A Green Citator Flag Won't Save You: What Legal AI Hallucination Actually Looks Like in 2026
When two attorneys walked out of the Sixth Circuit in March 2026 owing $30,000 between them, the cited cases in their brief were not all imaginary. That detail is the one nobody wants to sit with, and it is the reason I spend my days building what I build.
I came to this from inside the problem. Before Veriprajna, I worked as a litigation associate, and the part of the job nobody romanticizes is cite-checking — sitting at 11pm with a redlined brief, circling a citation, scrawling does this case actually say this? in the margin. When the first wave of legal AI arrived, I assumed it would make that night disappear. Instead it made the night more dangerous, because the tools got very good at producing citations that look checked. Legal AI citation verification turned out not to be a feature you switch on. It is a layer somebody has to build, and almost nobody had.
Here is the claim I want to defend in this essay: the hallucination that will get a firm sanctioned in 2026 is not the one your current tools are designed to catch. The famous failure — the invented case — is mostly solved. The failure that is escalating is the real case, cited wrong, wearing a green flag.
Everyone Remembers Mata. Almost Nobody Learned the Right Lesson
You know the story even if you don't know the name. Mata v. Avianca, 2023: a lawyer asked ChatGPT for supporting cases, it produced Varghese v. China Southern Airlines — convincing docket number, plausible court, detailed internal citations — and the case did not exist. A $5,000 fine and a career's worth of embarrassment followed.
The lesson the profession took from Mata was "the AI makes up cases." So the industry built defenses against made-up cases. Thomson Reuters has KeyCite. LexisNexis has Shepard's, the gold standard, decades old. Harvey grounds its output in the LexisNexis data vault. These citators are genuinely good at the Mata problem: feed them a citation that resolves to nothing, and they tell you it resolves to nothing.
The trouble is that the profession solved the 2023 problem and assumed it had solved the 2026 one.
Watch what actually happened in New Orleans in February 2026. An attorney was sanctioned for submitting eleven fabricated or mischaracterized citations. The part that should keep you up: he had used both ChatGPT and Westlaw Precision AI. He used the grounded, purpose-built, citator-backed tool — and still filed a brief that earned a sanction. "Reduce" is not "eliminate," and the gap between those two words is where the liability now lives.
The Failure Your Tool Can't See

Let me describe the failure mode precisely, because the precision is the whole point.
The AI cites a real case for a proposition the case does not support. The docket number is valid. The case exists. KeyCite returns a green flag. Shepard's agrees. And the analysis is still wrong — because the AI cited the dissent as if it were the majority holding, or cited a case interpreting a version of a statute that was amended two years ago.
This is what the Stanford study, peer-reviewed in the Journal of Empirical Legal Studies in 2025, actually measured when it put Westlaw Precision's hallucination rate at 33% and Lexis+ AI's at 17%. People read "33% hallucination" and picture a tool inventing cases one query in three. That is not what those numbers are. They are mostly wrong analysis of real citations. Your verification tool confirms the case exists. It does. It just never claimed to check what the case says.
I'll make it concrete, because this is the example that finally made my own team stop arguing. A litigation associate asks an AI assistant to research defenses to a breach-of-fiduciary-duty claim under Delaware law. The tool returns a clean analysis citing Stone v. Ritter (2006) for the standard of director oversight liability. The citation is real. The holding summary is accurate — for 2006. What the tool missed is that the Delaware Supreme Court's 2019 decision in Marchand v. Barnhill significantly expanded the Caremark oversight duty, and Chancery Court opinions since have built a "mission critical" compliance standard on top of it.
Stone v. Ritter still carries a green KeyCite flag. It was never overruled. It is still "good law." And a brief that leans on it for a 2026 filing is still wrong, because the practical reach of the holding was narrowed by everything that came after — exactly the kind of development a citator flag is not built to surface.
A citator tells you a case is alive. It does not tell you the case still means what your AI says it means.
