
Your Edge AI Sees Every Defect. It Also Rejects 12% of Good Parts.
I was standing next to a 200-ton stamping press, watching it kick good parts into the scrap bin.
The line was running at about 40 strokes a minute. Two GigE cameras we'd mounted over the die were catching burrs and short fills beautifully — in the lab, the model had hit 97% accuracy. On the floor, it was rejecting 14% of perfectly good parts. The plant manager stood next to me with his arms crossed and asked the only question that mattered: why did your AI just make my scrap rate worse?
That morning changed how I think about this entire category. Because the pitch for edge AI in manufacturing quality inspection is so clean it's almost irresistible: put a small GPU on the conveyor, run inference in twelve milliseconds, catch every defect in real time. NVIDIA will happily sell you the hardware. Landing AI will sell you the model. And then you stand on the floor and watch 14% of your good parts hit the reject bin, and you realize nobody sold you the part that actually matters.
The hardware works. The deployment doesn't. That gap is the whole business.
Here's the number that reframed the whole problem for me: 84% of system integration projects fail or partially fail. Not because the inference was too slow. Not because the model wasn't accurate enough. They fail in the seams — where the AI meets the press, the PLC, the lighting, the network, the night shift. We built Veriprajna's edge AI inspection practice around that uncomfortable truth: getting edge AI into production is an integration and operations problem wearing a hardware costume.
The month I spent fixing the wrong thing
When that stamping line first threw 14%, I did exactly what an engineer who trusts models does. I assumed the model was weak. So we retrained it. We added data, adjusted confidence thresholds, ran more epochs. The reject rate didn't move. I spent the better part of a month convinced that if I just made the network smarter, the floor would behave like the lab.
It wouldn't. And the reason it wouldn't is the single most important thing I've learned in this field.
The lab images were shot under a controlled LED ring light. On the press, the sheet metal reflects the overhead bay lights differently at every stroke angle. The stamping lubricant pools differently on a warm die than a cold one. The first fifty parts of a shift — before the tooling reaches thermal equilibrium — genuinely look different from the parts an hour later. My model wasn't wrong. My model had never seen the world the press actually lives in.
The fix had nothing to do with the network. It was polarized backlighting to kill the specular reflection off oiled metal, a thermal camera to correlate surface appearance with die temperature, and a training set rebuilt to include cold-start, mid-run, and end-of-run conditions. The model I'd spent a month "fixing" was fine the whole time. I'd been staring at the wrong layer of the stack.
The first fifty parts of a shift don't look like the part you trained on. If your data didn't see the cold die, your line will reject the cold die.
That's an expensive lesson to learn on a customer's floor. It's the lesson that turned us from people who build models into people who build deployments.
Why "just put a Jetson on it" is where projects quietly die
A while later I was pitching a manufacturer and the operations lead waved his hand and said, more or less, just bolt a Jetson on the conveyor and run inference — how hard can it be?
I understand the instinct. The hardware genuinely is a purchase order. But let me walk you through what that stamping line actually required after the lighting was fixed, because this is where the real work lives.
The inspection result has to reach the Allen-Bradley ControlLogix over EtherNet/IP so the reject actuator physically fires inside the 750-millisecond stroke window. Miss that window and you've correctly identified a defect that you then ship anyway. Every part has to be tagged with its inspection result in the MES for traceability. Defect images have to route to the quality engineer's dashboard, filtered by defect class and by die station, or the engineer drowns. None of that is a model problem. All of it is the difference between a demo and a line that runs unattended on third shift.
This is also the wall the cloud-pilot refugees hit — the buyers who already spent a budget cycle on an inspection pilot that couldn't keep up with the line. A round trip to a cloud GPU can be brilliant for training, but a 750ms actuator window leaves no room for a network hop to a data center and back. Their pilot didn't fail because the model was bad; it failed because the decision had to happen somewhere the cloud could never reach in time. The right architecture is hybrid by physics, not preference: train in the cloud or on-prem where you have the GPUs, infer at the edge where the data lives and the actuator waits.
