Your Procurement AI Scored a Better Supplier Lower — Here's the Math That Did It
I spent a long evening last quarter staring at a single sourcing scorecard, and it broke an assumption I'd carried through years of working in procurement.
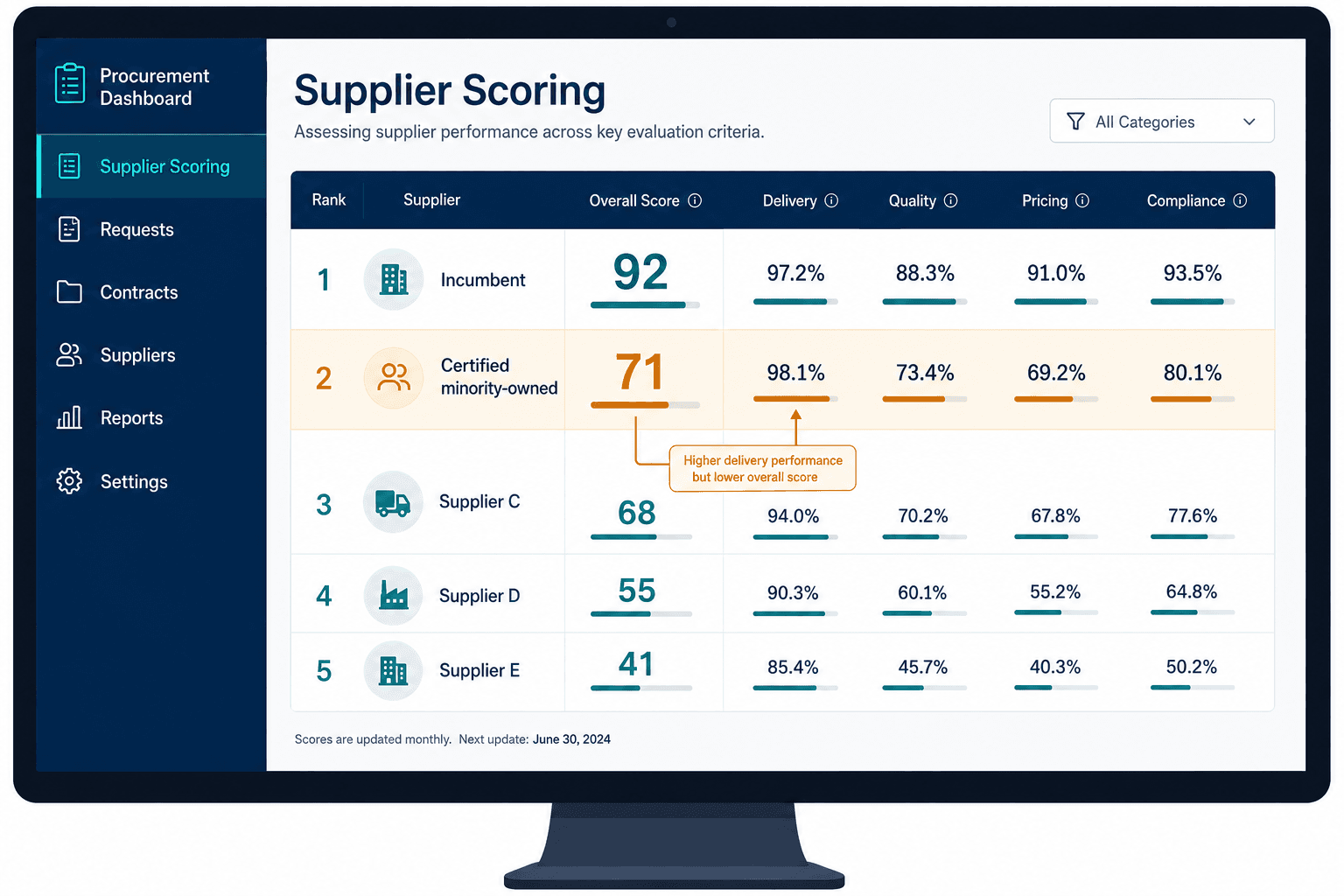
It was a routine event — industrial fasteners, five suppliers, the kind of category nobody loses sleep over. The platform's AI had ranked them on delivery, quality, financial stability, and price. Supplier A, a twelve-year incumbent with thousands of transactions behind it, came in at 92. A certified minority-owned business with a three-year history scored 71. On the surface, that's a clean result. The incumbent won on merit. Move on.