That is the difference between citation fabrication and contextual hallucination, and it is the single most important distinction in this entire field. The junior associate reviewing the output under deadline will not catch it, because the citation looks right. It is right, in the only sense the tool was ever checking.
We Got This Wrong First — And I'm the One Who Argued For It
I want to be honest about how I learned this, because I didn't reason my way to it. I shipped the wrong thing first.
When my team built our first verification checker, I argued — in our own design review, out loud, with some confidence — that if the case is real, we're fine. So our first pipeline essentially re-ran the citator logic. It confirmed every cited case existed and pulled its treatment status. Fast, clean, and in a pilot it sailed a brief straight through to a green dashboard.
Then one of the pilot users, an actual litigator, pushed back on a paragraph our tool had blessed. The cited case was real. Our checker loved it. The holding the brief attributed to it was from the portion of the opinion that didn't control. Our system had no opinion about that, because I had designed it to have no opinion about that. I had rebuilt Shepard's and called it verification.
That was the failure that paid for everything we did next. Re-running a citator faster is not verification — it's the same blind spot with a nicer interface. The pivot was forced on us: we had to build a layer that reads past citator status into subsequent citing references, that asks whether later cases distinguished or narrowed a holding, that flags an opinion whose core proposition has been substantively modified even though the case itself remains good law. That is the engineering problem. The citator was never going to solve it, no matter how fast we ran it.
Why Doesn't Buying Harvey Close the Gap?
People assume the platform vendors will fix this, and I understand why — the platforms are extraordinary, and the money says everyone agrees. Harvey reached an $11 billion valuation in March 2026 on roughly $190 million in annual recurring revenue, with custom agents numbering past 25,000 and adoption inside half the AmLaw 100. Thomson Reuters bought Casetext for $650 million and folded it into CoCounsel's agentic workflows. LexisNexis replaced Lexis+ AI with Lexis+ Protege in February 2026 — four specialized agents, 300-plus pre-built workflows.
These are not the problem. I tell firms this plainly: keep your platform. The gap is that none of these tools ship an independent verification layer, and the better ones are honest that output verification is the user's responsibility. There is a reason LexisNexis quietly walked back its "100% hallucination-free" language after the Stanford numbers landed.
And the platforms have made the verification problem harder, not easier, by going agentic. When a long-horizon agent runs a multi-step research-and-drafting workflow, the output isn't one cited paragraph — it's a chain of them, each step feeding the next, each a place a contextual error can enter and propagate. When a junior associate Slacks me at 11pm asking whether the agent's output is safe to file, the honest answer is: not until something has read every citation against what the cited case actually holds, and logged which agent step produced it. That audit trail is not a nice-to-have. It is the thing a judge's standing order increasingly demands. And this isn't a fringe workflow I'm bracing for — corporate legal AI adoption doubled from 23% to 52% in a single year, and Gartner expects 40% of enterprise applications to embed task-specific agents by 2026; the chain-of-citations failure mode scales with every one of them.
So What Actually Catches a Real Case Cited Wrong?