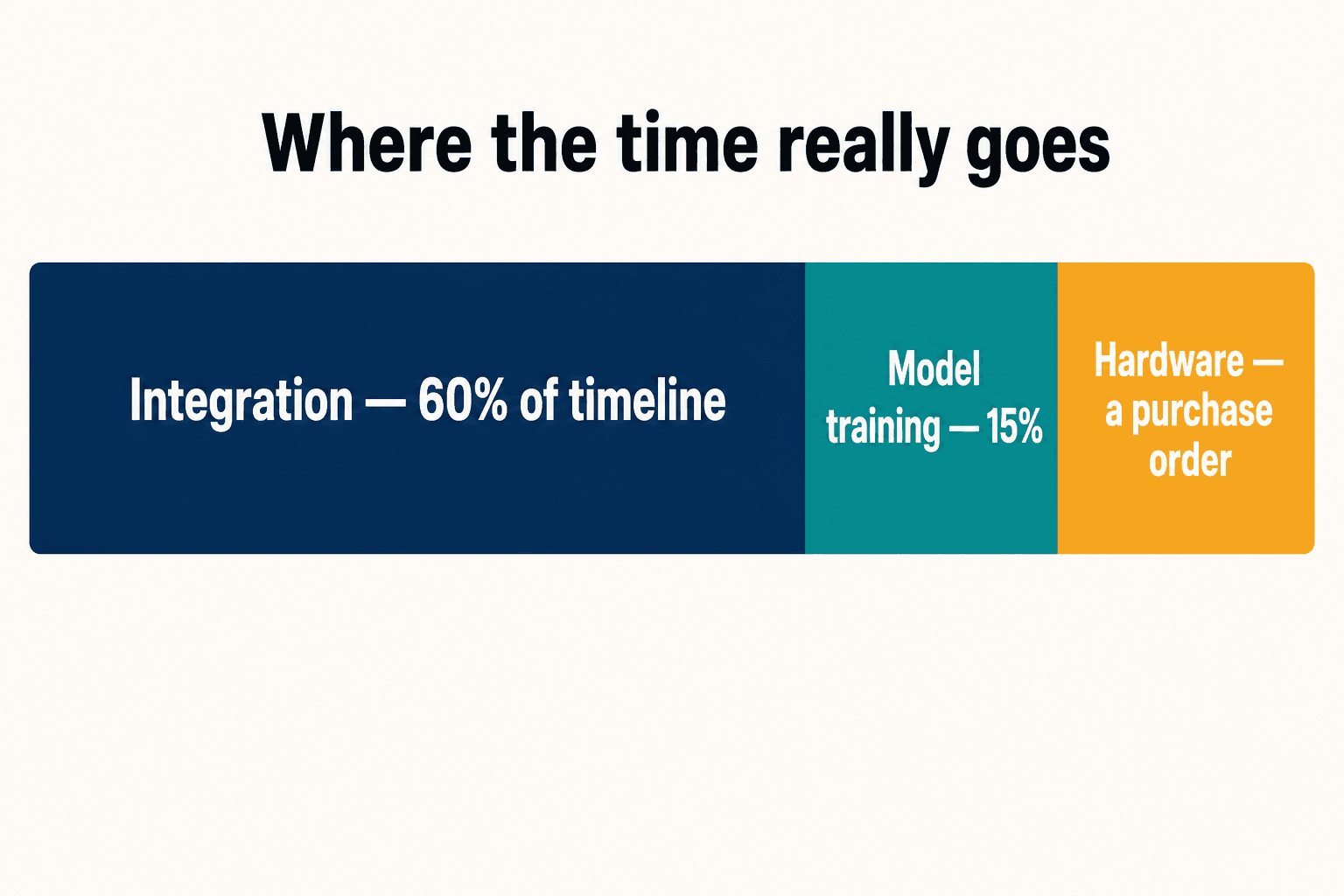
When we add up where a real project's time goes, the integration work — the OT/IT plumbing, the PLC handshakes, the data pipeline — is about 60% of the timeline. Model training is roughly 15%. The hardware, the thing everyone fixates on, is a line item on a PO. Roughly two-thirds of manufacturers hit production holdups during integration simply because their systems can't talk to each other, and legacy complexity is the reason cited most often. That's the 84% failure rate in slow motion.
