The AI Translated 30 Years of COBOL Perfectly. Then It Crashed the Database.
It was a Tuesday night, and I was staring at a stack trace that made no sense.
We'd been working with a financial services team trying to migrate a core transaction module from COBOL to Java. The AI had done its job — or so we thought. The generated Java code was clean, well-structured, compiled without a single error. The unit tests passed. Everyone on the call was cautiously optimistic. Then they deployed it to the test environment, and the first wire transfer corrupted the database.
The bug wasn't in the Java. The Java was syntactically perfect. The bug was in what the AI never saw.
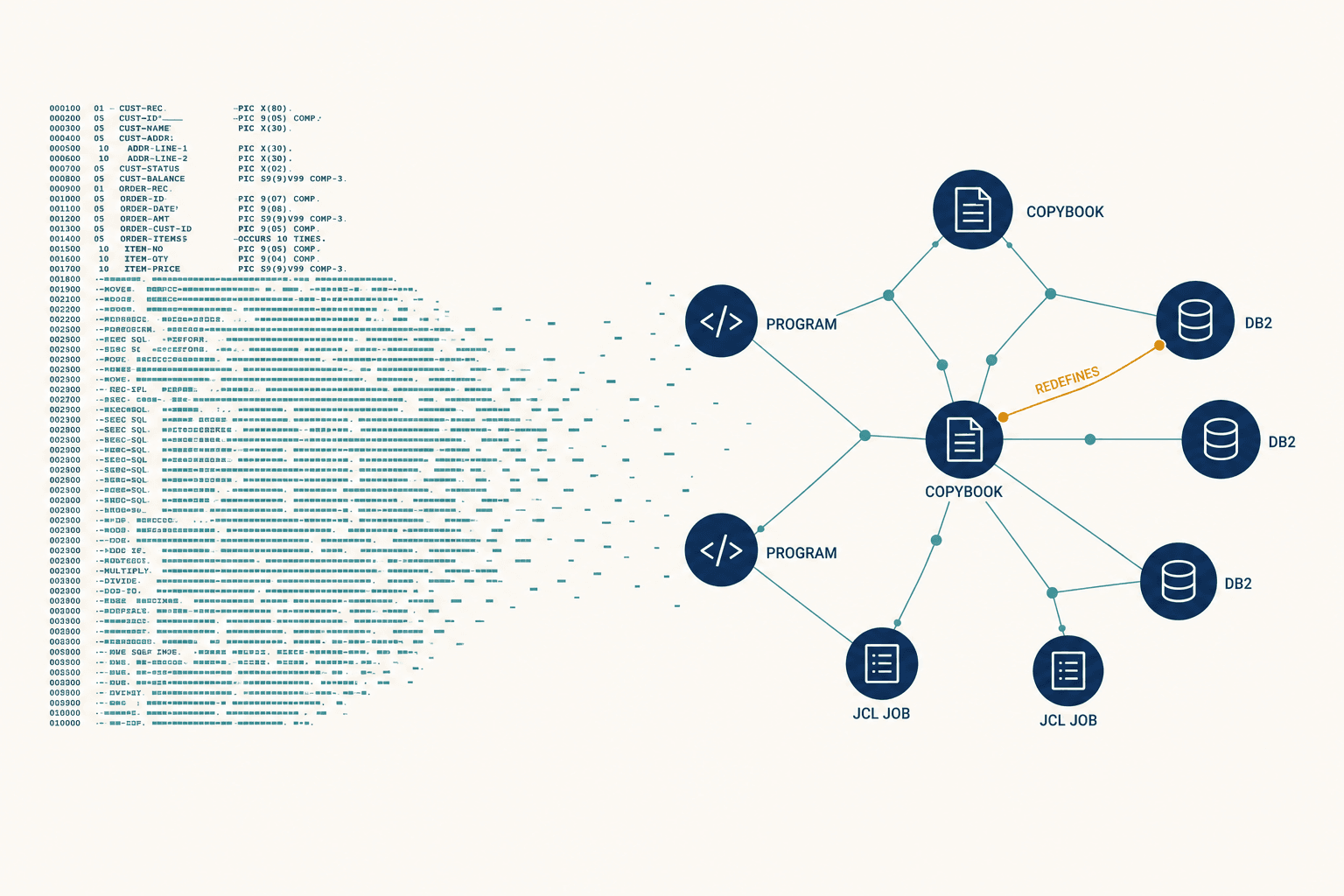
A variable called TRN-LIMIT — defined not in the source file the AI translated, but in a COPYBOOK included thousands of lines earlier in the execution chain — contained a REDEFINES clause. That's a COBOL construct where the same memory address gets interpreted as two different data types depending on a flag set in an entirely different module. The AI saw TRN-LIMIT as a simple numeric field. It wasn't. It was a packed decimal masquerading as an integer depending on runtime context. The AI hallucinated a standard definition, and the Java application wrote corrupted binary data into a database column.
