The COBOL Migration That Compiled Perfectly — and Still Corrupted the Ledger
The code was perfect. That was the whole problem.
A wire-transfer program had been translated from COBOL into Java. It compiled. The unit tests passed. It cleared every gate we'd built to catch mistakes. Then, in user-acceptance testing, the very first transaction tripped the database's consistency check and the whole thing fell over.
The autopsy took longer than it should have, because nothing in the Java looked wrong. The culprit was a variable called TRN-LIMIT. The translation tool had read it as an ordinary number and given it a standard integer type. But TRN-LIMIT was never defined where the tool was looking. It was declared in a copybook — a shared header file — pulled in thousands of lines earlier in the execution chain, and that copybook carried a REDEFINES clause: a COBOL construct that lets the same slot of memory be read as two completely different data types depending on a flag set somewhere else entirely. On the mainframe, that address held a packed decimal. The new Java code wrote corrupted binary into the database column, and the ledger's referential integrity gave way.
The code was syntactically flawless. The failure was contextual. The tool had missed a dependency that lived outside its field of vision — and in legacy COBOL modernization, that is almost always how the money disappears.
Modernization projects don't usually die on the code you can see. They die on the code the tool couldn't.
This is the story of why I stopped believing that better translation was the answer, and what we built at Veriprajna instead.
Why Does "Paste COBOL, Get Java" Always Demo Well?
