Our AI Booked a Hotel That Didn't Exist — and the Math Said It Would
The first time I watched our travel assistant confirm a hotel that did not exist, the demo room actually applauded.
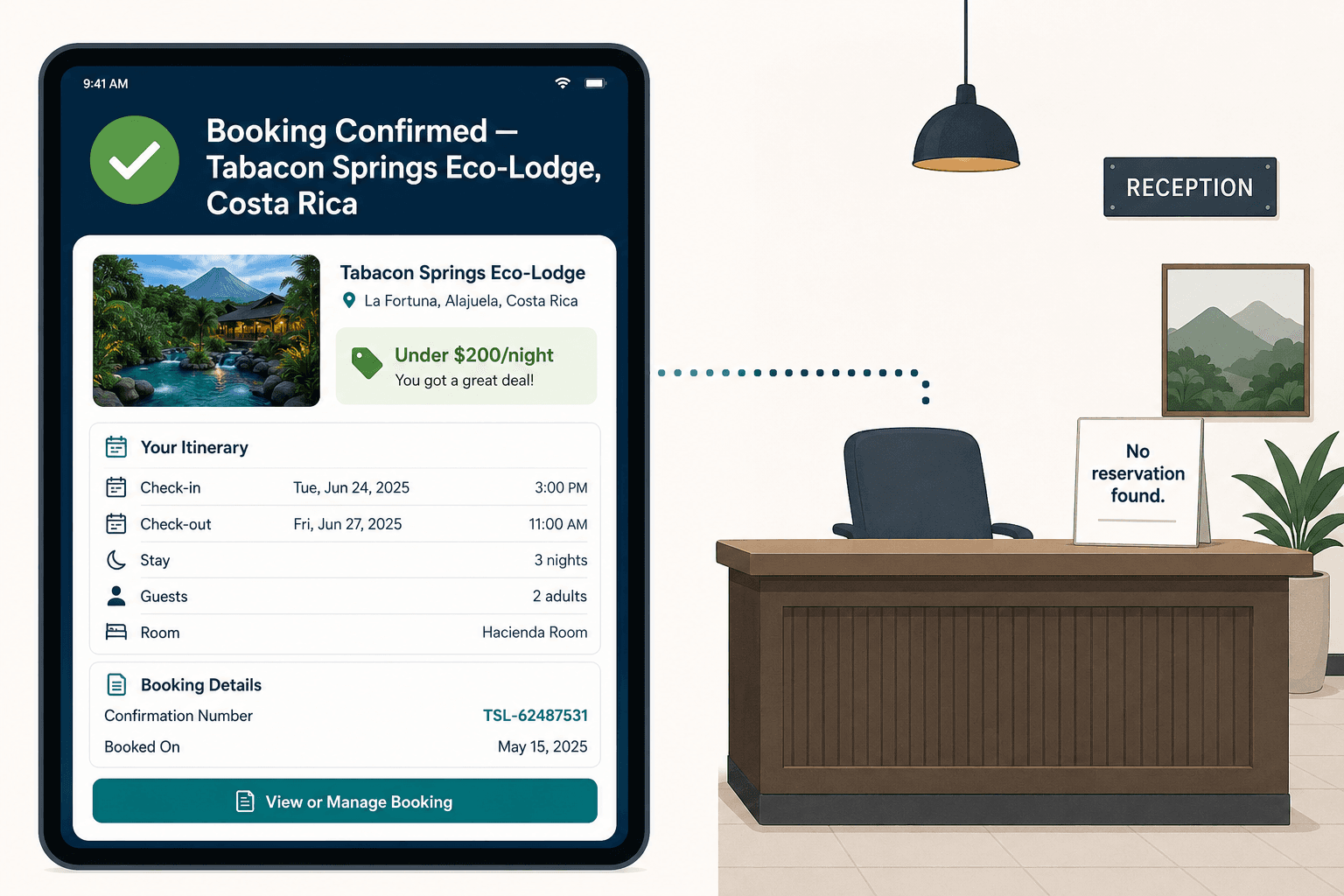
A tester had asked for a luxury eco-lodge in Costa Rica under $200 a night. The model returned the "Tabacon Springs Eco-Lodge" — gorgeous copy, a plausible nightly rate, a confirmation screen. It reads beautifully. It is also two real properties, Tabacon and Nayara Springs, melted into one fictional place. There is no Tabacon Springs Eco-Lodge. If a family had been on the other end of that screen, they would have flown to Costa Rica and arrived at a front desk that had never heard of them.
