Our AI Outbound Sent 1,000 Emails a Day. Then Our Invoices Stopped Arriving.
The first sign that something was wrong wasn't a sales metric. It was an invoice that never arrived.
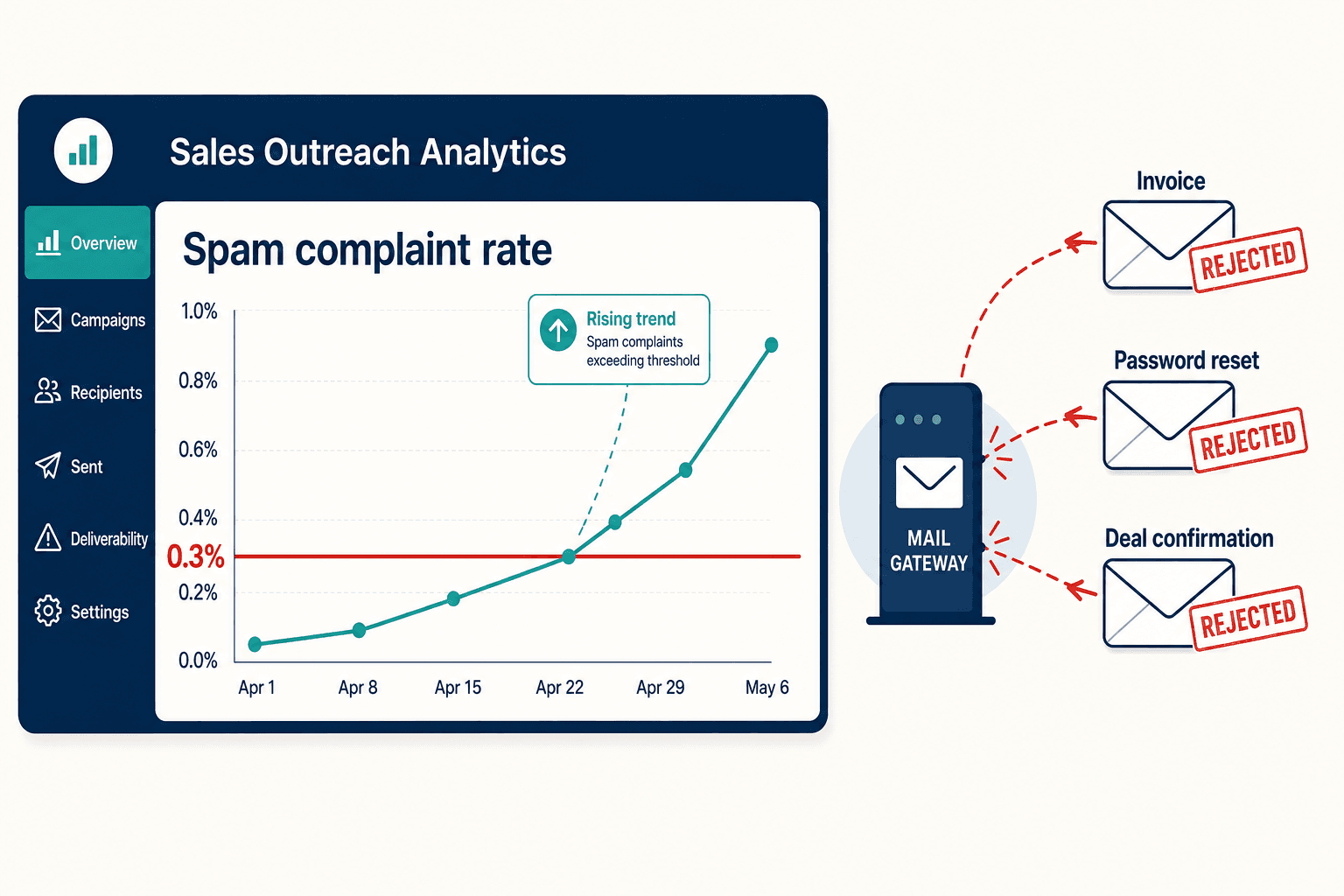
A customer emailed to ask why they hadn't been billed. We'd sent the invoice days earlier — from the same domain we'd been using to run an aggressive AI outbound campaign. The invoice hadn't gone to their spam folder. Gmail had refused it at the door. And once I started pulling the thread, I realized our password-reset emails, our deal confirmations, and a chunk of our legitimate transactional mail were all getting throttled along with it.
