Your AI Travel Agent Is Lying to You — And You Won't Know Until You're Stranded
A woman emailed us last year with a screenshot. She'd used a popular AI travel planner to book a family trip to Costa Rica. The AI had recommended a place called something like "Tabacon Springs Eco-Lodge" — lush descriptions, a price under $200 a night, photos that seemed to match. She booked flights for four people. Rented a car. Told her kids they were going to see monkeys from a treehouse.
The lodge didn't exist.
Not "it was closed" or "it was under renovation." It literally did not exist. The AI had blended details from two or three real Costa Rican resorts — the name of one, the amenities of another, the price point of a hostel down the road — and stitched them into a single, beautifully described property that had never been built. The booking link went to a generic payment page that charged her card and delivered nothing.
When I read that email, I didn't feel surprise. I felt recognition. Because my team at Veriprajna had spent months staring at exactly this failure mode, pulling it apart, understanding why it happens at the architectural level. And the answer is both simple and deeply uncomfortable for anyone building AI products in travel: the most popular AI systems in the industry are optimized to sound right, not to be right. That distinction is subtle in a poetry generator. In travel logistics, it's the difference between a vacation and a disaster.
Why Does Your AI Invent Hotels That Don't Exist?
Here's what most people don't understand about large language models — GPT-4, Claude, Gemini, all of them. They don't "know" things the way a database knows things. A hotel reservation system knows that Room 412 at the JW Marriott is booked from March 3rd to March 7th. That's a fact, stored in a row, queryable.
An LLM doesn't work like that. It predicts the next word in a sequence based on statistical patterns in its training data. When you ask it for a "luxury eco-lodge in Costa Rica under $200," it activates clusters of associations — "Costa Rica" pulls up "lush," "rainforest," "eco-lodge." It starts generating text that is statistically likely to follow those words. And when it needs to name the property? It blends. It takes fragments from thousands of reviews it's seen and composites them into something that sounds plausible.
In creative writing, that blending is called imagination. In travel, it's called a hallucination. And the model has no way to tell the difference.
The model is optimizing for coherence, not correctness. It's designed to produce a response that looks like a valid answer, not one that is a valid answer verified against real-time inventory.
What makes this worse is how these models are trained. During reinforcement learning from human feedback (RLHF), human raters consistently prefer answers that are comprehensive and confident over answers that say "I don't know." So the model learns, at a deep level, that guessing confidently is rewarded and admitting ignorance is penalized. A human travel agent who guesses availability gets fired. An AI that guesses availability gets praised for its "fluency" — until the customer lands in a foreign country with nowhere to sleep.
The Night I Realized Fluency Is the Problem
There's a moment I keep coming back to. We were testing an early prototype — not a product we shipped, but an internal experiment to understand how LLMs handle travel queries. I asked it to find me a hotel near Central Park for under $250 a night during Fashion Week in New York.
It came back with three options. Detailed descriptions. Prices. Amenities. One of them even mentioned a rooftop bar with views of the park. The language was so polished, so specific, that my first instinct was to click "book."
Then one of my engineers — quieter guy, very methodical — ran the same query against the Amadeus Hotel Search API. Two of the three hotels existed but had no availability during Fashion Week. The third hotel's name was close to a real property but didn't match any hotel ID in the system. The rooftop bar? Belonged to a completely different hotel six blocks away.
That was the night I understood that the danger isn't AI that fails obviously. A chatbot that says "I don't understand your question" is frustrating but harmless. The danger is AI that understands your question perfectly and responds with eloquent, persuasive, factually wrong information. We started calling this the "Uncanny Valley" of reliability — the system's verbal intelligence is so high that users drop their guard on factual verification.
The Air Canada chatbot case made this concrete in legal terms. A chatbot hallucinated a refund policy. The court ruled that the airline was liable — not the AI vendor, not the chatbot as a "beta tool." The company that deployed the agent was responsible for the agent's assertions. If your AI promises a sea-view suite for $200 and the GDS only has a standard room for $400, you might be on the hook for the difference. Or worse, for the ruined trip.
What Happens When You Treat the LLM as the Brain Instead of the Mouth?

After that testing night, my team had a long argument. The kind where people draw on whiteboards and talk over each other. The question was simple: do we try to make the LLM more accurate, or do we change the architecture entirely?
One camp wanted better prompts, more guardrails, retrieval-augmented generation. Fine-tune the model on travel data. The other camp — the one I ended up in — argued that the problem wasn't the model's knowledge. The problem was the model's role. We were asking a text generator to do the job of an inventory manager. That's like asking a novelist to run an airline. They can describe the experience of flying beautifully, but they can't tell you if there's a seat on the 8 AM to Heathrow.