If you've sat in any mainframe modernization meeting in the last two years, you've heard the pitch: paste your COBOL, get back Java. It's seductive because the demo always works. Someone drops in a tidy 200-line program, the model returns clean, idiomatic Java, and everyone in the room exhales. Finally.
I believed it too, for a while. When my team first went at this, we did the obvious thing — we tried to make the translation better. We fed models more context, tuned them for COBOL's quirks, benchmarked output quality. There's even a fine-tuned open model called XMainframe, built specifically for this, that scores about 30% higher than general-purpose code models on COBOL tasks. The translations got cleaner. The Java got more readable.
And it still broke in UAT. Over and over, on exactly the kind of hidden dependency that sank that wire-transfer program. That was the month I realized we were polishing the wrong thing. The quality of the translation was never the bottleneck. The code that compiles is the easy part. The hard part is the code the tool cannot see.
The numbers around this are brutal and consistent: 70 to 80% of mainframe modernization projects fail to meet their objectives. Not 70% run late — 70% fail. The usual diagnosis blames underestimated testing or messy data migration, and those are real. But underneath almost all of them is the same root cause I'd just watched live: the tools treat a codebase as text to be converted, when it is actually a topology to be understood.
What "Paste COBOL, Get Java" Cannot See
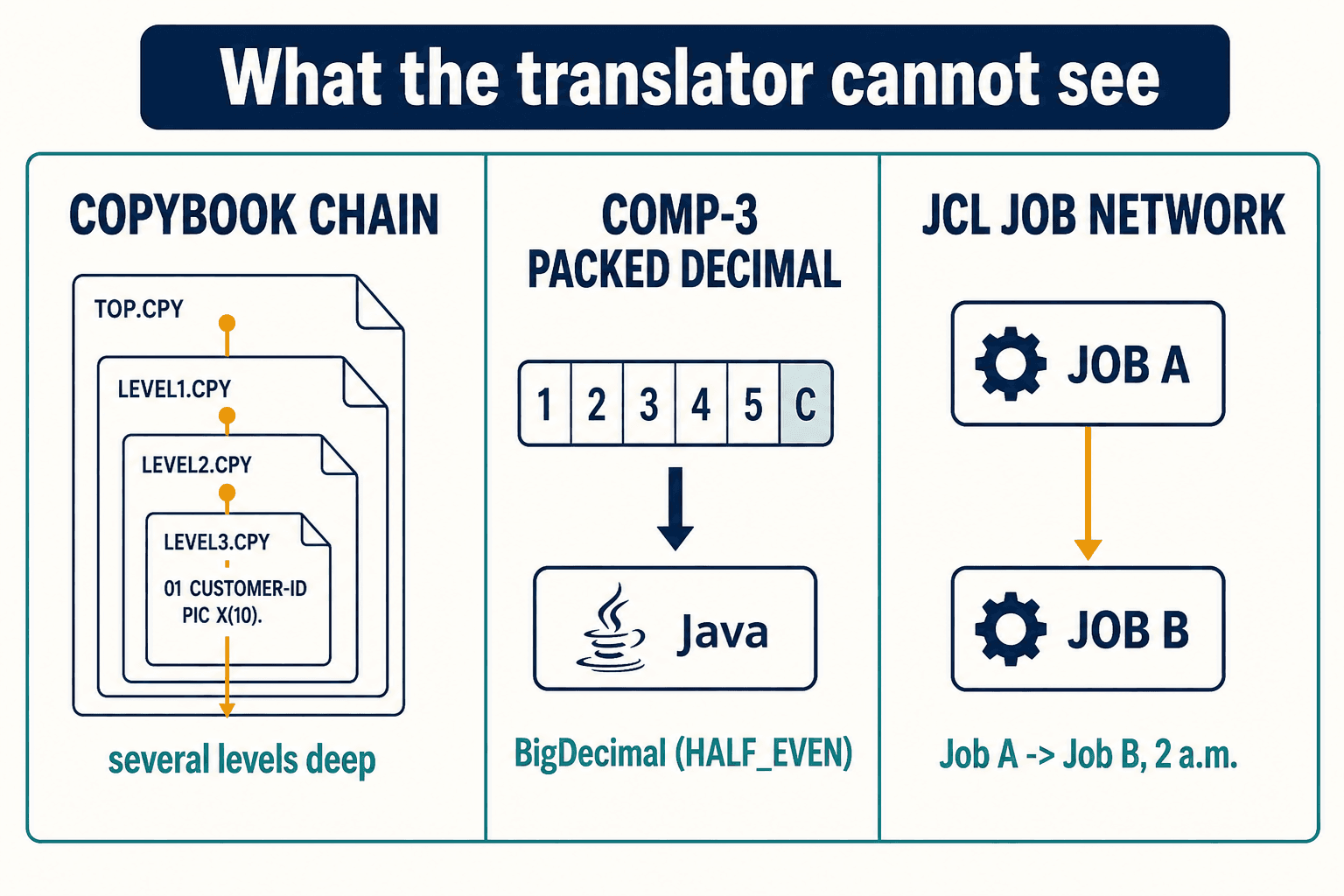
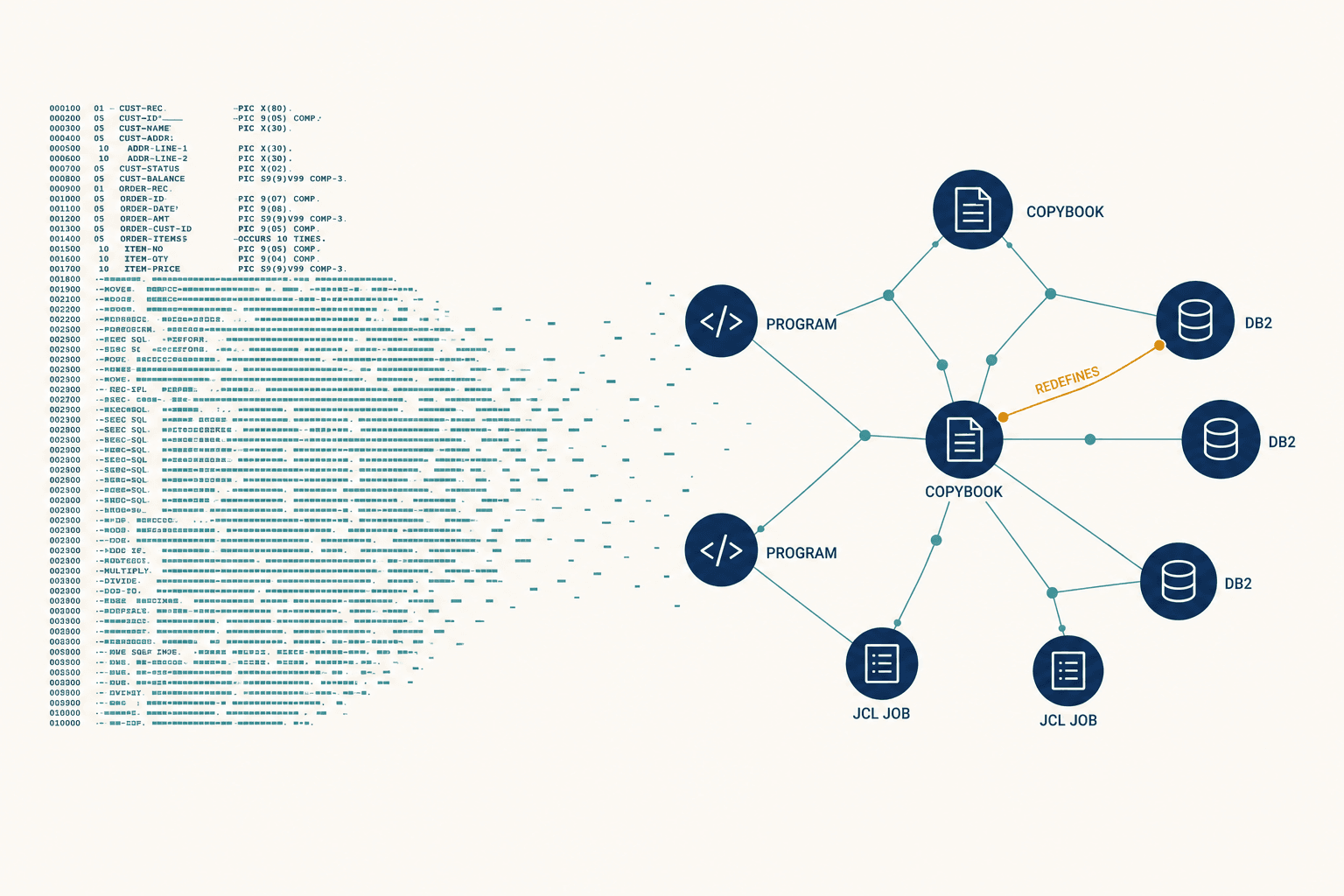