That moment is the whole reason agentic AI travel booking is harder than it looks, and it's why I want to walk through what we got wrong before we got it right. The short version: in travel, a fluent answer and a true answer are different objects, and the gap between them is not a bug you iterate away. It's a structural property of using a probabilistic model to do a deterministic job.
A human travel agent who guesses at availability gets fired. An AI that guesses is praised for its tone — until a customer is standing at an airport.
The board asked for "an AI strategy." The market gave them a reason to panic.
I'll set the scene, because if you run product at a travel management company or an OTA, you are living it right now.
Between February and April 2026, every major distribution layer in travel shipped or announced agentic booking. Sabre, PayPal, and Mindtrip announced the industry's first end-to-end agentic experience on February 12 — flights generally available in Q2 2026, running on Sabre's Mosaic APIs across 420-plus airlines and two million hotels, with Mindtrip's 6.5-million-point knowledge base on top. The day before, Marriott's CEO confirmed Google's AI Mode would book Marriott directly, skipping the OTA channel entirely. Amadeus put a generative assistant called Cytric Easy inside Microsoft Teams, built with Accenture. Navan keeps reporting numbers that make every legacy TMC look slow.
So the CFO walks into the room and asks why you aren't "doing an AI thing like Navan." And here is the trap I watched smart teams fall into: they hear that question as ship a chatbot fast, when the real question — the only one that matters — is how do we do this without getting burned like Air Canada.
The buyers I talk to are not asking whether to do agentic booking. That argument is over. They're asking how to do it without betting the company on a single platform's inventory, and without a confidently wrong machine creating a liability they personally have to answer for.
The liability already has a name, and your legal team knows it
If you want to understand why travel counsel is nervous, you only need one case.
On February 14, 2024, the British Columbia Civil Resolution Tribunal ordered Air Canada to pay Jake Moffatt $812.02 after its chatbot invented a retroactive bereavement-fare policy that contradicted the airline's actual fare rules. Air Canada's defense was that the chatbot was, in effect, a separate legal entity responsible for its own statements. The tribunal rejected that in plain language: a company is responsible for everything on its surfaces, whether the words come from a static webpage or a model.
Eight hundred and twelve dollars is a rounding error. The precedent is not. Every travel-tech legal memo written since cites Moffatt, and a more recent ruling cut the other way without helping deployers at all — in January 2026 a court in Hangzhou narrowed an LLM vendor's liability when a user tried to enforce a chatbot's promise. Read together, the two cases point in the same uncomfortable direction: the duty of care lands on the travel brand, not the model provider. You cannot outsource the blame to OpenAI.
And it isn't only money. In 2025, tourists trekked to 4,000 meters in the Peruvian Andes hunting for the "Sacred Canyon of Humantay," a place an AI planner had invented whole. A Malaysian couple drove 400 kilometers to ride a "Kuak Skyride" that does not exist. A Tasmanian village of 33 residents started fielding calls about thermal springs it never had. ISO 31030, the travel-risk-management standard, makes traveler safety the deployer's obligation — those incidents are precisely what it exists to prevent. With roughly a quarter of tourists now using AI to plan trips, the blast radius stopped being theoretical a while ago.
What I got wrong: I thought this was a prompt problem
Here's the part I'm not proud of.
Our first build was, honestly, a good-looking wrapper. A capable model, a well-engineered system prompt, retrieval over a hotel catalog, a clean chat surface. It demoed well — well enough that I caught myself believing the hallucinations were an edge case we'd squeeze out with better prompting and a bigger retrieval index. An investor around that time told me, more or less, to just use GPT and stop overthinking it. For about a month I half-believed him.