That was the week I stopped believing the AI SDR pitch. Not the idea of AI sales intelligence — I still think that's where outbound is going. But the specific promise every tool was selling at the time: more emails, more personalization, more pipeline, just add an autonomous agent and watch it scale. We'd done exactly that. And volume without verification destroyed more pipeline than it ever created.
This is an essay about what broke, why it broke at the level of architecture rather than copywriting, and what we ended up building instead. If you're evaluating AI SDR tools right now, or recovering from a deployment that cratered around day 90, I think you'll recognize the shape of it.
The First 30 Days Always Look Great
Nobody warns you about this part: the early numbers are genuinely good. That's what makes it dangerous.
AI SDR tools can post initial email response rates up to 50% higher than a human rep, mostly because they send at a volume no human could match. You launch, the dashboard lights up, and for about a month you feel like you've found free money. We did. I remember showing the reply-rate chart to the team and feeling slightly smug about how late everyone else was to this.
Then the second-order effects start compounding, and they don't show up on the dashboard you're watching.
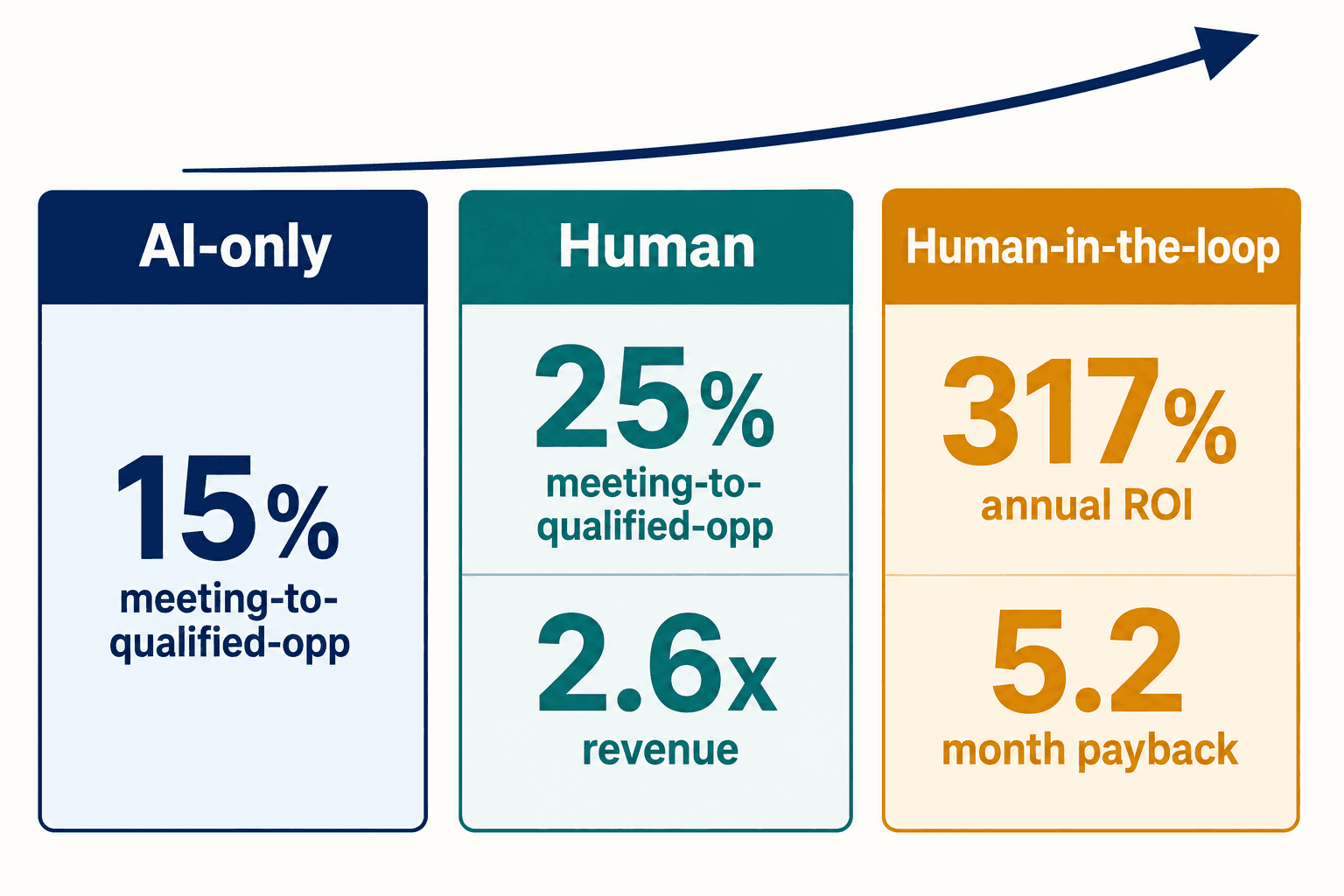
By the time you notice, the meetings the AI booked aren't converting. Industry data from 2026 puts the AI meeting-to-qualified-opportunity rate at around 15%, against 25% for a human SDR. The gap widens further downstream: human reps generate 2.6x more revenue than AI-booked meetings, despite touching fewer prospects. The AI was filling the calendar with conversations that died on contact.
And that's the benign failure. The expensive one was happening in the sent folder, where nobody on my team was looking.
The Email That Cited a Migration That Never Happened
One afternoon, debugging a low reply rate on a segment, I actually read what the system had sent. Not a sample we'd approved during setup — the live output, days of it.