Once you start looking for contextual blindness, you see it everywhere. Three patterns broke us most often, and none of them are visible in the source file a translator is staring at.
Start with the copybook problem I already described. A single COBOL program can reference more than forty copybooks, and those copybooks include other copybooks, so a variable's real definition can sit several levels deep in the inclusion chain. A text-based tool reads the statement in front of it and infers a type. It has no way to know that, in a packed-decimal field, that inference is silently wrong.
Then there's the arithmetic. COBOL's COMP-3 packed decimal has no native equivalent in Java. Reach for a double and you've just introduced floating-point rounding into a system that moves money. Even BigDecimal, the correct tool, doesn't match COBOL by default — you have to explicitly pin its rounding mode to HALF_EVEN to mirror COBOL's ROUNDED clause. Get it wrong and you're off by a penny per transaction. That penny compounds across millions of transactions until, weeks later, a reconciliation report flags a variance nobody can explain.
The pattern almost everyone forgets is the one that actually takes down production: your COBOL doesn't run by itself. A scheduler — CA-7 or TWS — orchestrates somewhere between two thousand and five thousand batch jobs, with dependency chains threaded through them. Job A writes a dataset at 1 a.m. that Job B reads at 2 a.m. You can migrate every line of COBOL flawlessly and still bring the bank down at midnight, because nobody mapped the job network. The production graph was never in the source code. It was in the JCL.
The job that breaks production at 2 a.m. is never the one you were looking at.
