
The AI Tracked a Bald Head for the Whole Match. More Training Data Won't Fix That.
In October 2020, an automated camera at a Scottish soccer match spent the entire game tracking a linesman's bald head instead of the ball. The clip went viral. Most people laughed at it as a cute glitch. I watched it on loop for a different reason: the system wasn't broken. It was doing exactly what we'd built it to do.
That clip is the cleanest possible illustration of why physics-constrained computer vision is the only thing that makes vision systems trustworthy in production — and why pouring more training data on the problem, which is what I tried first, doesn't fix it.
Under stadium floodlights, a bald head produces specular highlights — bright, round, white reflections — with pixel gradients statistically indistinguishable from a soccer ball. The detector, a standard CNN of the YOLO family, processed each frame on its own and assigned 98% confidence to "ball" on the head. The actual ball, blurring through shadows at speed, scored 80%. The system followed the higher number. That's not a bug. That's the model believing its own eyes.
A detector finds patterns. It has no idea that a "ball" sitting at a constant 1.7 meters off the ground, attached to a vertical cylinder, walking the touchline, is physically impossible.
The fix is not a better dataset. The fix is physics.
The Bald-Head Problem Is Everywhere — It Just Doesn't Always Go Viral
I spent years shipping vision pipelines in two worlds that look nothing alike: stadium gantries tracking a ball, and fab lines inspecting silicon. They share one disease. The model sees a shape it recognizes and reports it, with no mechanism to ask whether what it's reporting could exist in the physical world.
In semiconductor inspection, the symptom isn't a bald head — it's the nuisance defect. KLA owns about 63% of the process-control market, and their 2900-series broadband tools can resolve features as small as 10 nanometers. Detection sensitivity is not the bottleneck. The bottleneck is that a single broadband scan flags thousands of anomalies per wafer, and most of them are dust, surface artifacts, or pattern noise that will never touch yield. Each one still has to be classified by a deep-learning model trained on a library of historical defects.
Here's what that model doesn't have: any understanding of how light physically interacts with a pit versus a stain versus a process residue. So when a fab transitions to a new process node — say, gate-all-around at 2nm — the training library goes stale overnight and the nuisance rate spikes. And the cost of being wrong is not abstract. A 1% yield loss at advanced nodes runs into millions, because a single wafer can cost tens of thousands of dollars.
The manufacturing floor has the same disease with a quieter, nastier presentation. On a production line running AI quality control, you almost never know in real time when the model is wrong, because there are no ground-truth labels sitting next to the camera. A lighting angle shifts after maintenance. A lens hazes over a few weeks. A fixture wears. False rejects climb and you get rework loops, or false accepts creep in and you get escapes — and you find out which one only when a quality escape forces a containment, a quarantine, a full re-inspection.
The model didn't fail loudly. It drifted in silence, and the first alarm was a customer return.
That silence is expensive. The cost of poor quality runs around 20% of total sales for the average manufacturer. A defect caught in planning costs about $100; the same defect caught in production costs $10,000. Intel has reported saving roughly $2 million a year just by avoiding scrap with AI inspection. The upside is real — which is exactly why the silent-drift failure mode is so corrosive. It eats the upside without telling you.
And the overcorrection is just as costly as the drift. I've watched a multi-million-dollar automated optical inspection rig get quietly switched off because its tuning was so aggressive it rejected good parts faster than it caught bad ones — it couldn't pass a Knapp test, the standard that asks whether your inspection actually distinguishes defects from acceptable variation. A system that protects yield on paper and destroys it in practice is worse than no system, because someone paid for it and someone now distrusts every automated decision it touches.
Why Doesn't More Training Data Fix This?
When my team first hit this wall, I was certain about the answer, and I was wrong.
The orthodoxy in computer vision is that edge cases are a data problem. Your model fails on the weird stuff because it hasn't seen enough weird stuff, so you go collect more of it. I believed that. I backed it. We built a much larger, much more diverse dataset — different lighting, different angles, more of the confusing cases — and retrained. The model's numbers on the validation set were beautiful. I remember feeling like we'd closed the gap.