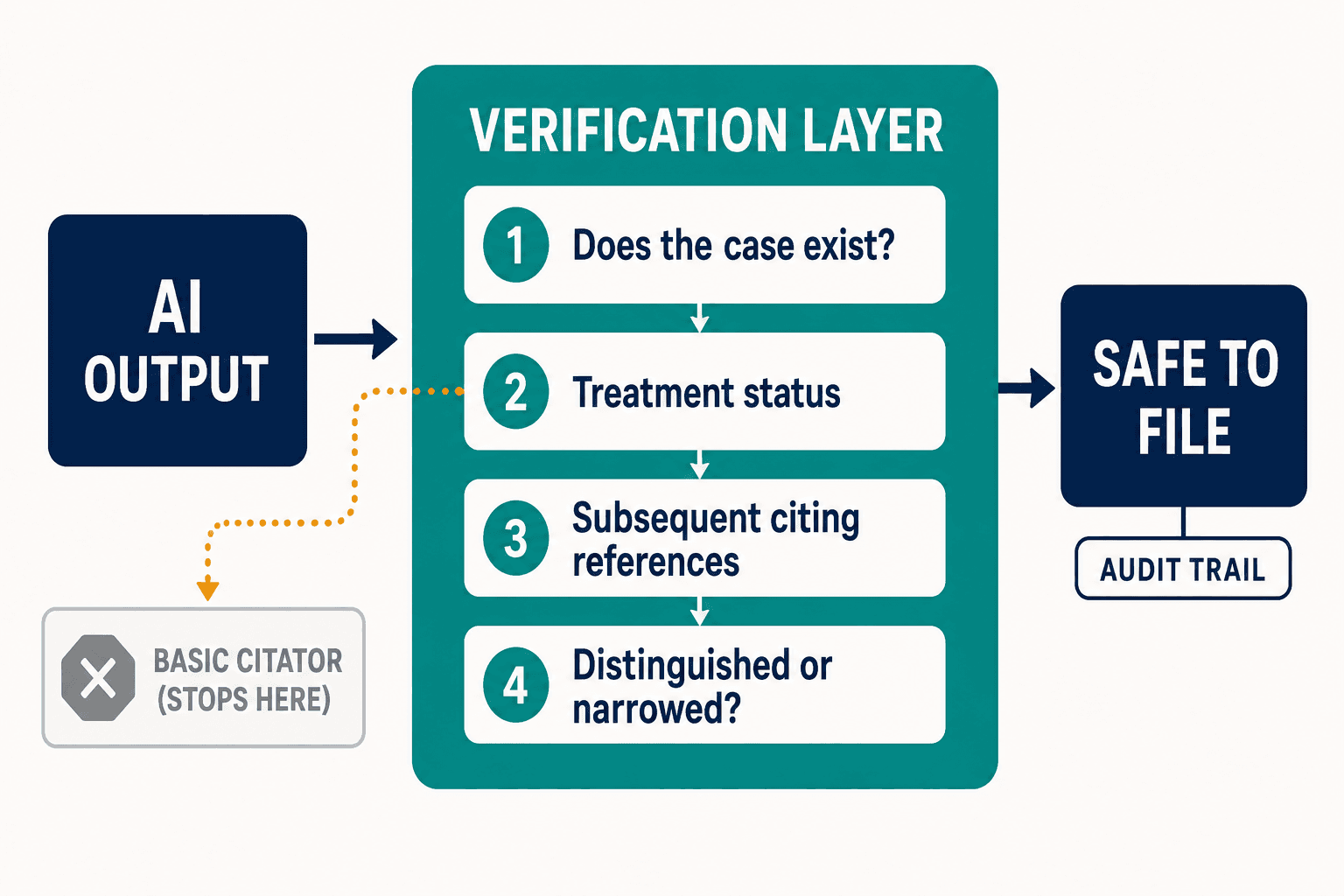
Not a different AI — a different job. The verification layer sits between the AI's output and the human's signature, and it does what the citator won't: instead of stopping at whether a case is still good law, it reads into the subsequent citing references, asks whether later opinions have distinguished or narrowed the holding, and flags the cases whose core proposition has been substantively modified even when the headnote still reads clean. The treatment status is the start of the inquiry, not the end of it.
Underneath, the retrieval matters more than people expect. Vector search — the default in most retrieval-augmented systems — finds cases that are textually similar to a query. Legal authority isn't organized by textual similarity; it's organized by how cases cite, distinguish, and overrule each other. That's a graph, not a list. Retrieval built over a legal knowledge graph rather than a flat vector index has been shown to outperform vector search by roughly 14% in retrieval relevance for legal work — the difference between surfacing the case that controls and surfacing the case that merely sounds like it controls. The graph is how you find the Marchand that quietly reshaped the Stone everyone still cites.