This is what I mean by topology. The artifact that actually runs your business is a web of relationships — programs, copybooks, datasets, scheduled jobs, DB2 tables, CICS transactions — and the COBOL source is only one strand of it.
Why I Stopped Trusting the Translator and Started Drawing the Map
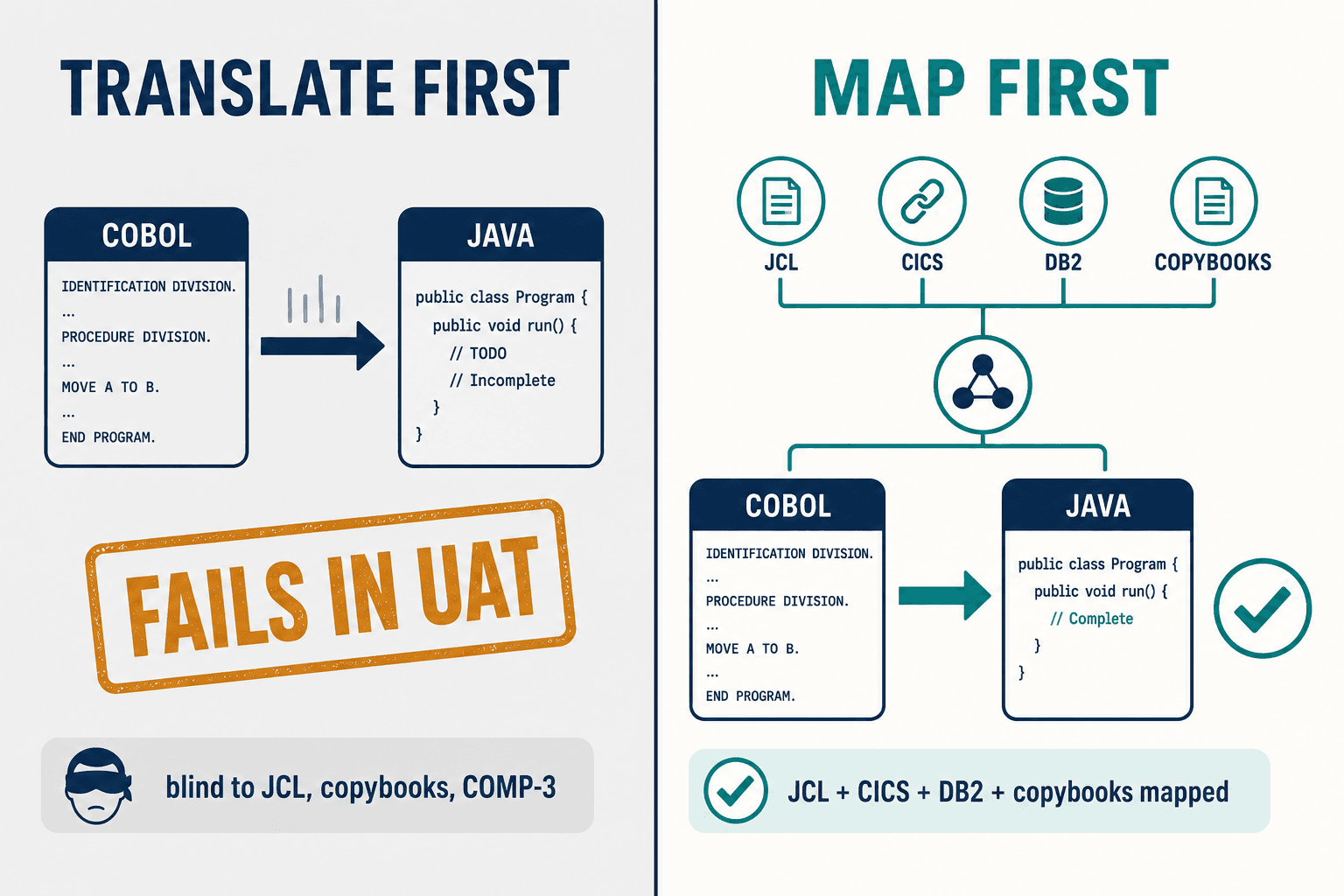
The turning point for us was deciding that the map is the product.