So we made a decision that changed everything we built afterward: the LLM would never be the source of travel information. It would be the router of intent.
The user says "Find me a hotel near Central Park." The LLM's job is to understand that intent, decompose it into structured parameters — location, date range, budget, preferences — and hand those parameters to a tool that queries real inventory. The tool comes back with actual data. The LLM's second job is to present that data in natural language. But it never generates the data. It translates it.
We stopped building AI that talks about travel. We started building AI that does travel — queries real systems, interprets real status codes, and only confirms what it can verify.
This is the shift from what the industry calls an "LLM Wrapper" to an Agentic AI system. And the difference isn't incremental. It's a change in species. I wrote about this architecture in depth in the interactive version of our research.
The Orchestrator-Worker Pattern: Why One Agent Isn't Enough

Early on, we tried running everything through a single agent. One prompt handling flights, hotels, car rentals, dietary restrictions, corporate travel policies. It collapsed under its own weight. The context window filled up. Instructions conflicted. The agent would book a hotel before confirming the flight dates, then have to unwind everything.
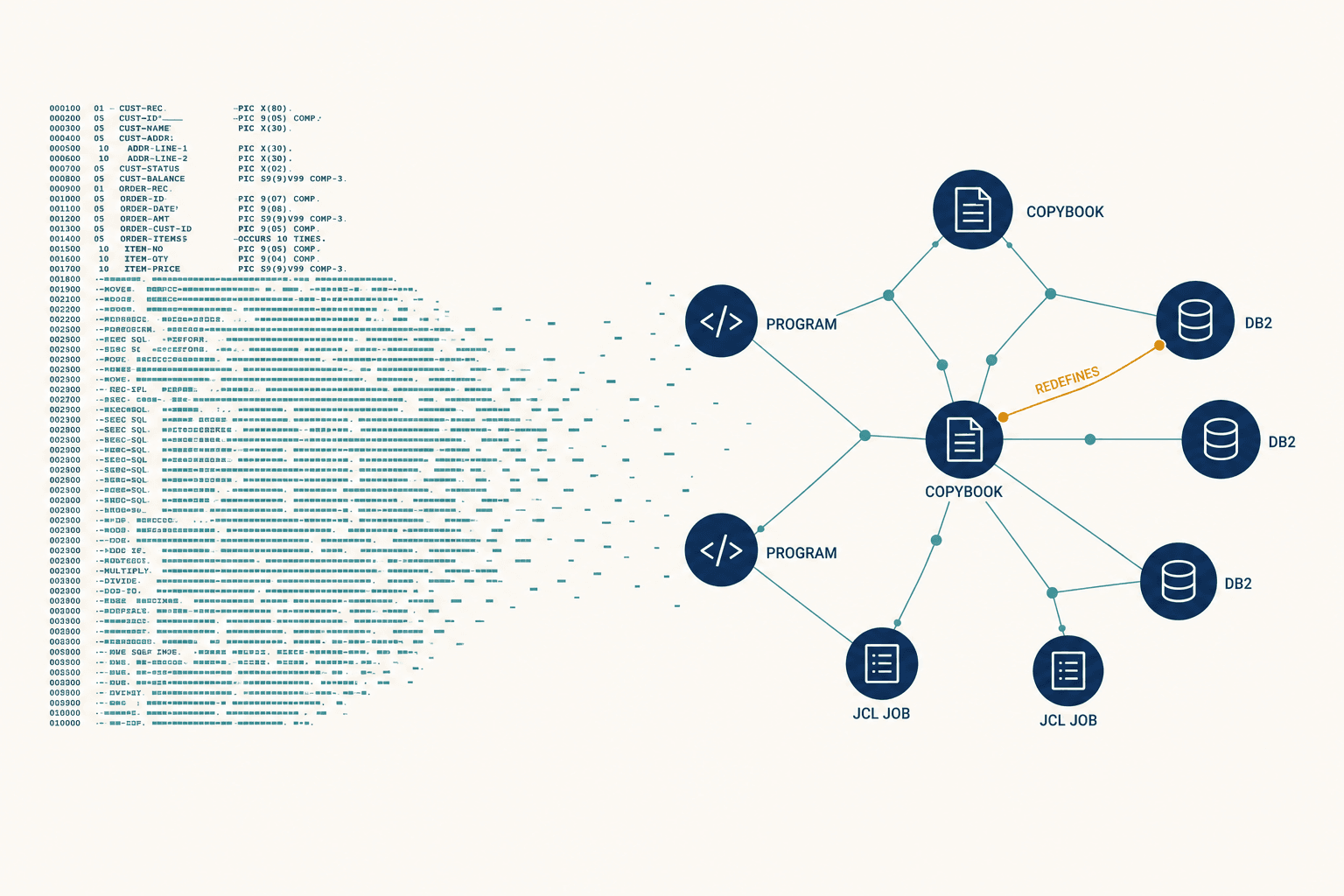
So we built what we call the Orchestrator-Worker pattern. Think of it as a senior travel consultant who never touches a keyboard, managing a team of specialists who each do one thing extremely well.