One email confidently congratulated a prospect on their "recent migration to Salesforce." Their careers page, which our enrichment had scraped, explicitly listed HubSpot in three open job postings. The AI had invented the migration. Another referenced a company's "expansion into APAC" — sourced, as far as I could reconstruct, from a 2019 press release that had long since been reversed.
The grammar was flawless. That's what made it worse. A typo gets caught. A confident, well-written, factually wrong sentence sails straight into a VP's inbox and tags your company as one that couldn't be bothered to check.
Perfect grammar is the disguise. It is what lets a false sentence pass every human eye between draft and send.
When I went back and audited our output against the broader benchmark, it tracked: single-pass language models get 12 to 18 percent of prospect-specific claims wrong. Sit with that number against volume. At 1,000 emails a day, that's 120 to 180 factually wrong messages landing in executive inboxes every single day — and not one of them set off an alarm, because each one read perfectly.
The thing I had built was an extremely efficient machine for being wrong at scale.
Why Didn't More Personalization Fix It?
This was my first wrong instinct, and I want to be honest about it because I argued for it hard internally: I thought the problem was that we weren't personalized enough.
The data seemed to back me. Generic, non-personalized templates reply at 1-3%. Signal-based personalized campaigns — outreach that references a real, specific, timely trigger — reply at 15-25%. That's roughly a 5x improvement, and only about 5% of senders personalize every message. So the obvious move was to crank personalization harder: more signals, deeper research, more specific hooks.
It made everything worse.
More personalization meant the AI reached deeper into its sources to find something specific to say — and the deeper it reached, the more it confabulated. Personalization and verification are not the same thing, and I had been treating them as if they were. A tool can be brilliant at finding a buying signal and have no mechanism whatsoever for checking whether the sentence it wrote about that signal is true. Most of the market is built exactly this way. The personalization is the product; the verification is the customer's problem.