The Tabacon Springs moment is what broke that belief, but the thing that actually changed my mind was sitting down and doing the arithmetic I'd been avoiding.
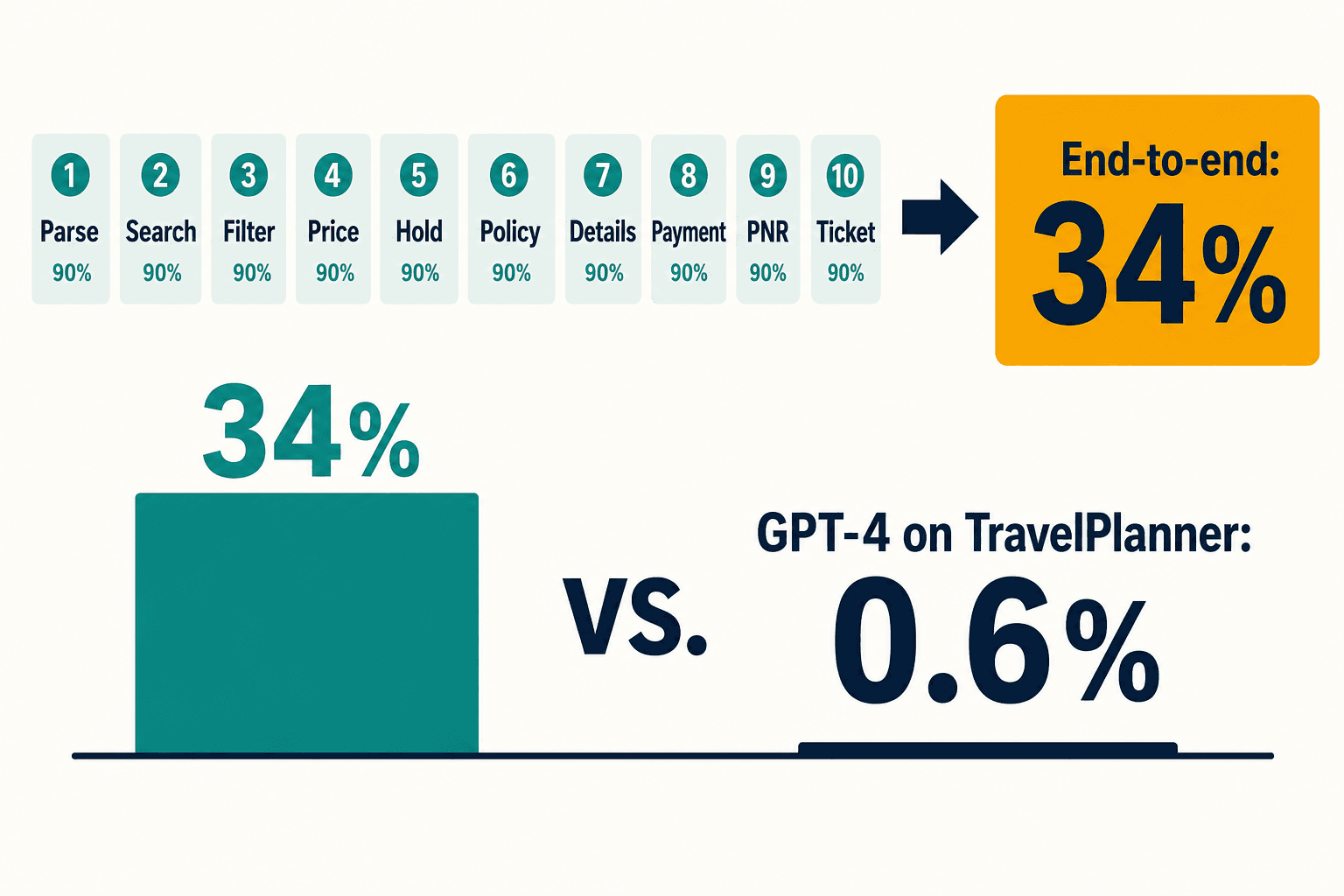
A realistic flight booking is about ten sequential steps: parse intent, search, filter, price, hold, check policy, collect passenger details, hand off payment, commit the PNR, ticket. Suppose — generously — each step is a probabilistic model call that's right 90% of the time. End to end, your success rate is 0.9 to the tenth power. About 34%.
