Your Compliance Training Says Everyone Passed. I Built a Model That Knows They Didn't.
A compliance officer at a bank once walked me through her annual anti-money-laundering recertification. Five hundred people in the compliance function, one four-hour module, everyone assigned the same content: customer due diligence, suspicious activity reporting, structured-transaction detection, trade-based money laundering, sanctions screening. At the end, her learning system produced five hundred green checkmarks. She showed them to me the way you'd show someone a receipt.
Then she said the thing I haven't been able to unhear since — that she had no idea which of those five hundred people actually knew how to file a suspicious activity report.
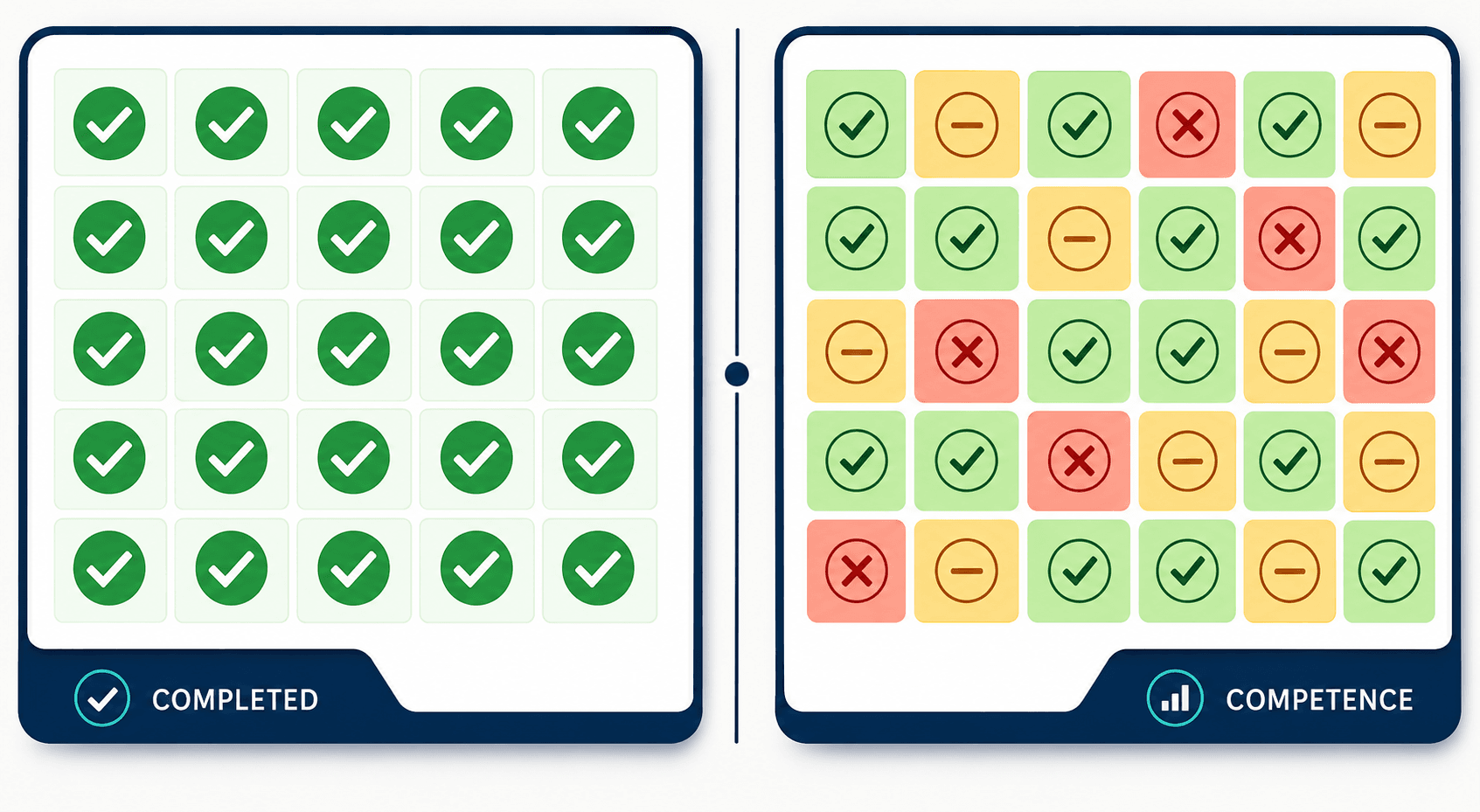
That gap — between completed and knows — is the entire reason I now spend my time building adaptive learning AI for corporate training. Not the recommendation-engine kind that suggests your next course. The diagnostic kind, built on a technique called knowledge tracing, that models what each individual employee actually knows, concept by concept, and updates that estimate every time they answer a question. Her LMS tracked completion. What she needed was a system that tracked competence. We build that competence layer, and it's the solution my team works on every day.