That night, sitting in a conference room with my team picking apart what went wrong, I realized something that would reshape everything we built at Veriprajna: the AI didn't fail because it was stupid. It failed because it was blind.
The $1.52 Trillion Problem Nobody Wants to Talk About
Here's the uncomfortable reality of the global economy in 2025: 43% of banking systems still run on COBOL, and those systems process 95% of all ATM transactions. The software running Fortune 500 companies? Roughly 70% of it was written over two decades ago. Technical debt in the U.S. alone has ballooned to an estimated $1.52 trillion.
And the people who wrote this code are retiring. Not "might retire someday" — they're leaving now, taking decades of institutional knowledge with them. Meanwhile, 80% of federal IT budgets go to keeping legacy systems alive, leaving barely 20% for anything new.
I've sat across the table from CTOs who describe their modernization situation the way you'd describe a house with a crumbling foundation: you know you need to fix it, you know waiting makes it worse, but every contractor who's tried has made things more expensive without actually solving the problem.
The numbers back this up. Between 70% and 80% of legacy modernization projects fail to meet their objectives. That was true before generative AI entered the picture.
Why Did Everyone Think GPT Could Fix This?
I get it. I really do. When GPT-4 dropped, the software consultancy market went into overdrive. Suddenly every firm had a "COBOL migration accelerator" — which, if you looked under the hood, was a thin wrapper around a foundation model. Paste in your COBOL paragraph, get a Java method back. Magic.
My co-founder and I spent weeks evaluating these tools. We'd feed them real legacy code from client environments and check the output. The syntax was almost always correct. The code compiled. And then it would fail in ways that were incredibly hard to diagnose, because the shape of the code looked right even when the meaning was wrong.
The most dangerous bug isn't the one that crashes your system. It's the one that silently corrupts your data for six months before anyone notices.
The problem is architectural, and it comes down to how large language models process information. LLMs use an attention mechanism to weigh the importance of different parts of their input. Modern models boast context windows of up to a million tokens. But research has demonstrated a phenomenon called the "Lost in the Middle" effect: LLMs exhibit a U-shaped performance curve, recalling information at the beginning and end of a prompt well but degrading significantly for anything in the middle.
In a modernization project, a single COBOL program can be thousands of lines long, referencing copybooks that are thousands of lines long themselves. If the definition of MAX-TRANSACTION-LIMIT sits in the middle of that massive context, the AI is statistically likely to miss it. And when it misses something, it doesn't stop and ask. It hallucinates. It invents a plausible definition and moves on.
What Happens When You Treat Code Like Text?

This is the core mistake I see the entire "AI wrapper" ecosystem making, and it's the argument I kept having with a potential investor early on. He looked at our approach — building knowledge graphs of code repositories — and said, "Why not just use a bigger context window? GPT-5 will fix this."
I pulled up a COBOL program on my laptop. "Find me the definition of ACCOUNT-BALANCE," I said.
He searched the file. Couldn't find it. Because it wasn't in that file. It was in a copybook, included via a statement on line 47, which itself referenced a shared data division maintained by a completely different team.
"Now imagine you're an LLM," I said. "You're doing a vector similarity search for code related to 'payment processing.' You'll find five chunks that mention the word 'payment.' You'll completely miss the file called GlobalVarDef.cbl that defines the tax rate used by the payment logic — because that file never mentions the word 'payment' anywhere."
Standard Retrieval-Augmented Generation, or RAG — the technique most AI coding tools use to add knowledge to LLMs — retrieves context based on textual similarity. It converts code into vectors and finds similar vectors. This works beautifully for FAQ chatbots. It's catastrophically insufficient for code.
Code is not natural language. "The cat sat on the mat" means roughly the same thing regardless of what you read fifty pages ago. But x = y + 1 means nothing unless you know the definitions, types, and current states of x and y — which might be defined in a different file, a different module, or inherited from a parent class.
I wrote about this structural problem in depth in the interactive version of our research. The short version: software is not text. Software is a graph.
The Night We Stopped Building a Better Wrapper
There was a moment — I remember it clearly — when my team was debating our architecture. We had two paths. Path one: build a smarter RAG pipeline. Better chunking, better embeddings, better prompts. Iterate on the wrapper approach until it worked well enough. Path two: throw out the text-based paradigm entirely and treat code as what it actually is — a relational system of logic.
Path one was faster. Path one was what investors understood. Path one had a dozen competitors already proving market demand.