That was the turning point, but it didn't feel like a breakthrough. It felt like discovering the foundation was poured wrong.
What Happens When Gmail Stops Sending to Spam?
While I was busy worrying about copy, the deliverability ground was shifting under all of us.
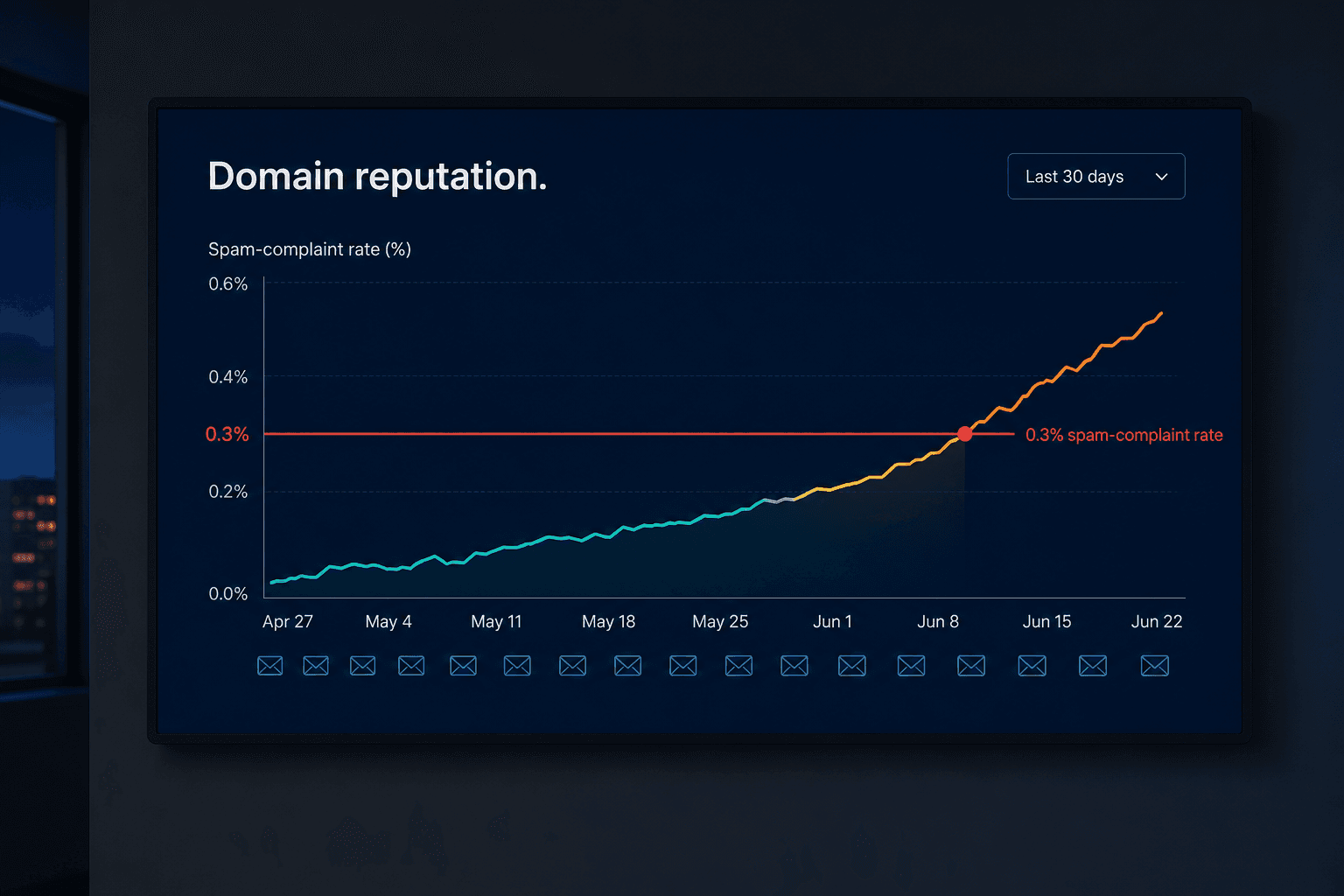
In November 2025, Gmail changed the rules, and the change is easy to miss until it bites you. It stopped routing non-compliant bulk mail to the spam folder and started rejecting it at the SMTP level — at the handshake, before the message exists in the recipient's mailbox at all. Your emails don't land in spam anymore. They never arrive.