A green checkmark tells an auditor that a video finished playing. It tells you nothing about whether anyone learned to do the job.
The $102.8 Billion Gap Between "Done" and "Knows"
U.S. companies spent $102.8 billion on training in 2025, up from $98 billion the year before — that's Training Magazine's number, and it works out to about $874 per learner. Most of that money buys completion data. SCORM, the file format the majority of corporate courses still ship in, was designed around a 1.2 spec that records pass, fail, and completion. That's it. It's an attendance sheet with better production values.
I find that genuinely strange when you sit with it. We've spent two decades optimizing the delivery of training — slicker video, mobile, microlearning — and almost none of that effort went into measuring whether the training changed what someone can do. The Josh Bersin Company put out a piece in February 2026 arguing that AI is about to transform $400 billion of corporate learning, and the stat that stuck with me was this: fewer than 5% of companies have actually deployed AI-native learning technology. Everyone has an LMS. Almost nobody has intelligence inside it.
And the cost of that gap is no longer abstract. Bersin's data shows companies using AI-native learning are six times more likely to exceed their financial targets. On the other side, 74% of companies say they can't keep up with demand for new skills, and the half-life of a professional skill has dropped from roughly ten years in 2000 to under five today. I've watched L&D teams respond to that collapse the only way their tooling lets them — by shipping more content, faster. I understand the instinct, because for twenty years more content was the single lever the systems gave us. The lever was never the problem. The instrument we use to measure whether any of it worked is.
The First Version I Built Was Wrong, and It Looked Great
Here's the part I'm not proud of. When I first started building this, I reached for the obvious model. In the knowledge-tracing literature there's a well-known approach called Deep Knowledge Tracing — DKT — that uses an LSTM, a kind of recurrent neural network, to predict whether a learner will get the next question right. It's the canonical starting point. We wired it up, fed it interaction data, and the dashboards were beautiful. Mastery curves that climbed, prediction accuracy that looked respectable.
I was ready to show it off. Then I went back to that AML use case and tried to answer the compliance officer's actual question — which concept does this specific analyst not know? — and the model couldn't tell me. It could tell me whether someone was generally "doing well." It could not cleanly say "she's solid on customer due diligence and dangerous on trade-based money laundering."
It took me longer than it should have to understand why. There's a 2025 paper from the Educational Data Mining community making a quietly brutal point: vanilla DKT learns ability, not knowledge per skill. It models a general "this person is good at the test" signal rather than concept-level mastery. Worse, researchers have shown that untrained RNNs — networks with random weights — can match trained DKT models on some benchmarks. My beautiful dashboard was, in a real sense, measuring vibes.
I had built a model that was confident, accurate-looking, and incapable of answering the one question the entire project existed to answer.
That month felt like a dead end. I'd promised competence evidence and built a confidence meter that didn't know what it was confident about.