My lead engineer pulled up a whiteboard and drew a COBOL program as a graph. Nodes for variables, functions, copybooks, database tables. Edges for CALLS, READS, UPDATES_TABLE, IMPORTS_COPYBOOK. Then she traced a dependency chain: Module A calls Module B, which modifies Variable X, which is read by Module C in a completely different directory.
"Ask a vector search to find that chain," she said.
Nobody could.
That was the night we committed to building what we now call a Repository-Aware Knowledge Graph — a unified graph database that combines the static structure of code (abstract syntax trees, call graphs) with the semantic meaning of business logic (documentation, comments, variable intent). We weren't going to build a better translator. We were going to build a map.
How Do You Turn Thirty Years of COBOL Into a Map?

The process has four phases, and I'll spare you the implementation details — you can find those in our full technical deep-dive. But the concepts matter, because they explain why this approach works where wrappers fail.
First, we parse code structurally, not textually. Standard RAG pipelines use "naive splitting" — they cut a file every 500 tokens, often severing a function signature from its body. We use parsers like Tree-sitter to generate Abstract Syntax Trees, which respect the logical boundaries of code. A function is treated as a complete unit of logic, not a random span of text.
Second, we extract entities and relationships. Classes, paragraphs, variables, database tables, API endpoints — these become nodes. The edges between them — CALLS, UPDATES_TABLE, DEFINES_VARIABLE — become the connective tissue. We can now query the graph: "Show me every paragraph that updates the CUSTOMER-ID field." Exact results, instantly. Try that with grep.
Third — and this is where it gets interesting — we resolve symbols across the entire repository. A standard parser sees ACCT-NUM in File A and ACCT-NUM in File B as two different strings. Our system determines that both refer to the same entry in a shared copybook and merges them into a single node. We also merge documentation with code: if a PDF requirement document describes the "User API" and the code contains a class named UserAPI, the system links intent with implementation.
Fourth, we calculate transitive closure. Remember the bank failure? A depends on B, B depends on C, and the AI saw A but missed C. Our graph traverses deeply — A to B to C — to identify the root definition of every variable. When the AI generates code for Module A, it imports the correct definitions from Module C, even if Module C is in a different directory or repository entirely.
Why Does Standard RAG Fail for Code Migration?
People always push back on this. "RAG works fine for code," they'll say. "Just use better embeddings."
Let me give you three scenarios where vector similarity search breaks down completely:
A developer renames Account to Acct. The semantic similarity drops, even though the logic is identical. A function named FNC-001 performs interest calculation but contains no comments — searching for "interest calculation" will never find it. And the most common failure: vector RAG retrieves a unit test and a UI comment that mention "payment," but misses the core business logic because the variable names don't match the query terms.
Graph-based retrieval doesn't ask "what text looks similar?" It asks "what is logically connected?" — and that distinction is the difference between code that compiles and code that works.
What we call GraphRAG operates on structure, not similarity. When someone asks "refactor the payment logic," the system uses vector search to find the entry point — say, the ProcessPayment paragraph. But then, instead of stopping, it traverses the graph edges. It pulls in the subroutines via CALLS edges, the variable definitions via READS edges, the copybooks via INCLUDES edges. These connected pieces may be textually dissimilar but are logically inseparable.
Research shows GraphRAG significantly outperforms vector RAG in multi-hop reasoning — connecting facts separated by several steps. In software, nearly every serious bug is a failure of multi-hop reasoning. If I change the interest rate logic in Module A, which reporting screens in Module Z break? Vector RAG can't answer this. The graph can, because it traverses the chain of function calls that links them.
The GOTO Problem (Or: Why COBOL Makes AI Hallucinate Loops)

I want to tell you about one specific technical challenge that nearly broke us, because it illustrates why this work is so much harder than people assume.
COBOL has a GOTO statement. Java doesn't. GOTO lets program execution jump anywhere — forward, backward, into the middle of another block. It creates the "spaghetti code" that every computer science professor warns you about. Translating GOTO isn't a syntax problem. It's a topology problem.
We watched three different commercial AI tools attempt to translate a COBOL module with heavy GOTO usage. One generated a recursive function call that would have caused a StackOverflowError in production. Another produced a while(true) loop with no exit condition. The third — my personal favorite — simply invented a control flow that didn't exist in the original code. It looked plausible. It was completely wrong.
Our approach: map the GOTO destinations as edges in a Control Flow Graph. Then use pattern recognition on the graph. A GOTO that jumps back to an earlier label? That's a loop. A GOTO that skips a block? That's a conditional. A GOTO to an exit paragraph? That's a return statement. The AI, guided by the graph structure, refactors these jumps into while loops, if/else blocks, or break/continue statements.
