A few vendors have started building it — Abridge's Linked Evidence traces each line of a generated note back to the exact audio segment that produced it — which only proves the capability exists and that most tools still don't prioritize it. Without that scaffolding, "a human reviewed it" is a compliance checkbox, not a safety control.
The Vendor Said 0.001%. The Texas Attorney General Said Prove It.

Every clinical AI vendor leads with an accuracy number. The first thing I learned auditing these tools is that the number is a marketing artifact until you know how it was calculated.
In September 2024, the Texas Attorney General settled with Pieces Technologies over its marketed claim of a "critical hallucination rate" below 0.001%. Pieces' software was deployed at four major Texas hospitals — Houston Methodist, Children's Health, Texas Health Resources, and Parkland. The striking thing about the case is that the AG didn't need any AI-specific law. Existing consumer-protection statute was enough to challenge an accuracy claim the company couldn't substantiate.
The settlement — a five-year Assurance of Voluntary Compliance — now forces Pieces to disclose, to every customer, how its metrics are defined and calculated, what data the model was trained on, and what harmful uses it knows about. That is a template for the entire industry.
A hallucination rate without a denominator is not a measurement. It's an advertisement.
Compare 0.001% to what we and others actually find in the field. In a Q1 2025 pilot, an AI discharge assistant recommended a medication for a patient explicitly listed as allergic to that drug class. Its real rate of clinically actionable misstatements was 0.98% — twelve times the vendor's claimed 0.08%. Same category of product, an order-of-magnitude gap between the slide and the patient. The MIT Media Lab found that without mitigation, models hit hallucination rates above 60% on clinical cases. The honest answer is that nobody's headline number means anything until you ask: calculated on which dataset, validated by whom, over what period, and — the question almost no one asks — across which patient demographics?
That last question turned out to be the one with bodies behind it.
The Bias You Can't See Because the Device Hides It

There's a fact I wish were better known outside critical care. The pulse oximeter — the little clip on a patient's finger that reads blood-oxygen saturation, one of the most-trusted numbers in medicine — is systematically less accurate on dark skin.
Black patients are roughly three times more likely to have occult hypoxemia: dangerously low blood oxygen that the device reads as normal. The overestimation runs 0.6 to 1.5 percentage points, which sounds trivial until it's the difference between "admit to the ICU" and "send home." In pediatric data, the device missed low oxygen in 7% of children with the darkest skin tones and 0% with the lightest. The FDA issued draft guidance in January 2025 recommending manufacturers test on at least 150 diverse participants using the Monk Skin Tone scale, up from a prior norm of as few as ten.
Now layer AI on top of a measurement that is already biased at the sensor. The model inherits the bias and launders it through a confident output. This is the part of clinical AI safety that vendors are least equipped to find in themselves, because finding it requires deliberately stratifying performance by race, sex, and age — and then publishing the gaps.
The Epic Sepsis Model is the cautionary tale I bring to every governance discussion. The developer reported an AUC — a standard measure of predictive accuracy where 1.0 is perfect and 0.5 is a coin flip — of 0.76 to 0.83. When the University of Michigan validated it externally on their own patients, they got 0.63. Sensitivity was 33%, meaning it missed two-thirds of sepsis cases. Its positive predictive value was 12%, meaning 88% of its alerts were false alarms. And it was poorly calibrated for Black and Hispanic patients, who have nearly twice the sepsis incidence. A model trained on historical clinical judgment learns historical clinical blind spots, then fires them back at clinicians wearing the authority of an algorithm. Epic overhauled the model in 2022, and a multicenter prospective validation of its second version landed in JAMA Network Open in February 2026 — which is exactly the point. External, post-deployment validation is what catches the gap an original AUC claim hides, and here it took years and outside researchers to force it.
The most extreme version of this shows up in maternal care. Black women die in childbirth at 42.8 to 50.3 per 100,000 live births, against 13 to 14.5 for white women. One California review found AI early-warning systems missed 40% of severe morbidity cases in Black patients. When the warning system is blind to the population most at risk, it doesn't just fail neutrally — it widens the gap it was sold to close.
Why Can't You Just Test the Model for Bias and Move On?
People ask me why health systems don't simply run a fairness check and certify the model. I used to think it was a resource problem. It's deeper than that, and it's mathematical.