Why We Rebuilt on Attention Instead of Memory

The way out came from the newer generation of knowledge-tracing models — the self-attentive ones. We moved to SAKT, Self-Attentive Knowledge Tracing, and then to AKT, the context-aware attentive variant. Instead of cramming a learner's whole history into a single recurrent memory, these models use attention to ask, for each new question, which of your past answers actually bear on this skill right now? AKT goes further and folds in ideas from educational measurement theory, adjusting difficulty as it goes.
The practical payoffs were the ones I cared about. SAKT does this with around 700,000 parameters and an AUC near 0.80 — small enough to run efficiently, accurate enough to trust, and crucially it produces a per-concept mastery probability rather than one blurry competence score. AKT turned out to be the better fit when a scenario genuinely needs individualized instruction, which compliance recertification absolutely is. There's a quiet advantage corporate data has over the academic benchmarks these models were built on: compliance sequences are short and high-stakes, not the thousand-interaction tutoring logs that make long-sequence prediction the hard open problem in the literature. The thing the papers struggle with most is mostly not our problem.
That's when the AML example finally rendered the way it should. Picture a heatmap: rows are employees, columns are the five AML concepts, each cell a probability that this person has mastered that concept. A senior BSA analyst with eight years in the role lights up green across customer due diligence, suspicious activity reporting, sanctions — but shows up amber on trade-based money laundering. A branch manager six months into the role is green nowhere and deep red on SAR filing and TBML. Same module, radically different needs.
The senior analyst shouldn't sit through four hours to re-prove what she demonstrably knows; she should verify the mastered concepts quickly and spend her time on the one weak spot. The new manager needs scaffolded, slower paths exactly where his probabilities are lowest. We set thresholds we could defend to an auditor: above roughly 0.75, treat the concept as mastered and verify briefly; in the middle band, that's the productive struggle zone where learning actually happens; below 0.35, stop and remediate with support. The model updates every cell with every response.