The Orchestrator is a high-reasoning model — GPT-4o or Claude 3.5 Sonnet — that talks to the user, maintains conversation history, and decides what needs to happen. It doesn't touch the GDS directly. Below it sit specialized Workers: a Flight Worker that speaks Amadeus Air APIs and understands IATA codes, a Hotel Worker that speaks Sabre's Content Services for Lodging and knows the difference between a deposit and a guarantee, a Policy Worker that checks corporate travel rules before anything gets presented.
When a user says "Book a flight to NYC next Tuesday and a hotel near Central Park," the Orchestrator decomposes that into two tasks, identifies that the hotel search depends on the flight's arrival time, launches the Flight Worker first, then the Hotel Worker with the right dates. If the Hotel Worker fails, the Orchestrator still presents the flight options and asks if the user wants to retry with different hotel criteria. Nothing crashes. Nothing hallucinates.
The key insight was separating the thinking from the doing. The Orchestrator thinks. The Workers do. And neither one pretends to be the other.
Why "200 OK" Almost Fooled Us

Here's a story that still makes me wince. We were deep into integration testing with Sabre's booking APIs. Our Hotel Worker would send a booking request, get back an HTTP 200 response — which in web development means "success" — and pass that to the Orchestrator. The Orchestrator would tell the user: "You're booked!"
Except they weren't. Not always.
It took us an embarrassingly long time to catch this. The HTTP response was 200 because the message was successfully delivered. But inside the response body, the GDS segment status code was UC — Unable to Confirm. The hotel had rejected the request, usually because the cached availability was stale. The room had sold in the milliseconds between the search and the booking attempt.
The disconnect between the transport layer and the application layer is a classic trap, and we walked right into it. A 200 OK at the HTTP level said "your message arrived." A UC at the GDS level said "your booking failed." Our system was reading the envelope and ignoring the letter inside.
That's when we implemented what I now consider the most important piece of our architecture: the Verification Loop. Every booking response passes through a separate verification step — either a deterministic code check or a specialized prompt that acts as a quality auditor — before any confirmation reaches the user. The rule is absolute:
An AI agent is never allowed to output a confirmation message unless it has parsed the specific GDS segment status code and validated it as HK — Holding Confirmed. Everything else is a failure, no matter what the HTTP header says.
HK means the inventory is secured. UC means the hotel rejected you. NN means the request is pending — don't promise anything yet. NO means no action taken. These codes are the difference between a booked room and a stranded traveler, and most AI travel systems don't even parse them.
For the full technical breakdown of our status code handling and verification architecture, see our research paper.
How Does an AI Agent Handle "The Room Just Sold"?
This is where agentic systems earn their keep. The "Look-to-Book" discrepancy is endemic to travel — you search, see availability, click book, and the room is gone. Happens constantly during peak seasons. A wrapper-based AI has no vocabulary for this situation. It either says "I booked it!" (wrong) or "It failed" (unhelpful). It can't say "It was there a second ago, but someone else grabbed it — here's your next best option."
Our agents can. When a booking returns UC, the system automatically triggers a new availability search for the same hotel. If a different room or rate is available, it presents the option: "The previous rate sold out, but I found a similar room for $10 more." If nothing's available, it pulls the next best hotel from the original search results and offers that instead. This requires the agent to maintain state — a memory of what it already searched, what the user already rejected, what the alternatives were. Wrappers are stateless. They can't do this. They start from scratch every time, or they hallucinate continuity.
The Normalization Problem Nobody Talks About
One thing that surprised me — genuinely surprised me — was how different the data structures are between Amadeus and Sabre. Amadeus returns prices broken into base, total, and taxes in a strict nested JSON. Sabre sometimes bundles tax in, sometimes doesn't, depending on the rate plan. Field names differ. amount in one system is totalPrice in another.