Then we put it on a real line, and a maintenance crew adjusted a light fixture, and the reject bin started filling with good parts.
Nothing in our gorgeous dataset covered that exact new lighting geometry, because that geometry hadn't existed when we collected the data. We could have gone and collected that too — and then chased the next shift, and the next lens haze, forever. That's when the sentence that had been nagging at me finally landed: edge cases aren't 5% of the problem. They're 80% of the engineering time, 90% of the support cost, and 100% of the liability. You cannot enumerate your way out of an infinite set.
One of my engineers wanted to keep tightening — raise the confidence threshold until the false positives went away. It works on a slide. In practice, pushing toward zero false positives just trades them for false negatives: now you're missing the real defects, the real threats, the things you actually deployed the system to catch. After enough of those arguments I had to say it out loud: every knob we knew how to turn was a way of moving the failure around, not removing it.
This is not a fringe experience. Roughly 95% of computer vision projects never reach production, and the reason is almost never the algorithm — it's exactly this kind of implementation breakdown, the gap between a model that works in the lab and one that survives the floor. MIT research found 95% of enterprise AI pilots failed to deliver measurable ROI within six months. We were about to become a line item in that statistic.
What Physics Constraints Actually Do
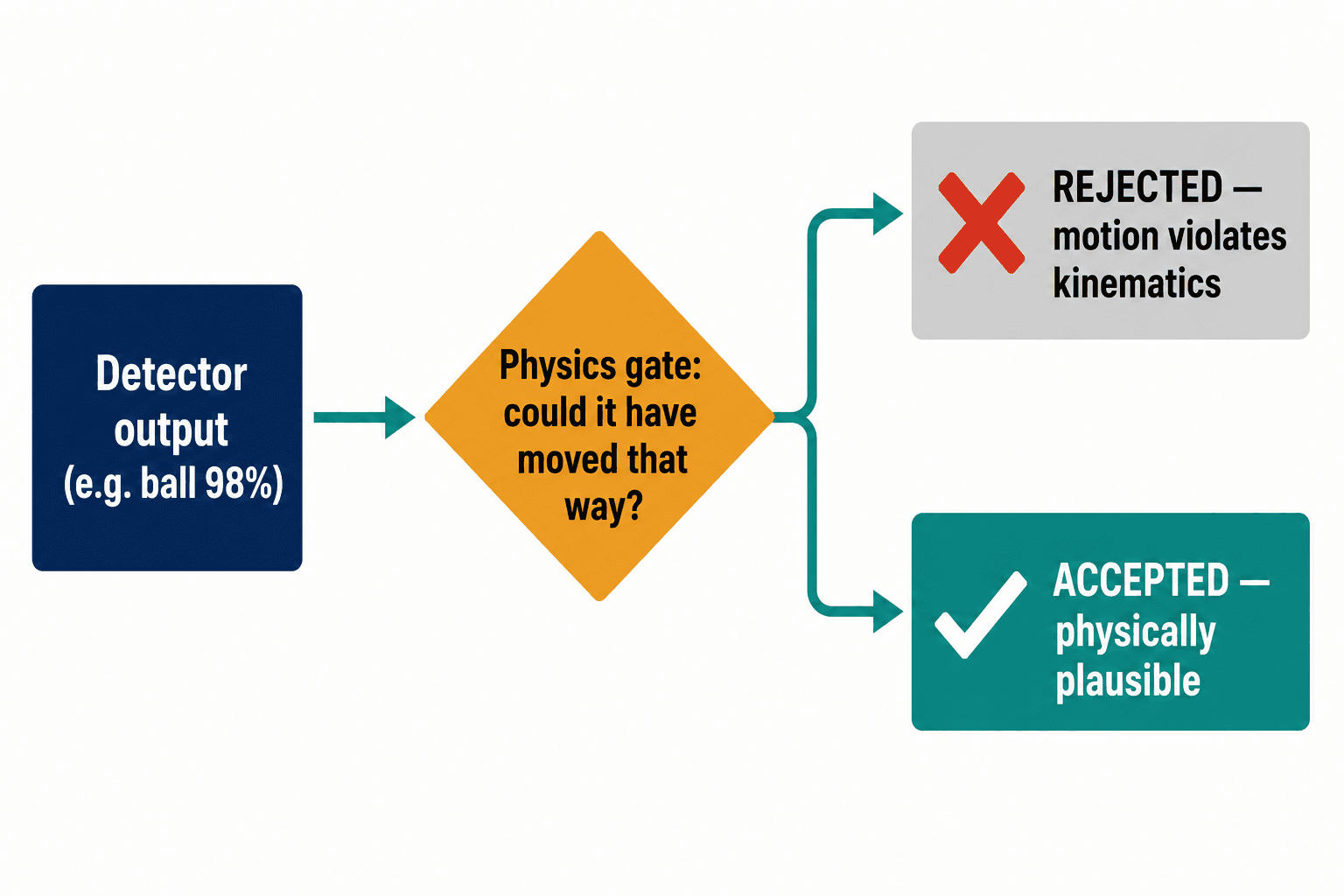
The turning point was small and almost embarrassing in hindsight.
Instead of asking the detector to be more certain, we put a gate in front of its output that asked a physics question: could this thing have moved the way you say it moved? A track that violates the kinematics of an object with mass and momentum — a detection that jumps a distance no ball could cover between two frames — gets rejected before it's ever believed. We didn't touch the detector. The false-positive rate dropped anyway.