Across five hundred employees, that's the difference between two thousand hours of identical seat time and somewhere around half that — with stronger evidence at the end, not weaker. At $874 a learner, the recovered productivity on a single five-hundred-person compliance function lands in the low hundreds of thousands of dollars a year. This isn't a projection I invented. Fulcrum Labs and Allegiant Airlines documented training time falling from 51 days to 23 — a 55% cut — with accidents and equipment damage down 60%. And it isn't only banks and airlines: a global med-tech firm running the same adaptive approach saved more than 16,000 training hours across 113,000 learners, and a healthcare organization cut onboarding time by 22%. The subject matter changes — patient-data handling, device protocols, AML typologies — but the diagnostic problem doesn't. A top-ten U.S. bank ran adaptive compliance across more than 70,000 employees and saw 75% more traffic to required courses. The seat-time reduction is real and it's been proven by people who aren't me.
"Doesn't Cornerstone Already Do This?"
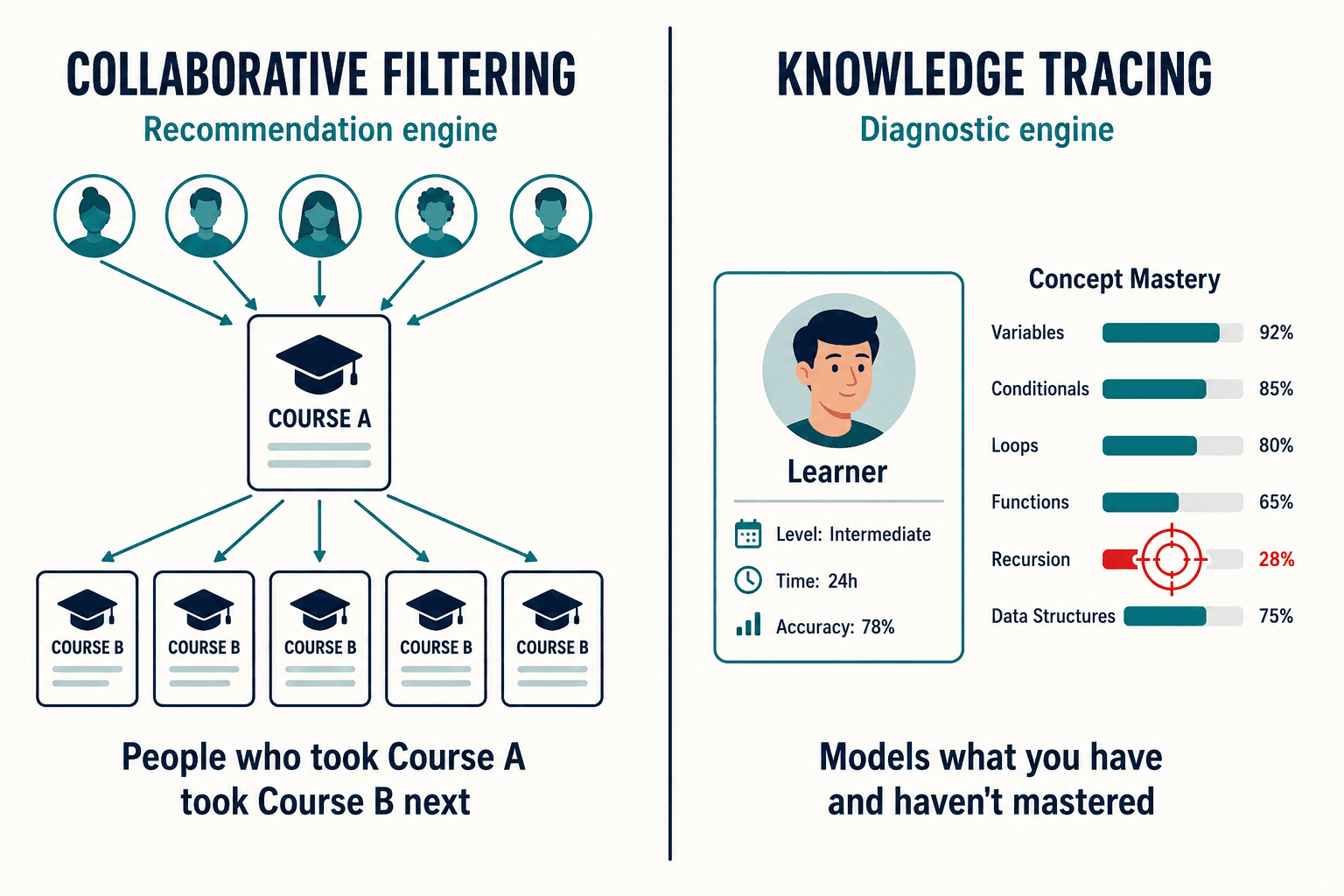
This is the first question I get, every time, and it's a fair one. In March 2026 Cornerstone launched what it calls an Adaptive Learning Agent inside its Galaxy AI system. Docebo acquired 365 Talents to bolt on skills assessment. The whole industry is stamping "AI-powered adaptive learning" on the box. So why build anything custom?
Because most of what's being sold as adaptive is collaborative filtering, not knowledge tracing — and the difference is the whole ballgame. Collaborative filtering is the Netflix move: people who completed Course A tended to take Course B next, so here's Course B. It recommends based on what your peers did. Knowledge tracing does something categorically different: it models what you specifically have and haven't mastered, and targets the gap. One is a recommendation engine. The other is a diagnostic engine. Cornerstone's agent recommends what to learn next; it doesn't measure concept-level mastery. Docebo's skills tracking is largely declaration-based or completion-based — the employee says they know it, or they finished the course — not measured from how they actually interacted with the material.
There are vendors who genuinely do knowledge tracing well. Fulcrum Labs has a proprietary engine and the case studies to back it. The EdTech players — companies like Riiid, which raised $256 million — have real knowledge-tracing models. But Fulcrum needs you to migrate your content onto its platform, and the EdTech models were built for standardized tests and K-12, not AML workflows and audit evidence. And the Big Four? Deloitte and PwC will run you a $500,000-to-$5-million workforce-transformation engagement and install Cornerstone or SAP beautifully. They configure the vendor's platform. The adaptive intelligence still belongs to the vendor, not to you.