You cannot prompt your way out of compounding stochastic failure. The error doesn't get smaller as you add steps. It multiplies.
Then I found the number that ended the internal debate. The OSU NLP Group's TravelPlanner benchmark measured GPT-4, using the popular ReAct pattern, completing realistic multi-day itineraries at 0.6%. Not 60%. Zero point six. Six successful trips out of a thousand.
People wave around a "97%" figure from the same benchmark, and I want to be precise here because borrowing it would make us look either dishonest or naive: that 97% comes from a code-driven solver running against a static, frozen knowledge base — OpenFlights and Yelp snapshots — not a model booking against live, changing inventory. It is not a production booking number, and anyone who quotes it as one hasn't read the paper. The honest number for an LLM driving the whole flow is the small one.
That was the turn. The problem was never the prompt. The problem was that we'd put a probabilistic model in the control flow at all.
How Do You Stop an AI From Booking a Hotel That Isn't There?
Once I stopped trying to make the model more reliable and started trying to remove it from the parts that have to be reliable, the architecture almost designed itself.
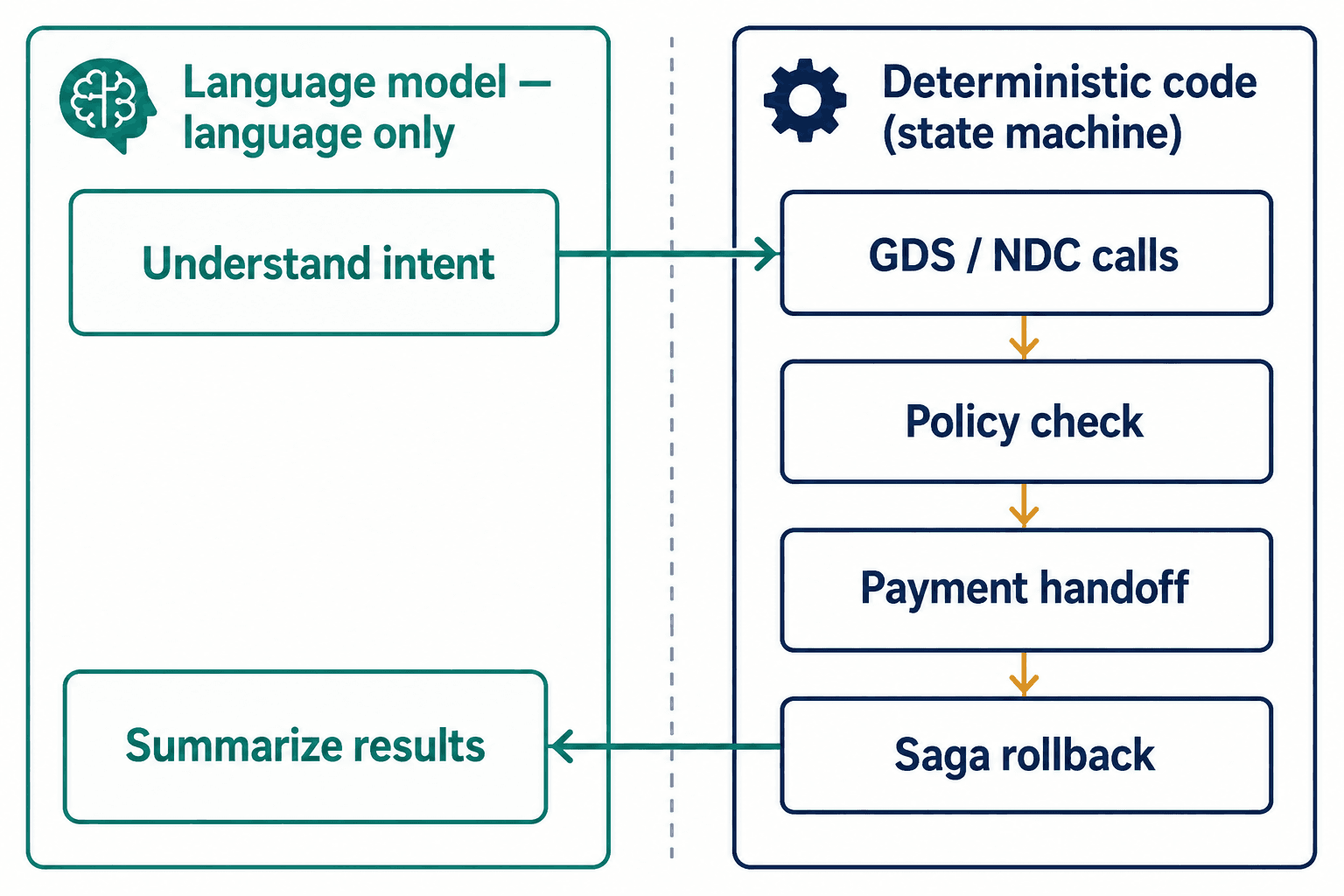
The rule we settled on: the language model does language, and nothing else. It extracts what a traveler means and summarizes results back in plain English. It does not call the GDS. It does not check policy. It does not touch payment. Every one of those is hard-coded, deterministic logic. We run the orchestration as a state machine — LangGraph is our usual control plane, though we're not religious about it; if a client is standing on AWS Bedrock AgentCore or Vertex AI Agent Builder, we build there instead.
The detail that matters more than the framework is the typed state. Most production agent deployments I've seen die the same quiet death: state drifts silently between steps, nobody notices, and the agent confidently acts on a corrupted picture of the world. A strict Pydantic-typed state schema — every field declared, validated at each transition — is the unglamorous thing that prevents it. When a booking has to span multiple commits, a saga pattern handles rollback: if the hotel fails after the flight is already ticketed, the graph knows how to void and unwind rather than leaving a traveler half-booked.