Underneath that, Google's RETVec system detects AI-generated text patterns across thousands of messages even when the individual word choices vary, so spinning the copy doesn't save you. And the threshold is brutal: a spam-complaint rate above 0.3% triggers domain reputation damage, with recovery taking six to twelve weeks of restricted sending.
Here's the detail that turned this from a marketing problem into a company problem, and it's the one I wish someone had put in front of me before we launched:
Domain reputation isn't scoped to your campaign. It's scoped to your domain. When the cold outreach burns your reputation, your invoices, password resets, and deal confirmations burn with it.
That's the invoice that never arrived. I'd been looking at our Postmaster Tools dashboard watching the spam-rate line creep toward that red 0.3% line as if it were a campaign KPI. It wasn't. It was the health of every email the business sends. We crossed it, and for the next stretch our legitimate transactional mail got throttled right alongside the outbound we'd been told was safe.
The $74 Million Version of My Mistake
The reason I'm willing to write all this down is that I watched a much better-funded company make the identical mistake in public, and it clarified for me that this wasn't a Veriprajna execution failure. It was the end state of an entire approach.
In March 2025, TechCrunch reported that 11x.ai — backed by $74M from a16z and Benchmark at a $350M valuation — had been listing customers it didn't actually have. ZoomInfo's logo sat on the 11x website despite ZoomInfo having run only a one-month trial, during which, they said, the product performed significantly worse than human SDRs. Former employees described 70 to 80 percent customer churn in the early cohorts, with the product hallucinating and, for some customers, failing to load at all.
That churn figure isn't an 11x anomaly. The AI SDR category as a whole runs 50 to 70 percent annual churn. People buy the volume promise, hit the wall I hit, and leave. The broader pattern is the same: 42% of companies abandoned most of their AI initiatives in 2025, up from 17% the year before, and Gartner expects more than 40% of agentic AI projects to be scrapped by the end of 2027.
$74 million in funding cannot paper over a product that sends wrong information at scale. It just buys a more expensive version of the same crater.
Reading that story was the moment I stopped trying to tune my way out of the problem and accepted I had to rebuild from a different premise.
The Liability Nobody Reads the Fine Print On
There's a third failure mode that I genuinely didn't see coming, and it's the one that should make a general counsel sit up.
Under the doctrine of apparent authority, an AI agent acting on your company's behalf can bind you to what it says. An AI SDR that types "guaranteed 100% uptime" or "we'll give you a full refund, no questions" may be creating an enforceable obligation. In regulated industries, it's worse than a bad deal — an AI that hallucinates "we're FedRAMP authorized" or invents a compliance certification can trigger a federal inquiry. These aren't hypotheticals lawyers raise to slow you down; they're a direct consequence of letting an unverified text generator speak in your company's voice to strangers.
And almost nobody is governing for it. As of 2026, only 7% of enterprises have agentic-specific governance policies in place, even though GDPR enforcement now requires explicit, documented consent for cold outreach in the EU — well beyond the old "legitimate interest" shrug. You are letting an autonomous agent make representations to the market with, statistically, no policy layer behind it.