Before we translate a single line, we build a knowledge graph of the entire codebase — every program, every copybook edge, every JCL dependency, every dataset hand-off, every DB2 touchpoint — and we resolve the transitive relationships the source files hide. When you can see that one program has forty-plus copybook edges and that one of them carries a REDEFINES two modules away, the TRN-LIMIT disaster simply doesn't happen, because you knew the field was packed decimal before you typed a character of Java.
I want to be precise about why this is different from what the rest of the field sells, because the field is crowded and most of it is genuinely good at the part it solves.
IBM's watsonx Code Assistant for Z is the most serious incumbent — an agentic system, with orchestration, architecture, and code agents, that handles COBOL-to-Java and even PL/I and IMS, and it analyzes CPU consumption right down into copybooks. It is also a $2M-plus commitment that runs on z/OS and leans on IBM's ADDI tooling, which quietly locks you to the mainframe during the migration meant to free you from it. It doesn't do behavioral-equivalence testing, and it doesn't map your JCL job network.
Then there's the moment that reshaped the whole market. In February 2026, Anthropic published a COBOL-modernization playbook for Claude Code; IBM's stock dropped 13.2% the day of the announcement, and a $100M partner network followed in March. Claude Code is excellent at discovery, documentation, and reading unfamiliar code — genuinely useful in the early phases. But it's a general-purpose tool. It has no built-in knowledge graph for resolving transitive dependencies, and it doesn't pretend to solve JCL scheduling, behavioral equivalence, or the audit trails a regulated bank has to produce.
Microsoft's Azure migration factory targets Java Quarkus and locks your target platform to Azure. The big systems integrators — DXC with its patented conversion engine, TCS with MasterCraft, Infosys with Cobalt, Accenture — run $500K-to-$5M-plus engagements and implement vendor tools rather than building intelligence about your system; Accenture led the Commonwealth Bank of Australia core migration that ran roughly $749.9 million and took five years. And Micro Focus's Visual COBOL, often pitched as a starting point, isn't modernization at all — it's rehosting. Your COBOL keeps being COBOL, just on a new runtime. The technical debt and the workforce problem are exactly where you left them.
Every one of these does something real. What none of them does is build the complete dependency topology — JCL, CICS, DB2, copybooks, and all — first, independent of any target platform, and treat that map as the foundation everything else stands on.
Most vendors sell you a better translator. The translation was never the part that failed.
The Clock Nobody Can Stop
Here's the part that turns this from an engineering problem into an emergency.
The people who understand these systems are leaving. The average COBOL developer in the US is around 55. Roughly 10% of that workforce retires every year, and 85% of universities dropped COBOL from the curriculum back in the 1990s, so almost nobody is replacing them. Sixty percent of organizations now say finding skilled COBOL developers is their single biggest modernization challenge — and 58% of the developers who still know these stacks say they're considering quitting because of them.
I've stood at the version of this that haunts me: the retirement party for the one person who actually understood the batch window. Everyone's smiling, there's a cake, and somewhere in the back of my head a voice is saying that knowledge just walked out the door and it is not written down anywhere. A knowledge graph is, among other things, a way to capture what's in that person's head before the party — to make the dependency map outlive the people who memorized it.
And the stakes are not small or abstract. Around 220 billion lines of COBOL are still in active production. It runs 95% of ATM transactions and clears roughly $3 trillion a day. Forty-three percent of banking systems are built on it. US technical debt sits at an estimated $1.52 trillion, and the average enterprise burns around $370 million a year on legacy inefficiency, with financial-services firms spending 70 to 75% of their IT budgets just keeping the old systems breathing. The teams that get the migration right report returns of 114 to 225% and around $25 million a year in savings — but that upside only exists on the far side of a migration that didn't fail. This is the rare modernization where doing nothing is the expensive option.