This is the layer we build at Veriprajna — the citation verification pipeline, knowledge graph infrastructure, and governance systems that make AI output safe to file — and we build it around whatever platform a firm already runs, Harvey or Lexis Protege or an open-source model, rather than asking anyone to rip out a tool that works.
The Part Nobody Puts on a Slide: Governance
There is a second problem underneath the technical one, and it's the one that turns a sanction into a malpractice claim.
Roughly 68% of legal professionals admit to using an unapproved AI tool at least once, and fewer than one firm in five has a formal AI policy — even as nearly seven in ten lawyers now use generative AI for work, a share that doubled in a single year. So most firms have lawyers feeding client matters into tools nobody approved, with no record of which tool, no verification step, and no audit trail. Malpractice insurers have noticed. They are writing AI usage into policy considerations, and unauthorized use without attorney oversight is exactly the kind of thing that voids coverage when a claim lands.
The regulatory floor moved too, and most firms haven't met it. ABA Formal Opinion 512, issued in July 2024, lays out six ethical obligations for generative AI — competence, confidentiality, candor to the tribunal, supervision among them — and it carries two edges people miss. You cannot bill a client for the time you spend learning a tool you'll use regularly. And a federal court has already held that AI-generated work product isn't shielded by attorney-client privilege. Meanwhile more than 300 judges have issued their own AI standing orders, each with its own disclosure or certification requirement, Florida added a disclosure mandate in February 2026, and no firm I've met has a systematic way to track which judge demands what. And the floor is still rising: the EU AI Act takes force in August 2026, Colorado's AI Act in June, and the EU's Product Liability Directive now treats AI as a product under strict liability — which moves the exposure from a single sanctioned associate onto the firm's balance sheet.
Shadow AI isn't a discipline problem. It's an infrastructure gap — people route around tools that don't fit the way they work.
A governance system worth the name doesn't just document a policy in a PDF nobody reads. It enforces the policy in the workflow, logs every AI-assisted citation, generates the disclosure language a given jurisdiction requires, and produces the audit trail that lets a supervising partner certify, honestly, that every citation was checked.
The Questions Firms Always Ask Me
It usually opens with some version of: if I verify every citation by hand, haven't I thrown away the efficiency the AI gave me? Yes — which is the whole point of building the verification into the pipeline instead of leaving it to a tired associate at midnight. Manual cite-checking of AI output doesn't scale, and skipping it is the malpractice risk. The layer exists precisely so the speed survives the safety.
Then comes the skeptic's version: isn't this overkill — how often does contextual hallucination really bite? The Charlotin hallucination database had passed 1,222 documented cases of AI hallucination in U.S. court filings by early 2026, up from 729-plus at the end of 2025. The curve is going the wrong way, the sanctions have climbed from $500 slaps to five-figure penalties as routine, and that count only captures the ones that got caught and published. I keep that database open in a tab. The number ticks up while you're not looking.
And from a managing partner, almost always: can't a Big Four firm or a large systems integrator just handle all of this? They can configure your platform, and they'll charge $500K to $2 million to do it. But configuring Harvey is deploying a platform — it is not building the verification layer the platform deliberately leaves to you. Those are different problems, and only one of them is the one that gets you sanctioned.
What I'd Tell the Associate at 11pm
The legal AI market is heading from roughly $5.6 billion in 2026 toward $12.5 billion by 2030, and legal research is its single largest slice. That growth is real and the tools deserve it. But the entire industry is optimizing for output — faster research, more agents, longer autonomous workflows — and treating verification as someone else's responsibility, which in practice means nobody's.
The case that sanctions you in 2026 will pass every check your current tools run. It will exist. It will carry a green flag. It will be cited for something it doesn't quite say, and the version of you reading it at midnight under deadline will not catch it, because everything on the screen says it's fine.
That's not a reason to distrust legal AI. It's a reason to build the one layer the platforms left out — the verification and governance layer that reads what the case actually holds, not just whether it's still breathing. The firms that install it will keep the speed. The ones that don't will keep finding out, one show-cause order at a time, what a green flag was never promising them.