What We Built Instead
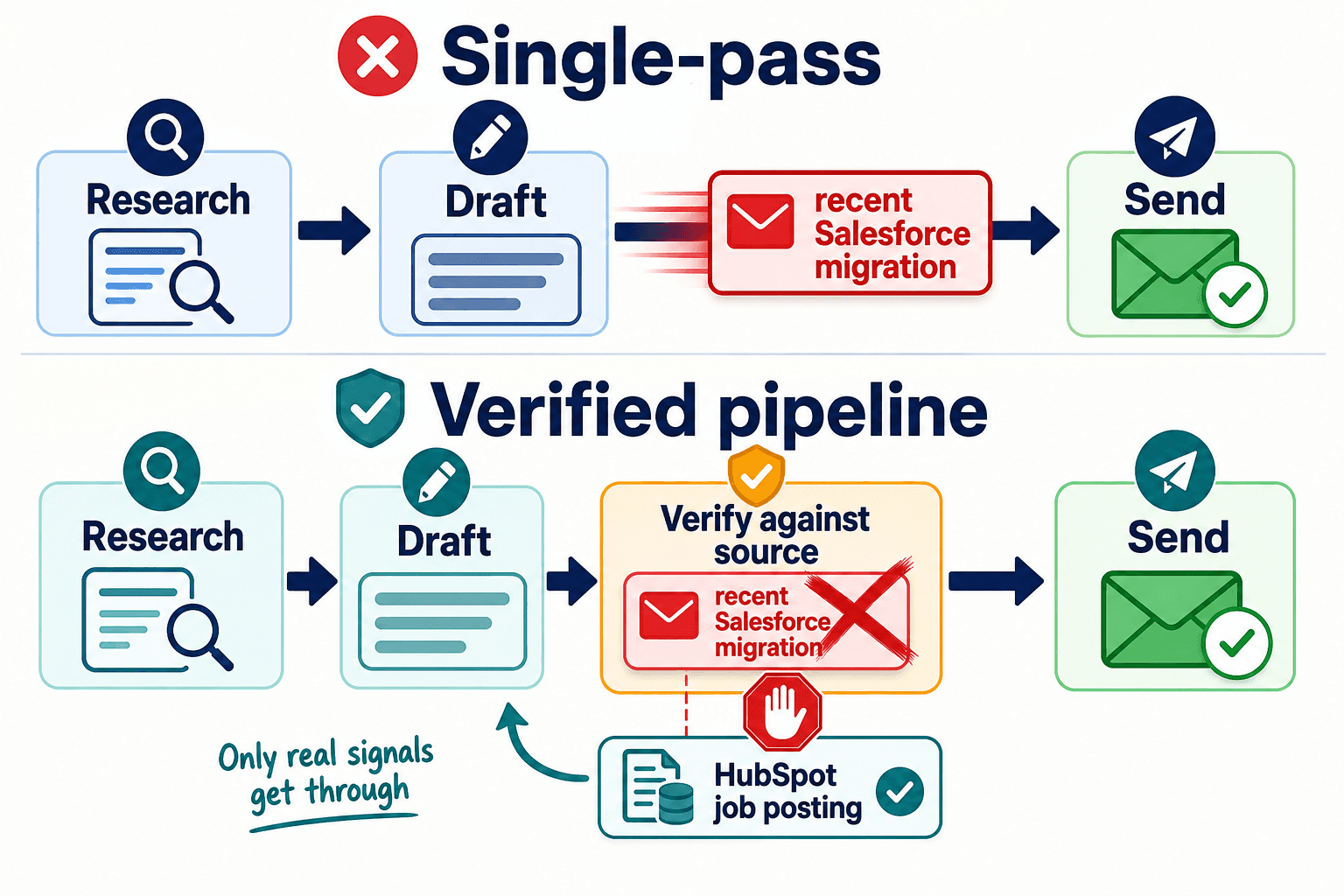
When I lay these three failures next to each other — hallucinated facts, domain collapse, and legal exposure — they share one root cause. None of them is a copywriting problem. All of them come from the same architectural choice: letting a single language model both decide what's true and hit send in one pass.
So we stopped bolting checks onto the end and moved verification into the architecture itself.