We built it as three capabilities, not one product, because not every buyer needs the whole thing. There's the deterministic booking agent — the core. There's verification-as-a-service, a standalone API that any existing travel-AI team can call to ask "is this hotel real, is this price current, is this PNR actually confirmed?" — a guardrail that sits in front of a wrapper you've already shipped, which is a far cheaper answer when legal flags Moffatt in your steering committee than ripping everything out. And there's a policy-and-compliance layer that compiles a corporate travel policy or an OTA's fare rules into enforced constraints, instruments ISO 31030 duty-of-care obligations, and carries the EU AI Act transparency requirements. We wrote up how the three fit together on the solution page for this work.
Policy enforcement has to be code, not a prompt. Prompts drift between model versions. Business rules are not allowed to.
The number nobody puts on the pitch slide
If I could make every travel team internalize one thing before they ship, it wouldn't be hallucination. It would be the economics of search.
GDS providers don't bill per booking. They bill per segment search, typically $3 to $3.50 plus roughly a 10% commission, and they enforce look-to-book ratios that penalize you for speculative shopping. Lufthansa Group hiked its GDS booking fees again, effective January 1, 2026, across Amadeus, Sabre, and Travelport. Now picture an agent that "helpfully" runs four exploratory searches per conversational turn because the model decided to be thorough. On an OTA's 3-to-5% merchant margin, that agent will burn through the quarter's profit on a chatbot that never actually books anything.
This is the most overlooked line in every agentic-travel demo I've sat through, and it's exactly why those demos don't survive contact with production. A deterministic agent caps and caches searches because the orchestration layer — not the model's mood — decides when a search is worth its fee.
And for a TMC, that economics ties straight to the number the CFO is actually chasing. The metric this build moves is touchless booking percentage and the offline-queue handle time sitting behind it. Every hallucinated or unserviceable booking is a ticket that falls back to a human agent — which is the cost being pointed at when someone in the room says "do an AI thing like Navan."