Most enterprises don't need to rip out their LMS. They need an intelligence layer that plugs into the one they already have.
That's the gap we build into: a knowledge-tracing engine that sits on top of your existing learning system and talks to it through open standards — xAPI to capture granular interaction data, LTI to hand learners back and forth. You keep your LMS. We add the brain.
The Real Risk Isn't the Model — It's the Tagging
I'll tell you the thing the demos never mention, because it's the thing that actually decides whether one of these projects succeeds. The hardest part of an adaptive learning build is not the neural network. It's content tagging.
A knowledge-tracing model can only trace knowledge it can see. Every question in your compliance module has to be mapped to a concept — this item tests trade-based money laundering, that one tests sanctions screening — or the model has nothing to update. Most corporate content arrives as a pile of SCORM 1.2 packages that emit a single completion flag and no concept structure at all. Moving to xAPI means standing up a Learning Record Store, rethinking your data governance and network architecture, and often retagging content question by question. It's unglamorous, it's where the real labor lives, and it's why I'm wary of anyone who tells you adaptive learning is a switch you flip.
I'd rather be honest about that up front than win a project on a promise I can't keep. The model is the part I can hand you in a few weeks. The tagging is the part we do together, and it's the part that makes the difference between a system that produces audit-grade mastery evidence and one that produces prettier checkmarks.
Will the EU AI Act Make Completion Tracking Worthless?
For a long time, "competence versus completion" was a quality argument — nice to have, hard to fund. That's changing because of the EU AI Act. Article 4, the AI-literacy obligation, has been in effect since February 2, 2025, and supervision by national market-surveillance authorities begins August 2, 2026. It requires that staff be trained for AI literacy in a way that's appropriate to their role — and the EU's own guidance is explicit that there's no one-size-fits-all format. Role-based, or it doesn't count.
Think about what that does to the green-checkmark model. "Everyone watched the same AI-ethics video" is precisely the thing Article 4 is built to reject, and the penalties on the high-risk provisions run up to €35 million or 7% of global revenue. Regulators have shown they'll write enormous checks for training failures in adjacent domains — TD Bank took a $3.1 billion penalty tied to an inadequate AML compliance program. The cost of treating training as theater is no longer hypothetical.
There's a second pressure I didn't anticipate when I started, and it's almost funny. Employees have figured out they can lean on AI assistants to breeze through compliance modules — answer the quiz, click complete, learn nothing. HR Morning reported on it in 2026, and Gartner went as far as predicting that through 2026 half of organizations will require "AI-free" skill assessments because of critical-thinking atrophy. When your workforce can fake completion at scale, completion stops meaning anything at all. The only durable answer is to measure what someone actually knows — which is the thing knowledge tracing was built to do.
What I'd Tell That Compliance Officer Now
People ask me whether all of this is worth it for training, of all things — isn't this over-engineering a corporate obligation nobody enjoys? My answer is that we've been under-engineering it for twenty years, and the bill is coming due from two directions at once: a skills half-life that's collapsed below five years, and a regulator that's about to ask for evidence we mostly don't have. Only 26% of leaders even feel able to measure training ROI today. The thing we chose not to measure is the thing that came due.
I think back to that binder of five hundred green checkmarks. The tragedy of it wasn't that the training was bad. It was that the organization had spent real money and real hours and ended up knowing less than it thought it did — confidently, in writing, with audit trails. The senior analyst was bored and the new manager was lost, and the system reported both as a success.
If I could go back and hand her one thing, it wouldn't be a better video. It would be the heatmap — five hundred rows, five concepts, every cell a number she could actually defend. Not "everyone passed." Something truer and far more useful: here is exactly what each of these people knows, and here is what we're going to do about the rest. That's the system we build, and the longer I do this, the more convinced I am that "completed" was never the answer to a question anyone actually had.