The core decision was to put a fact-checking step between the draft and the send, not after it — a stage where every prospect-specific claim in an email gets validated against the source data it supposedly came from before the message is ever queued. If the AI writes "recent Salesforce migration," the pipeline goes back to the evidence; if the only signal is a HubSpot job posting, the claim doesn't ship. The language model is allowed to be creative about phrasing. It is not allowed to be the final authority on whether something is true.
That sounds obvious written down. It is not how the off-the-shelf tools are built, because verification is the expensive, unglamorous part, and a multi-agent pipeline that researches, drafts, and checks is genuinely harder to engineer than one that researches and drafts. Most internal teams that try to build this default to retrieval-augmented generation without a verification layer for exactly that reason — the hard part gets skipped because the demo looks fine without it.
A few other things had to be true for this to actually serve an enterprise rather than just demo well:
It had to cover private companies. The strongest public-company tools, like Autobound, build their signal libraries off SEC filings and 10-Ks — which is genuinely powerful, but caps out around 4,500 public tickers. Most of anyone's real pipeline is private companies that file nothing, so the research layer has to work without an EDGAR feed to lean on.
It had to be governance-first, with an audit trail for every claim and every send, so a compliance team can answer "why did the AI say that" — not as a feature we added later under regulatory pressure, but as the substrate.
And it had to be CRM-native and start from clean data. We audit the customer's CRM in week one, because a verification pipeline pointed at duplicated, stale contact records — the HubSpot dedup collisions and Salesforce API throttling every RevOps team knows — just verifies its way into the wrong inbox faster. The whole approach is laid out on our AI Sales Intelligence solution page if you want the architecture rather than the story.
Why Not Just Hire Human SDRs Instead?
People always ask me some version of the same question: if the AI is this error-prone, why not just go back to human SDRs?
Because the economics of pure-human outbound don't work either, and pretending they do is its own kind of dishonesty. A fully loaded human SDR runs $75,000 to $125,000 a year. The leverage AI provides is real — when it's verified. The model that actually performs isn't AI-only or human-only; it's the human-in-the-loop pipeline, which the 2026 data credits with a 317% annual return and a 5.2-month payback. Hybrid tools like Amplemarket's Duo report a 5-6x productivity multiplier per rep precisely because the human handles judgment and escalation while the verified machine handles scale.
The point of building verification in isn't to make the AI safe enough to remove the human. It's to make the AI trustworthy enough that the human's judgment gets multiplied instead of spent cleaning up confabulations.
The other question I get is about cost, and it's fair. A custom verified pipeline is a larger upfront commitment than a per-seat SaaS subscription — the SaaS tools run anywhere from a couple thousand to thirty-five thousand a year, and a custom build is a different order of investment with a 10-to-14-week timeline. But run the real comparison. The cheap tool that hallucinates 15% of its claims and burns your domain isn't cheap; it's a six-to-twelve-week deliverability outage and a brand tax you pay in every executive inbox you poisoned. The expensive part was never the software. It was the cleanup.
What I'd Tell Myself Before We Launched
If I could send one message back to the version of me staring at that beautiful first-month reply-rate chart, it wouldn't be "don't use AI for outbound." I'd build it again. It would be this: the dashboard you're watching is the wrong dashboard. The number that matters isn't how many emails went out or even how many got replies. It's what fraction of the claims you sent into the world were actually true — and you have no way of knowing, because you built a system that never checks.
An AI that sends faster than it can verify isn't a sales accelerator. It's a reputation furnace with a really impressive open rate. The whole craft of AI sales intelligence — the version of it worth building — is in the verification step everyone else treats as someone else's problem. That's the part we put at the center, and it's the reason our invoices arrive now. You can see how it fits together on the solution page.
I still watch a spam-rate line on a Postmaster dashboard most mornings. It sits well under that 0.3% threshold now, flat and boring. After the year I've described, a flat, boring line is the most beautiful chart in the company — because it means every email we sent yesterday, to a prospect or a paying customer, actually arrived, and every claim inside it was true before it left.