Won't the New AI Tools Just Solve This?
This is the question I get most, and it's fair, especially after the Anthropic announcement made it look like the problem had just been declared solved.
My honest answer: the new tools made the discovery phase dramatically faster, and that's real progress — I use them. But agentic AI getting good at reading COBOL doesn't change the thing that actually kills projects. Gartner expects 40% of enterprise apps to include task-specific AI agents by 2026; more agents translating code faster doesn't help if they're all blind to the same JCL dependency. Speed on the wrong problem is just a faster way to reach UAT and fail there.
The other question I get is about regulation, and it's the one mid-tier banks underestimate. The EU's Digital Operational Resilience Act — DORA — took effect in January 2025 and demands operational-resilience and threat-led penetration testing that legacy systems were simply never designed to pass. US examiners at the FFIEC and OCC treat aging infrastructure as a live compliance gap, and systems older than ten years carry roughly three times the breach probability. A migration that can't produce an audit trail proving the new system behaves identically to the old one isn't a modernization — it's a new liability with better syntax.
That's why behavioral-equivalence testing matters as much as the map. The technique is straightforward to describe and hard to do well: capture real inputs and outputs from the legacy system — a golden dataset — and replay them against the new one until the behavior matches, edge case for edge case. Those edge cases, accumulated over decades, often encode regulatory logic that exists nowhere else — not in a spec, not in a person's head, only in the running code. I've watched this bite a carrier harder than a bank: the rating rule that only fires for a 1998 policy endorsement, the claims-reserve calculation whose rounding nobody alive can explain but every audit depends on. Lose them silently and you'll find out which ones mattered the day a regulator asks.
Which Brick Do You Pull First?
Once you have the map, it tells you something no translator can: where it's safe to start.
The dominant strategy now — for good reason — is the strangler fig: instead of a big-bang rewrite, you extract one capability at a time, run old and new side by side, and keep the legacy system as a live fallback until the new piece has earned trust. But every vendor that recommends the strangler fig leaves out the hardest question — which module do you strangle first? Pick a deeply-coupled one and you've recreated the big-bang risk with extra steps.
The knowledge graph answers it directly. It surfaces the lowest-coupling modules — the ones with the fewest inbound dependencies — so you can extract a real piece of the system, prove the approach, and build organizational confidence before you touch the dangerous core. The map isn't just insurance against the TRN-LIMIT failure. It's the sequencing plan.
We built all of this — the dependency knowledge graph, the strangler-fig sequencing, the behavioral-equivalence harness, deliberately independent of any target platform — into Veriprajna's legacy COBOL modernization practice, aimed squarely at the mid-tier banks and insurers that the $2M-floor incumbents and the seven-figure SIs treat as too small to bother with.
What I'm Honest About
I won't pretend the technology solves everything, because the most expensive failures I've seen weren't technical at all.
No tool — ours included — fixes organizational buy-in, cleans up years of bad data, or wins the political fight of convincing two hundred developers to change how they work. The market is projected to grow from about $9 billion in 2026 toward double that by the end of the decade precisely because so much of the spend goes to the human and organizational layer, not the compiler. And no parser on earth, open-source or commercial, perfectly covers every construct in IBM Enterprise COBOL — the pre-1985 ALTER statements, the deepest REDEFINES. Anyone who tells you otherwise is selling you the gap. The technology is necessary. It has never been sufficient.
But the part the technology can own, it must own completely. The reason migrations burn through millions and deliver nothing is rarely that someone wrote bad Java. It's that they translated a system they had never actually mapped — converting strands of a web while the web itself stayed invisible until the night it tore.
Draw the map first. A system that's outlived the people who wrote it doesn't forgive a missed dependency, and there is no version of this work that's safe before you can see what connects to what. We learned that from a ledger undone by a single packed-decimal field nobody knew was there. Find those fields before they find you.