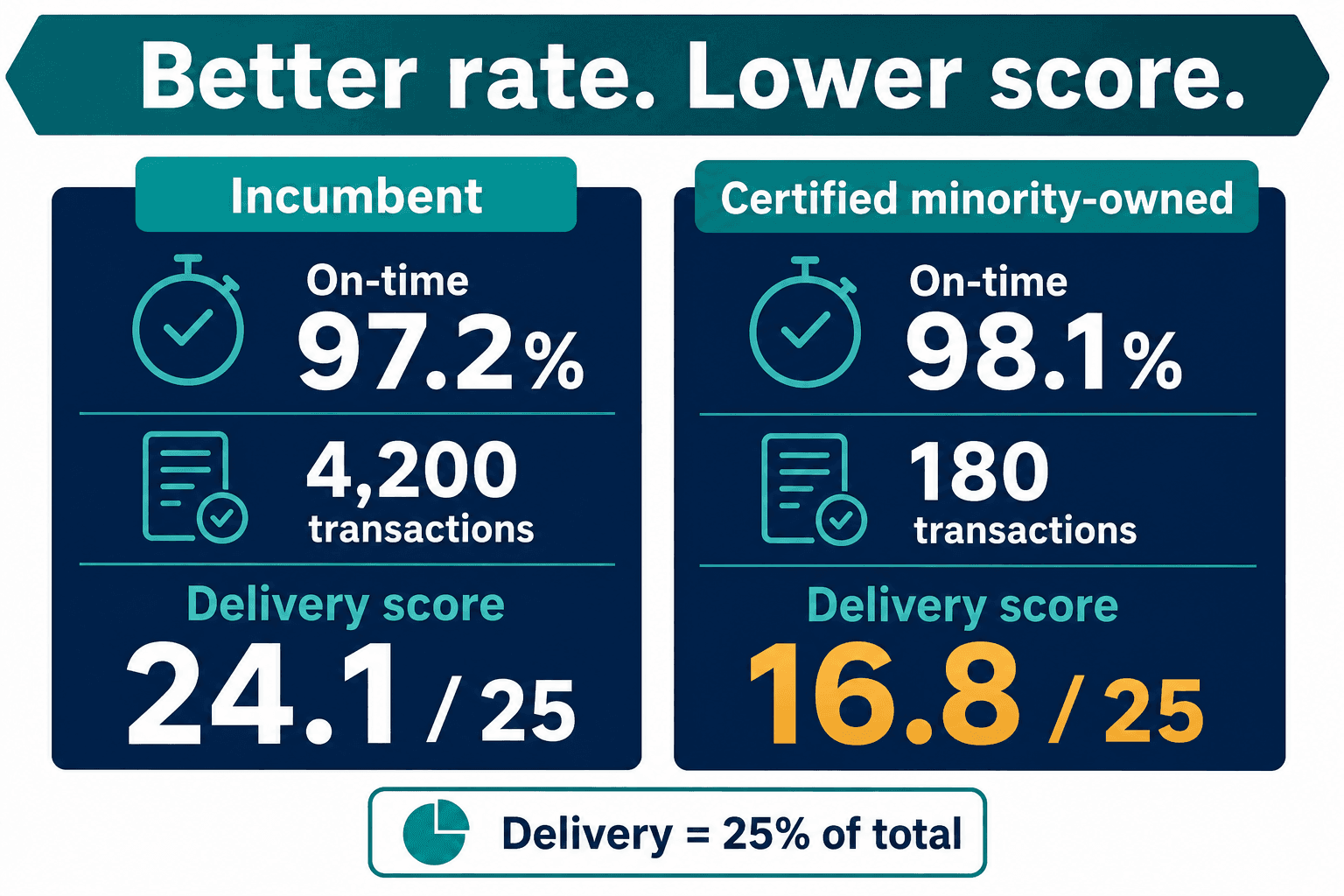
Except I didn't move on. I pulled the delivery sub-scores apart, line by line, and what I found is the reason I now spend my time building procurement AI fairness auditing for a living. The smaller supplier had a better on-time delivery rate — 98.1% against the incumbent's 97.2%. And it scored lower on delivery anyway.
The supplier who performed better got ranked worse. Not because the model was biased against them — because the math was.
That gap, between what the data said and what the score said, is the whole story. Let me walk you through how it happens, why no procurement platform on the market will fix it for you, and what it actually took to build something that could.
The bias isn't in the model. It's in the history.
Here's the part that took me too long to accept: there was nothing malicious in that algorithm. Nobody coded a penalty for diverse suppliers. The bias was a structural consequence of training on historical spend data — and once you see it, you can't unsee it.
Delivery performance was 25% of the supplier score, and the AI calculated it as on-time rate weighted by transaction count. The incumbent's 97.2% across 4,200 transactions generated a confidence-weighted delivery score of 24.1 out of 25. The minority-owned supplier's 98.1% across just 180 transactions generated a 16.8. Same metric. Better raw number. Eight points lost — to confidence weighting alone.