That's the whole idea, and it generalizes. A tracked object can't teleport between frames. A real defect has parallax — it shifts against the background as the viewpoint changes, the way a shadow never will. A shadow has no depth. These are constraints the physical world obeys for free, and they don't move when your lighting does. The physical properties of a correctly manufactured part don't change when a fixture wears or a light gets nudged. That makes physics the one stable anchor in a system where everything data-driven is drifting.
Raising a confidence threshold asks the model to bluff harder. A physics constraint just refuses to believe the impossible.
So the question we now ask isn't "does this look like a good part compared to the training images?" It's "is this image consistent with the known geometry and material behavior of the real object?" Those are profoundly different questions, and only the second one survives a process-node transition or a Tuesday-afternoon maintenance window.
There's a mature toolkit for this, and the honest truth is most of it lives in research papers rather than shipping products. Physics can be baked into a vision system three ways: into the network architecture itself, into the loss function as a physics-based penalty during training, or into synthetic data generation through physics-accurate rendering. The catch — the one that keeps this out of production — is that physics usually stops at training time. The deployed model is still a purely data-driven black box at the moment of inference, when it actually matters.
The work we lean on closes that gap at inference. Modern tracking pairs a classical Kalman filter — a decades-old method for estimating where a moving object will be next, given the laws of motion — with deep learning, instead of choosing one or the other. Approaches like KalmanNet aid the filter with a neural network for dynamics that aren't fully known. A 2026 system called Phys-3D enforces physically plausible 3D motion through pinhole-camera geometry and reports a 2.97% counting error even through dense occlusion and camera shake. PhyOT goes further and treats the neural network itself as a sensor feeding a Kalman setup governed by Newton's laws. The common thread: the network proposes, and physics disposes. The physics-constrained vision systems we build put exactly this kind of constraint layer into the inference path — Kalman filtering, optical-flow gates, and physics-informed architecture — so the rejection of the impossible happens live, not in a training notebook.
Why Don't the Big Vendors Just Do This?