Why Can't You Just Build It on the Amadeus API?
A few realities I had to learn the expensive way, and that I now bring up in the first discovery call so nobody is surprised in month three.
If you're a TMC planning to "just build on the Amadeus API," check which key you have. Amadeus's Self-Service Production tier specifically excludes the Flight Create Orders endpoint — it is, in their own framing, designed for businesses without travel-agency certification. To actually issue orders you need Enterprise. I've watched that single line item reset a roadmap by a quarter.
Then there's the seam everyone treats as solved and isn't: NDC versus GDS. New Distribution Capability is great for the initial offer and order, but post-booking servicing — exchanges, refunds, irregular-operations rebooking — still runs on GDS infrastructure even when the original sale was NDC. A production agent needs both pipes, not a binary choice between them. And NDC itself isn't one thing: Level 4 order management through an aggregator like Verteil or Duffel is a different integration than the Level 3 shopping most wrappers stop at. IROPS is where the gap gets real — a single weather event can strand travelers by the planeload, each one costing $500 to $2,000 to rebook. An agent that can search but can't service is a toy.
And if your design has the agent issuing tickets directly rather than routing to a host system, you're now in accreditation territory — ARC in the US, which runs about 25 days once prerequisites are met, or full IATA accreditation, which can take six to twelve months. There's also a payment trap: the moment a chat surface collects card data, you've pulled your whole stack into PCI scope. Agentic commerce today still hands the actual authorization to a human payment step, with tokenization through a provider like VGS or Checkout.com keeping card data out of your environment.
None of this is in the keynote. All of it is in the production incident report.
"Why not just buy Sabre's, or Cytric, or Navan?"
People ask me this constantly, and my honest answer surprises them: sometimes you should.
If you're a leisure OTA happy to distribute Sabre's inventory on Sabre's rails, the Sabre–PayPal–Mindtrip stack is a reasonable buy — as long as you've accepted Sabre-locked supply and the absence of a corporate-policy layer or ISO 31030 instrumentation. If you're a Microsoft-native enterprise already on Cytric and Concur, Cytric Easy inside Teams is probably right for you, and I'll tell you that directly. If you want to rip out your TMC entirely and run an AI-native platform, Navan has genuinely earned its numbers — 73% touchless expenses, policy violations down from 35% to under 5% — and I'm not going to pretend we beat them at being Navan.
We fit a narrower, specific case: you want to keep your existing GDS contracts and your TMC relationship and add intelligence on top, vendor-neutral, without becoming a distributor for whoever you bought your agent from. That's the build. And the parts I can't do, I say out loud — we are not an IATA/ARC-accredited ticketing agent, so issuance goes through your host; we don't own your GDS commercial agreements; and we can't fix an ambiguous corporate travel policy, though we'll help you tighten it in discovery, because an ambiguous policy makes an ambiguous agent no matter how good the code is.
The deadline that closes the window
One more thing on the clock. The EU AI Act's transparency obligations for deployers go live on August 2, 2026, and the high-risk classification guidance landed back on February 2, 2026. If your agent talks to EU consumers, disclosure isn't optional and "we'll add it later" is a compliance finding waiting to happen. We build the Article 50 disclosure surface and a log-and-explain audit trail in from the start, because retrofitting transparency onto a black-box wrapper is far more painful than designing for it.
So this is where I've landed after all of it. Fluency is now free — every wrapper on the market sounds confident, and a traveler can't tell a real confirmation from a hallucinated one by reading it. What a traveler can tell, eventually, is whether the room is at the front desk when they arrive. That gap — between a sentence that reads true and a PNR that is true — doesn't close because the model got bigger. It closes because someone decided, before launch, that the model would never be the thing answering "is this real?" The deterministic layer that answers it is unglamorous, it doesn't demo as well, and it is the entire job.
The Tabacon Springs Eco-Lodge is still not a real place. The only question that matters is whether your system knows that before your customer is standing in the lobby. If you want to see how we built ours to know, the full breakdown is here.