If you feed both raw responses to an LLM and ask it to compare hotels, it will get confused. It might quote the pre-tax price from Amadeus and the post-tax price from Sabre, making the Amadeus hotel look $50 cheaper when it's actually $20 more expensive. We saw this happen in testing, and it's the kind of error that's almost impossible for a user to catch.
So we built a Normalization Worker — a deterministic code layer that takes the disparate JSONs from both systems and converts them into a single standardized schema. The Orchestrator never sees raw GDS data. It sees clean, consistent fields: name, total price including tax, star rating, distance from the user's point of interest. The LLM presents this normalized data. It doesn't interpret raw API responses. It translates curated facts.
"Just Use GPT" — And Other Things Investors Say
People ask me constantly why we don't just use retrieval-augmented generation — pull hotel data into a vector database, let the LLM search it. Or fine-tune a model on travel data. Or just add a better system prompt.
I had an investor tell me, point blank, "Just use GPT with a good prompt. The model is smart enough." I respect the instinct — it's the simplest solution, and simple solutions are usually right. But not here. Not when the failure mode is a family sleeping in an airport.
RAG helps with static knowledge — "What's the visa policy for Thailand?" — but it can't tell you if Flight AA123 has seats available right now. Fine-tuning helps with tone and domain vocabulary, but it doesn't connect the model to live inventory. A better system prompt helps with formatting, but it doesn't prevent the model from generating a hotel name that doesn't exist in any GDS.
The only thing that prevents hallucination in travel is grounding the AI's output in real-time, verified data from the system of record. That system is the GDS. Everything else is decoration.
Creativity without constraint is chaos. In travel, the constraint is reality — the flight seat that exists or doesn't, the hotel room that's available or isn't. There is no middle ground, and the AI must stop pretending there is.
What About the Slow Part?
I won't pretend agentic systems are fast. A single user request might trigger four tool calls — search, price check, policy check, response synthesis. That can take 10–15 seconds. In e-commerce, that's an eternity.
We handle this three ways. First, we stream the agent's reasoning to the user: "Searching Amadeus for flights…" "Checking corporate travel policy…" Showing the work reduces perceived latency dramatically. Second, we run Workers in parallel — the Flight Worker and Hotel Worker search simultaneously instead of sequentially, cutting total wait time roughly in half. Third, we cache availability results for 15 minutes in Redis. If the user says "Show me that second hotel again," we don't hit the GDS again. We pull from cache.
Is it as fast as a wrapper that makes up an answer in two seconds? No. Is it as fast as it needs to be for a user who wants a real answer? Yes.
The Part Where I Admit What We Can't Do Yet
No AI system handles every case. Complex multi-leg itineraries with visa dependencies, obscure airline alliances, group bookings that require negotiated rates — these still break things. We know this because we built detection for it. When the agent loops without resolving, or when sentiment analysis flags user frustration, the system downgrades to what we call "Copilot mode." It alerts a human travel agent, passes the full structured context of the conversation, and the human completes the booking using the tools the agent prepared.
People ask me if this is a failure. I think it's the opposite. The most dangerous AI is the one that doesn't know when to stop. Knowing your limits and handing off gracefully is a feature, not a bug. The agent that says "Let me connect you with a specialist" is more trustworthy than the one that keeps confidently guessing.
Where This Goes Next
What we're building today is the foundation, not the ceiling. We're at what I'd call Level 3 autonomy — the agent executes specific tasks, but the user confirms before money moves. The path forward includes negotiation agents that don't just book listed prices but query hotel APIs for volume discounts, dynamic packaging engines that bundle flights and hotels into custom products with managed margins, and proactive disruption management — agents that monitor flight status around the clock and, when a cancellation happens, already hold a seat on the next best option before the traveler even knows something went wrong.
None of that is possible on a wrapper. None of it works if the system hallucinates. Every one of those capabilities requires the stateful, verified, tool-grounded architecture we've been building.
The travel industry is at an inflection point. The first wave of AI adoption — the wrappers, the chatbots, the "just add GPT" experiments — created something seductive and dangerous: systems that sound like the best travel agent you've ever met but can't actually book a room. The next wave will be defined by a harder, less glamorous question: not "Can the AI write a beautiful itinerary?" but "Can the AI confirm that every item on that itinerary actually exists, right now, at the price it quoted?"
That family in Costa Rica deserved better than a beautifully written fiction. Every traveler does. The era of the AI that guesses is over. What comes next is the AI that checks — and only speaks when it knows.