This is also where the vendor landscape quietly breaks down for a mid-size manufacturer. Siemens Industrial Edge is genuinely excellent — deep S7-1500 integration, IEC 62443 security certification, real fleet management — if you run Siemens end to end. But if you run Allen-Bradley on half your lines, and most plants I walk into do, Industrial Edge doesn't bridge that gap. Rockwell's FactoryTalk VisionAI closes the loop beautifully with ControlLogix and lets your own quality staff train models with no code — inside the Rockwell ecosystem only. NVIDIA Metropolis powers inspection in 50-plus factories at remarkable accuracy, but it sells you SDKs and hardware, not a deployed solution in your specific OT environment, and it ties you to NVIDIA silicon. Each of these solves a real slice. None of them solves the integration-to-operations pipeline for the plant that runs Siemens and Allen-Bradley side by side — which is nearly every plant.
Why doesn't the model just get smarter over time?
This is the question I get from technically literate buyers, and it deserves a real answer instead of a brush-off.
The honest constraint isn't the model — it's the data underneath it. Only 34% of manufacturers have production systems with real-time data streaming. The other two-thirds are still piloting. If your historian logs a reading every five seconds but your inspection decision has to happen in fifty milliseconds, no amount of edge compute closes that gap — it's an architectural mismatch, not a tuning problem. And the training data is worse than people admit: only about 5% of manufacturers keep comprehensive records of equipment failures, which is exactly the data a predictive model would need to learn from. Inconsistent tag names and missing timestamps in the OPC-UA layer quietly poison a model long before anyone blames the algorithm.
So before we train anything, we often have to build the thing nobody budgeted for: a plant-level data layer that can actually feed an edge model in real time. It's unglamorous. It's also why the projects that get this right see roughly 4x faster AI deployment and 3x higher value capture than the ones that skip it.
The failure that taught us operations is half the job
Here's the part of edge AI nobody puts in the sales deck.
A logistics edge deployment I watched from the outside collapsed six months after a successful launch. The devices worked. The models worked. Then a power issue knocked 30% of 500 devices offline, and because nobody had built a process for field troubleshooting, each one took 48 hours to bring back. The project didn't die from bad AI. It died from the absence of an operations plan.
I think about that one constantly, because it's the failure mode that's invisible at pilot scale and fatal at production scale. Updating a model in the cloud is a CI/CD pipeline. Updating a model across 200 edge devices in 15 plants across 4 countries touches OT change management, network security, and production scheduling all at once — and most organizations have no established process for it. A rollback button that's never been tested under production load is not a rollback button. It's a prayer.
A pilot proves the AI can work once. Operations is what makes it work on the third shift in plant number twelve, six months later, with nobody from the vendor on the phone.
So now, before we deploy anything at scale, we build the operational frame first: over-the-air model updates with a rollback path we've actually exercised, device health monitoring, and maintenance procedures written so an OT technician can run them without the vendor on speed dial. The unglamorous infrastructure is what separates a deployment that survives from one that quietly goes dark.
Getting false rejects from 14% to below 2%

Let me come back to the reject bin, because this is the number a quality director actually loses sleep over.
Out-of-the-box automated optical inspection typically runs a 5–15% false-reject rate. That's not a rounding error — at scale it's a tax on good product, and worse, it teaches your operators to distrust the system. A well-tuned AI vision system gets below 2% while still catching 99%-plus of true defects. The journey between those two numbers is the whole craft, and almost none of it is "a better model."
It's structured, polarized lighting so the metal stops fighting you. It's disciplined hardware maintenance — most false-reject creep traces back to a drifting light source or a smudged lens, not the algorithm. It's pixel-level segmentation that lets you write a rule a quality engineer actually trusts: is there a scratch longer than two millimeters within five millimeters of the sealing surface? That single capability lets you stop rejecting cosmetic blemishes without going soft on the defects that ship warranty claims.
And it's calibration discipline at the silicon level. To run fast on an edge device you quantize the model to INT8 — a compression that, done carelessly, tanks your accuracy. Done with a proper calibration set of around a thousand representative parts spanning every defect type and every normal variation, the accuracy loss is about 0.2%, while you get roughly 4x memory reduction and, in one benchmark, a 32x speedup. But that 0.2% assumes you calibrate properly. The naive post-training quantization that most toolchains do by default can quietly cost you several points of accuracy; quantization-aware training — folding the compression into training itself — claws most of it back. Plenty of teams never learn the difference until the line starts over-rejecting and they go hunting for a model bug that was actually a quantization choice. The other trap is that the calibration set has to cover cold-start and end-of-run conditions too — the same lesson the stamping line beat into me, showing up one layer down.