Then the same pattern repeated everywhere. Quality scoring leaned on audit frequency, and audit frequency correlates with contract volume. Financial-stability scoring treated revenue size as a proxy for risk tolerance. By the time the model reached price competitiveness, the gap was already mathematically insurmountable.
The exclusion is self-reinforcing, and that's what makes it ugly. A supplier scores lower, so they win fewer contracts, so they accumulate fewer transactions, so their confidence score is even lower next cycle. The algorithm is equating more historical data with more reliable — and any supplier who was never given the chance to build that history pays for it forever.
AI trained on your spend history doesn't predict the best supplier. It predicts the supplier you already used.
Why won't your procurement platform fix this for you?
My first instinct was the obvious one: surely SAP, Coupa, GEP, or Ivalua already handles this. They're pouring enormous engineering into agentic AI. Joule's Bid Analysis Agent compares supplier bids and recommends awards. Coupa's Navi runs supplier discovery in natural language and the company booked something like $15 billion in customer savings in a single quarter. Ivalua ships more than thirty ready-to-use AI agents. GEP has agentic AI across its entire source-to-pay suite.
So I went looking for the fairness metrics. The disparate-impact testing. The published methodology for how they audit their own scoring engines for adverse impact.
There aren't any. I checked all four major platforms. Not one of them publishes supplier-scoring fairness metrics. Coupa acknowledges in blog posts that AI providers should "demonstrate bias mitigation" — but there's no documented audit process behind the sentence. It's a talking point, not a feature.
And honestly, once you understand platform economics, you stop expecting it. These vendors build general-purpose scoring optimized for cost reduction and risk mitigation across their entire customer base. Adding fairness constraints tuned to your subcontracting goals, your supplier categories, your regulatory jurisdiction would mean maintaining a different model configuration for every customer they have. That's not a product roadmap. That's a support nightmare.
There's a sharper edge to that than convenience. The contracts are increasingly written so the liability lands on you, not the vendor — federal courts have been expanding AI accountability, and the platform agreements quietly shift the risk to the customer. So when a passed-over supplier eventually asks why their score was 71, it's your name on the audit finding, not SAP's. And it gets worse as the agents grow more autonomous: when a bot triggers an award or a payment on its own — or hallucinates a phantom agreement that never existed — the contract has already made sure the liability is yours, not the AI vendor's. The platform gives you speed. The fairness layer — and the liability that comes with it — was always going to be yours.
The fix I was sure would work — and didn't
I'll tell you about the version I got wrong, because it's the version most teams reach for first.
If the model under-scores smaller and diverse suppliers, the intuitive fix is to put a thumb on the scale the other way. Add a diversity adjustment. Boost the certified suppliers a few points to compensate for the confidence penalty. We sketched exactly that. It felt fair. It felt corrective.
It was a trap, and the thing that exposed it wasn't an engineering problem — it was a legal one.
While we were building the boost, I was also reading through the regulatory environment our federal-contractor customers actually live in, and it had just turned into a minefield. On one side, FAR Part 19 requires contractors to hit separate percentage goals for small-business, veteran-owned, service-disabled-veteran-owned, HUBZone, and women-owned subcontractors — and enforcement had recently tightened. On the other side, Executive Order 14319, signed in July 2025, prohibits federal procurement of AI carrying "ideological biases or social agendas," explicitly naming DEI.
Sit with that for a second. A federal contractor is now legally required to advance diverse suppliers under one rule, and legally prohibited from baking a social agenda into procurement AI under another. Our diversity boost — a hard-coded thumb on the scale favoring a protected category — was precisely the kind of thing EO 14319 was written to kill. We'd have shipped a compliance liability dressed as a solution. It would not have survived the first audit.
The moment you correct bias by adding a different bias, you've built something you can't defend in a hearing room.
That failure is what reframed the entire problem for me. The goal was never to make the AI favor anyone. The goal was to make it demonstrably favor no one — and to produce the proof.
The hiring rule that cracked it open

The turning point came from an employment-discrimination rule that, as far as I can tell, almost nobody in procurement was applying.
The EEOC's four-fifths rule — 29 CFR 1607.4 — says that any group's selection rate must be at least 80% of the highest-selected group's rate. It was written for hiring discrimination. But supplier selection is structurally identical to candidate selection: you have categories, advancement rates, and a threshold. The same statistical test drops straight in.
So we ran it against real scoring output. If an AI advances 60% of non-diverse suppliers past the scoring threshold, the four-fifths rule says it must advance at least 48% of certified minority- and women-owned suppliers. In volume-weighted scoring, the actual rate we kept seeing was closer to 22%. That's a disparity ratio of 0.37 — less than half the legal floor.