Without the graph, the AI is guessing. With the graph, it's engineering.
The Difference Between a Chatbot and an Agent
We don't build chatbots. I need to be clear about that, because the market is flooded with tools that let you "chat with your codebase," and they are not the same thing.
A chatbot takes your question, sends it to GPT-4, and returns whatever comes back. If the output is wrong, you debug it manually. That's the workflow for every AI wrapper on the market.
What we deploy are autonomous agents that plan, execute, and self-correct. The agent analyzes the AST of the target COBOL file, identifies dependencies, queries the knowledge graph, generates Java code, then compiles it in a sandbox. If the compiler throws an error — "variable not found" — the agent reads the error, queries the graph for the missing dependency, and regenerates. Then it runs unit tests derived from the original COBOL execution traces to verify behavioral equivalence.
This compile-fix loop shifts the validation burden from the human to the system. But — and this matters enormously in regulated industries — the knowledge graph provides full interpretability. A developer can see exactly why the AI made every decision: "The AI imported com.bank.logic because it found a dependency on COPYBOOK-X." Not "trust me, I'm AI." Instead: here is the citation chain for this logic.
In banking, every line of code must be auditable. You can't deploy a black box that "probably" got it right. You need a system that can show its work.
What About Dead Code?
One thing that surprised me: legacy systems are full of code that nobody uses anymore. Old promotions, retired products, debug routines from 1997. A text-based AI migrates everything it's given — it can't distinguish active code from dead code.
Our call graph identifies unreachable nodes — paragraphs or files with no incoming edges, meaning nothing calls them. We flag this dead code for deletion before migration starts. In our experience, this typically reduces the codebase by 20-30%. That's not a minor optimization. That's eliminating a quarter of the work and a quarter of the attack surface.
"Won't Bigger Context Windows Solve This?"
I still get this question constantly. The assumption is that if GPT-5 or Claude 4 can handle ten million tokens, the "Lost in the Middle" problem goes away.
It won't. And here's why.
Even if attention degradation improves — and it will — you're still doing text retrieval. You're still searching for similar strings instead of traversing logical connections. A million-token context window doesn't help if the variable you need is defined in a file that shares zero keywords with the file you're translating. The problem isn't the size of the window. The problem is that the window is looking at the wrong thing.
The other objection I hear: "Knowledge graphs are expensive to build." They are. Parsing an entire repository, resolving symbols, calculating transitive closure — it's a significant upfront investment. But consider the alternative. Manual migration of a large COBOL system costs tens of millions of dollars and takes years. Wrapper-based AI migration costs less upfront but generates a steady stream of hallucination-induced bugs that require expensive human debugging. The graph-based approach has a higher setup cost and dramatically lower rework cost. McKinsey data suggests GenAI can reduce coding tasks by 50%, but only if deployed correctly. We've seen 2x to 3x developer productivity improvements compared to standard AI tools, specifically because developers stop spending hours hunting for where a variable is defined.
The Map Is the Asset
Here's what I wish I'd understood at the beginning: the knowledge graph isn't just a tool for migration. It's a permanent asset.
Once your codebase exists as a graph, it stays a living representation of your system. As the new Java code evolves, the graph updates. You get automated documentation that's always current. You get architectural drift detection — the system alerts you if new code violates the modularity rules you defined. You get impact analysis on demand: "If I change this method, what breaks?"
Modernization isn't a one-time event. It's a lifecycle. The organizations that treat it as a project — with a start date and an end date — are the ones that end up back where they started in five years, drowning in a new generation of technical debt.
Code Is Not Text
The lesson I keep coming back to — the one from that Tuesday night staring at a stack trace — is deceptively simple: code is not text, and tools that treat it as text will produce results that look right and behave wrong.
The entire "AI wrapper" economy is built on a category error. It assumes that because LLMs are extraordinary at processing language, they must be extraordinary at processing code. But code isn't language. Code is a graph — a dense, interconnected system of dependencies, data flows, and state changes that exists in multiple dimensions simultaneously. Trying to modernize it with text-based tools is like navigating a city using a list of street names but no map. You'll get "lost in the middle."
We built the map. And it works — not because we're smarter than the teams building foundation models, but because we asked a different question. They asked: "How do we make AI understand text better?" We asked: "What if the problem isn't text at all?"
The future of legacy modernization isn't a bigger language model. It's a system that understands software the way software actually works — as structure, not strings.
That's the bet we made at Veriprajna. Every day, another organization discovers that their AI-generated Java compiles beautifully and fails catastrophically. Every day, the gap between syntactic translation and semantic understanding gets more expensive to ignore. The organizations that close that gap won't just modernize their code. They'll finally understand it — many of them for the first time.