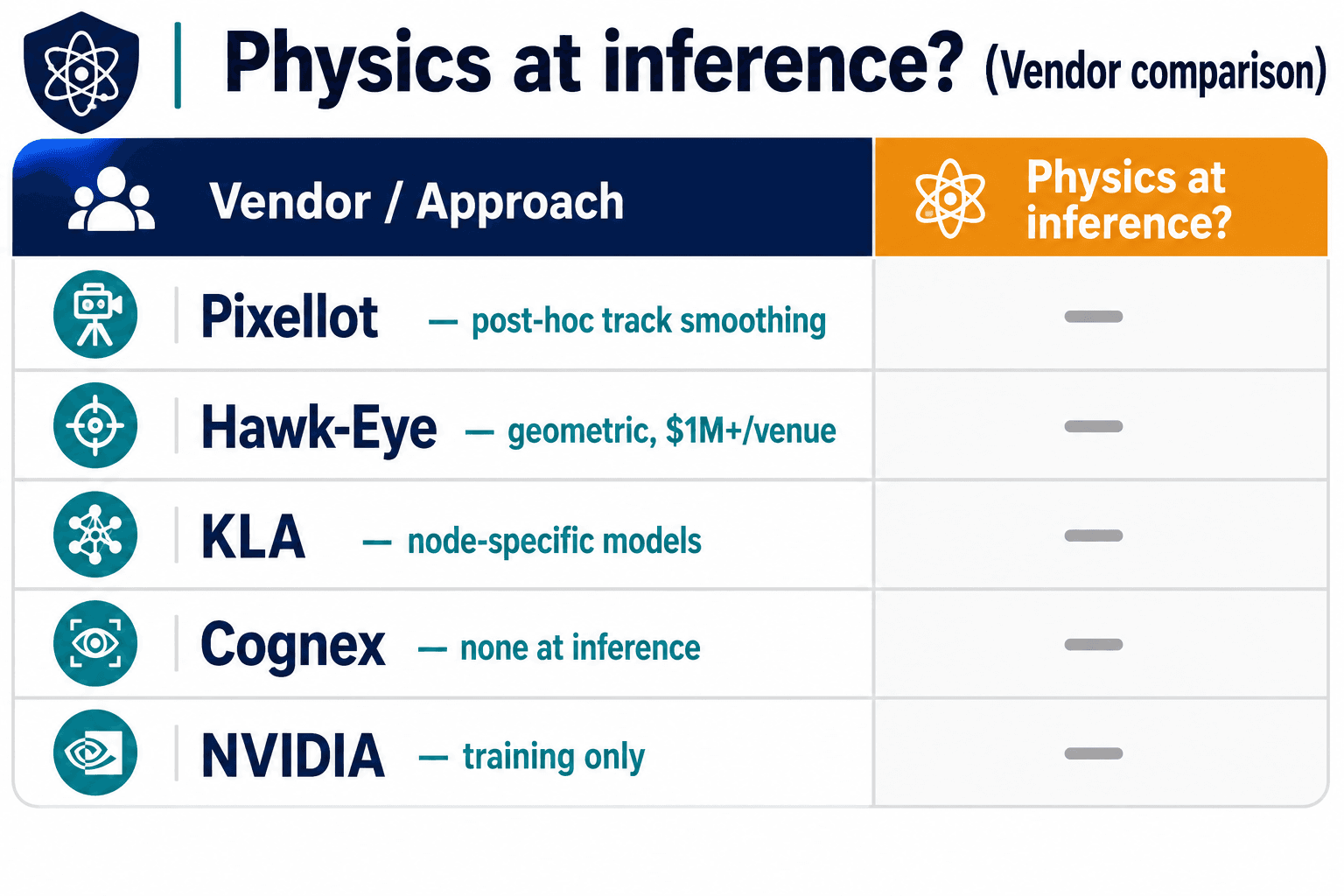
People ask me this constantly, usually with a note of suspicion — if physics constraints are so obviously right, why isn't Hawk-Eye or KLA shipping them as the default? The answer is that the leaders have some physics, but almost always in the wrong place, and the gaps are instructive.