That number isn't a soft signal. A 0.37 disparity ratio is prima facie evidence of adverse impact — the same standard a court would apply to a hiring discrimination claim. It's the kind of finding that turns into contract losses and audit findings, not a strongly-worded memo.
And that's why it mattered more than any fairness boost ever could: the four-fifths test doesn't favor anyone. It just measures. It gave us a way to satisfy both masters at once — to show a FAR Part 19 auditor that diverse suppliers were getting a fair shot, and to show an EO 14319 reviewer that we'd added zero ideological thumb to the scale. Just math, applied symmetrically, with a number at the end.
And this isn't only a federal problem. Most states already bake diversity scoring into their procurement evaluations — Illinois alone routes up to 20% of an RFP's technical points to supplier diversity — so the same disparity ratio that sinks a federal audit quietly bleeds a state contractor of points it was explicitly told to capture. The four-fifths test travels everywhere the scoring does.
How do you prove a procurement AI is fair?
So we stopped trying to fix anyone's model and built an audit layer that sits on top of it. That's the heart of what's now at veriprajna.com/solutions/procurement-ai-fairness: a vendor-agnostic fairness auditor that connects to SAP Ariba, Coupa, GEP, or Ivalua, reads the supplier-scoring output the platform already produces, and tests it for disparate impact.
Vendor-agnostic was a deliberate choice, not a convenience. We don't touch the platform's model — we don't have to, and frankly we don't want the liability of retraining someone else's scoring engine. We treat the AI's output as the thing under examination: pull the selection rates by supplier category, compute the four-fifths disparity ratios, decompose where in the scoring stack the gap originates (almost always the confidence-weighting, almost never price), and hand the procurement officer something they can take into a room.
That last part is the deliverable that matters. Not a dashboard that says "looks fine." A mathematical proof that the AI treats every supplier category equitably — or a specific, sourced finding that it doesn't, with the disparity ratio and the offending scoring factor named. Something a CPO can put in front of leadership, a compliance officer can file, and an auditor can't wave away.
"Isn't this just a DEI program with a calculator?"
This is the objection I get most, usually from someone who's been burned by the regulatory whiplash and is wary of anything that smells like a social agenda. It's a fair question, and the answer is no — and the distinction is the entire point.
A DEI program decides in advance that an outcome is desirable and steers toward it. A disparate-impact audit decides nothing. It measures whether the selection rates clear a long-established statistical threshold the courts apply to discrimination claims. If your AI passes the four-fifths test, the audit says so and you have your proof of neutrality. If it fails, the audit tells you which scoring factor caused it — and the fix is almost always making the math more accurate, not less, because confidence-weighting a 98.1% delivery rate down to a 16.8 isn't fair or correct.
People also ask me why this is urgent now, when procurement AI still feels early. And it is early — that's exactly the window. Across the industry, 49% of procurement teams are running AI pilots, but only 4% have reached meaningful deployment. The bottleneck isn't the technology. It's trust. Leadership won't greenlight autonomous supplier scoring they can't justify to a stakeholder or a regulator. The fairness proof isn't a nice-to-have bolted on after deployment. For a lot of organizations, it's the thing that unblocks deployment.
The third question is always about the diversity-discovery tools — Supplier.io with its 20-million-supplier database, Tealbook, Fairmarkit. Don't those already solve this? No. They help you find diverse suppliers. None of them audit whether your scoring algorithm gives those suppliers a fair shot once they're in the funnel. Finding a qualified minority-owned supplier and then letting confidence-weighting bury them at 71 isn't progress. It's a more efficient path to the same exclusion.
The wall nobody meant to build
I keep coming back to that fastener scorecard. Five suppliers, one routine event, and a piece of math that quietly decided a better-performing vendor deserved to lose — not because anyone wanted that, but because the algorithm mistook familiar for good.
That's the thing about bias in procurement AI. It doesn't arrive as prejudice. It arrives as a confidence interval, a transaction count, a perfectly reasonable-looking 25% weighting. Every step is defensible. The wall it builds is not.
You can't argue your way out of that with intentions, and you can't fix it by tilting the scale the other way — I tried, and the law was right to forbid it. You can only do one thing: measure it, prove it, and make the proof something you'd hand to an auditor without flinching. That measurement-not-correction stance is the whole of what we build at Veriprajna. Your procurement AI is fast. The only question that's going to matter, the first time a passed-over supplier asks why, is whether you can prove it was fair. If you can show the disparity ratio and the audit that produced it, you have an answer. If you can't, you don't have a fairness problem — you have a discovery problem waiting for a subpoena.