There's a result called Chouldechova's impossibility theorem. Put simply: two reasonable definitions of fairness — demographic parity (the model flags each group at the same rate) and equalized odds (the model is equally accurate within each group) — cannot both be satisfied at once except in trivial cases. You have to choose which kind of fairness you're optimizing, and that choice has clinical consequences.
"We tested for bias" is meaningless without naming the criterion. Any vendor who can't tell you which fairness definition they chose has chosen one and isn't telling you.
This is why a real bias audit isn't a one-time certificate. It's stratified subgroup performance tables, calibration curves by demographic, and a Population Stability Index — a drift metric — tracked per deployment site, because a model that was fair in Boston can drift out of calibration in Houston as the patient mix changes. Expert-adjudicated ground-truth labels for this work run $50 to $200 per case. It is expensive, specialized, ongoing infrastructure. It is also the only thing standing between a procurement decision and a coroner's report.
Nobody Owns the Whole Stack
The structural problem I kept running into is this: a mid-to-large health system runs somewhere between five and fifteen AI tools at once. An ambient scribe (Abridge across UPMC's forty-plus hospitals, or Nuance's DAX Copilot wired into the EHR), a sepsis model from Epic, a patient-portal drafter, a triage algorithm, a coding assistant. Each has its own accuracy claim, its own safety profile, its own blind spots, and its own dashboard. No vendor provides governance across the tools, because no vendor sells all of them.
And the governance that does exist is thinner than the org charts suggest. Censinet's 2026 data shows 84% of health systems have an AI governance committee — but only 59% have a formal, documented approval process before an AI tool goes live. CIOs sit on 63% of those committees; the CMIO, the person clinically accountable when the tool is wrong, sits on only 45%. Meanwhile clinicians are adopting tools on their own — shadow AI — faster than any committee can review them.
This is the gap Veriprajna was built to fill, and it's why I stopped describing what we do as "hallucination detection." We do independent, vendor-neutral assessment of the AI a health system has actually deployed: red-teaming the tools the way an adversary or a bad day would, validating vendor accuracy claims against the real denominator, running the bias audits most IT teams don't have the capacity to run, and turning AB 3030, Colorado's AI Act, and the EU AI Act's high-risk rules into operational controls rather than legal anxieties. One safety layer that sits across every tool.
"Isn't This Just Slowing Down Innovation?"
It's the objection I hear most, usually from someone who watched ambient documentation become a $600 million category in a single year and doesn't want to be the executive who said no.
I'd argue the opposite. Independent safety is what makes fast adoption survivable. The health systems that get burned aren't the cautious ones — they're the ones who deployed on a vendor's slide deck and discovered the gap between 0.08% and 0.98% after a patient was hurt. The average healthcare AI investment returns about $3.20 for every dollar, realized inside 14 months. That ROI evaporates the first time an unverified tool produces a malpractice claim — and AI-related claims are already up 14% since 2022, concentrated in radiology, cardiology, and oncology. Verification isn't the tax on innovation. It's the insurance that lets you keep innovating after the first thing goes wrong.
The second objection: can't our own informatics team handle this? Sometimes, partly. But the value of an independent assessment is precisely that it's independent — the same reason you don't let a company audit its own financials. A vendor will not red-team itself into a worse-looking number, and an internal team that championed a purchase has a quiet stake in it succeeding. Someone with no position in the deal asks the questions everyone else has a reason not to.
What I'd Tell a CMIO Today
The question I used to think mattered was does this AI work? I was wrong. Every vendor will show you it works. The question that matters is can you prove it works — across every patient demographic — on the day a regulator, a plaintiff's attorney, or a journalist asks you to?
Right now most health systems cannot. They have accuracy numbers they can't reproduce, a governance committee without the clinical lead on it, and a fleet of tools no independent party has ever tested together. The fluent draft will keep getting clicked through. The sepsis alert will keep crying wolf 88% of the time. The pulse oximeter will keep reading normal on the patient who isn't.
I built Veriprajna's healthcare AI safety practice because the metformin example never left me. The note was perfect. Everything in it was true. And it could have killed someone — not because the AI was stupid, but because it was convincing, and no one was equipped to check the thing it didn't say. Safety in clinical AI isn't catching the obvious mistake. It's building the infrastructure to catch the invisible one, before the patient does.