Pixellot, after the bald-head era, added multi-hypothesis tracking that largely killed that specific class of error — but their physics is post-hoc track smoothing, not a constraint layer, so new failure modes (jersey OCR under motion blur, offside projection on a non-flat pitch) keep appearing. And this isn't anecdotal: on SoccerNet, the largest public sports-tracking benchmark, multi-object tracking is still measured as far from solved on fast motion and heavy occlusion, and no physics-aware tracker has been integrated into it yet. That empty space is the whole opportunity. Hawk-Eye, owned by Sony, has genuinely strong geometric constraints — it triangulates from six to eight calibrated 4K and 8K cameras, tracks 29 skeletal points per player, and is accurate enough that the NFL uses it for first-down measurements. But that rigor costs over a million dollars per venue and demands dedicated infrastructure. It's not a layer you add to your existing pipeline; it's a stadium retrofit.
On the industrial side the pattern repeats. KLA's defect-physics models are real but baked to specific process nodes, which is why node transitions spike the nuisance rate — and KLA's own $2.3 billion investment in next-generation inspection is a tell that they know the gap exists. Cognex's ViDi deep-learning tools are excellent and can train from as few as 5–10 images, cutting setup time by 90% — but there's no physics at inference, so they're as exposed to silent drift as anyone. And NVIDIA's Metropolis and Omniverse ecosystem simulates gorgeous physics — for generating synthetic training data. Physics stops at training; the deployed model is still data-driven.
Across the entire field, the "physics integration" column is either empty or pointed at training. The deployed model, the one making the call in real time, is still guessing from pixels.
That's the gap we build into. Not a platform, not a stadium retrofit — a physics-constraint layer that sits in your existing pipeline and rejects the impossible before it becomes expensive. Whether you're running automated cameras over a pitch, inspecting wafers at 10nm, or classifying defects on a line, the constraint holds when the lighting moves, because the lighting is exactly what physics doesn't depend on.
The Part Nobody Wants to Hear About "Zero False Positives"
Every buyer eventually asks me for zero false positives. I understand the instinct, and I tell them the same thing every time: it's technically achievable and it will probably hurt you.
Pushing a system toward zero false positives inevitably raises false negatives — the missed real defect, the threat that slips through. The goal is never zero of one kind of error; it's the right balance for the specific stakes of your application. What physics constraints give you is a better frontier to balance on. Conventional false-positive reduction — threshold tuning, calibration, autoencoders that research shows can cut false positives anywhere from 22% to 87% — all of it operates on the model's confidence. Physics operates on reality. It rejects the physically impossible detection without making the model more timid about the genuinely ambiguous one. You get fewer false alarms and you don't pay for it in missed defects, because you removed a category of error instead of trading it.
There's a regulatory tailwind here too, and it's not the one people expect. The EU AI Act's major provisions go live on August 2, 2026, and while most industrial inspection isn't classified as high-risk biometric surveillance, the Act's documentation and transparency requirements push broadly toward systems whose decisions you can explain. A data-driven black box that says "ball, 98%" can't tell you why. A system that rejected a detection because it violated parallax can. Falsifiability isn't just good engineering anymore; it's becoming a compliance posture.
What I Believe Now
I came into this convinced that computer vision was a data problem and that the team with the biggest, cleanest dataset would win. I shipped a model that proved me wrong on a factory floor, in front of people whose throughput depended on it.
What I believe now is narrower and more durable. A vision model that only knows what things look like is permanently one lighting change, one process node, one bald linesman away from confidently telling you something impossible. The systems that survive production are the ones that also know what the physical world allows — and check every detection against it before they act.
The market is about to learn this the hard way at scale. Computer vision is a $33 billion market in 2026 growing at nearly 20% a year, agentic vision systems are starting to trigger real-world actions on their own authority, and the more autonomous they get, the less tolerable a confident impossible answer becomes. You can keep collecting edge-case footage and chasing the next lighting change, the next node transition, forever. Or you can teach the model the one set of rules that never drift. If you want to see how we build that constraint into a production pipeline, that's where I'd start.
A ball can't teleport. Build the system that knows it.