There's a vendor-strategy decision buried in here that costs people real money. If you compile only to NVIDIA's TensorRT, your model is married to NVIDIA hardware forever. We export to ONNX first and keep a dual path — ONNX Runtime for mixed and ARM-based deployments, TensorRT where the workload is genuinely NVIDIA-heavy. It's a small architectural choice that quietly preserves your ability to negotiate with your hardware vendor three years from now.
When the defect is a sound, not an image
Quality inspection is the front door, but the same edge problem shows up in predictive maintenance — and it's where I see the most expensive false-confidence.
Acoustic and vibration AI for machine health is real and proven; Augury built a billion-dollar company on it with customers like PepsiCo and Nestlé. But the metric that gets quoted in demos — detection rate — hides the metric that kills adoption. A 5% false-positive rate across 2,000 monitored assets is 100 unnecessary work orders every inspection cycle. Your technicians chase a hundred phantom faults, find nothing, and within a month they stop responding to alerts with any urgency at all. Alarm fatigue isn't a people problem; it's a tuning failure that creates a people problem.
The benchmark I hold us to is Ford's: their models predicted 22% of component failures about ten days in advance at a 2.5% false-positive rate, saving 122,000 hours of downtime and roughly $7 million on a single component type. The gap between 5% and 2.5% false positives is the entire difference between a system your maintenance team trusts and one they learn to ignore.
This matters because the cost of getting it wrong is brutal and specific: unplanned downtime in automotive runs around $22,000 per minute. A predictive system that cries wolf doesn't just waste technician hours — it erodes the trust that would have prevented the one failure that counts.
The compliance deadline most plants haven't started on
People ask me whether the regulation is real or just consultant noise. It's real, and the clock is specific.
Most obligations under the EU AI Act become fully applicable on August 2, 2026. For manufacturing AI that means full data-lineage tracking, human-in-the-loop checkpoints for decisions that affect safety, and risk-classification tags on each model. "Data-lineage tracking" sounds like paperwork until you realize it means every reject decision your edge box makes has to be reconstructable a year later — which changes how you log at the device, not just how you report upward. I now design the logging schema before the model. The penalty ceiling is €35 million or 7% of global annual turnover. What that changes, practically, is that your architecture decisions in 2026 are now shaped by whether they survive regulatory scrutiny — not just whether they're accurate. A model whose decisions you can't trace is no longer just a technical risk; it's a filing risk.
The security layer is moving in parallel. IEC 62443 defines how industrial control systems stay secure, and edge devices making autonomous reject decisions need certified, trusted hardware — vendors like Advantech and Innodisk are already shipping 62443-certified modules. It's worth remembering that even Siemens Industrial Edge had a CISA advisory in January 2026 requiring an authorization-bypass patch. The most capable platform in the category still needed patching. Security posture at the edge isn't a checkbox; it's a standing operational commitment.
Does any of this actually pay off?
It does, and the numbers are good enough that I understand why the category is the fastest-growing slice of edge AI — manufacturing is compounding at roughly 23% a year for a reason.
Knauf Insulation reported 511% ROI in the first year from edge-vision AI for scrap reduction. BMW cut defects 40% with CNN models on painted surfaces. A cookie manufacturer saved $94,000 a year by trimming 8.7% of scrap waste. Typical payback across these projects lands between 6 and 18 months. The economics aren't the hard part.
The hard part is that those outcomes are earned, not purchased. Knauf's 511% and Ford's $7 million are exceptional precisely because most buyers can't replicate them by signing a contract — they require the integration, the data layer, the operations frame, and the false-reject discipline that the vendor brochures quietly leave to you. That gap, between the technology you can buy and the outcome you actually want, is the entire reason we do this work the way we do — vendor-neutral, integration-first, built to run on your third shift without us in the room.
I still think about the plant manager with his arms crossed by that press. He didn't care about my model's accuracy. He cared that his line was throwing away good steel. The day his false-reject rate dropped below 2% and stayed there through a shift change, he didn't say anything about AI. He just stopped watching the reject bin. That's the only benchmark that has ever mattered: not how smart the model is in the lab, but whether the people on the floor forget it's there.


